基于CUDA的粒子系统的实现
基于CUDA的粒子系统的实现
用途:
这篇文章作为代码实现的先导手册,以全局的方式概览一下粒子系统的实现大纲.
科普:
对粒子进行模拟有两种基本方法:
- Eulerian(grid-based) method : 相对于固定坐标系的点进行属性计算
- Lagrangian(particle) method : 相对于移动坐标系的点进行属性计算
这是两个完全不同的坐标系参考下的方法,而且这两种方法各自发展出了自己的方法派系.
在刚体动力学中的应用:
- 欧拉方法多被应用于固定坐标系下的动力学模拟,比如吊车,机械臂等.
- 拉格朗日方法多被应用于移动坐标系下的动力学模拟,比如航天器等航天器.
因为在各自不同的领域两种坐标系都能以最简方程式表达动力方程,所以两种坐标系下的方法并不打算合并统一.
若读者不太了解的话请思考,xyz坐标系和极坐标系的关系.
Particle-based method(拉格朗日方法)对比欧拉方法在粒子模拟领域
优点:
- 只有必要时才进行计算
- 更小的储存空间和带宽,因为只需计算粒子位置的模型属性而不用计算整个空间内任意点的属性.
- 不需要被限制在一个有限的盒子内(因为欧拉方法计算空间中任意点的状态,所以必须限制范围)
- 能简单实现质量守恒(每个粒子的质量固定)
缺点:
- 每个粒子需要储存自己的计算结果(当粒子非常多时需要很大的内存开销)
幸运的是,这对于显卡这种高速且大量并行运算的架构来说这种模拟方法正合适.
这篇文章会介绍如何实现一个粒子模拟系统.
实现:
我们把实现过程分为三步:
- 积分位移
- 建立网格结构数据
- 处理碰撞
1.积分位移
计算积分位移是一个简单的过程, 我们采集粒子的属性(位置,速度),然后根据每个粒子的位置和速度计算下一个时间步长中粒子移动到的位置.
我们使用欧拉方法(固定坐标系)根据粒子受到的力计算其速度 F=mvt .t为时间步长. 碰撞检测随后在这一环节进行计算.
2.粒子间交互
如果粒子间没有交互(比如实现烟花,烟雾,火焰等游戏特效),那整个系统就太简单了.
当然我们讨论的粒子间是有交互的,基本交互就是碰撞(当然还有粘滞,引力吸引等),我们使用空间分割方法来进行碰撞检测(当然这也是唯一的高效碰撞检测方法,以后我们单独讨论不同碰撞算法的区别和实现)
但首先我们承认一个基本事实:
*. 当距离越远作用力越小,距离越近作用力越大 (你有可能认为这不符合宏观现实,但请你考虑往分子中插入一个质子需要多大力?)
这样我们就可以只计算给定粒子周围半径内其他粒子给它的合力.空间分割方法能高效的获取粒子的最近临(你可以暂且当作kd-tree)
3.均分空间网格
我们使用均分网格作为空间分割方法(当然也可以使用其他的空间分割方法)
均分网格吧空间分割成一个个 cell. 为了简单起见我们认为 cell的大小只能容下一个粒子.那么每个粒子最多被空间中8个 cell所包围.我们暂且认为粒子间没有穿透.那么每个 cell最多最多只能接触到4个粒子.
当一个粒子恰好在一个 cell的中心的时候,我们需要检测空间中 3x3x3-1=26个格子内是否包含其他粒子.所以我们把粒子中心点位置的 cell的索引号作为粒子的索引号,这样根据每个粒子的 cell编号就可以轻易的找到附近是否有其他粒子,因为 cell的编号是有排序的.
还有一种实现方式是把粒子半径中碰到的所有 cell编号都记录下来(更多细节被储存),这样碰撞处理所需计算量就减少了,但建立这个索引模型所需的开销就变大了,而根据实践结果而言,增加模型建立的开销比减少碰撞处理的时间来得更大,这是一种得不偿失的做法.
因为每个时间步长(你可以暂且当作每帧,如果你对时间步长没有概念的话),网格数据都要进行更新,你可能想到在原有的数据结构中去更新,而非重新建立,但通常来说更新模型并不比重新建立模型需要的时间更少.
