360Vedio To NFOV Vedio
Deep 360 Pilot Learning a Deep Agent for Piloting through 360° Sports Videos
源码、数据集和视频演示
ego-centric(以自我为中心的)
背景:
看360°运动视频需要观察者连续选择视角,通过一系列的鼠标点击或头部运动
解决方案:
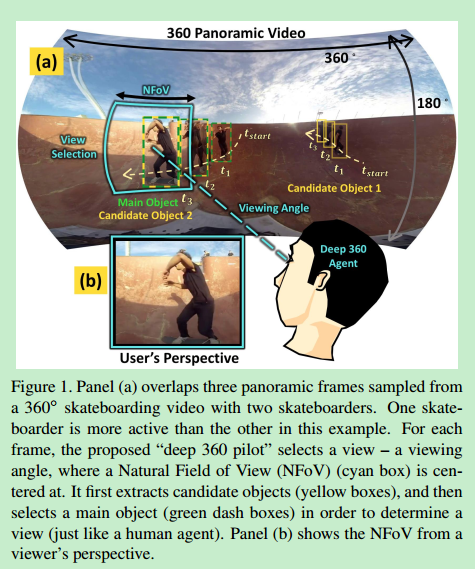
叫作deep 360 pilot的方法(基于深度学习的方式在360°运动视频里进行导航)
自动帮用户选择合适的视角的代理人
每一帧,代理人观察全景图,结合之前帧的视角得出下一个最合适的视角并帮助观看者调整画面,使用户不需要动鼠标和头部自动获得最佳画面内容体验
视角转换尽量平滑
捕获视频中有趣的运动
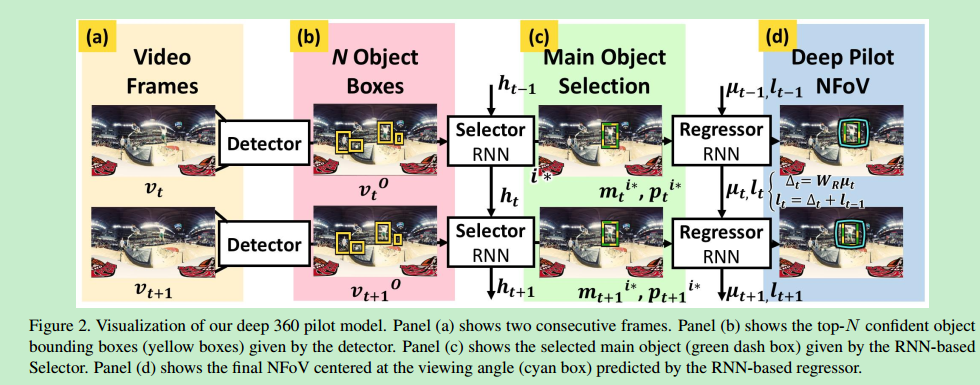
运动视频的前景物体是观看者感兴趣的,所以用最先进的物体探测器(Faster r-cnn: Towards
real-time object detection with region proposal networks)识别感兴趣的候选物体
然后用RNN选择候选物体中的主要物体
将主要物体和之前选中的视角结合通过训练回归器(regressor)来预测如何旋转视角到更好的视角
训练的时候用到了以下函数:
1.用来测量选中视角和标注视角之间距离的回归损失(regression loss)
2.平滑损失(smoothness loss)来使视角转换更加平滑
3.注视到前景物体有额外奖励
使用策略梯度法(policy gradient technique)
先用RCNN检测出物体,再根据显著性检测器(saliency detector)选择最显著的物体
Su(SYC)等人提出了处理360°视频的离线方式(Pano2Vid),然而这篇文章是在线的基于之前和现在帧观察的像人一样做出反应的代理
只预测方位角和俯仰角
需要人工标注视频作为训练集
旋转视角的决策只跟当前帧的画面和前一帧的视角有关
定义:
vt:t时刻的帧
θt:t时刻的方位角[0°,360°]
φt:t时刻的俯仰角[-90°,90°]
lt:t时刻的视角,lt=(θt,φt)=Δt + lt−1
Δt:t时刻采取的行动,Δt = π(Vt, Lt−1),π是我们的在线策略
因此主要任务是从数据中学习π
我们只关注360°视频的前景物体而不是提取整个视频的信息(因为运动视频中关注的目标主要是前景物体,而且物体的大小与全景视频相比小得多)
