Nginx - buffer缓冲区部分
目录
- 1. 前言
- 2. 指令
- 3. 原理及总结
1. 前言
关于缓冲,主要是合理设置缓冲区大小,尽量避免缓冲到硬盘
2. 指令
proxy_buffering
说明:proxy_buffering这个参数用来控制是否打开后端响应内容的缓冲区,如果这个设置为off,那么proxy_buffers和proxy_busy_buffers_size这两个指令将会失效。但是无论proxy_buffering是否开启,对proxy_buffer_size都是生效的。
proxy_buffering开启的情况下,nignx会把后端返回的内容先放到缓冲区当中,然后再返回给客户端(边收边传,不是全部接收完再传给客户端)。 临时文件由proxy_max_temp_file_size和proxy_temp_file_write_size这两个指令决定的。
如果proxy_buffering关闭,那么nginx会立即把从后端收到的响应内容传送给客户端,每次取的大小为proxy_buffer_size的大小,这样效率肯定会比较低。
注: proxy_buffering启用时,要提防使用的代理缓冲区太大。这可能会吃掉你的内存,限制代理能够支持的最大并发连接数。
proxy_buffer_size
后端服务器的响应头会放到proxy_buffer_size当中,这个大小默认等于proxy_buffers当中的设置单个缓冲区的大小。
proxy_buffer_size只是响应头的缓冲区,没有必要也跟着设置太大。 proxy_buffer_size最好单独设置,一般设置个4k就够了。
proxy_buffers
proxy_buffers的缓冲区大小一般会设置的比较大,以应付大网页。 proxy_buffers当中单个缓冲区的大小是由系统的内存页面大小决定的,Linux系统中一般为4k。
proxy_buffers由缓冲区数量和缓冲区大小组成的。总的大小为number*size。
若某些请求的响应过大,则超过_buffers的部分将被缓冲到硬盘(缓冲目录由_temp_path指令指定), 当然这将会使读取响应的速度减慢, 影响用户体验. 可以使用proxy_max_temp_file_size指令关闭磁盘缓冲.
proxy_busy_buffers_size
proxy_busy_buffers_size不是独立的空间,他是proxy_buffers和proxy_buffer_size的一部分。nginx会在没有完全读完后端响应的时候就开始向客户端传送数据,所以它会划出一部分缓冲区来专门向客户端传送数据(这部分的大小是由proxy_busy_buffers_size来控制的,建议为proxy_buffers中单个缓冲区大小的2倍),然后它继续从后端取数据,缓冲区满了之后就写到磁盘的临时文件中。
proxy_max_temp_file_size和proxy_temp_file_write_size
临时文件由proxy_max_temp_file_size和proxy_temp_file_write_size这两个指令决定。
proxy_temp_file_write_size是一次访问能写入的临时文件的大小,默认是proxy_buffer_size和proxy_buffers中设置的缓冲区大小的2倍,Linux下一般是8k。
proxy_max_temp_file_size指定当响应内容大于proxy_buffers指定的缓冲区时, 写入硬盘的临时文件的大小. 如果超过了这个值, Nginx将与Proxy服务器同步的传递内容, 而不再缓冲到硬盘. 设置为0时, 则直接关闭硬盘缓冲.
3. 原理及总结
nginx buffer 原理图
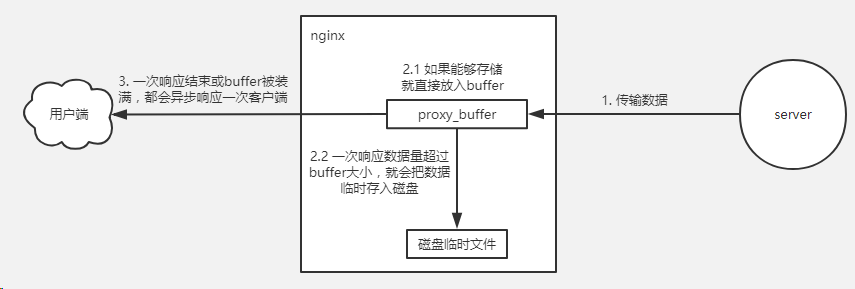
总结:
首先第一个概念是所有的这些 proxy buffer参数是作用到每一个请求的。每一个请求会按照参数的配置获得自己的buffer。proxy buffer不是global 而是 per request的。
1. 无论在 proxy_buffering 是否开启的情况下,proxy_buffer_size 都会用来缓冲后端服务的 header信息。
2. 当proxy_buffering 开启时, proxy_buffers 和 proxy_busy_buffers_size 才会生效。
3. 在开启 proxy_buffering 的情况下,nginx会尽量将后端获取到的数据存入 buffer中,直到 proxy_buffers 被写满或数据读取完毕。如果buffer装不下后端返回的数据,那么nginx服务器会将部分接收到的数据临时存放在磁盘的临时文件中,磁盘上的临时文件目录可以通过 proxy_temp_path 指定,临时文件的大小有 proxy_max_temp_file_size 和 proxy_temp_file_write_size 指令决定
4. 一旦proxy_buffers设置的buffer被写入,直到buffer里面的数据被完整的传输完(传输到客户端),这个buffer将会一直处在busy状态,我们不能对这个buffer进行任何别的操作。所有处在busy状态的buffer size加起来不能超过proxy_busy_buffers_size,所以proxy_busy_buffers_size是用来控制同时传输到客户端的buffer数量的。
5. 一次响应数据接收完成或者buffer已经转满,nginx服务器开始向客户端传输数据。
通用网站配置:
proxy_buffer_size 4k; # 设置代理服务器(nginx)保存用户头信息的缓冲区大小
proxy_buffers 32k; #proxy_buffers # 缓冲区,网页平均在32k以下的设置 -> 如果页面过大可以设置为 512k
proxy_busy_buffers_size 64k; # 高负荷下缓冲大小(proxy_buffers*) -> k
proxy_temp_file_write_size 64k; # 设定缓存文件夹大小,大于这个值,将从upstream服务器传 -> 10m;
Nginx - buffer缓冲区部分的更多相关文章
- Java NIO Buffer缓冲区
原文链接:http://tutorials.jenkov.com/java-nio/buffers.html Java NIO Buffers用于和NIO Channel交互.正如你已经知道的,我们从 ...
