Hadoop基础原理
Hadoop基础原理
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
业内有这么一句话说:云计算可能改变了整个传统IT产业的基础架构,而大数据处理,尤其像Hadoop组件这样的技术出现,将是改变IT业务模式的一种技术。
另外,很多小伙伴可能还搞不明白云和Hadoop有什么关系,事实上这是两种截然不同的技术。虽然从某种意义上来讲,他们都是在大规模的计算机集群上来完成的。但是openstack或其它的paas或sas的云环境,他们所指的是所谓的云计算的方式,通常是来讲是用于指定如何将用户本地完成的运算迁移到云上去,让用户无需得知其计算能力,存储能力等各种能力来自任何一个地方的机制。
一.数据的存储方式(就是对数据的建模)
1>.结构化数据:
即行数据,存储在数据库中,用二维表来存储的数据。
2>.非结构化数据:
难以使用数据库二维表来存储的数据,如文档,图片等,字段可变,字段内容可变或不可变组成的。
3>.半结构化数据:
能够实现自我描述的数据,将结构和数据本身混在一起,xml,json,html。
二.Hadoop的由来
1>.GFS文件系统诞生
2003年,The Google File System(简称GFS)诞生了,GFS采取了数据块的方式管理数据,将一个单独的大文件切割成N个指定的小片段,而后在每个节点上存储单个片段并且通过在集群中的多个节点上存储同一个数据块的多份冗余副本以实现容灾的功能。站在这个角度来讲,GFS的设计主要是用来支持大规模数据密集型的分布式应用程序的运行。存储过程如下图:
2>..MapReduce相继开源
继2003发布GFS文件系统开源后,2004年又发表了关于MapReduce的文章,即Simplify Data Processing On Large Clusters。MapReduce定义了一种编程模型及其运行框架,它提供了集中的多个节点上自动并行容错及可处理TB规模数据,甚至能够达到PB规模的数据处理平台。事实上MapReduce是GFS集群的组成部分,他要工作在GFS的基础之上才能够完成处理操作的。因此MapReduce与GFS一同构成了所谓的大数据存储及并行处理平台。

MapReduce的特性:
a>.向外扩展;
b>.假设故障常见,自我完成数据冗余,并自我完成故障处理;
c>.将程序移向数据;
d>.顺序处理数据,并避免随机访问;
e>.向程序员隐藏系统级别的细节;
f>.实现平滑扩展;
3>.Nutch搜索平台诞生
该搜索引擎用Java语言编写而成,该搜索引擎在工作一段时间后,作者发现了一个难题,这个搜索引擎爬来的数据难以有效存储,在小规模存储中还能正常应用,但是到大规模应用该存储的很让然头疼了,正在为这个问题发愁时,作者看到了Google公司公开的论文,也就是上面我们介绍的GFS文件系统,作者看到之后如获至宝。因此作者倾注了心血在Nutch搜索引擎的应用,于是在Google的GFS基础上,山寨出来了一个DFS和MapReduce平台。后来作者看见他的还在在玩一个玩具象,给其平台取名为Hadoop。
Hadoop完全由Java语言实现的DFS和MapReduce。由于DFS是分布式文件系统的统称,回来干脆取Hadoop首字母,称之为HDFS,因此我们可以说Hadoop是由HDFS和MapReduce组成。所以Hadoop在某种意义上来讲,就是Google处理平台的山寨版本,当然我更喜欢称它开源实现。比较有意思的是整个程序都是由Java语言编写的,因此HDFS和MapReduce都要依赖JDK才能跑起来。换句话说,MapReduce的原生接口就是由Java实现的,所以我们要在他的MapReduce框架上去写MapReduce程序的话,很显然Java是首选语言哟!
4>.Hadoop的应用平台
当我们把一个Hadoop集群构建出来之后,将来是要在该集群上跑上面任务呢?当然我们不是为了在这个平台上跑一些单词统计(wordCount)程序,而是跑一些有意义的事情,比如对日志进行分析等等。要怎么对这些日志进行处理呢?此时就需要Hadoop程序员来研发MapReduce程序了。
因此Hadoop的应用平台主要有两个层次,即Hadoop运维和Hadoop开发工程师,而后者的需求量是远远大于前者的。而安装Hadoop服务对运维而言自然是小菜一碟啦,如果对Java本身进行研究的话,运维还得对JDK进行优化,这样可以保证Java程序跑的更灵活。Hadoop运维就是无非就是对其进行优化的(后期我会写一片关于Hadoop运维的技能)而真正更多的需求就是在运维搭建好的Hadoop环境上跑一个个的特定任务。
Hadoop本身还只是一个基础框架。收集数据并存放在Hadoop中的HDFS中就是一个难题。另外,我们传统意义上的很多数据早起是存在数据库中的,如果我们想要用Hadoop对数据库里面的数据进行处理,那么就需要一个ETL工具,来帮我们实现收集数据,转换和装载。
一个公司Hadoop集群若只是不熟在三四十台服务器上,我们称之为入门级应用。一百台两百台服务器都不好意思说是Hadoop集群的,据说腾讯和淘宝他们单一的Hadoop集群在4000个节点左右。
Hadoop不建议跑在虚拟机上的,因此Hadoop和openstack结合使用还是很少见的!因为Hadoop对磁盘的IO要求是相当的高的,若你用虚拟机进行存储性能上得打上一个大大的问号!