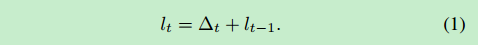
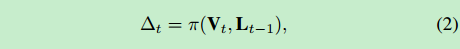
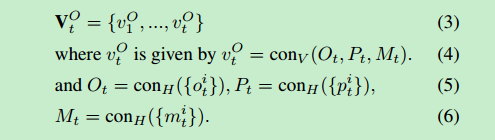
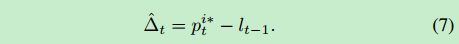
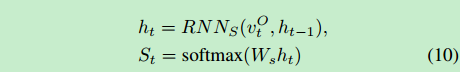
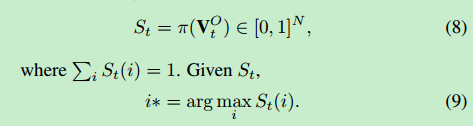
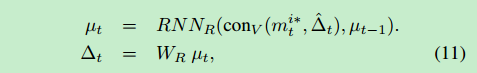
conH() 和 conV ()表示向量水平和垂直的连接

每个物体都有St(i)的概率成为主要物体,概率和为1,概率最大的物体就是我们估计的主要物体,St函数和在线策略π和当前物体的观察集合VO_t有关
由于VO_t随时间越来越大,我们用RNN(循环神经网络聚合这些信息)
将这些信息与平滑转换相结合
最小化预测视角和标注视角的欧几里得距离同时考虑平滑性(大的速率在两帧之间移动将会受到惩罚)
loss:
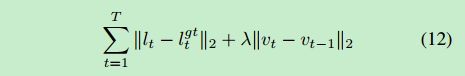
vt:视角移动速率 vt=lt-l(t-1)
lgt_t:t时刻标注的视角
λ:平衡参数
T:视频总帧数
根据与标注的窗口的重叠程度和每帧窗口移动的速率来判断好坏
没说处理视频要花多少时间
Learning Spherical Convolution for Fast Features from 360° Imagery

背景:
360°图像不变形就不能投影到一个简单的平面上,cnn需要平的图像才能训练
解决方案:
球面卷积网络让平面CNN在它的矩形投影上直接处理360°图像
能从图像和视频中提取足够的特征
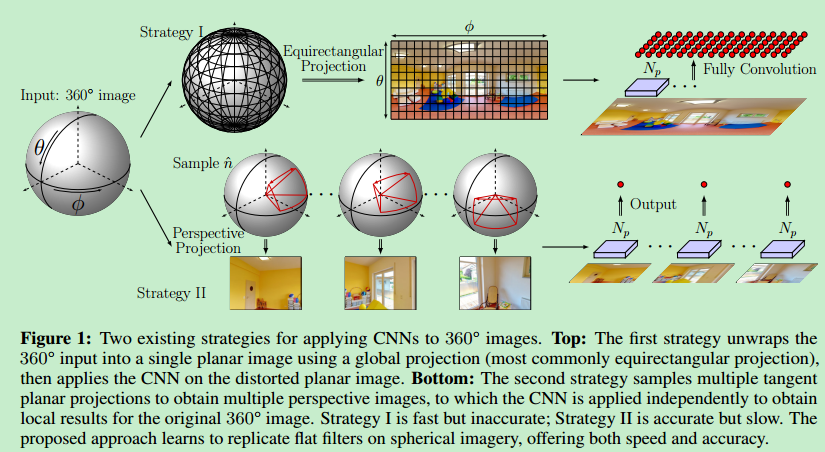
传统的在360°图像上应用CNN的方法:
1.用全球投影将360°图像变为一个平面上的图(速度快,不准确)
2.在球面上采样多个区域,将它们分别变为平面投影再独立使用CNN(速度慢,更准确)
任何球到平面的投影都会产生形变
测试用到的数据集:Pano2Vid,PASCAL VOC
缺点:
不能处理非常近的物体
实验:
检测它卷积的准确性和在360°数据中识别物体的适用性(与VGG和Faster_RCNN对比)
Learning to look around: intelligently exploring unseen environments for unknown tasks