4.建立空间网格模型
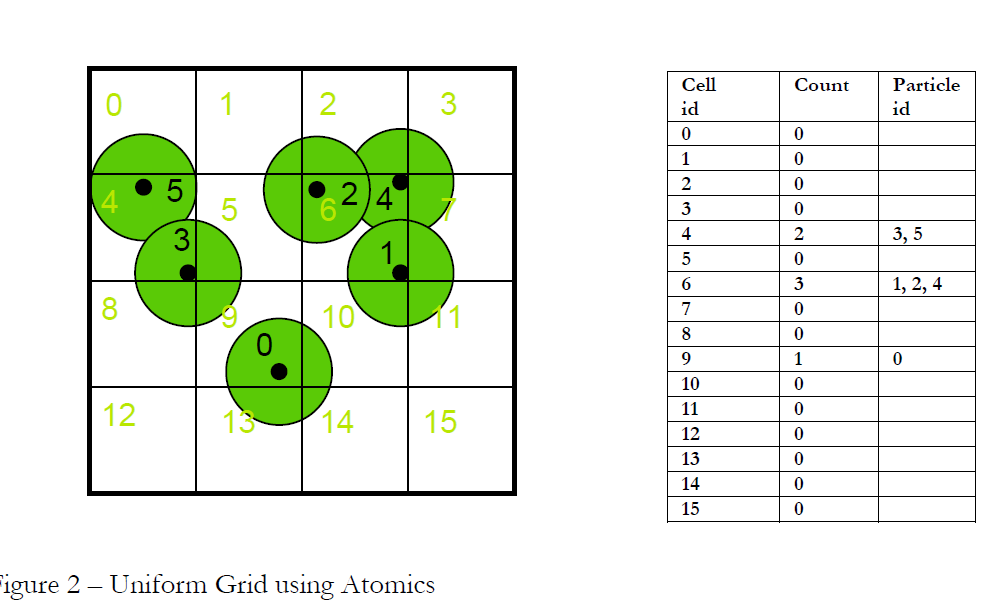
4.1 基于原子操作的方法
在支持原子操作的GPU上(nvdia显卡计算能力超过1.1),我们可以用相对简单的算法实现这个建立过程.原子操作允许多个threads同时更新 global内存块中的同一个数据,而不必担心其发生读写冲突和竞争.
我们使用两个数组,存放在 global memory中:
- gridCounters - 这个数组储存着每个 cell中含有多少个粒子.且每帧都重置为0,然后重新计算.
- gridCells - 这个数据中储存着每个 cell中包含粒子的索引号,且具有最大包含粒子个数限制.
updateGrid 这个 kernel函数负责计算并更新每一个网格结构. GPU上每个 thread跟踪计算一个粒子.
计算流程包括:
- 粒子所在 cell
- 使用 atomicAdd 函数增加 gridCounters中对应 cell的 counter值.
- 把自己(粒子)的索引号加入 gridCells中对应 cell之中(使用scattered global write(散列全局内存写入)技术)
我们限制每个 cell设置最大包含粒子数,这样它就不会导致内存溢出问题,这是为了防范粒子穿透等情况发生时程序崩溃,也为了防止程序性能下降.(当多个粒子处在同一个 cell时,写入相关 cell的操作会进行序列化,这会导致程序性能的降低.),当然也可以分两步走:
- 只计算 counter值
- 扫描全部 grid 并写入粒子索引.
区别在于第二步每个 thread计算对象是 grid,所以不会存在排序写入的问题.