三.开源大数据处理平台开源解决方案

四.HDFS各节点详解

1>.NameNode
HDFS的名称节点,在内存中保存所有文件的元数据,因此任何客户端想要获取文件时,要到namenode节点上来获取该文件的元数据信息。所以我们文件想外展示时是单个文件但却可以分割起来进行存储的。所谓的元数据,咱们可以理解为NameNode的文件名称空间。对于分布式文件系统来讲,从分布式文件访问的入口开始被称为分布式文件系统的根,在跟目录下可以存放文件或者子目录。要注意的是,这里的文件或子目录并不是保存真正的数据,而是存放的是路径映射。在各个路径映射下有不同的文件,每个文件可以被分割成了多个数据块,每个块默认最少有三个副本,这三个副本分别位于不同的DataNode节点上,这些信息都记录在NameNode服务器中。
2>.SecondaryNameNode
为了保证NameNode的可用性,最简答的方式就是将名称节点上的持久元数据信息实时存储多个副本于不同的存储设备中,或者是提供第二名称节点,即Secondary NameNode。
第二名称节点并不真正扮演名称节点角色,它的主要认识是周期性地将编译日志合并至名称空间镜像文件中以免编译日志变得过大;它运行在一个独立的物理主机上,并需要跟名称节点同样大的内存资源来完成文件合并;另外,它还保存一份名称空间镜像的副本;然而,根据其工作机制可知,第二名称节点要滞后与主节点,因此名称节点故障时,部分数据丢失仍然不可避免。
综上所述,大家应该很清楚的知道NameNode是整个HDFS文件系统的关键入口,它很有可能出现单点故障,为了避免这种情况(NameNode服务器过长时间宕机),就有了另外一个离线冗余备份,即SecondaryNameNode。辅助NameNode节点(即SecondaryNameNode)会帮助NameNode不断去合并内存中所谓元数据的映像信息,简单的来讲,就是对文件的删除,修改,创建等不断修改元数据的操作获取到本地进行持久化存储(你也可以理解是SecondaryNameNode得到了一个离线的副本),当NameNode宕机以后,SecondaryNameNode可以替换成之前的NameNode,只不过这个提升过程是相当漫长的(可能要20~30分钟不等)。因为当NameNode宕机后,各种元数据必须要在指定时间内收到各个DataNode对于其所持有的数据模块的报告并最终汇总到本地真正去获取到每一个数据的副本信息以后才可以完成替换NameNode流程。
3>.HDFS的Client(Hadoop的API)
那么客户端是如何跟我们的HDFS进行交互呢?很显然他们之间交互是要基于HDFS自带的API进行的。HDFS的Client到NameNode获取元数据,在得到元数据之后,元数据的节点会告诉Client其想要访问文件被分割成了多少个块,以及每个块都在哪个DataNode服务器上存储着,这个时候Client再去相应的DataNode服务器上拿数据。也就是说Client不仅要和NameNode打交道,还要跟DataNode打交道。换句话说,Client存储和读取数据都是Client自我直接实现的。
4>.DataNode
负责存储真实数据。
5>.HDFS故障分类
a>.Namenode故障
如果NameNode故障发生时,这就意味着整个集群挂掉了,因此我们可以说NameNode是整个集群的单点故障所在。
b>.网络故障
为了避免网络故障,每次发送数据包报文时,我们的DataNode服务器都需要做确认的,若没有收到DataNode服务器的确认信息,我们就可以认为其可能存在故障。因此他们传输数据是可靠的,是基于TCP这种协议进行传输的。
c>.数据节点故障
事实上,每个DataNode每隔三秒钟就会向NameNode发送自己的心跳信息(还要报告其存放的数据块列表的相关信息),目的是告诉NameNode服务器当前的DataNode依然是存活状态,也就是正常工作状态。当NameNode在一段时间内(默认是10分钟)一直没有收到某个DataNode的心跳信息, 那么NameNode就任务该DataNode已经挂掉了,并将之前存在该DataNode服务器上的数据重写在其它节点中重写拷贝一份。