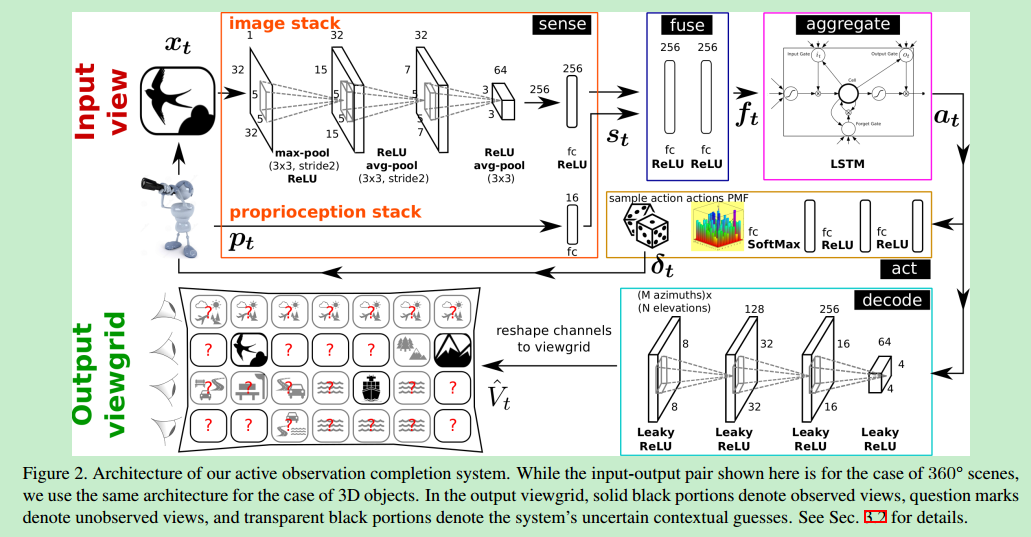

背景:
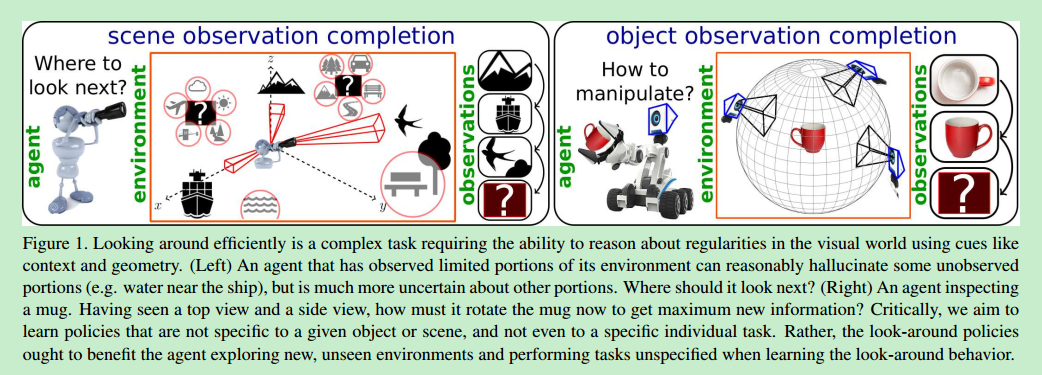
智能选择好的观察视角是一个挑战
利用识别物体方法选景的代理是没有灵魂的
该代理在新的环境中应该能智能地看新的物体
解决方案:
一个可以自己选择环境中富有信息的视角的代理
一个在全景自然场景和3d物体形状上的递归神经网络
训练时不依赖任何识别任务或特别的语义内容
我们有下面两个想法:
1.首先代理人(agent)从有限视野的相机观察场景,目标是在一些观察之后选择有效的相机运动,并建模出未观察到的场景的部分
2.代理人操作3d物体并检查它,目标是花费尽量少的行动获得物体3d形状的完整信息
为了完成上述想法,系统必须利用当前的视觉信息(形状、上下文等),推荐出下一时刻该查看未看见内容的哪一部分
使用rnn实现
意义:
在没有见过的环境中该代理也能发挥作用
训练数据无需手动标注
每一时刻如何选择全景图上看的地方才能获得更多的信息
SphereNet: Learning Spherical Representations for Detection and Classification in Omnidirectional Images
一种全景图上探测和分类的球面表示网络(SphereNet)
A Deep Ranking Model for Spatio-Temporal Highlight Detection From a 360◦ Video
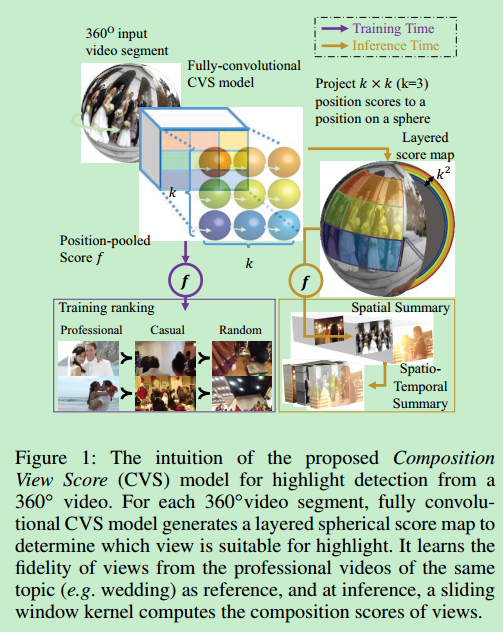
解决了360°视频时空上的重要内容检测
从360°视频中选择看起来令人满意的固定窗口的视频(不是实时的)
用户可以设定最后生成的视频的播放长度
提出了一个打分神经网络(Composition View Score CVS),给定一个360°视频能够生成球面的分数图,表示每一块区域的重要程度
对输入的每个视频每秒采样5帧
将每一帧划分为12个区域,既没重叠部分又能覆盖整个球面区域
将每一个区域变成平面投影,再丢到CVS模型计算它的得分图
与其他方法的对比:
AutoCam的卷积操作重叠严重且有太多的平面矩形投影,计算时间太高(1分钟的全景视频处理3小时)
我们的方法先预计算一个不重叠的360°打分图,再用滑动窗口找到最重要的区域,从而将交互的矩形投影和CNN计算从198减少到了12(1分钟全景视频处理11分钟)
从YouTube/Vimeo建立数据集
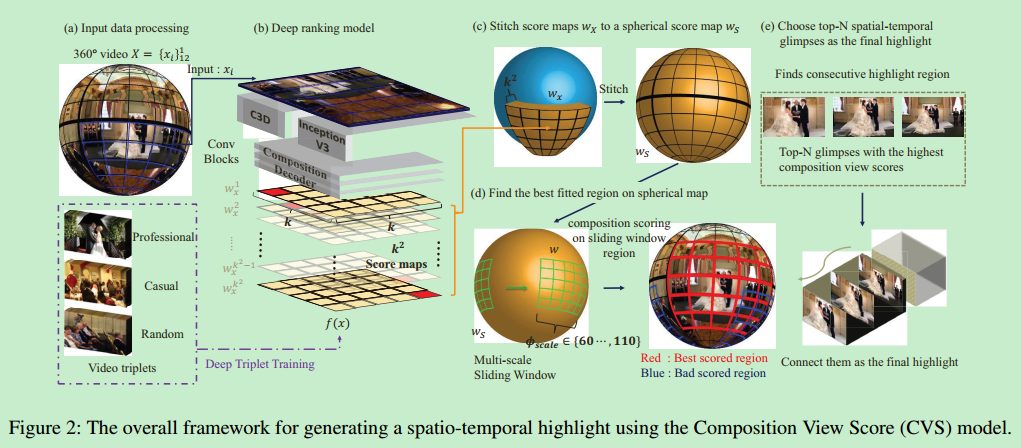
