斯坦福大学卷积神经网络教程UFLDL Tutorial - Convolutional Neural Network
Convolutional Neural Network
Overview
A Convolutional Neural Network (CNN) is comprised of one or more convolutional layers (often with a subsampling step) and then followed by one or more fully connected layers as in a standard multilayer neural network. The architecture of a CNN is designed to take advantage of the 2D structure of an input image (or other 2D input such as a speech signal). This is achieved with local connections and tied weights followed by some form of pooling which results in translation invariant features. Another benefit of CNNs is that they are easier to train and have many fewer parameters than fully connected networks with the same number of hidden units. In this article we will discuss the architecture of a CNN and the back propagation algorithm to compute the gradient with respect to the parameters of the model in order to use gradient based optimization. See the respective tutorials on convolution andpooling for more details on those specific operations.
Architecture
A CNN consists of a number of convolutional and subsampling layers optionally followed by fully connected layers. The input to a convolutional layer is a m x m x rm x m x r image where mm is the height and width of the image and rr is the number of channels, e.g. an RGB image has r=3r=3. The convolutional layer will have kk filters (or kernels) of size n x n x qn x n x q where nn is smaller than the dimension of the image and qq can either be the same as the number of channels rr or smaller and may vary for each kernel. The size of the filters gives rise to the locally connected structure which are each convolved with the image to produce kk feature maps of size m−n+1m−n+1. Each map is then subsampled typically with mean or max pooling over p x pp x p contiguous regions where p ranges between 2 for small images (e.g. MNIST) and is usually not more than 5 for larger inputs. Either before or after the subsampling layer an additive bias and sigmoidal nonlinearity is applied to each feature map. The figure below illustrates a full layer in a CNN consisting of convolutional and subsampling sublayers. Units of the same color have tied weights.
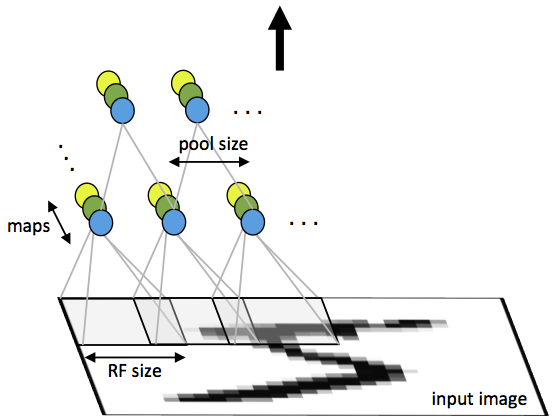
Fig 1: First layer of a convolutional neural network with pooling. Units of the same color have tied weights and units of different color represent different filter maps.
After the convolutional layers there may be any number of fully connected layers. The densely connected layers are identical to the layers in a standard multilayer neural network.
Back Propagation
Let δ(l+1)δ(l+1) be the error term for the (l+1)(l+1)-st layer in the network with a cost function J(W,b;x,y)J(W,b;x,y)where (W,b)(W,b) are the parameters and (x,y)(x,y) are the training data and label pairs. If the ll-th layer is densely connected to the (l+1)(l+1)-st layer, then the error for the ll-th layer is computed as
and the gradients are
If the ll-th layer is a convolutional and subsampling layer then the error is propagated through as
Where kk indexes the filter number and f′(z(l)k)f′(zk(l)) is the derivative of the activation function. The upsampleoperation has to propagate the error through the pooling layer by calculating the error w.r.t to each unit incoming to the pooling layer. For example, if we have mean pooling then upsample simply uniformly distributes the error for a single pooling unit among the units which feed into it in the previous layer. In max pooling the unit which was chosen as the max receives all the error since very small changes in input would perturb the result only through that unit.
Finally, to calculate the gradient w.r.t to the filter maps, we rely on the border handling convolution operation again and flip the error matrix δ(l)kδk(l) the same way we flip the filters in the convolutional layer.
Where a(l)a(l) is the input to the ll-th layer, and a(1)a(1) is the input image. The operation (a(l)i)∗δ(l+1)k(ai(l))∗δk(l+1) is the “valid” convolution between ii-th input in the ll-th layer and the error w.r.t. the kk-th filter.
from: http://ufldl.stanford.edu/tutorial/supervised/ConvolutionalNeuralNetwork/
斯坦福大学卷积神经网络教程UFLDL Tutorial - Convolutional Neural Network的更多相关文章
- 树卷积神经网络Tree-CNN: A Deep Convolutional Neural Network for Lifelong Learning
树卷积神经网络Tree-CNN: A Deep Convolutional Neural Network for Lifelong Learning 2018-04-17 08:32:39 看_这是一 ...
- 深度学习笔记 (一) 卷积神经网络基础 (Foundation of Convolutional Neural Networks)
一.卷积 卷积神经网络(Convolutional Neural Networks)是一种在空间上共享参数的神经网络.使用数层卷积,而不是数层的矩阵相乘.在图像的处理过程中,每一张图片都可以看成一张“ ...