d>.数据故障
每个数据块在发送数据给接收端时,会将该数据块的校验码一起发送给接收端,接收端接受数据后会重写生成校验码并与发送端发来的校验码进行比较,若两个校验码一致则说明数据是完整的,否则接收端会认为该数据块是损坏的。DataNode节点除了想NameNode发送心跳信息外,还要定期的发送其存放的数据块列表信息,当发现自己存放的数据块是损坏的时候,并不会将该损坏的数据块加入在列表中发送给NameNode,而是将完整的数据块发送给NameNode,NameNode服务器会定期整理所有的DataNode发来的数据列表信息,当发现有的数据块存储不足指定的份数(默认是3份)时,NameNode会自动新生成相应的份数进行备份。
6>.HDFS的机架感知
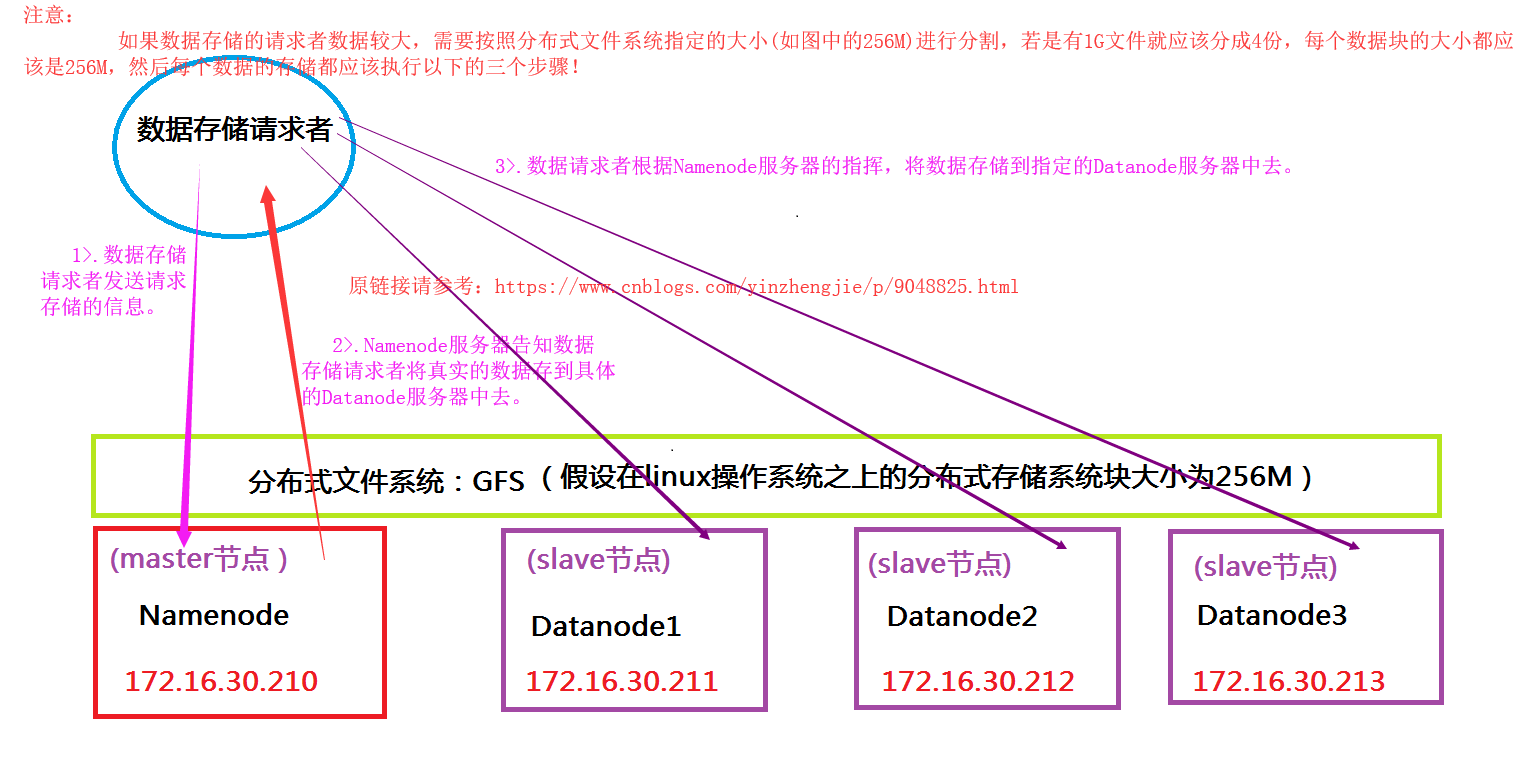
我们知道Hadoop默认会将每个数据块复制三分。如果想往HDFS分布式文件系统中写数据,而写需要写的客户端恰好也是DateNode,那么这台服务器就优先被存放为第一份副本的存放位置,否则的话就从众多的DataNode中随机挑选一个存放副本(假设数据要保留三份,当第一台DataNode存入数据时,并不会等到其将数据第一份数据存储完毕,于是同时,会自动向第二台服务器上拷贝数据进行备份,而第二台服务器也不会等到数据拷贝完毕,而是继续拷贝到其它节点中去,我们称之为管线操作(英文:Pipe Line))。而剩下的两份数据应该存放在不同的机架上或者是相邻机架的两台服务器中,也就是说同一个机架上要求最多存放两个副本。(我大胆猜测设计者是为了方式一个机柜断电时,DateNode访问不到情况。)当然,具体如何存储还是靠我们手动配置,如果你非要放在同一个机柜上谁也那你没辙。详情请参考:“http://hadoop.apache.org/docs/r2.7.3/hadoop-project-dist/hadoop-common/RackAwareness.html”
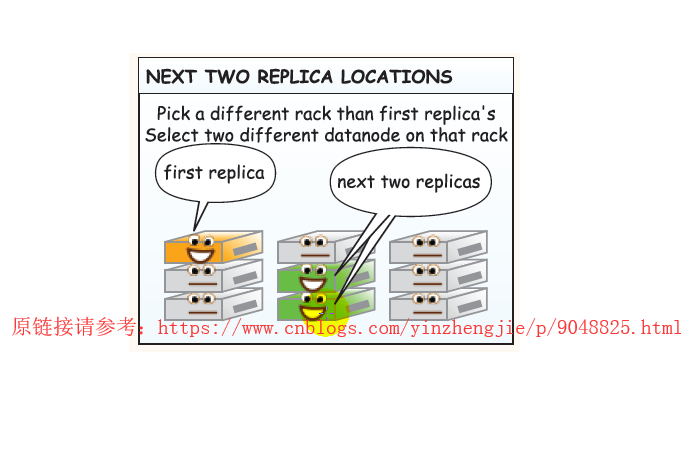
7>.向HDFS文件系统保存数据
上图链接所画的链接工具为JVM,实际上HDFS的API已经支持不同的编程语言了,我们可以用不仅仅可以用Java,还可以用我们运维拿手的编程语言Python或者是shell进行编程哟。
五.MapReduce详解
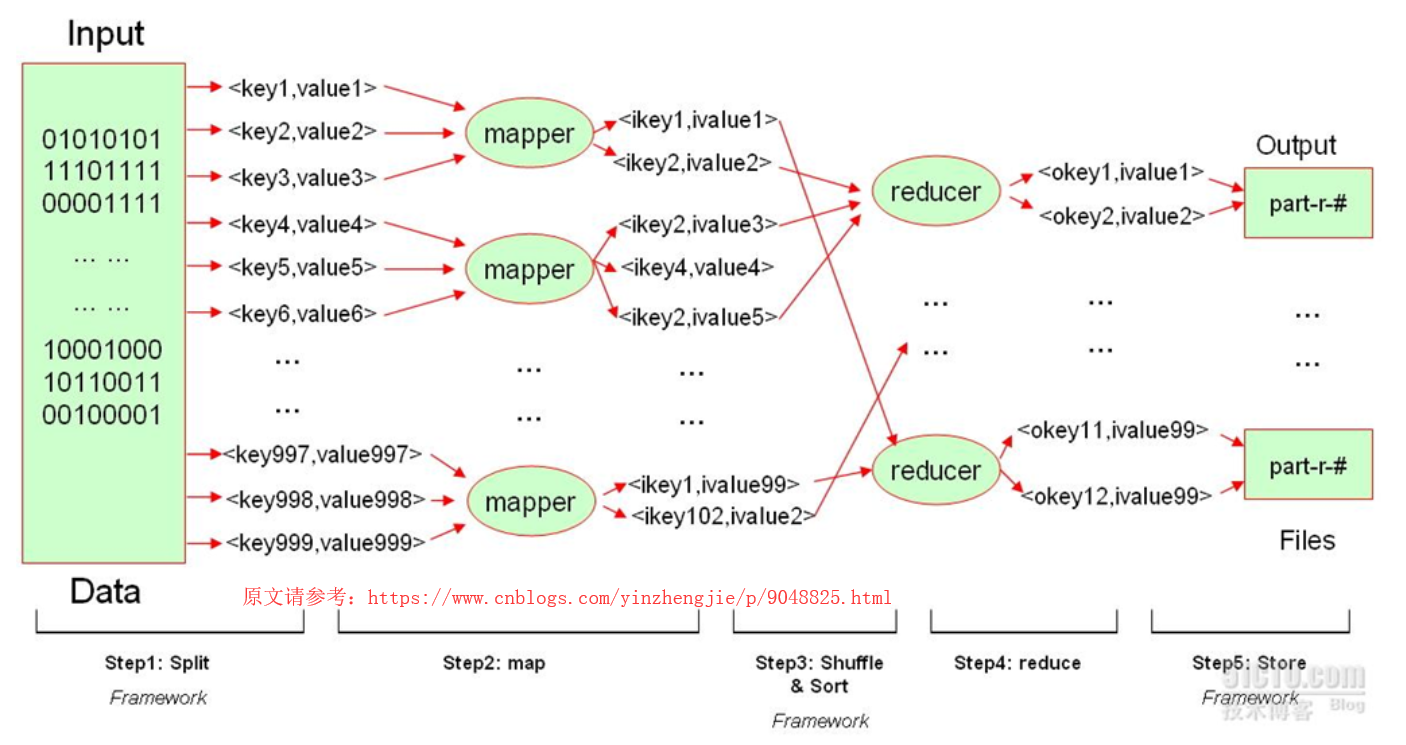
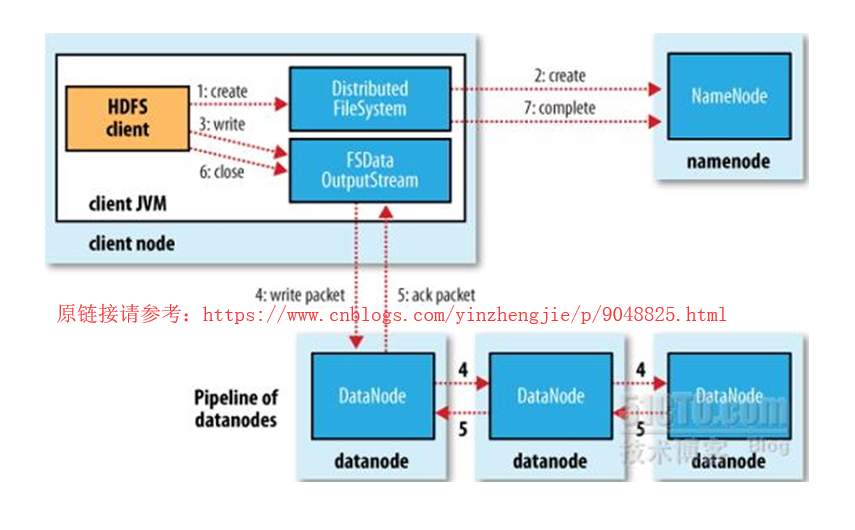
1>.Hadoop的MapReduce的工作流程
结合上图来看,说明Hadoop的MapReduce所能处理的数据仅简单的键值数据,Hadoop的MapReduce的工作流程大致分为五个步骤:
a>.Split
我们知道我们写的MapReduce任务主要是用来处理文件的,这个文件的输入(Input)有可能是来自某个DataNode的一个数据块而已,也有可能是来自多个不同的DataNode的多个数据副本(注意:这些副本是指的是不同的数据哟)。而这些数据块未必就是键值数据(比如日志文件),由于Hadoop是无法处理非键值数据的,我们必须要把数据做成模型化,把一些杂乱无章的非结构化数据抽取成键值数据对。这个时候就需要MapReduce提供一个Split程序(这个程序可以是程序员自己编写),这个split程序能够将文件中的每一个数据按照用户所指定的标准给它切割成理想的键值对(如上图:<key1,value1>),并将切割后的键值对发送给第二阶段的mapper任务(maper worker,即map工作进程)。【我们以Wordcount为例,此时Split切割的方式就是将文件的行号作为键,将每行的内容作为值,并发送给map程序】