- Nio再学习之NIO的buffer缓冲区
1. 缓冲区(Buffer): 介绍 我们知道在BIO(Block IO)中其是使用的流的形式进行读取,可以将数据直接写入或者将数据直接读取到Stream对象中,但是在NIO中所有的数据都是使用的换冲 ...
- Netty buffer缓冲区ByteBuf
Netty buffer缓冲区ByteBuf byte 作为网络传输的基本单位,因此数据在网络中进行传输时需要将数据转换成byte进行传输.netty提供了专门的缓冲区byte生成api ByteBu ...
- Java NIO 之 Buffer(缓冲区)
一 Buffer(缓冲区)介绍 Java NIO Buffers用于和NIO Channel交互. 我们从Channel中读取数据到buffers里,从Buffer把数据写入到Channels. Bu ...
- 笔记:Node.js 的 Buffer 缓冲区
笔记:Node.js 的 Buffer 缓冲区 node.js 6.0 之前创建的 Buffer 对象使用 new Buffer() 构造函数来创建对象实例,但权限很大,可以获得敏感信息,所以建议使用 ...
- NIO(一):Buffer缓冲区
一.NIO与IO: IO: 一般泛指进行input/output操作(读写操作),Java IO其核心是字符流(inputstream/outputstream)和字节流(reader/writer ...
- nginx buffer
1.错误日志:warn:an upstream response is buffered to a temporary file 解决办法:增加fastcgi_buffers 8 4K; fa ...
- Nginx SPDY缓冲区溢出漏洞
漏洞版本: nginx 1.3.15 nginx 1.5.x 漏洞描述: CVE ID:CVE-2014-0133 Nginx是HTTP及反向代理服务器,同时也用作邮件代理服务器,由Igor Syso ...
- C++ buffer缓冲区的秘密
在搞数据库和C++进行连接的时候,遇到一个问题,就是如果前面用到了fflush(stdin)即清空缓冲区,就OK,如果不清空缓冲区就不能把记录加入到Mysql的数据库中, 但是即便如此,这个问题目前还 ...
随机推荐
- LINUX第四周学习
<Linux内核设计与实现>第四周读书笔记——第五章 5.1 与内核通信57 系统调用在用户空间进程和硬件设备之间添加了一个中间层,该层主要作用有三个: 首先它为用户空间提供了一种硬件的抽 ...
- debian包管理
常用的包管理工具有:apt.apt-get.apt-cache.apt-file.aptitude.dpkg等.功能有重复的,挑顺手的即可. 1.apt # apt --help list - lis ...
- MySQL 第六篇:数据备份、pymysql模块
一 IDE工具介绍 生产环境还是推荐使用mysql命令行,但为了方便我们测试,可以使用IDE工具 下载链接:https://pan.baidu.com/s/1O8hXkdRK5_EVHZwNPwjCB ...
- bzoj1874 [BeiJing2009 WinterCamp]取石子游戏
1874: [BeiJing2009 WinterCamp]取石子游戏 Time Limit: 5 Sec Memory Limit: 162 MBSubmit: 925 Solved: 381[ ...
- Java入门:用户登录与注册模块1(实践项目)——分析
任务描述:用户登录与注册是大多数软件都拥有的一个模块.请编写一个控制台程序,实现用户的登录与注册功能,并且用户能够修改自己信息. [需求分析]由于本程序是一个演示程序,用户的信息我们做简化处理,仅包括 ...
- 彻底理解 Python 生成器
1. 生成器定义 在Python中,一边循环一边计算的机制,称为生成器:generator. 2. 为什么要有生成器 列表所有数据都在内存中,如果有海量数据的话将会非常耗内存. 如:仅仅需要访问前面几 ...
- linux命令总结之state命令
ls 命令及其许多参数提供了一些非常有用的文件信息.另一个不太为人所熟知的命令 stat 提供了一些更为有用的信息. [root@Gin scripts]# man stat STAT() User ...
- linux命令总结之查找命令find、locate、whereis、which、type
我们经常需要在系统中查找一个文件,那么在Linux系统中我们如何准确高效的确定一个文件在系统中的具体位置呢?一下我总结了在linux系统中用于查找文件的几个命令. 1.find命令 find是最常用也 ...
- python 资产扫描01
本地建立的三个文件: Asset1.txt 用来保存扫描到的资产 Asset2.txt 用来导入给定的资产 Repeat.txt 保存重复的资产 程序的功能: 1.资产扫描,以 位置:资产 格式保存到 ...
- windows10下基于vs2015的 caffe安装教程及python接口实现
啦啦啦:根据网上的教程前一天安装失败,第二天才安装成功.其实caffe的安装并不难,只是网上的教程不是很全面,自己写一个,留作纪念. 准备工作 Windows10 操作系统 vs2015(c++编译器 ...