【十大经典数据挖掘算法】k
【十大经典数据挖掘算法】系列
1. 引言
k-means与kNN虽然都是以k打头,但却是两类算法——kNN为监督学习中的分类算法,而k-means则是非监督学习中的聚类算法;二者相同之处:均利用近邻信息来标注类别。
聚类是数据挖掘中一种非常重要的学习流派,指将未标注的样本数据中相似的分为同一类,正所谓“物以类聚,人以群分”嘛。k-means是聚类算法中最为简单、高效的,核心思想:由用户指定k个初始质心(initial centroids),以作为聚类的类别(cluster),重复迭代直至算法收敛。
2. 基本算法
在k-means算法中,用质心来表示cluster;且容易证明k-means算法收敛等同于所有质心不再发生变化。基本的k-means算法流程如下:
选取k个初始质心(作为初始cluster);
repeat:
对每个样本点,计算得到距其最近的质心,将其类别标为该质心所对应的cluster;
重新计算k个cluser对应的质心;
until 质心不再发生变化对于欧式空间的样本数据,以平方误差和(sum of the squared error, SSE)作为聚类的目标函数,同时也可以衡量不同聚类结果好坏的指标:
SSE=k∑i=1∑x∈Cidist(x,ci)
表示样本点x到cluster Ci 的质心 ci 距离平方和;最优的聚类结果应使得SSE达到最小值。
下图中给出了一个通过4次迭代聚类3个cluster的例子:
k-means存在缺点:
k-means是局部最优的,容易受到初始质心的影响;比如在下图中,因选择初始质心不恰当而造成次优的聚类结果(SSE较大):
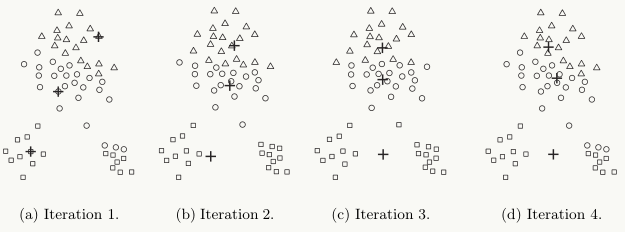
同时,k值的选取也会直接影响聚类结果,最优聚类的k值应与样本数据本身的结构信息相吻合,而这种结构信息是很难去掌握,因此选取最优k值是非常困难的。
3. 优化
为了解决上述存在缺点,在基本k-means的基础上发展而来二分 (bisecting) k-means,其主要思想:一个大cluster进行分裂后可以得到两个小的cluster;为了得到k个cluster,可进行k-1次分裂。算法流程如下:
初始只有一个cluster包含所有样本点;
repeat:
从待分裂的clusters中选择一个进行二元分裂,所选的cluster应使得SSE最小;
until 有k个cluster上述算法流程中,为从待分裂的clusters中求得局部最优解,可以采取暴力方法:依次对每个待分裂的cluster进行二元分裂(bisect)以求得最优分裂。二分k-means算法聚类过程如图:
从图中,我们观察到:二分k-means算法对初始质心的选择不太敏感,因为初始时只选择一个质心。
4. 参考资料
[1] Pang-Ning Tan, Michael Steinbach, Vipin Kumar, Introduction to Data Mining.
[2] Xindong Wu, Vipin Kumar, The Top Ten Algorithms in Data Mining.
【十大经典数据挖掘算法】k的更多相关文章
- 【十大经典数据挖掘算法】PageRank
[十大经典数据挖掘算法]系列 C4.5 K-Means SVM Apriori EM PageRank AdaBoost kNN Naïve Bayes CART 我特地把PageRank作为[十大经 ...
- 【十大经典数据挖掘算法】SVM
[十大经典数据挖掘算法]系列 C4.5 K-Means SVM Apriori EM PageRank AdaBoost kNN Naïve Bayes CART SVM(Support Vector ...
- 【十大经典数据挖掘算法】Naïve Bayes
[十大经典数据挖掘算法]系列 C4.5 K-Means SVM Apriori EM PageRank AdaBoost kNN Naïve Bayes CART 朴素贝叶斯(Naïve Bayes) ...