ST-glimpse:5秒的从360°视频采集的NFOV视频片段(相机方向固定为(θ, φ)),所以问题就是从360°视频找到最佳的ST-gimpses
CVS为每个NFOV ST gimpse计算一个分数(图2 b)
我们用两个特征提取器表示一个ST glimpse:C3d和Inception-v3
为了让CVS为重要区域打分,我们没有定义组成的好坏,而是运用数据驱动的方式:收集同一主题下专业的NFOV视频和普通用户的NFOV视频作为正样本(专业的视频有更高的权重),随机拍摄的视频作为负样本,将这三类样本组成我们的训练数据集
因为在360°视频输入的处理和输出360°打分图的时候没有用到CNN所以我们获得的是球形的打分图
CVS是卷积的所以信息丢失发生在空间相邻glimpses的边界附近,于是我们把每个glimpse扩大了1/k,然后将12个打分图缝合成一个球形的打分图,并把重叠区域去掉,然后信息就不会丢失了
Pano2Vid: Automatic Cinematography for Watching 360∘ Videos



背景:
记录全景视频很方便,拍摄者不需要决定捕获场景中的哪些内容
对看视频的人来说这就变得具有挑战,不知道看哪,找不到最感兴趣的内容
解决方案:
Pano2Vid,设计算法自动控制全景图中NFOV(normal field-of-view 正常视角)相机的姿势和运动,使用户直接观看该相机生成的内容
使用AUTO CAM算法,不需要人工标注,非监督学习
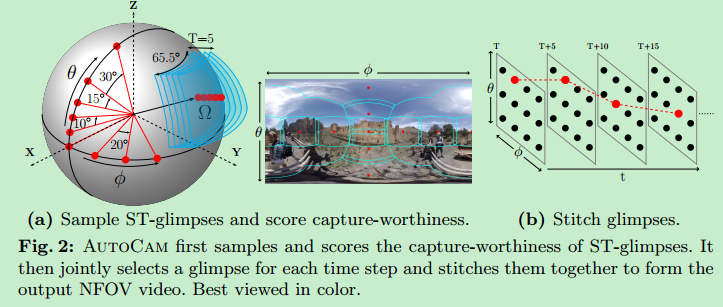
这里水平角度65.5°,NFOV视频的宽高比4:3
生成的看起来自然的NFOV视频应该是无法从人捕捉的NFOV视频相区分的
相机不允许跳跃和缩放
用c3d(convolutional 3d feature)提取特征
最优化轨迹的解决方法是离散的,也就是每5s从一个方向跳到另一个方向(jump)
为了平滑这些跳跃,对离散的轨迹进行线性插值,所以最后输出的轨迹是连续的
是离线的方法,需要先看完整个视频
ST-glimpse:五秒的固定相机方向的从360°视频记录的NFOV视频片段(如图2a所示),这些玩意在等矩形投影上不是矩形的(如图2a右图所示),所以在投到NFOV视频时需要处理
我们从以下角度采样了候选的ST-glimpse:Φ={0,20,40,...,340},Θ={0,+-10,+-20,+-30,+-45,+-75,},间隔为5s
