基于统计的无词典的高频词抽取(二)——根据LCP数组计算词频
接着上文【基于统计的无词典的高频词抽取(一)——后缀数组字典序排序】,本文主要讲解高频子串抽取部分。
如果看过上一篇文章的朋友都知道,我们通过 快排 或 基数排序算出了存储后缀数组字典序的PAT数组,以及PAT数组内,每每两个子串的最大公共前缀数组LCP。
我们可以通过LCP来计算出一个字符串在语料库中出现的次数。那怎么计算呢?我们先看看下面一个简单的例子:
【例】我们还是以上一篇文章中的字符串“abcba”为例,经过对后缀数组字典序排序(过程参照前一篇),可以得到以下的结果:
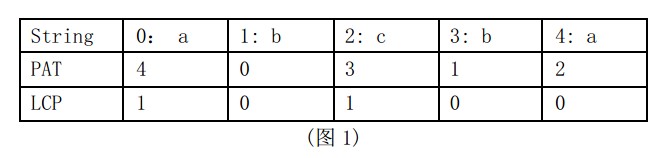
由上图中的PAT和LCP两个数组我们可以知道:“a”的频率为2,“b”的频率为2。
计算方式其实很简单,从左扫描LCP数组,如果LCP[i]>=n(n为自定义的两个字符串公共子串的长度的最小长度,上面例子中设置为1),LCP[0]=1符合候选规则,则看PAT[0]=4,意思是说“abcba”这个字符串中的第PAT[i]+1=5个后缀子串,也就是“a”,我们知道,LCP表示的是相邻的两个PAT间的最长公共前缀,故“a”的频率=LCP[0]+1=2次。同理,可以知道“b”出现两次(S[PAT[3]]=b,LCP[2]=1,所以b出现的次数为1+1=2,刚开始有点难理解,但其实很好理解的)
分析完上面的例子,我们应该更加清楚的了解了LCP的作用,就是计算一个字符串在一个语料库中出现的次数,现在我们就用伪代码(文字)一步一步分析这个过程:
① 设定c 的初值为0;
② 从LCP位置c开始扫描直至索引i,有LCP[i]≥n;
③ 记录LCP[i]的值,继续向前扫描,直至位置j,有LCP[j]<LCP[i]。如果存在位置x(i<x≤j),有LCP[x]>LCP[i],则令c=x,否则c=j;
④ 提取字符串S,其在T中的开始位置为PAT[i],长度为LCP[i],S出现的次数为j-k,记录串S出现的次数j-k;
⑤ 返回步骤②,提取下一个字符串,直至扫描完LCP数组;
⑥ 对所记录的所有字符串,按照出现次数进行排列,输出所有出现次数≥n的字符串序列;
这个过程中要注意存在这样这样的一种情况:假设LCP为:1,1,3,2,1,0,0,2,...,那么1,1,3,2,1 我们知道,第一个字符出现了6次,而中间的3那个串出现了2次,但是计算2那个串的时候,因为前面的3>2,所以我们必须往前回溯,也就是说这里2那个串出现的次数是2+1=3次;
代码实现过程如下(经测试,对30万的数组查找耗时12s左右,没做过多优化,大家可以根据此思路来做优化):
public static void ScanLCP(List < StringFrequency > stringFrequncy, int[] LCP, int count, int start, int minLen, int maxLen)
{
var _START = start;
while (_START <= count - )
{
var _LCP = _START;
var isFirst = true;
var isLarge = true;
var isContinue = true;
int j = ;
int i = _START;
for (; i < count; i++)
{
if (LCP[_START] > maxLen)
{
_START += ;
break;
}
if (isFirst)
{
if (i - >= )
{
if (LCP[i - ] >= LCP[i])
{
for (var k = i - ; k >= ; k--)
{
if (LCP[k] >= minLen && LCP[k] != LCP[i])
j += ;
else
{
if (LCP[k] == LCP[i])
{
isContinue = false;
j = ;
}
break;
}
}
}
}
}
if (LCP[i] >= minLen && LCP[i] >= LCP[_LCP] && isContinue)
{
if (isFirst)
{
_LCP = i;
isFirst = false;
}
if (isLarge && LCP[i] > LCP[_LCP])
{
_START = i;
isLarge = false;
}
}
else
{
if ((isFirst && LCP[i] < minLen) || !isContinue)
_START = i + ;
else
{
if (isLarge && LCP[i] < LCP[_LCP])
_START = i;
if (LCP[_LCP] <= maxLen)
{
var sf = new StringFrequency();
sf.Position = _LCP;
sf.Times = (i - _LCP) + + j;
stringFrequncy.Add(sf);
}
}
break;
}
}
}
}
看起来好像挺玄乎,其实,到这一步的时候,对语料库的分析抽词已经初见成效了,下图,是我对《人民日报》2012年8月份到11月份的报纸的分析抽取,进行了后缀数组排序,LCP计算后的结果:
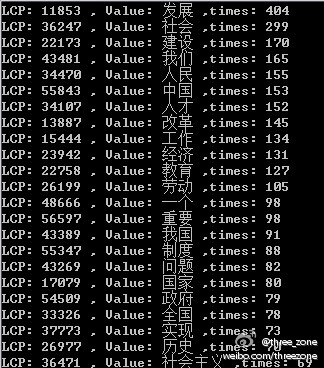
现在的结果还不够精确,等做完子串归并,最大熵模型后,可以获得更精准的结果(Ps:人民日报涉及的内容太片面,实际情况下,要采集涉及面广的语料库)
好了,第二部分就先讲到这里,如果觉得文章对您有用或者对其他人有帮助,请帮忙点文章下面的“推荐”;如果文章有任何纰漏,欢迎指正,谢谢!