下图显示了一个例子:
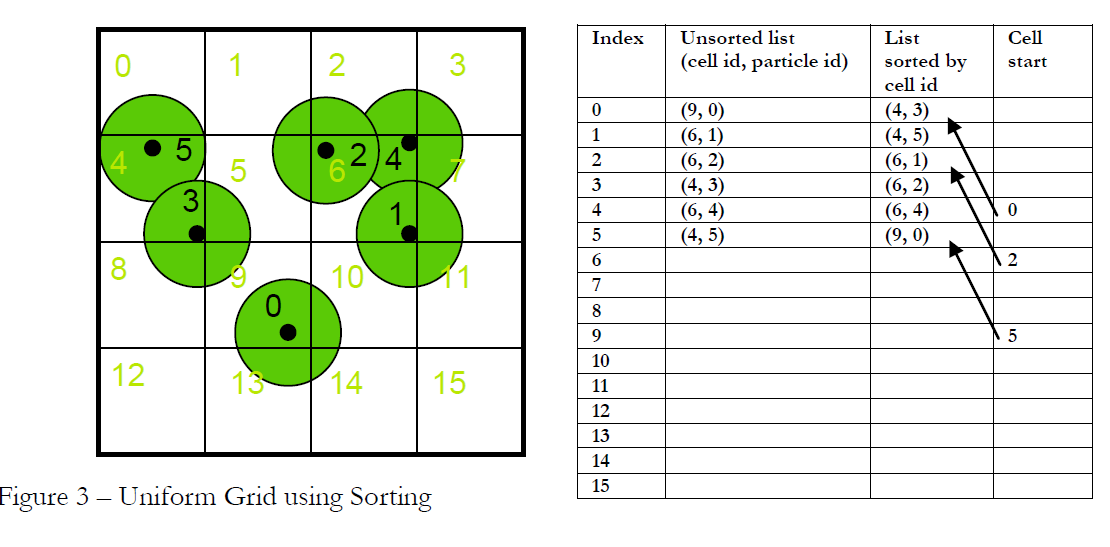
4.2 基于排序的方法
另一种方法使用排序而不是原子操作来建立网格结构模型.
- 使用 kernel calcHash 计算每个粒子所在 cell的索引哈希值.然后根据该哈希值进行排序.这样就获得了以 cell索引为顺序的列表,随后寻找并合并相同 cell id的项,并散列写入 cell start列表中,因为已经排序,所以不会发生写入冲突或者排队写入的问题.
这种方法解决了原子写入的排队等待问题的瓶颈,但增加了排序算法的开销.(实践结果显示使用Satish, N., Harris, M方法
(fast radix sort 快速树排序在 CUDPP库中实现并提供)排序方法的算法开销比使用原子操作导致的排队写入开销来的小,所以性能更加)
注意:该方法在不支持CUDA散列内存写入技术的硬件上只能使用二叉树来实现.
5. 粒子碰撞
一旦我们建立起网格空间模型,我们就可以使用它来加速粒子之间的交互计算,我们使用DEM 方法计算碰撞. 这种碰撞方法由两个粒子间的弹簧阻尼函数计算,弹簧力使两个粒子分开,阻尼力使粒子粘滞.
每个粒子的计算首先在之前建立的空间模型内寻找附近 27个 cell中是否有其他粒子,如果存在其他粒子就进行碰撞的计算.如果没有其他粒子,就直接由粒子的速度计算下一时间的位置并刷新即可.
我们可以看到如果我们不建立空间网格模型,如果我们有1万个粒子,则需要进行1W x 1W = 1亿次计算,而一旦建立空间模型只需进行 1W x 27 = 27万次计算即可,差了将近 400倍. N^2 和 27*N 的算法复杂度.
性能
在大多数的硬件上, 4.2 排序法有更好的性能.因为排完序可直接进行碰撞检测,在列表中的顺序即是空间上的位置结构.
而使用原子操作的方法对粒子的分布更加敏感,之前我们已经讨论过排队等待写入的问题.
在实践中可以使用 texture memory 对 global array进行映射,来获取粒子的速度和位置数据,因为 texture缓存对二维读取是优化过的, 一个 warp(32条并行 threads)内的 threads恰好要读取 texture缓存中的数据地址非常相近的话, texture缓存会为读取操作提供最佳性能和带宽,这是 texture 缓存硬件设计上的优势所决定的. (使用 texture缓存为读取数据增加了45%的性能)
这更加说明了排序方法的优势,因为它就是按照位置来排序的.
总结
CUDA的散列内存写入技术为创建动态数据结构提供了强力的支持.排序使得内存连续读取特性得到了充分的发挥,这一系列的组合使得GPU可以在一个实时的环境下模拟大型粒子系统. 我们还可以使用以下这些算法来进一步优化程序性能:
- Qiming Hou, Kun Zhou, Baining Guo, BSGP: Bulk-Synchronous GPU Programming, ACM TOG (SIGGRAPH 2008)
- Ericson, C., Real-Time Collision Detection, Morgan Kaufmann 2005
- Satish, N., Harris, M., Garland, M., Designing Efficient Sorting Algorithms for Manycore GPUs, 2009.
