floodlight路由机制分析
SDN的出现可以使得各种复杂的路由协议从原本的Device OS中剥离出来,放在SDN Controller中,Controller用一种简单的协议来和所有的Router进行通信,就可以获得网络拓扑,从而计算路由,有更好的可扩展性(scalable,而不会出现Full-Mesh)。Floodlight 中路由的原理利用的是LLDP这个协议,当第一个OF SW连接过来的时候,Controller会构造LLDP frame(用openflow消息包装),然后下发给这个交换机,那么这个SW就会向与其相连的设备传播LLDP消息,这些设备收到后会以packetin的形式递交给Controller,Controller就是通过这种方式获得了与一个交换机连接的DPID和端口信息,这个构建拓扑结构的基础,route engine根据一系列的NodePortTuple 计算路由,然后下发流表。
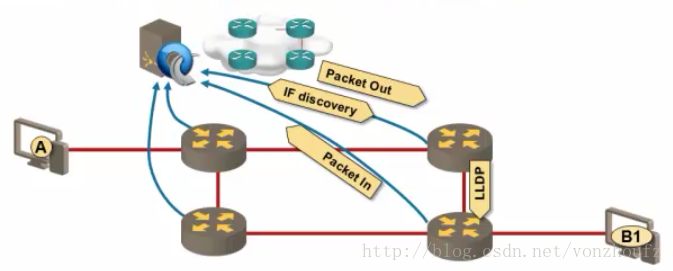
路由部分是floodlight最核心的机制,本文中的floodlight(FL)与控制器/网络控制器(NC, nework controller ) 等术语等同,交换机(SW)默认为openflow-enabled switch,不再赘述。
首先谈一下SDN控制器的路由原理:当交换机收到一个不能被当前流表各条流匹配的数据包时,会把这个数据包以openflow的格式(PACKET_IN)发送给控制器。控制器经过路由决策后,同样以openflow的格式(PACKET_OUT)的方式将该数据包的下一跳信息回给该交换机。
如果学过最短路径计算的同学一定知道,两点之间的最短路径计算首先要知道任意两点之间是否相连,如果两者间有link相连还需知道其长度。所以总体而言,FL路由包括两部分:拓扑更新和路由计算,前者是定时事先完成的,形成一个全局的拓扑结构,后者是收到数据包后运行时完成的,根据拓扑生成路由策略。
首先看拓扑更新。SDN环境中拓扑是集中控制的,故FL需要了解全局的拓扑环境,所以FL在链路更新时自动更新拓扑。
1 链路更新
当交换机加入SDN环境后,控制器通过LLDP协议定时地获得该交换机与其他设备连接的link信息,然后添加或更新这些link(LinkDiscoveryManager.addOrUpdateLink()),最后将这些link更新的事件添加到updates队列中(LinkDiscoveryManager.handleLldp())。
2 拓扑更新
计算路由的关键在于路径更新和路由计算,该过程为:
2.1 启动 首先拓扑管理启动(TopologyManager.startUp())时新起一个线程UpdateTopologyWorker,间隔500ms重复运行 。
2.2 更新拓扑 如果之前在第一步中有一些链路、交换机等更新,那么LDUpdates队列中会有元素,那么依次取出这些链路更新的元素(TopologyManager.updateTopology()/TopologyManager.applyUpdates()),判断其类型(如链路更新/删除、端口增加/删除),进行响应处理。
以链路更新为例,调用TopologyManager.addOrUpdateLink()方法,判断链路类型(多跳、单跳或隧道),再把link添加到相应交换机的端口中,如果是多跳的则再删除可能的单跳link
2.3 计算拓扑路径 每次新建一个实例(TopologyManager.createNewInstance()),初始化过程中计算拓扑路径(TopologyInstance.compute()),具体地:
2.3.1 归类 将现有所有相连的link置于同一个簇中,从而形成多个簇结构(identifyOpenflowDomains())
2.3.2 建簇 遍历所有link(addLinksToOpenflowDomains()),如果link连接的是同一个簇,则将其加入该簇,所以该方法统计了所有簇内的link。FL这么做也是减少路由计算的开销,不然若干个大二层网络中共有n个节点,就需要n平方的存储开销,计算效率也会下降,如果将不相连的节点分开就减少了上述开销。
2.3.3 遍历所有簇 对于每个簇内sw,形成一个BroadcastTree结构(包括两个属性:cost记录到其他簇内sw的路径长度,links记录其他sw的link),最终将信息保存到destinationRootedTrees中(caculateShortestPathTreeInClusters ()和calculateBroadcastNodePortsInClusters()),核心思想就是使用dijkstra计算簇内任意两点的最短路径,保存到该点的cost和下一跳。
2.4 定义路径计算模式 这样,FL就获得了从一个点出发所有相连的所有路径和点。那么只要给定一个源SW节点和一个目的SW节点,那就能知道这两者间的最短路径长度和。早在2.3开始TopologyInstance在定期新建实例时,就定义了根据拓扑计算路径的方法:
pathcache = CacheBuilder.newBuilder().concurrencyLevel(4)
.maximumSize(1000L)
.build(
new CacheLoader<routeid, route="">() {
public Route load(RouteId rid) {
return pathCacheLoader.load(rid);
}
});这里的pathcache是一个类似hash表的结构,每当被调用get时执行pathCacheLoader.load(rid),所以这里没有真正计算路由路径,只是一个注册回调。具体运行时在后面3.6中的getRoute方法中被调用:
result = pathcache.get(id);在TopologyInstance.buildRoute方法实现该路由rid的计算:先确定目的sw,因为2.3.2中以获得源目的sw的最短路径,然后根据nexthoplinks迭代查找该路径上的所有sw,最终形成一个path。
虽然2.4中没有最终计算节点间的路径,但是2.3中使用dijkstra计算了任意两点间的距离,基本上已经完成了90%的路由计算功能,在大二层网络中这也是不小的开销。
3 路由计算
当完成拓扑计算后,FL在运行时可计算输入的数据包应走的路由。这里还需说明一下,FL的某些模块监听PACKET_IN数据包,Controller收到这个数据包后,会逐个通知这些模块,调用其receive方法:
for (IOFMessageListener listener : listeners) {
pktinProcTime.recordStartTimeComp(listener);
cmd = listener.receive(sw, m, bc);
pktinProcTime.recordEndTimeComp(listener);
if (Command.STOP.equals(cmd))
{ break; } }那么回到路由计算这部分来,Controller会依次调用以下模块:
3.1 LinkDiscoveryManager链路处理模块,如果数据包是LLDP处理该消息,如步骤1中在此处会有处理;如果是正常的数据包则略过,所以这里忽略
3.2 TopologyManager拓扑管理模块,查看源端口在TopologyInstance是否允许转发
3.3 DeviceManager设备模块,通过源目SW的id和port相连的device找到源设备和目的设备,如找不到则放弃,否则暂存入一个上下文结构context
3.4 Firewall防火墙模块,判断该数据包的源目的主机是否可以通信,如不在规则表中则继续
3.5 LoadBalancer负载均衡模块,如是ARP数据包则查看是否在vipIPToId中,如不在则继续。这里关系不大,忽略。
3.6 ForwardBase路由模块,首先在上下文context查找之前模块是否已有路由策略,如无则检查是否数据包是广播的,如是则Flood。否则调用doForwardFlow,我们主要看这个方法,具体的,从上下文中获取3.3中解析的源目的主机信息,如果不在同一个island上(我的理解是这两台主机在FL的知识库中没有路径,也许中间有别的传统方法相连,也许根本不相连),则Flood;如果在同一个端口,那就是同一台主机,则放弃;否则调用routingEngine.getRoute获得路由。这个才是最重要的,也是2.4中没有完成的最终部分,这里使用了TopologyInstance的getRoute方法,使用2.4的方法计算出路由路径,然后调用将路由所对应的路径推送给交换机,如果是多跳路径,则将路由策略推送给该路径上的所有交换机(ForwardBase.pushRoute())。
最后给出一个场景吧,假定h1和h2是主机,s1、s2和s3是交换机,拓扑是h1-s1-s2-s3-h2。当h1 ping h2,首先h1发送ARP包,由于该数据包是广播的,那么最终ForwardBase会执行doFlood,所有交换机都会广播这个数据包,最后h2收到s3广播的的ARP请求后,向h1发送ARP响应。h1收到ARP响应后发送ping请求,该包在交换机以PACKET_IN的形式发送给floodlight,此时floodlight知道h2所在的交换机s3,所以调用doForwardFlow,计算出
s1到s3的路径s1->s2,s2->s3,然后将OFFlowMod命令发送给s1、s2和s3。最终数据包通过s1、s2和s3直接被发送到h2,搞定。
p.s.1 Floodlight在计算拓扑calculateShortestPathTreeInClusters时,首先会将所有的路径置为失效,然后在计算所有两点间距离,如果每次(间隔为500ms)存在一条链路变动,那么就需要重做所有计算,在大二层网络中会不会出现性能瓶颈?