从HumanCam数据学习如何为捕获价值打分,我们希望捕获价值依赖内容和组成两个方面(内容要自然多样,例如一个爬山的视频中既要捕获同行的伙伴也要捕获美丽的风景;组成:对于人脸而言只捕捉到下半部分是不够的,应该捕捉全脸,对于户外场景来说应该把地平线放在这一帧的中间)
AUTOCAM学习到一个数据驱动的模型而不是通过规则定义捕获的重要程度。我们做出了如下假设:1.人相机拍摄的NFOV视频里大多数的内容是值得捕获的;2.大多数随机的ST-glimpses是不值得捕获的
基于上述假设训练捕获价值分类器:
首先将所有人类相机拍摄的视频分成不重叠的5秒片段当做正样例(根据假设1)。接着所有从360°视频提取出来的候选ST-glimpses当做负样例(根据假设2)
为了表示每个ST-glimpse和5s的人类相机拍摄的视频片段,我们使用现成的卷积3d特征(convolutional 3D features (C3D))。C3D是基于可以捕获外观和运动信息的3d(空间+时间)卷积的通用视频特征
在获得了所有ST-glimpses的捕获价值分数后我们找一条最大化总的捕获价值分数的相机移动路径(找路径的同时生成了像人一样的平滑的相机运动)
在选路径的时候引入了平滑运动先验使相机的轨迹更加平滑(选择的ST-glimpse的方位角和角度不超过30°)
评价NFOV视频的两种标准:
1.基于人相机的度量:
越像人相机拍出来的视频,算法越好
2.基于人编辑的度量:
算法选择的相机轨迹要接近人选择的轨迹(HumanEdit)
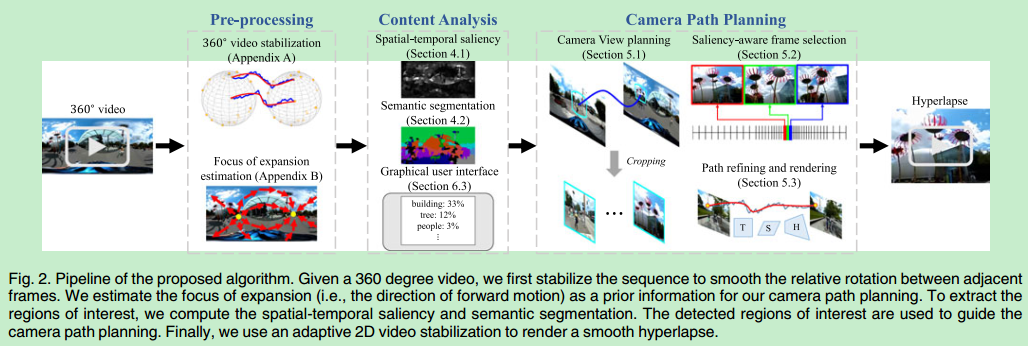
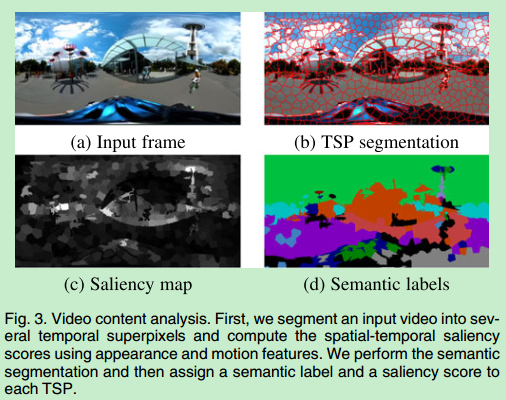
Semantic-Driven Generation of Hyperlapse from 360 Degree Video


vedio
hyperlapse(快进视频)
一个将整个360全景图转化为NFOV(normal field-of-view)快进视频的带有最优视觉体验的系统
首先稳定输入的360度视频,然后计算每个区域兴趣和显著性的得分,在此基础上生成快进视频,最后再用2d视频稳定方法生成最后的快进视频
用到了场景语义分割
显著性的计算根据物体的运动和外观
用户可以选择输出视频的播放速率,并标出自己感兴趣的物体
系统会计算最优的时空上的相机路径(结合显著性的分,语义偏好和时间平滑)
意义:
替用户找到有意思的内容,缩短看视频的时间
贡献:
第一个从360度视频生成NFOV快进视频的系统
提出了利用时间和空间上的非均匀采样最优化平移感兴趣物体上窗口的语义驱动的方法
提出了鲁棒的2d稳定方法自适应地选择运动模型生成平滑的快进视频