- Joshua A. Anderson, Chris D. Lorenz, and Alex Travesset General purpose molecular dynamics simulations fully implemented on graphics processing units, Journal of Computational Physics 227 (2008)
脚注:
scattered-global-write 散列全局内存写入技术是CUDA引入的技术,通常来说只有获取或者写入连续物理内存地址时,写入和读取操作才能被合并成为一个,因为处理器一个指令只能获取一个内存地址(比如SIMD),如果内存地址连续那么就可以一次性拷贝连续数据至内存(内存对齐后,intel的CPU芯片也支持最多4个 float4类型的 SIMD).但当地址不连续时因为只有一个地址,所以也只能一个个指令顺序进行读取,显然这种方式成为了其他部分的性能瓶颈. 散列全局内存写入就是为了解决那些不连续内存写入的问题,它把多个不连续的内存写入合并为一个命令,然后并发写入,解决了这个瓶颈,当然也多亏了Nvidia显卡的MIMD架构(多指令多数据流).
DEM Harada, T.: Real-Time Rigid Body Simulation on GPUs. GPU Gems 3. Addison Wesley, 2007
Satish, N., Harris, M., Garland, M., Designing Efficient Sorting Algorithms for Manycore GPUs, 2009.
Ian Buck and Tim Purcell, A Toolkit for Computation on GPUs, GPU Gems, Addison-Wesley, 2004
参考文献:
- Reeves, W. T. 1983. Particle Systems—a Technique for Modeling a Class of Fuzzy Objects. ACM Trans. Graph. 2, 2 (Apr. 1983), 91-108.
- Monaghan J.: Smoothed particle hydrodynamics. Annu. Rev. Astron. Physics 30 (1992), 543. 12, 13
- Müller M., Charypar D., Gross M.: Particle-based fluid simulation for interactive applications. Proceedings of 2003 ACM SIGGRAPH Symposium on Computer Animation (2003), 154–159.
- Müller, M., Heidelberger, B., Hennix, M., and Ratcliff, J. 2007. Position based dynamics. J. Vis. Comun. Image Represent. 18, 2 (Apr. 2007), 109-118.
- Harada, T.: Real-Time Rigid Body Simulation on GPUs. GPU Gems 3. Addison Wesley, 2007
- Le Grand, S.: Broad-Phase Collision Detection with CUDA. GPU Gems 3, Addison Wesley, 2007
- Nyland, L., Harris, M., Prins, J.: Fast N-Body Simulation with CUDA. GPU Gems 3. Addison Wesley, 2007
- Z-order (curve), Wikipedia http://en.wikipedia.org/wiki/Z-order_(curve)
- Ian Buck and Tim Purcell, A Toolkit for Computation on GPUs, GPU Gems, Addison-Wesley, 2004
- Qiming Hou, Kun Zhou, Baining Guo, BSGP: Bulk-Synchronous GPU Programming, ACM TOG (SIGGRAPH 2008)
- Ericson, C., Real-Time Collision Detection, Morgan Kaufmann 2005
- Satish, N., Harris, M., Garland, M., Designing Efficient Sorting Algorithms for Manycore GPUs, 2009.
- Joshua A. Anderson, Chris D. Lorenz, and Alex Travesset General purpose molecular dynamics simulations fully implemented on graphics processing units, Journal of Computational Physics 227 (2008)
基于CUDA的粒子系统的实现的更多相关文章
- (转)基于CUDA的GPU光线追踪
作者:Asixa 链接:https://zhuanlan.zhihu.com/p/55855479 来源:知乎 著作权归作者所有.商业转载请联系作者获得授权,非商业转载请注明出处. 替STL. ...
- unity, 只发射一个粒子的粒子系统
- SpriteBuilder中的粒子系统属性
一个粒子发射器可以有2种模式,放射状和重力的(radial or gravity) 放射状模式允许你去使用发射器创建粒子旋涡状环绕在指定位置的效果. 当启用重力效果,你可以使得粒子在任何方向任意飞行, ...