b>.map
map的工作进程(mapper)在收到工作进程以后,会对其做进一步处理,在处理结束之后,形成另外一个键值对(如上图:<ikey1,ivalue1>),新生成的键值对是可以让reduce程序进行折叠的!【我们仍然一Wordcount为例,Split程序发来行号和行号对应的数据,mapper接受后,会将Split的结果的每个单词切割好的单词取出来作为key,并对其每个单词赋初始值为1。】需要注意的是,map的数据量如果非常大的话,会临时将数据保存到当前节点的临时目录中生成临时文件,当所有的mapper都处理完任务时,才会将数据发送给reduce。
c>.Shuffle & Sort
map的工作进程mapper将数据发送给reduce之前,会进行排序操作,并将排序的结果发送给reducer。【由MapReduce框架(framework)决策将相应的key发送给具体的reducer】
d>.reduce
一个reduce可以处理多个键,它所处理的每一个键对应的所有数据都必须由这个reduce来处理,它可以根据键对每个数据进行折叠。【我们还是以Wordcount为例,把同一个单词出现的次数都交给同一个reducer,此时reducer就会将这些key做一个聚合,就是将将多个相同的key合并成同一个key,然后把每一个key的value进行累加操作,最终多个reducer将处理的结果进行存储】
e>.Store
多个reducer处理的结果整合到一起,就是Input数据中每个单词出现的频次,最终结果默认会存入到HDFS系统中。如果处理的文件较小的话我们也可以存入到本地哟。
2>.单reduce任务的MapReduce数据流(此图摘自“Hadoop权威指南")
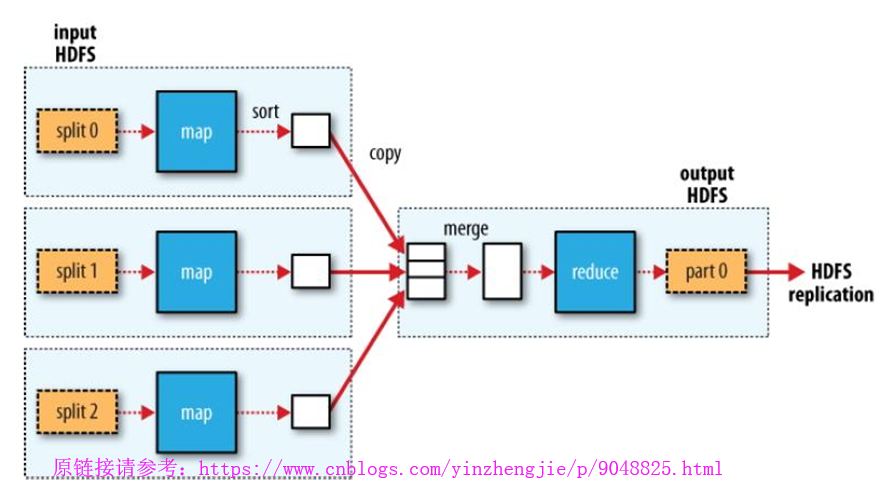
我们来阐述一下单reduce任务的MapReduce数据流处理过程,如上图所示:
a>.Split程序将数据切割成三分,分别发送给3个map去处理;
b>.map将数据处理的数据临时存在本地,等到map程序执行完毕后,在对这些临时数据进行排序并发送给reduce;
c>.此图只有一个reduce,因此它拿到了所有的键值对,这个时候由它执行merge操作,将多个重复的key进行聚合并排序,再由reduce进行折叠,折叠后的数据结果就只有一份,因为reduce就只有一个,而后数据保存在HDFS文件系统之上;
d>.将数据存放在HDFS之后,需要执行replication来保存多个副本。
3>.多reduce任务的MapReduce数据流(此图摘自“Hadoop权威指南")
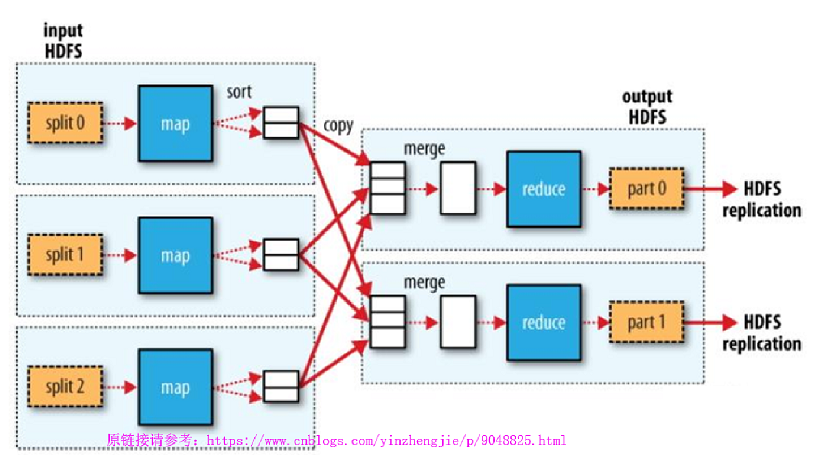
我们来阐述一下多reduce任务的MapReduce数据流处理过程,如上图所示:
a>.Split程序将数据切割成三分,分别发送给3个map去处理;
b>.map将数据处理的数据临时存在本地,等到map程序执行完毕后,在对这些临时数据进行排序(排序可以让相同的键都相邻)并把相同的键发给同一个reduce;
c>.在数据发送给reduce之前,数据需要进行merge操作(这里的merge仅是指的的将数据流进行合并成单独的一个流);,
d>.数据在本地完成merge操作之后,会将结果发送给reduce,由reduce完成折叠操作,即将重复的key进行合并,每个reduce处理的结果手动合并起来就是最终的结果(结合上图来看的话,“part 0”和“part 1”就是两个reduce的输出结果);
4>.没有reducer的MapReduce作业(此图摘自“Hadoop权威指南")
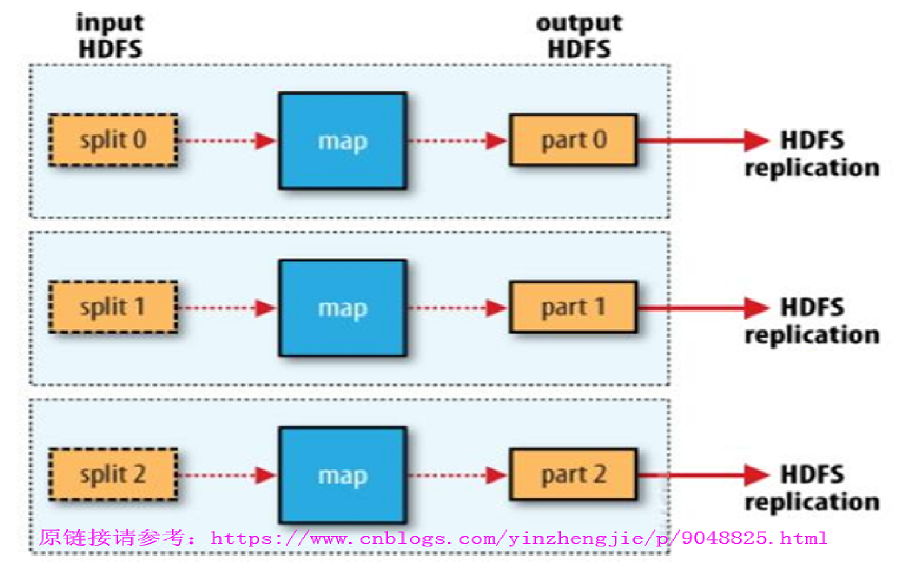
事实上,我们的作业完全可以没有reduce,如上图所示:
如果我们map输出的结果本身已经就是最终结果的话,就无效reduce再次处理,大家应该都知道reduce的主要目的就是将相同的key折叠起来,若map处理后的结果本身就无序折叠的话就完全没有必要在执行reduce任务啦!因此我们可以说在MapReduce程序中,可以没有reduce,单必须得有map程序。
5>.MapReduce客户端提交一个作业

接下来我们阐述一下MapReduce客户端提交一个作业的过程:
a>.MapReduce的客户端提交一个作业请求(这客户端可以是一个开发人员针对MapReduce的maste的API发起的作业请求);
b>.MapReduce在拿到作业后,会将这个作业分割成多个小作业去执行。如上图所示,master将任务分为两个部分,一部分是map作业,另一部分是reduce作业,由MapReduce的master决定map运行在哪个物理节点上,在map启动后不久就要启动reduce,这些操作都是由MapReduce来调度的;
c>.接下来的处理过程请参考上面的“多reduce任务的MapReduce数据流”。
6>.MapReduce逻辑架构

通过上图可以看出,我们可以了解到MapReduce的逻辑架构:
a>.同一个集群内部,可以同时运行N个作业的,这些N个作业可能提前完成任务,那么就会腾出空间来让master调度执行下一个作业;
b>.当任何一个作业提交结束了,提交完成之后,他就成了历史列表中的历史作业,如上图的“Historical jobs”;
c>."job Tracker"在接受到每一个作业之后,就要把作业本身完成分割而后将其发送至各“task Tracker”给予运行的;
d>.如果是非常繁忙的Hadoop集群的话,很有可能整个集群的所有的物理节点都比较繁忙,而对于Hadoop来说,无论是对于IO资源(磁盘I/O和网络带宽)的占用还是对CPU资源的占用都很密集,因此,Hadoop集群很少运行在虚拟环境中的。
7>.partitioner和combiner(下图摘自互联网)

在了解基本的MapReduce的宏观框架之后,我们可以结合上图来了解MapReduce的微观框架:
a>.Combiner是MapReduce的一种优化机制,它的主要功能是在“shuffle and sort”之前先在本地将中间键值对进行聚合,以减少在网络上发送的中间键值对数据量。因此可以把combiner视作在“shuffle and sort”阶段之前对mapper的输出结果所进行聚合操作的“mini-reducer”。在实现中,各combiner之间的操作是隔离的,因此,它不会涉及到其它mapper的数据结果。需要注意的是,就算是某combiner可以有机会处理某键相关的所有中间数据,也不能将其视作reducer的替代品,因为combiner输出的键值对类型必须要与mapper输出的键值对类型相同。无论如何,combiner的恰当应用将有机会有效提高作业的性能。简单的来说,combiner的主要作用就是在各mapper程序执行完毕之后,可以将相同的key进行本地合并,这样就可以避免本地的同一个key进行多次发送的情况,从而达到节省网络带宽的目的(从上图可知,combiner只能做简单的合并操作,并不能实现折叠的功能,它的读入和输出的数据类型都是一致的);
b>.Partitioner负责分割中间键值对数据的键空间(即前面所谓的“分组”),并将中间分割后的中间键值对发往对应的reducer,也即partitioner负责完成为一个中间键值对指派一个reducer。最简单的partitioner实现是将键的hash码对reducer进行取余计算,并将其发往余数对应编号的reducer,这可以尽力保证每个reducer得到的键值对数目大体上是相同的。不过,由于partitioner仅考虑键而不考虑“值”,因此,发往每个reducer的键值对在键数目上的近似未必意味着数据量的近似。简单的来说,partitioner的主要作用就是将各mapper输出的键值对在“shuffle & sort”完成之后,将不同的键值对进行分离操作,将分离后的同一个键值对发送同一个reducer的作用,partitioner也是可以程序员自己开发的,简单的来说,partitioner就是传输功能;