p.s.2 Floodlight的计算出路由后,下发的流只包括源目的主机的mac,流的其他字段都是通配符,这么做的逻辑应该是“我只做路由和转发功能,别的不用控制”。这样会给北向的APP造成很大的麻烦,例如在做DDoS的防御时,需要检查每条流的目的端口,如果流的dst_transport_addr是*的话,显然无法检测攻击,甚至连FL自带的Firewall都力不从心。
p.s. 一般而言,交换机的端口与与其他端口相连,有两个对称的link。但TopologyManager中有一类特殊的端口broadcastDomainPorts,这类是广播端口,不是一般的端口,没有对称的link.
附:
3.6中的Forward模块分析:
主模块在初始化并启动各个二级模块后,通过Netty网络应用框架监听6633端口,当有packet-in进来的时候,会调用各个二级模块的receive函数(java中似乎喜欢称之为方法,那下面就都用“方法”来表述吧),此处暂不详表。
对于Forward模块很轻松可以定位到Forwarding.java文件,但是这个文件中或者说Forwarding类中并没有定义receive方法,其实这里可以通过两个途径找到receive函数:1、Forwarding类中首先定义了一个processPacketInMessage方法,见名知义,这个方法是负责处理packet-in消息的,那么通过eclipse中的“open call hierarchy”直接定位到调用该方法的方法,发现是ForwardingBase.java文件中的receive方法;2、Farwording类在声明时继承了ForwardingBase类,可以直接即继承了ForwardingBase类的receive方法。
为了方便描述,以下分析只分析我们关心的流程:Forwarding模块如何向各个交换机添加flow。
通过以上描述,我们找到了Forwarding模块处理packet-in的入口receive方法,该方法中调用了processPacketInMessage方法,该方法又调用doForwardFlow方法。下面描述doForwardFlow方法的实现细节:
首先声明一个OFMatch对象,并将packet-in中的相关信息加载到该对象中:
OFMatch match = new OFMatch();
match.loadFromPacket(pi.getPacketData(), pi.getInPort());然后通过packet-in消息获取目标和源设备(idevice),即以下代码:
IDevice dstDevice =IDeviceService.fcStore.get(cntx, IDeviceService.CONTEXT_DST_DEVICE);
if (dstDevice != null) {
IDevice srcDevice =IDeviceService.fcStore.get(cntx, IDeviceService.CONTEXT_SRC_DEVICE);再然后定位发生packet-in消息的switch所属于的island的标志
Long srcIsland = topology.getL2DomainId(sw.getId());接下来,判断目标和源设备是否处于同一个island,是则继续,否则执行doFlood方法(类似广播),代码如下:
boolean on_same_island = false;
boolean on_same_if = false;
for (SwitchPort dstDap : dstDevice.getAttachmentPoints()) {
long dstSwDpid = dstDap.getSwitchDPID();
Long dstIsland = topology.getL2DomainId(dstSwDpid);
if ((dstIsland != null) && dstIsland.equals(srcIsland)) {
on_same_island = true;
if ((sw.getId() == dstSwDpid) &&(pi.getInPort() == dstDap.getPort())) {
on_same_if = true;
}
break;
}
}
if (!on_same_island) {
// Flood since we don't know the dst device
if (log.isTraceEnabled()) {
<span></span>log.trace("No first hop island found for destination " +
"device {}, Action = flooding", dstDevice);
}
doFlood(sw, pi, cntx);
return;