- 卷积神经网络用语句子分类---Convolutional Neural Networks for Sentence Classification 学习笔记
读了一篇文章,用到卷积神经网络的方法来进行文本分类,故写下一点自己的学习笔记: 本文在事先进行单词向量的学习的基础上,利用卷积神经网络(CNN)进行句子分类,然后通过微调学习任务特定的向量,提高性能. ...
- Deep Learning 19_深度学习UFLDL教程:Convolutional Neural Network_Exercise(斯坦福大学深度学习教程)
理论知识:Optimization: Stochastic Gradient Descent和Convolutional Neural Network CNN卷积神经网络推导和实现.Deep lear ...
- Deep Learning 8_深度学习UFLDL教程:Stacked Autocoders and Implement deep networks for digit classification_Exercise(斯坦福大学深度学习教程)
前言 1.理论知识:UFLDL教程.Deep learning:十六(deep networks) 2.实验环境:win7, matlab2015b,16G内存,2T硬盘 3.实验内容:Exercis ...
- Deep Learning 1_深度学习UFLDL教程:Sparse Autoencoder练习(斯坦福大学深度学习教程)
1前言 本人写技术博客的目的,其实是感觉好多东西,很长一段时间不动就会忘记了,为了加深学习记忆以及方便以后可能忘记后能很快回忆起自己曾经学过的东西. 首先,在网上找了一些资料,看见介绍说UFLDL很不 ...
- Deep Learning 10_深度学习UFLDL教程:Convolution and Pooling_exercise(斯坦福大学深度学习教程)
前言 理论知识:UFLDL教程和http://www.cnblogs.com/tornadomeet/archive/2013/04/09/3009830.html 实验环境:win7, matlab ...
- Deep Learning 13_深度学习UFLDL教程:Independent Component Analysis_Exercise(斯坦福大学深度学习教程)
前言 理论知识:UFLDL教程.Deep learning:三十三(ICA模型).Deep learning:三十九(ICA模型练习) 实验环境:win7, matlab2015b,16G内存,2T机 ...
- Deep Learning 12_深度学习UFLDL教程:Sparse Coding_exercise(斯坦福大学深度学习教程)
前言 理论知识:UFLDL教程.Deep learning:二十六(Sparse coding简单理解).Deep learning:二十七(Sparse coding中关于矩阵的范数求导).Deep ...
随机推荐
- php面向对象中public与var的区别
public和var的作用差不多 因为 var定义的变量如果没有加protected 或 private则默认为public php4 中一般是用 varphp5 中就一般是用 public了 现在基 ...
- c#中值类型和引用类型的区别
1. 值类型的数据存储在内存的栈中:引用类型的数据存储在内存的堆中,而内存单元中只存放堆中对象的地址. 2. 值类型存取速度快,引用类型存取速度慢. 3. 值类型表示实际数据,引 ...
- Java学习(简介,软件安装)
1. Java概述: Java的发展可以归纳如下的几个阶段. (1)第一阶段(完善期):JDK 1.0 ( 1995年推出)一JDK 1.2 (1998年推出,Java更名为Java 2): (2)第 ...
- 编辑器之Sublime Text3、Notepad++
Sublime text 3 破解版是一款极其强大的代码编辑器,又是一款可以代替记事本的文本编辑器.Sublime text 3拥有着美观的界面和实用的功能,既能够完成代码的编辑又能够完成文本编辑,还 ...
- 得分(UVa1585)
题目具体描述见:https://uva.onlinejudge.org/index.php?option=com_onlinejudge&Itemid=8&page=show_prob ...
- 修改 jupyter notebook 启动工作路径的方法
Windows下jupyter notebook默认的启动路径就是当前cmd启动jupyter 的路径: C:\Users\用户名>jupyter notebook 此时jupyter 的启动工 ...
- pyqt5最简单的打开和保存文件
import sys import os from PyQt5.QtWidgets import QApplication,QWidget,QFileDialog from t import Ui_F ...
- 开源IDS系列--snorby 2.6.2 undefined method `run_daily_report' for Event:Class (NoMethodError)
rails runner "Event.run_daily_report"测试邮件配置undefined method `run_daily_report' for Event:C ...
- Markdown 格式如何转换成 Word?
参考资料:https://www.zhihu.com/question/22972843/answer/136008865 markdown语法简洁,写作效率极高,非常适合网络博客.邮件.笔记等非正式 ...
- FFT(快速傅里叶变换)
学习了FFT用来求多项式的乘法,看了算导上的介绍,上面讲的非常明白,概括一下FFT的原理就是,我们在计算多项式的乘法时,如果暴力模拟的话是n^2 复杂度的,就像小学学的竖式乘法一样,比如一个n位数乘上 ...