c>.partiontioner和combiner只是MapReduce的两个组件,combiner和partitioner并不一定要存在,如果没有它们的话,他们的任务都会被堆积到reduce,让reduce执行combiner和partitioner的操作。
8>.Hadoop的小缺陷
各位要注意的是,有些任务非常复杂,它可能需要N轮的MapReduce处理,即第一轮MapReduce处理的结果会调用第二次MapReduce,第二次的MapReduce结果继续调用第三次的MapReduce等等,只不过每一轮所需要运行的程序可能各不一样。比如分析淘宝网站的日志,分析出来自哪个区域访问量最大,统计出北京,上海,深圳,西安,天津的访问量。如果每轮MapReduce处理结果需要等待两天时间,那么要把整个任务执行完毕估计就一个星期之后了,这个分析的结果并不是实时的,就无法提供有效的数据支持了。这也是Hadoop为人诟病的主要原因。
Hadoop还有一个缺陷,HDFS设计用来存储单个大文件的,但事实上很多时候很多的数据都是很短小的数据信息,比如我们想把日志信息实时的收集过来,若我们有100多万台服务器,每一万台服务器产生一行日志,此时每一行的数据你有打算怎么存储呢?因此,Hadoop仅适用于存储批量的,单个大文件,HDFS仅适于处理流式数据,不支持随机模式的数据访问,如果想要存储类似于数据库中存的一行短小的数据信息的话(或者是随机性数据),HDFS就特别的不适用。这个时候HBase就出现了。
六.Yarn(资源管理系统)
Yarn是Hadoop2.0新增的系统,负责集群的资源管理和调度,使得多种计算框架可以运行在一个集群中。Apache Hadoop YARN (Yet Another Resource Negotiator,另一种资源协调者)是一种新的 Hadoop 资源管理器,它是一个通用资源管理系统,可为上层应用提供统一的资源管理和调度,它的引入为集群在利用率、资源统一管理和数据共享等方面带来了巨大好处。
详情请参考:https://baike.baidu.com/item/yarn
七.HBase
1>.什么是HBase
我们知道HDFS很难实现随机数据处理的,因此我们要引入HBase。它也是一个HBase是一个分布式的、面向列的开源数据库,该技术来源于 Fay Chang 所撰写的Google论文“Bigtable:一个结构化数据的分布式存储系统”。就像Bigtable利用了Google文件系统(File System)所提供的分布式数据存储一样,HBase在Hadoop之上提供了类似于Bigtable的能力。HBase是Apache的Hadoop项目的子项目。HBase不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。另一个不同的是HBase基于列的而不是基于行的模式。
HBase可以单机运行,但是它的冗余能力就没法保证了,因此HBase最好的工作方式还是在Hadoop集群上工作。
2>.HBase的组成

a>.Master
我们知道HBase也是一个分布式系统,这个分布式系统也是有个主从节点组成的,只不过它的主节点叫做HMaster,它的从节点叫做HRegionServers。我们一般把HMaster简写为Master,它是用来做请求调度的。换句话说,Master是协调各个RegionServers工作过程的,比方说,我们写一个数据时,应该发往哪个RegionServers的那个位置进行存储等;