基于统计的无词典的高频词抽取(二)——根据LCP数组计算词频的更多相关文章
- 词频分析 评论标签 nltp APP-分析买家评论的评分-高频词:二维关系
0-定评论结果:好评.差评,1星.4星,二元化为“积极.消极”,取一元的数据为样本 1-得到词频结果:如手机类的“积极样本”得到前10的高频词:运行(run running ran).内存(memor ...
- 【爬虫+情感判定+Top10高频词+词云图】“谷爱凌”热门弹幕python舆情分析
一.背景介绍 最近几天,谷爱凌在冬奥会赛场上夺得一枚宝贵的金牌,为中国队贡献了自己的荣誉! 针对此热门事件,我用Python的爬虫和情感分析技术,针对小破站的弹幕数据,分析了众网友弹幕的舆论导向,下面 ...
- 【爬虫+情感判定+Top10高频词+词云图】“刘畊宏“热门弹幕python舆情分析
一.背景介绍 最近一段时间,刘畊宏真是火出了天际,引起一股全民健身的热潮,毕竟锻炼身体,是个好事! 针对此热门事件,我用Python的爬虫和情感分析技术,针对小破站的弹幕数据,分析了众多网友弹幕的舆论 ...
- 【爬虫+情感判定+Top10高频词+词云图】"王心凌"热门弹幕python舆情分析
目录 一.背景介绍 二.代码讲解-爬虫部分 2.1 分析弹幕接口 2.2 讲解爬虫代码 三.代码讲解-情感分析部分 3.1 整体思路 3.2 情感分析打标 3.3 统计top10高频词 3.4 绘制词 ...
- kaggle信用卡欺诈看异常检测算法——无监督的方法包括: 基于统计的技术,如BACON *离群检测 多变量异常值检测 基于聚类的技术;监督方法: 神经网络 SVM 逻辑回归
使用google翻译自:https://software.seek.intel.com/dealing-with-outliers 数据分析中的一项具有挑战性但非常重要的任务是处理异常值.我们通常将异 ...
- NLP系列-中文分词(基于统计)
上文已经介绍了基于词典的中文分词,现在让我们来看一下基于统计的中文分词. 统计分词: 统计分词的主要思想是把每个词看做是由字组成的,如果相连的字在不同文本中出现的次数越多,就证明这段相连的字很有可能就 ...
- [LeetCode] Top K Frequent Words 前K个高频词
Given a non-empty list of words, return the k most frequent elements. Your answer should be sorted b ...
- 5分钟Serverless实践 | 构建无服务器的敏感词过滤后端系统
前言 在上一篇“5分钟Serverless实践”系列文章中,我们介绍了什么是Serverless,以及如何构建一个无服务器的图片鉴黄Web应用,本文将延续这个话题,以敏感词过滤为例,介绍如何构建一个无 ...
- 图解kubernetes scheduler基于map/reduce无锁设计的优选计算
优选阶段通过分离计算对象来实现多个node和多种算法的并行计算,并且通过基于二级索引来设计最终的存储结果,从而达到整个计算过程中的无锁设计,同时为了保证分配的随机性,针对同等优先级的采用了随机的方式来 ...
随机推荐
- 文件的概念以及VC里的一些文件操作API简介
文件的基本概念 所谓“文件”是指一组相关数据的有序集合. 这个数据集有一个名称,叫做文件名. 实际上在前面的各章中我们已经多次使用了文件,例如源程序文件.目标文件.可执行文件.库文件 (头文件)等.文 ...
- Python反转
1切片 s="svdfbffdbdf" a=s[::-1] 2入栈出栈 入栈之后再出栈正好就是了 3reverse 这个函数是列表的....你要先把str转成list list-& ...
- python笔记之str常用方法
#Auther Bob#--*--conding:utf-8 --*--# s1 = 'aBcdE1d'# ============================================== ...
- access数据库收缩(压缩)
一般是因为表中有大量没用的数据,把没用的数据全部删除 菜单栏的“工具”——“数据库实用工具”——“压缩和修复数据库” OK啦
- haproxy 学习
https://cbonte.github.io/haproxy-dconv/configuration-1.5.html#4-option%20tcp-check https://www.hapro ...
- 15-js提交表单的简单检测实例
<%@ page language="java" contentType="text/html; charset=UTF-8" pageEncoding= ...
- ImageView小技巧
ImageView截取图片的方式 centerCrop:以中心点为基准 将图片的最短边与ImageView宽度匹配 其他部分裁掉centerInside: 以中心点为基准 将图片最长边 缩进控件去
- VMware下centos7安装VMware Tools
右键虚拟机设置,找到CD/DVD,选择使用ISO映像文件,在VMware安装目录下找到linux.iso. 挂载iso文件 > mount -t auto /dev/cdrom /mnt/c ...
- sock基础编程介绍
一个简单的python socket编程 一.套接字 套接字是为特定网络协议(例如TCP/IP,ICMP/IP,UDP/IP等)套件对上的网络应用程序提供者提供当前可移植标准的对象.它们允许程序接受并 ...
- PAT 1070 结绳(25)(代码)
1070 结绳(25 分) 给定一段一段的绳子,你需要把它们串成一条绳.每次串连的时候,是把两段绳子对折,再如下图所示套接在一起.这样得到的绳子又被当成是另一段绳子,可以再次对折去跟另一段绳子串连.每 ...