与其它方法的比较:
Pano2Vid是从预计算的时间空间划分中学习捕捉重要性得分并用dp选择平滑的相机路径
我们的方法:
1.给定360°视频,我们生成的是快进视频,Pano2Vid生成的是与输入视频等长的视频
2.Pano2Vid用整个视频内容来学习得分,我们是结合了低等级的时空视觉显著性和高等级的图像语义分割来检测关键区域或物体,并且为使用者提供了更多的操作空间(选择感兴趣的语义标签)定制快进视频
3.我们的相机运动可以向前、平面移动和加速,而向前移动在Pano2Vid中是没有的
4.我们给视频添加了稳定操作而Pano2Vid没有
Self-View Grounding Given a Narrated 360° Video

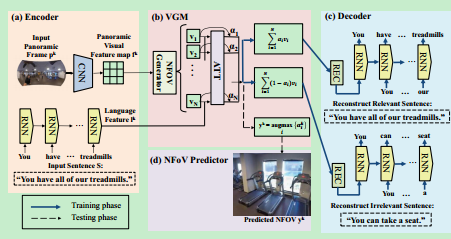
从全景视频中生成NFoV并为每一帧配上对应文字描述
Motion parallax for 360◦ RGBD video(源码暂未公布)


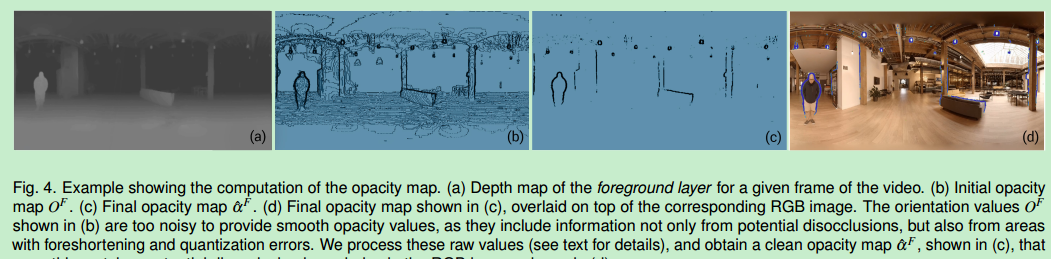
disocclusion(遮挡图像的去除)
一种在虚拟现实头显为360°视频添加视差和实时回放的方法
背景:
现有的视频回放不能响应用户头部的平移运动,可能会给用户带来模拟器病的困扰
给定360°视频以及它对应的深度,简单的基于图像的渲染方法使用深度生成3d网格,可以相应用户头部平移。然而这种方法有看得见的扭曲以及使网格不连续
解决方案:
从输入的视频获得深度图(由现有的360缝合算法或现成的深度学习算法提供)
将给定的初始深度图改进为更干净的和自然的轮廓
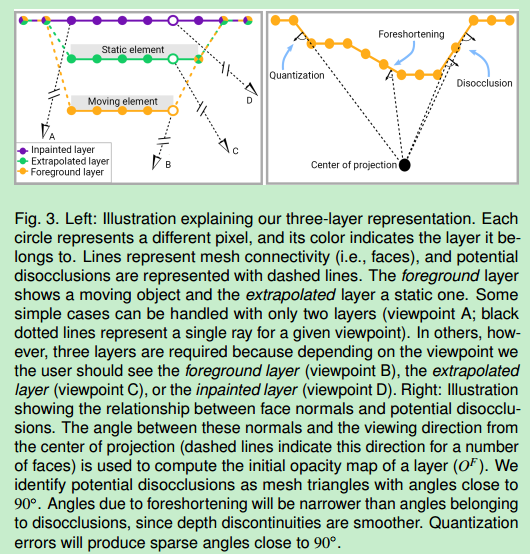
依赖三层场景表示(一个前景层和两个静态背景层)
输入的视频+深度作为前景层
一个背景层表示遮挡物
另一个背景层表示遮挡物后面的背景
从第一个背景层的多帧传播信息处理不一致性,再用图像修复方法修复第二个背景层
输入的rgb360°视频每个像素都有一个深度值
先对视频预处理使得它适合重投影
最基本的重投影是将输入视频转化到球形三角网格上,将每个带rgb值的像素转移到顶点上,3d位置由深度图决定(输入视频分辨率为1024X2048则顶点数也为1024X2048),于是在观看者移动头的时候网格就能被实时渲染了
然而上述基本的重投影方式在空洞边界产生了看得见的失真效果(如图1A所示),因为观看者移动头的时候网格将前景元素和背景元素的边界不正确的连接在一起