Master想要研发协调多个RegionServers过程的话会比较困难,因此Master借助一个现有的项目叫ZooKeeper来完成各RegionServers的协调。简单的来说,如果某个RegionServer宕机时,那么此前的RegionServer保存的数据应该其它那些HRegionServers中重新构建出来呢?这就是由ZooKeeper来协调完成的。
b>.RegionServers
HRegionServers是用来真正存取的服务器。
c>.ZooKeeper
在通过一组服务器向客户端提供服务的场景中,需要客户端能定位各服务器以便使用其提供的服务。然而这面临的挑战之一便是如何维持这个服务器列表——其显然不能放置于网络中的某单个节点上,否则此节点故障将导致整个系统不可用。即便我们有办法保证存储此服务器列表的节点不会出现故障,但当列表中的某服务器故障时将其移出列表仍然会是个问题,故障的服务器无法自行退出列表,因此这需要外部的一组处理动作来完成。Zookeeper正是设计用来提供这种服务。
可以把Zookeeper想像成为一个提供高可用功能的文件系统,它没有文件或目录,而用znode来统一实现目录及文件的功能,它既可以存储数据,又可以包含其它的znode。所有的znodes组成一个层次性的名称空间,父节点的名称为某服务器组的名称,其子节点的名称为此组中的各服务器名称。
当然,ZooKeeper还有着诸多优点:
、简洁:ZooKeeper的核心是一个精简的文件系统,它仅提供了几个简单操作和一些额外的抽像机制如排序和通知等功能;
、富于表现力:ZooKeeper的本体是一组丰富的可用于构建大规模协作式数据结构和协议的代码块,这包括分布式队列、分布式锁以及在一组节点中推举主导节点等;
、高可用:ZooKeeper运行于一组主机,设计人员在对其进行设计时就充分考虑到节点故障的可能性并由此给系统带来的问题,由此为其添加了高可用能力;
、松耦合的交互性:ZooKeeper的交互式并不要求协作方事先互相知悉彼此的存在,甚至也不要求各协作方预先进行同步;
、开源:ZooKeeper是一个开源项目;
、高性能
3>.HBase特性:
a>.线性及模块可扩展性;
b>.严格一致性读写;
c>.可配置表的自动切分策略;
d>.RegionServer自动故障恢复;
e>.便利的API;
f>.实时查询缓存;
八.Hive
1>.什么是Hive
HDFS的访问接口只有一个,即MapReduce编程接口,要想对HDFS系统中的数据进行处理,程序员就只能编程了,好在MapReduce可以支持多种API了,比如Python,shell等等,只不过没有Java的速度更快而已(因为Hadoop整个生态圈都是用Java语言实现的,如果你用其它的语言进行交互,必然会存在一个翻译的过程,而这个翻译过程自然而然是需要占用一定时间的!)因此我们如果真的想要对MapReduce进行研发,最好还是以Java编程语言为主。但是不能让所有使用Hadoop软件的IT人员都成为程序员,这个时候Facebook就在Hadoop的基础之上,给他引入了一个新的使用接口,即Hive。
hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。 其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。简单的来说,Hive就是把MapReduce的API给封装成了类似与关系型数据库的SQL接口,它里面支持类似与SQL语法的insert,delete,update,select等操作。我们可以把Hive编写的SQL语句称为Hive查询语言,简称HQL。因此,我们根据Hive的HQL编写的语句之后,Hive内部会负责实现将SQL语句转移成MapReduce作业。
由于Hadoop是批处理的,可能我们填写的HQL语句转移成MapReduce作业后,可能过了半小时仍然没有返回结果,因此Hive查询的结果不想SQL查询是实时的,当然,究其根本原因并不在于Hive,而是Hadoop的锅,但好在是Hive给总算给我们提供了一个简单的接口,不是吗?
