Hadoop2.0环境搭建
需准备的前提条件:
1. 安装JDK(自行安装)
2. 关闭防火墙(centos):
systemctl stop firewalld.service
systemctl disable firewalld.service 编辑 vim /etc/selinux/config文件,修改为:
SELINUX=disabled
源码包下载:
http://archive.apache.org/dist/hadoop/common/
集群环境:
master 192.168.1.99
slave1 192.168.1.100
slave2 192.168.1.101
下载安装包:
# Mater
wget http://mirror.bit.edu.cn/apache/hadoop/common/hadoop-2.7.5/hadoop-2.7.5.tar.gz -C /usr/local/src
tar -zxvf hadoop-2.7.5.tar.gz
mv hadoop-2.7.5 /usr/local/hadoop
配置主机
1、编辑/etc/hostname文件
分别配置主机名为master slave1 slave2
2、编辑/etc/hosts,添加对应的域名和ip
cat /etc/hosts
192.168.1.99 master
192.168.1.100 slave1
192.168.1.101 slave2
3. 配置ssh(自行操作,我这边配置的用户是hadoop)
修改配置文件:
cd /usr/local/hadoop/etc/hadoop
vim hadoop-env.sh
export JAVA_HOME=/usr/local/jdk1.8.0_91
vim yarn-env.sh
export JAVA_HOME=/usr/local/jdk1.8.0_91
slave1
slave2
vim core-site.xml
<configuration>
<property>
<!--指定namenode的地址-->
<name>fs.defaultFS</name>
<value>hdfs://192.168.1.99:9000</value>
</property>
<property>
<!--用来指定使用hadoop时产生文件的存放目录-->
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
</property>
<property>
<!--读写缓存size设定,默认为64M-->
<name>io.file.buffer.size</name>
<value>131702</value>
</property>
</configuration>
vim hdfs-site.xml
<configuration>
<property>
<!--指定hdfs中namenode的存储位置-->
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/dfs/name</value>
</property>
<property>
<!--指定hdfs中datanode的存储位置-->
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/dfs/data</value>
</property>
<property>
<!--指定hdfs保存数据的副本数量-->
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<!--为secondary指定访问ip:port-->
<name>dfs.namenode.secondary.http-address</name>
<value>192.168.1.99:9001</value>
</property>
<property>
<!--设置为True就可以直接用namenode的ip:port进行访问,不需要指定端口-->
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>
vim mapred-site.xml
<configuration>
<property>
<!--告诉hadoop以后MR(Map/Reduce)运行在YARN上-->
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>192.168.1.99:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>192.168.1.99:19888</value>
</property>
</configuration>
vim yarn-site.xml
<configuration>
<property>
<!--nomenodeManager获取数据的方式是shuffle-->
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<!--客户端对ResourceManager主机通过 host:port 提交作业-->
<name>yarn.resourcemanager.address</name>
<value>192.168.1.99:8032</value>
</property>
<property>
<!--ApplicationMasters 通过ResourceManager主机访问host:port跟踪调度程序获资源-->
<name>yarn.resourcemanager.scheduler.address</name>
<value>192.168.1.99:8030</value>
</property>
<property>
<!--NodeManagers通过ResourceManager主机访问host:port-->
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>192.168.1.99:8035</value>
</property>
<property>
<!--管理命令通过ResourceManager主机访问host:port-->
<name>yarn.resourcemanager.admin.address</name>
<value>192.168.1.99:8033</value>
</property>
<property>
<!--ResourceManager web页面host:port.-->
<name>yarn.resourcemanager.webapp.address</name>
<value>192.168.1.99:8088</value>
</property> <!--我们可以指定yarn的master为哪台机器,与namenode分布在不同的机器上面 -->
<!-- <property>
<name>yarn.resourcemanager.hostname</name>
<value>192.168.1.100</value>
</property>
-->
</configuration>
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value>
</property>
#创建临时目录和文件目录
mkdir /usr/local/hadoop/tmp
mkdir -p /usr/local/hadoop/dfs/name
mkdir -p /usr/local/hadoop/dfs/data
配置环境变量:
#Master slave1 slave2
vim ~/.bashrc
HADOOP_HOME=/usr/local/hadoop
PATH=$PATH:$HADOOP_HOME/bin #刷新环境变量
source ~/.bashrc
修改启动脚本保存pid的路径
目的:因为存放pid的路径为/tmp,/tmp是临时目录,系统会定时清理该目录中的文件,所以我们需要修改存放pid的路径
mkdir /usr/local/hadoop/pid
cd /usr/local/hadoop/sbin
sed -i 's/tmp/usr\/local\/hadoop\/pid/g' hadoop-daemon.sh
sed -i 's/tmp/usr\/local\/hadoop\/pid/g' yarn-daemon.sh
拷贝安装包:
# 我用的hadoop用户,需先在从主机上面创建/usr/local/hadoop目录,设置权限chown -R hadoop:hadoop /usr/local/hadoop
rsync -av /usr/local/hadoop/ slave1:/usr/local/hadoop/
rsync -av /usr/local/hadoop/ slave2:/usr/local/hadoop/
启动集群(主机时间需同步):
#初始化Namenode
hadoop namenode -format
./sbin/start-all.sh
集群状态:
#Master