}如果在同一个island中,则通过getAttachmentPoints方法获取目标和源设备相连的交换机的端口信息
SwitchPort[] srcDaps = srcDevice.getAttachmentPoints();
Arrays.sort(srcDaps, clusterIdComparator);
SwitchPort[] dstDaps = dstDevice.getAttachmentPoints();
Arrays.sort(dstDaps, clusterIdComparator);获取到的结果是两个排序的端口数组,数组的元素类似:
SwitchPort [switchDPID=7, port=2, errorStatus=null]再接下来进入一个while循环,循环的终止条件是取完上一步得到的两个数组中的元素,目标是找到属于同一个island的分布在两个数组中的元素。循环内部先通过getL2DomainId方法判断,所选取的与目标和源相连接的交换机是否在同一个island,如果不在,则根据两个island标志的大小选择性的选取srcDaps或dstDaps中的其它元素,继续比较,之所以可以这么做,是因为两个数组是经过排序的,而且key就是各个交换机所属的island标志,代码为while循环最后的if-else语句:
} else if (srcVsDest < 0) {
iSrcDaps++;
} else {
iDstDaps++;
}如果找到两个island相同的元素,会调用routingEngine的getRoute方法获取两个端口之间的路由,这才是我们真正关心的流程。这里并未继续跟踪getRoute是如何获取两个交换机端口之间的最短路径(官网提到获取的路由是最短路径),其获取的结果类似:
[[id=00:00:00:00:00:00:00:07, port=2], [id=00:00:00:00:00:00:00:07, port=3],
[id=00:00:00:00:00:00:00:05, port=2], [id=00:00:00:00:00:00:00:05, port=3],
[id=00:00:00:00:00:00:00:01, port=2], [id=00:00:00:00:00:00:00:01, port=1],
[id=00:00:00:00:00:00:00:02, port=3], [id=00:00:00:00:00:00:00:02, port=1],
[id=00:00:00:00:00:00:00:03, port=3], [id=00:00:00:00:00:00:00:03, port=1]]
接下来利用最初生成的OFMatch对象信息定义一个规则:
wildcard_hints = ((Integer) sw.getAttribute(IOFSwitch.PROP_FASTWILDCARDS))
.intValue()
& ~OFMatch.OFPFW_IN_PORT
& ~OFMatch.OFPFW_DL_VLAN
& ~OFMatch.OFPFW_DL_SRC
& ~OFMatch.OFPFW_DL_DST
& ~OFMatch.OFPFW_NW_SRC_MASK
& ~OFMatch.OFPFW_NW_DST_MASK;最后调用pushRoute方法,下发路由策略,即flow信息。
pushRoute(route, match, wildcard_hints, pi, sw.getId(), cookie,
cntx, requestFlowRemovedNotifn, false,OFFlowMod.OFPFC_ADD);继续追踪pushRoute函数,其在ForwardingBase.java中实现,其实就是循环上面route获取到的最短路径,在每个交换机上添加一条flow,包含inport和outport,当然上面提到的wildcard_hints也会通过setMatch方法设置到没条flow中。
以上过程建立了从07:2([id=00:00:00:00:00:00:00:07, port=2])到03:1的一条单向通路,从03:1到07:2的通路又是一个相同的过程。
参考链接 https://blog.csdn.net/crystonesc
floodlight路由机制分析的更多相关文章
- Linux mips64r2 PCI中断路由机制分析
Linux mips64r2 PCI中断路由机制分析 本文主要分析mips64r2 PCI设备中断路由原理和irq号分配实现方法,并尝试回答如下问题: PCI设备驱动中断注册(request_irq) ...
- Linux x86_64 APIC中断路由机制分析
不同CPU体系间的中断控制器工作原理有较大差异,本文是<Linux mips64r2 PCI中断路由机制分析>的姊妹篇,主要分析Broadwell-DE X86_64 APIC中断路由原理 ...