为了解决这个问题,需要根据深度的不同识别空洞边界(disocclusion boundaries),然后弄断这些边界(这样做会造成锯齿剪影边界或者由于深度图上边界估计不准确丢失信息如图1B所示)
我们的场景表示法是分层的,用来表示带有干净空洞边界的物体剪影的rgbd视频(尽量用原来的视频渲染而不是将物体分到不同的层中)
一共有三层:一个动态前景层和两个静态背景层
前景层是由rgb视频和相关的深度生成的网格并带有每一帧的不透明贴图(opacity map)用来控制空洞边界的不透明度,所以这层有有rgb视频、深度视频和不透明贴图视频
两个静态层:推算层和修复层(extrapolated layer和 inpainted layer)用来填补观看者运动头部产生运动视差时暴露的空洞
推算层包含有时被移动物体遮挡的静态背景区域信息(所以能直接通过背景消除法(background subtraction)得出),它也有不透明贴图控制空洞发生时该网格的透明度,所以存rgba图和深度图
修复层包含填补被静态背景区域遮挡的静态物体区域的信息(从来没有被相机观察到的信息,并且由图像修复技术(inpainting)计算出来),因为它是最远层,所以没有不透明贴图,只有rgb图和深度图
只要观看者的头不做平移运动就只能看到前景层
空洞的边缘应该是网格上法向量与从投影中心观看方向成直角的部分
贡献:
为现有的360°视频提供了6自由度的观看体验(不需要新的捕捉和硬件要求)
不足之处:
假定拍摄时的相机是静止的,我们未来将要解决移动相机的情况(更多的存储空间和带宽)
理论上根据场景的复杂度可以拥有更多的层(不止三层),然而需要更多地存储空间和处理要求
观察者头部移动的距离与原始相机的距离越远误差越大
因为全方位立体的格式问题,靠近两极的深度信息不是很准确,所以在这两个区域的表现不是很好(然而这些区域是很少被观察到的)
如何理解 Graph Convolutional Network(GCN)?
RNN
360Vedio To NFOV Vedio的更多相关文章
- Load Audio or Vedio files
//Load Audio or Vedio files private void btnLoadFile_Click(object sender, EventArgs e) { Startindex ...
- 关于移动端开发,vedio标签层级高遮挡蒙版的解决方案
问题描述: 使用famework7框架搭建了一个界面,然后再界面中需要使用蒙版效果,在PC端,ios测试没有问题,在Andriod播放视屏再点击显示蒙版的效果师,视频会遮盖蒙版.修改定位,z-inde ...