#Slave1
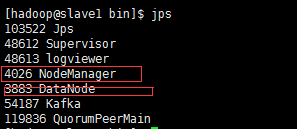
#Slave2

监控网页:
http://master:8088

关闭集群:
./sbin/hadoop stop-all.sh
Hadoop2.0环境搭建的更多相关文章
- ubantu16.04+mxnet +opencv+cuda8.0 环境搭建
ubantu16.04+mxnet +opencv+cuda8.0 环境搭建 建议:环境搭建完成之后,不要更新系统(内核) 转载请注明出处: 微微苏荷 一 我的安装环境 系统:ubuntu16.04 ...
- 菜鸟学自动化测试(八)----selenium 2.0环境搭建(基于maven)
菜鸟学自动化测试(八)----selenium 2.0环境搭建(基于maven) 2012-02-04 13:11 by 虫师, 11419 阅读, 5 评论, 收藏, 编辑 之前我就讲过一种方试来搭 ...
- XNA 4.0 环境搭建和 Hello World,Windows Phone 游戏开发
XNA 4.0 环境搭建和 Hello World,Windows Phone 游戏开发 使用 Scene 类在 XNA 中创建不同的场景(八) 摘要: 平方已经开发了一些 Windows Phone ...
- (win10 64位系统中)Visual Studio 2015+OpenCV 3.3.0环境搭建,100%成功
(win10 64位系统中)Visual Studio 2015+OpenCV 3.3.0环境搭建,100%成功 1.下载opencv 官网http://opencv.org/下载windows版Op ...
- [转]OPENCV3.3+CUDA9.0 环境搭建若干错误总结
编译OpenCV设计启用OpenGL三维可视化支持和启用GPU CUDA并行加速处理的基本知识: 1.从2.4.2版本开始,OpenCV在可视化窗口中支持OpenGL,这就意味着在OpenCV中可以轻 ...
- Hadoop学习笔记—22.Hadoop2.x环境搭建与配置
自从2015年花了2个多月时间把Hadoop1.x的学习教程学习了一遍,对Hadoop这个神奇的小象有了一个初步的了解,还对每次学习的内容进行了总结,也形成了我的一个博文系列<Hadoop学习笔 ...
- vs2012+qt5.2.0环境搭建/vs2013 + qt5.3.2 环境搭建
分类: Windows Qt2014-01-17 00:50 15434人阅读 评论(18) 收藏 举报 此文章已作废,请参考我的新文章: vs2013 + qt5.3.2 环境搭建 ( http:/ ...
- heritrix 3.2.0 -- 环境搭建
heritrix作为一个比较经典的开源爬虫,写这篇文章目的是因为,3.X之后的heritrix的介绍以及配置的文章比较少了. heritrix 3.x 以后使用maven 2配置jar包引用,但是总是 ...
- 云服务器下ASP.NET Core 1.0环境搭建(包含mono与coreclr)
最近.net core如火如荼,国内这方面环境搭建方面的文档也非常多,但是不少已经是过时的,就算按照那个流程走下去也避免不了一些地方早就不一样了.所以下面我将从头到尾的教大家搭建一次环境,并且成功运行 ...
随机推荐
- 三角剖分算法(delaunay)
开篇 在做一个Low Poly的课题,而这种低多边形的成像效果在现在设计中越来越被喜欢,其中的低多边形都是由三角形组成的. 而如何自动生成这些看起来很特殊的三角形,就是本章要讨论的内容. 项目地址: ...
- ios开发之 -- 5分钟集成融云的客服功能
最近项目中遇到了客服的功能,首先想到的就是使用融云的功能,因为以前做的即时通讯的项目,用的都是融云的sdk,花了点时间研究了下,希望能帮到大家! 废话不多说,步骤如下: 一.申请融云账号 二.创建应用 ...
- 第六篇:二维数组的传输 (host <-> device)
前言 本文的目的很明确:介绍如何将二维数组传递进显存,以及如何将二维数组从显存传递回主机端. 实现步骤 1. 在显存中为二维数组开辟空间 2. 获取该二维数组在显存中的 pitch 值 (cudaMa ...
- 面试题思考:Java RMI与RPC,JMS的比较
RPC:(Remote Procedure Call) 被设计为在应用程序间通信的平台中立的方式,它不理会操作系统之间以及语言之间的差异. 支持多语言 RMI:(Remote Method Invo ...
- Influxdb时序数据库阅读笔记
时序数据库 2017年2月Facebook开源了beringei时序数据库:到了4月基于PostgreSQL打造的时序数据库TimeScaleDB也开源了,而早在2016年7月,百度云在其天工物联网平 ...
- __construct __destory __call __get __set
1,__construct() 当实例化一个对象的时候,这个对象的这个方法首先被调用. 我们知道 php5对象模型 < ,所以__construct()作为类的默认的构造函数 而不会调用同类名函 ...
- 【BZOJ4275】[ONTAK2015]Badania naukowe DP
[BZOJ4275][ONTAK2015]Badania naukowe Description 给定三个数字串A,B,C,请找到一个A,B的最长公共子序列,满足C是该子序列的子串. Input 第一 ...
- dbForge mysql数据库比对
Comparison选项卡,新建一个表结构比较, (将source库的表结构变化应用到target库) 下面示例中,source用positec_uat, target用positec_pro ...
- JAVA基础之multipart,urlencoded以及JSON
一.(enctype) 表单的默认编码方式 ajpplication/x-www-form-urlencoded 上传文件的编码方式 multipart/form-data 互联网应用常用编码 ...
- windows server 2008 R2域中的DC部署 分类: AD域 Windows服务 2015-06-06 21:09 68人阅读 评论(0) 收藏
整个晚上脑子都有点呆滞,想起申请注册好的博客还从来都不曾打理,上来添添生机.从哪里讲起呢,去年有那么一段时间整个人就陷在域里拔不出来,于是整理了一些文档,害怕自己糊里糊涂的脑子将这些东西会在一觉醒来全 ...