- 关于Cocos2d-x的粒子系统
1.cocos2d-x有一些自带的粒子效果,以后可以用到.当然,也可以自己定义一些粒子,不过要定义的话,虽然可以用cpp文件自己写,但是没有可视化的调节,还要设定各种奇怪的参数,是非常困难的.可以用一 ...
- unity2017.1.0f3与旧的粒子系统不兼容
在测试旧版本插件unistorm时用unity2017.1.0f3打开后其它天气效果显示正常,雨点看不到,再用unity5.52打开后,所有效果都可以看到了. 记录备忘
- 【3D动画建模设计工具】Maxon Cinema 4D Studio for Mac 20.0
图标 Icon 软件介绍 Description Maxon Cinema 4D Studio R20 ,是由德国公司Maxon Computer一款适用于macOS系统的3D动画建模设计工具,是 ...
- DirectX11 With Windows SDK--35 粒子系统
前言 在这一章中,我们主要关注的是如何模拟一系列粒子,并控制它们运动.这些粒子的行为都是类似的,但它们也带有一定的随机性.这一堆粒子的几何我们叫它为粒子系统,它可以被用于模拟一些比较现象,如:火焰.雨 ...
- [笔记] 基于nvidia/cuda的深度学习基础镜像构建流程 V0.2
之前的[笔记] 基于nvidia/cuda的深度学习基础镜像构建流程已经Out了,以这篇为准. 基于NVidia官方的nvidia/cuda image,构建适用于Deep Learning的基础im ...
- 介绍用C#和VS2015开发基于Unity架构的2D、3D游戏的技术
[Unity]13.3 Realtime GI示例 摘要: 分类:Unity.C#.VS2015 创建日期:2016-04-19 一.简介 使用简单示例而不是使用实际示例的好处是能让你快速理解光照贴图 ...
随机推荐
- powerdesigner反向SQLServer2008数据库生成物理数据模型
方法一:通过数据库脚本生成物理数据模型 具体步骤如下图所示:
- WebView具体介绍
PART_0 侃在前面的话 WebView是Android提供给我们用来载入网页的控件.功能非常强大.我们经常使用的手机淘宝.手机京东的Androidclient里面大量使用到了WebView. ...
- linux列出一个目录及其子目录下面的某种类型的文件
linux列出一个目录及其子目录下面的某种类型的文件 作者:smarteng ⁄ 时间:2009年07月09日 ⁄ 分类: Linux命令 ⁄ 评论:0 怎么样把,一个目录及其所有的子目录下面的某种类 ...
- 【centOS7】centOS7上普通用户切换root用户,相互切换
当前普通用户登录,想要切换为root用户,需要输入命令 su 需要输入root密码.输入时候屏幕不会显示,直接输入完了,回车即可 回车后,即切换到root用户下 想要从root用户切换到普通用户,只需 ...
- 玩转rocketMQ
下载地址https://github.com/alibaba/RocketMQ 安装环境需要jdk,maven,git http://maven.apache.org/download.html
- 计算Fisher vector和VLAD
This short tutorial shows how to compute Fisher vector and VLAD encodings with VLFeat MATLAB interfa ...
- 关于ios发布AppStore验证UUID不过的问题
转载于:http://blog.csdn.net/iunion/article/details/9045573 刚刚更新过的代码出现了问题,在上传之前的验证就不通过,提示 Apps are not p ...
- 在Ubuntu 12.04 桌面上设置启动器(快捷方式)
在Ubuntu 12.04 桌面上设置启动器(快捷方式)过程讲解: 如下图所示,Eclipse 和 SQLDeveloper 都可以直接双击打开,这些应用程序的启动器都在 /usr/share/app ...
- scala的一些特殊用法
1.创建多行字符串,只要把多行字符串放在3个双引号间("""...""")即可.这是Scala对于here document,或者叫here ...
- 解决:HTTP 错误 404.2 - Not Found. 由于 Web 服务器上的“ISAPI 和 CGI 限制”列表设置,无法提供您请求的页面
错误重现: 在发布网站的过程中,虽然不是第一次发布了,但是还是遇到了很多的问题.为了以后可以轻松解决此类问题还是积累下来比较好. 问题:HTTP 错误 404.2 - Not Found. 由于 We ...