- Meandering Through the Maze of MFC Message and Command Routing MFC消息路由机制分析
Meandering Through the Maze of MFC Message and Command Routing Paul DiLascia Paul DiLascia is a free ...
- C#进阶系列——WebApi 路由机制剖析:你准备好了吗?
前言:从MVC到WebApi,路由机制一直是伴随着这些技术的一个重要组成部分. 它可以很简单:如果你仅仅只需要会用一些简单的路由,如/Home/Index,那么你只需要配置一个默认路由就能简单搞定: ...
- 迈向angularjs2系列(6):路由机制
目录1.angular-seed的路由2.路由机制的探索3.懒加载 一:angular-seed的路由 step1:安装种子项目 $ git clone --depth 1 https://gi ...
- MongoDB Sharding 机制分析
MongoDB Sharding 机制分析 MongoDB 是一种流行的非关系型数据库.作为一种文档型数据库,除了有无 schema 的灵活的数据结构,支持复杂.丰富的查询功能外,MongoDB 还自 ...
- MVC进阶篇(二)—路由机制
前言 这个东西好像,一般也不经常动,都用默认的即可.由于MVC模式在framework里面的解析机制,区别与webform模式,是采用解析路由机制的url.从来实例化视图列对象,然后对该action进 ...
- 【C#】 WebApi 路由机制剖析
C#进阶系列——WebApi 路由机制剖析:你准备好了吗? 转自:https://blog.csdn.net/wulex/article/details/71601478 2017年05月11日 10 ...
- SPA路由机制详解(看不懂不要钱~~)
前言 总所周知,随着前端应用的业务功能起来越复杂,用户对于使用体验的要求越来越高,单面(SPA)成为前端应用的主流形式.而大型单页应用最显著特点之一就是采用的前端路由跳转子页面系统,通过改变页面的UR ...
随机推荐
- [翻译] OCMaskedTextField
OCMaskedTextField https://github.com/OmerCora/OCMaskedTextField Simple class to display dynamically ...
- swift版的CircleView
swift版的CircleView 效果图 源码 // // CircleView.swift // CircleView // // Created by YouXianMing on 15/10/ ...
- [控件] LineAnimationView
LineAnimationView 效果 说明 水平循环无间隔播放动画效果,用于loading的界面 源码 https://github.com/YouXianMing/UI-Component-Co ...
- UIButton的resizableImageWithCapInsets使用解析
UIButton的resizableImageWithCapInsets使用解析 效果: 使用的源文件: 源码: // // ViewController.m // SpecialButton // ...
- 0x01 现阶段目标
现阶段目标: 1.完成前端知识基础的学习. 具体如下: 在目前学习的基础上(html,css,JavaScript+BOM基础已经大致了解).针对DOM进行学习,个人在http://how2j.cn? ...
- U-Mail详解邮件营销优势及应用领域
最近频频有营销人员向U-Mail小编咨询:邮件营销到底有什么好处呢?与此同时,还有不少人对邮件营销存在一定的误解:邮件营销是不是只给潜在消费者发送邮件推广商品呢?其实邮件群发的应用面非常广泛,可不仅仅 ...
- php实现简单的单链表
<?php /** * 建立一个链表,节点的data为数组,记录一个id,完成链表所以操作 */ //结点,结点数据data定义为一个数组,id和value class Node{ public ...
- [DAViCHi/SeeYa/T-ARA][원더우먼][Wonder Woman]
歌词来源:http://music.163.com/#/song?id=5371229 作曲 : 赵英秀 [作曲 : 赵英秀] [作曲 : 赵英秀] 作词 : K-Smith [作词 : KSmith ...
- 【原创】Spring 注入方式
Spring 强烈推荐注解在构造器上,且对于不能为null的字段或者属性都用断言. 1. 设值注入 原理:通过setter方法注入 XML配置方式:bean下的property标签,用value指定基 ...
- JavaScript设计模式—工厂模式
工厂模式介绍 将new操作符单独进行封装,遇到new时,就要考虑是否该使用工厂模式 举一个生活当中的示例: 你要去购买汉堡,直接点餐,取餐,不会自己动手做,商店要“封装” 做汉堡的工作,做好直接给购买 ...