- 【十大经典数据挖掘算法】C4.5
[十大经典数据挖掘算法]系列 C4.5 K-Means SVM Apriori EM PageRank AdaBoost kNN Naïve Bayes CART 1. 决策树模型与学习 决策树(de ...
- 【十大经典数据挖掘算法】k-means
[十大经典数据挖掘算法]系列 C4.5 K-Means SVM Apriori EM PageRank AdaBoost kNN Naïve Bayes CART 1. 引言 k-means与kNN虽 ...
- 【十大经典数据挖掘算法】Apriori
[十大经典数据挖掘算法]系列 C4.5 K-Means SVM Apriori EM PageRank AdaBoost kNN Naïve Bayes CART 1. 关联分析 关联分析是一类非常有 ...
- 【十大经典数据挖掘算法】kNN
[十大经典数据挖掘算法]系列 C4.5 K-Means SVM Apriori EM PageRank AdaBoost kNN Naïve Bayes CART 1. 引言 顶级数据挖掘会议ICDM ...
- 【十大经典数据挖掘算法】CART
[十大经典数据挖掘算法]系列 C4.5 K-Means SVM Apriori EM PageRank AdaBoost kNN Naïve Bayes CART 1. 前言 分类与回归树(Class ...
- 【十大经典数据挖掘算法】EM
[十大经典数据挖掘算法]系列 C4.5 K-Means SVM Apriori EM PageRank AdaBoost kNN Naïve Bayes CART 1. 极大似然 极大似然(Maxim ...
随机推荐
- [洛谷P4609] [FJOI2016]建筑师
洛谷题目链接:[FJOI2016]建筑师 题目描述 小 Z 是一个很有名的建筑师,有一天他接到了一个很奇怪的任务:在数轴上建 \(n\) 个建筑,每个建筑的高度是 \(1\) 到 \(n\) 之间的一 ...
- session_write_close()的作用
简单地说,当开启session_start以后,这个session会一直开启,并且被一个用户使用.其他用户开启session的话要等待第一个session用户关闭以后才可以开启sessio,这样就造成 ...
- 【代码优化】调用optional delegates的最佳方法
[转载请注明出处]http://www.cnblogs.com/lexingyu/p/3932475.html 本文是以下两篇blog的综合脱水,感谢两位作者为解放码农生产力所做的深入思考=.= Sm ...
- HDU 2082 找单词 (普通母函数)
题目链接 Problem Description 假设有x1个字母A, x2个字母B,..... x26个字母Z,同时假设字母A的价值为1,字母B的价值为2,..... 字母Z的价值为26.那么,对于 ...
- docker ubuntu容器更换阿里源(转)
问题:使用docker 利用下载的ubuntu镜像启动容器时,使用的源下载更新软件的速度较慢. 解决这个问题的方法是跟新ubuntu容器的源 示例:以ubuntu为基础镜像 启动一个名称为 test0 ...
- wifi钓鱼 强势拿你的wifi密码
钓鱼wifi 首先设一个场景!!! 如何得到一个免费的wifi 有人可能做过抓包跑包的方法或者跑pin码的方法然而这些方法可能会耗去你大量的时间(我曾经跑包花了一天的时间 跑pin码花了一晚上)感 ...
- Battery Charging Specification 1.2 中文详解 来源:www.chengxuyuans.com
1. Introduction 1.1 Scope 规范定义了设备通过USB端口充电的检测.控制和报告机制,这些机制是USB2.0规范的扩展,用于专用 充电器(DCP).主机(SDP).hub(SDP ...
- js日期工具
/** * 日期工具类 */ define(function(require, exports, module) { var constants = require("constants&q ...
- C++ 模版的优点和缺点
优点: 1. 灵活性, 可重用性和可扩展性; 2. 可以大大减少开发时间,模板可以把用同一个算法去适用于不同类型数据,在编译时确定具体的数据类型; 3. 模版模拟多态要比C++类继承实现多态效率要高, ...
- 重置HTML标签样式
;;} header,footer,section,article,aside,nav,hgroup,address,figure,figcaption,menu,details{display:bl ...