- 20190325-HTML框架、audio标签、vedio标签、source标签、HTML表单
目录 1.HTML框架 frameset:框架标记 frame:框架内文件 iframe:内嵌框架 2.audio标签 src:URL(可以用source标签替代) autoplay:自动播放 pre ...
- 大数据-将MP3保存到数据库并读取出来《黑马程序员_超全面的JavaWeb视频教程vedio》day17
黑马程序员_超全面的JavaWeb视频教程vedio\黑马程序员_超全面的JavaWeb教程-源码笔记\JavaWeb视频教程_day17-资料源码\day17_code\day17_1\ 大数据 目 ...
- HTML5(Canvas Vedio Audio 拖动)
1.Canvas (在画布上(Canvas)画一个红色矩形,渐变矩形,彩色矩形,和一些彩色的文字) HTML5 元素用于图形的绘制,通过脚本 (通常是JavaScript)来完成. 标签只是图形 ...
- java 断点续传(springMvc),可支持html5 vedio在线播放 posted @ 2017年3月11日 16:15:44
Controller @RequestMapping(value = "/getVedio") public void getVedio(HttpServletRequest re ...
- html5 vedio 播放器,禁掉进度条快进快退事件
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- EL表达式 EL函数 自定义el函数 《黑马程序员_超全面的JavaWeb视频教程vedio》
\JavaWeb视频教程_day12_自定义标签JSTL标签库,java web之设计模式\day12_avi\12.EL入门.avi; EL表达式 1. EL是JSP内置的表达式语言! * jsp2 ...
- Ajax 及里面的XStream《黑马程序员_超全面的JavaWeb视频教程vedio》
1. ajax是什么? * asynchronous javascript and xml:异步的js和xml * 它能使用js访问服务器,而且是异步访问! * 服务器给客户端的响应一般是整个页面,一 ...
随机推荐
- SCP命令小例子
磨砺技术珠矶,践行数据之道,追求卓越价值 回到上一级页面: PostgreSQL杂记页 回到顶级页面:PostgreSQL索引页 [作者 高健@博客园 luckyjackgao@gmail. ...
- mfc 函数模板
函数模板的使用 一. 函数模板的使用 使用函数模板可以简化 形参个数相同,而类型不同的函数. template<typename T> //可以用class替换typename int m ...
- 【BZOJ1047】[HAOI2007]理想的正方形
[BZOJ1047][HAOI2007]理想的正方形 题面 bzoj 洛谷 题解 二维\(st\)表,代码是以前的 #include<iostream> #include<cstdi ...
- com.jcraft.jsch.JSchException: java.io.FileNotFoundException: file:\D:\development\ideaProjects\salary-card\target\salary-card-0.0.1-SNAPSHOT.jar!\BOOT-INF\classes!\keystore\login_id_rsa 资源未找到
com.jcraft.jsch.JSchException: java.io.FileNotFoundException: file:\D:\development\ideaProjects\sala ...
- <link rel="stylesheet" type="text/css" href="css/index.css">详解
整条语句的含义是: 调用一个外部的CSS样式文件.他是通过<link/>这个标签来调用的. 然后, href="css/index.css" 表示外部样式文件的路径, ...
- JavaScript验证时间格式
1. 短时间,形如 (13:04:06) function isTime(str) { var a = str.match(/^(\d{1,2})(:)?(\d{1,2})\2(\d{1,2})$/) ...
- 2018年美国大学生数学建模竞赛(MCM/ICM) 比赛心得
话不多说,题目先上: 这是我们这次选择的题目,说说建模的那些事! 美赛的时间和国赛挑战杯时间略有不同,貌似多的一天是为了让我们对文章进行一个翻译吧QAQ 建议参加美赛的同学可以参照此计划进行 Day0 ...
- 写个hello world了解Rxjava
目录 什么是Rxjava? 在微服务中的优点 上手使用 引入依赖 浅谈分析Rxjava中的被观察者,观察者 spring boot 项目中使用Rxjava2 什么是Rxjava? 来自百度百科的解释 ...
- Linux下的man page使用守则
文章链接:https://blog.csdn.net/qq_38646470/article/details/80147650
- 自动化jenkins报:ModuleNotFoundError: No module named 'common'
直接执行脚本是没有问题,报如下错误: 你已经在run.py脚本加路径了为什么还会报这个错呢,就是你加的路径,应该在所有的包上面,才不会报这个错,如下: 注:以下是我的解决方法仅作参考.如果我的发表的内 ...