2>.Hive的适用场景
3>.Hive的特性

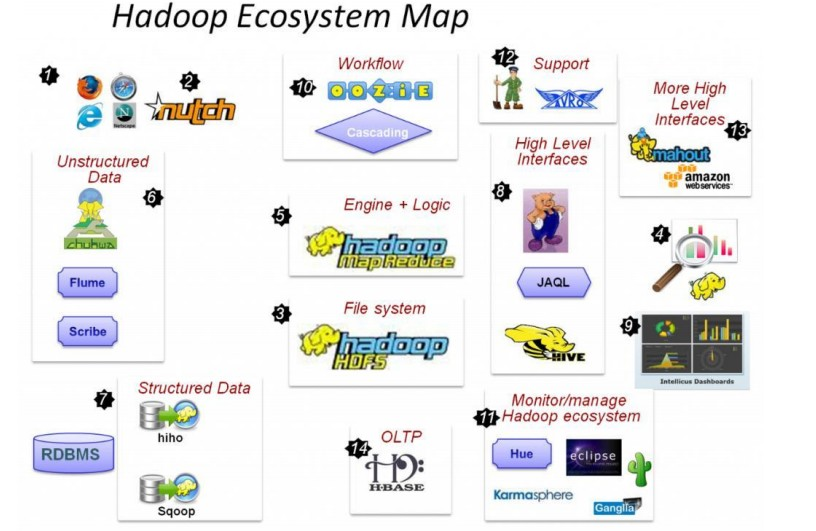
) Nutch,互联网数据及Nutch搜索引擎应用
) HDFS,Hadoop的分布式文件系统
) MapReduce,分布式计算框架
) Flume、Scribe,Chukwa数据收集,收集非结构化数据的工具。
) Hiho、Sqoop,讲关系数据库中的数据导入HDFS的工具
) Hive数据仓库,pig分析数据的工具
)Oozie作业流调度引擎
)Hue,Hadoop自己的监控管理工具
)Avro 数据序列化工具
)mahout数据挖掘工具
)Hbase分布式的面向列的开源数据库
Hadoop基础原理的更多相关文章
- Hadoop基础-Hdfs各个组件的运行原理介绍
Hadoop基础-Hdfs各个组件的运行原理介绍 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.NameNode工作原理(默认端口号:50070) 1>.什么是NameN ...
- Hadoop基础-MapReduce的工作原理第二弹
Hadoop基础-MapReduce的工作原理第二弹 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.Split(切片) 1>.MapReduce处理的单位(切片) 想必 ...
- Hadoop基础-MapReduce的工作原理第一弹
Hadoop基础-MapReduce的工作原理第一弹 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 在本篇博客中,我们将深入学习Hadoop中的MapReduce工作机制,这些知识 ...
- hadoop基础教程免费分享
提起Hadoop相信大家还是很陌生的,但大数据呢?大数据可是红遍每一个角落,大数据的到来为我们社会带来三方面变革:思维变革.商业变革.管理变革,各行业将大数据纳入企业日常配置已成必然之势.阿里巴巴创办 ...
- OpenStack的基础原理
OpenStack的基础原理 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. OpenStack既是一个社区,也是一个项目和一个开源软件,它提供了一个部署云的操作平台或工具集.其 ...
- Hadoop基础-HDFS安全管家之Kerberos实战篇
Hadoop基础-HDFS安全管家之Kerberos实战篇 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 我们都知道hadoop有很多不同的发行版,比如:Apache Hadoop ...
- 云小课|MRS基础原理之MapReduce介绍
阅识风云是华为云信息大咖,擅长将复杂信息多元化呈现,其出品的一张图(云图说).深入浅出的博文(云小课)或短视频(云视厅)总有一款能让您快速上手华为云.更多精彩内容请单击此处. 摘要:MapReduce ...
- I2C 基础原理详解
今天来学习下I2C通信~ I2C(Inter-Intergrated Circuit)指的是 IC(Intergrated Circuit)之间的(Inter) 通信方式.如上图所以有很多的周边设备都 ...
- [转]《Hadoop基础教程》之初识Hadoop
原文地址:http://blessht.iteye.com/blog/2095675 Hadoop一直是我想学习的技术,正巧最近项目组要做电子商城,我就开始研究Hadoop,虽然最后鉴定Hadoop不 ...
随机推荐
- SpringMVC(一)-- springmvc的系统学习之配置方式
资源:尚学堂 邹波 springmvc框架视频 一.springMVC 工作流程 页面请求---->控制器(Controller DispatcherServlet)----& ...
- Scala入门系列(六):面向对象之object
object object相当于class的单个实例,类似于Java中的static,通常在里面放一些静态的field和method. 第一次调用object中的方法时,会执行object的con ...
- 深入理解Java虚拟机&运行时数据区
其中,程序计数器.虚拟机栈.本地方法栈3个区域随线程而生,随线程而灭.
- iOS 如何改变搜索取消按钮的值和颜色
在初始化的时候加上下面两句就行了,试了无数方法,什么遍历查找子元素啊什么的都白搭,也不知道为啥还说可以,下面代码测试是有效果的: //改变搜索取消按钮的文字颜色 [[UIBarButtonItem a ...
- 交换机、linux光衰查询
RX收光,TX发光 一.交换机 命令: display interface transceiver brief 结果: ...... HW6851 10GE1/0/15 transceiver dia ...
- eclipse+IDEA快捷键记录
Eclipse中自动获取 IDEA中:ctrl+alt+v==alt+shift+l 其它 (有些地方前面的C代表Ctrl .S代表Shift.A代表Alt) Ctrl+Shift+F ...
- ubuntu下安装vsftpd及vsftpd配置文件不见的解决办法
利用命令 sudo apt-get install vsftpd //安装 进入etc文件可以找到 vsftpd.conf的配置文件 作为新手难免会弄错配置又不知道怎么办,那么可能会利用 sudo ...
- python 9*9乘法口诀表
# -*- coding: utf-8 -*- # __author__ = 'Carry' for i in range(1, 10): for j in range(1, i + 1): prin ...
- 【Java】提取JSON数值时遇到数组集合时使用的K-V方式转换
1.实体类转换方法 参照文章:http://www.cnblogs.com/dflmg/p/6933811.html 2.K-V方法(此方法比较笨,但是没有办法,我现在不知道有没有相关的简单API,只 ...
- JS中JSON对象和JSON字符串的相互转化
转:http://www.cnblogs.com/wbyp/p/7086318.html 一.JSON字符串转换为JSON对象 var str = '{"name":"c ...