Apache Hive (七)Hive的DDL操作
转自:https://www.cnblogs.com/qingyunzong/p/8723271.html
库操作
1、创建库
语法结构
CREATE (DATABASE|SCHEMA) [IF NOT EXISTS] database_name
[COMMENT database_comment] //关于数据块的描述
[LOCATION hdfs_path] //指定数据库在HDFS上的存储位置
[WITH DBPROPERTIES (property_name=property_value, ...)]; //指定数据块属性
默认地址:/user/hive/warehouse/db_name.db/table_name/partition_name/…
创建库的方式
(1)创建普通的数据库
0: jdbc:hive2://hadoop3:10000> create database t1;
No rows affected (0.308 seconds)
0: jdbc:hive2://hadoop3:10000> show databases;
+----------------+
| database_name |
+----------------+
| default |
| myhive |
| t1 |
+----------------+
3 rows selected (0.393 seconds)
0: jdbc:hive2://hadoop3:10000>
(2)创建库的时候检查存与否
0: jdbc:hive2://hadoop3:10000> create database if not exists t1;
No rows affected (0.176 seconds)
0: jdbc:hive2://hadoop3:10000>
(3)创建库的时候带注释
0: jdbc:hive2://hadoop3:10000> create database if not exists t2 comment 'learning hive';
No rows affected (0.217 seconds)
0: jdbc:hive2://hadoop3:10000>

(4)创建带属性的库
0: jdbc:hive2://hadoop3:10000> create database if not exists t3 with dbproperties('creator'='hadoop','date'='2018-04-05');
No rows affected (0.255 seconds)
0: jdbc:hive2://hadoop3:10000>
2、查看库
查看库的方式
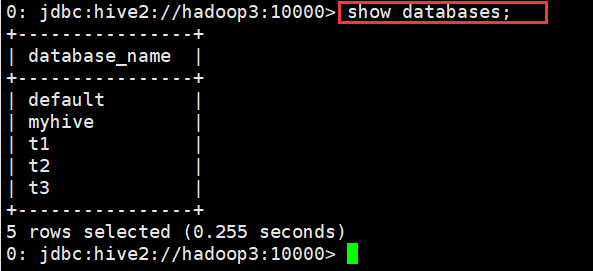
(1)查看有哪些数据库
0: jdbc:hive2://hadoop3:10000> show databases;
+----------------+
| database_name |
+----------------+
| default |
| myhive |
| t1 |
| t2 |
| t3 |
+----------------+
5 rows selected (0.164 seconds)
0: jdbc:hive2://hadoop3:10000>
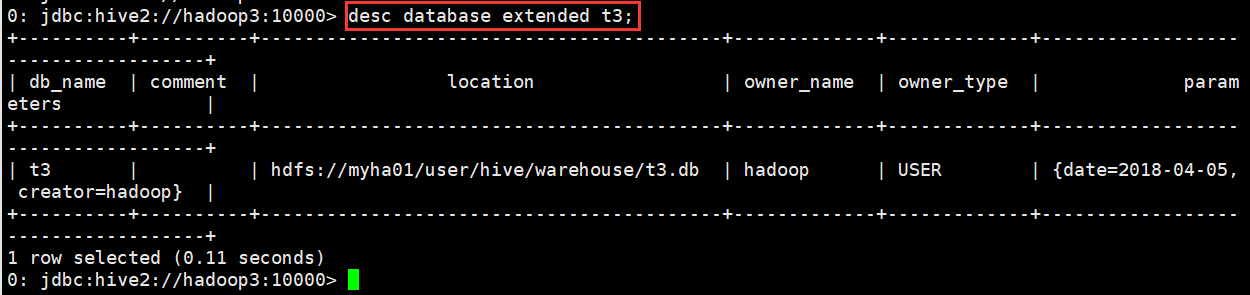
(2)显示数据库的详细属性信息
语法
desc database [extended] dbname;
示例
0: jdbc:hive2://hadoop3:10000> desc database extended t3;
+----------+----------+------------------------------------------+-------------+-------------+------------------------------------+
| db_name | comment | location | owner_name | owner_type | parameters |
+----------+----------+------------------------------------------+-------------+-------------+------------------------------------+
| t3 | | hdfs://myha01/user/hive/warehouse/t3.db | hadoop | USER | {date=2018-04-05, creator=hadoop} |
+----------+----------+------------------------------------------+-------------+-------------+------------------------------------+
1 row selected (0.11 seconds)
0: jdbc:hive2://hadoop3:10000>
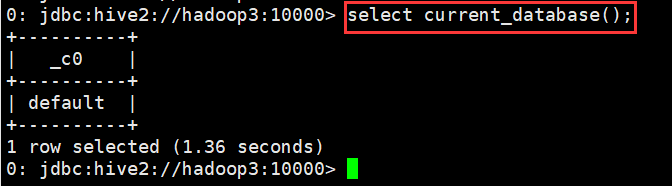
(3)查看正在使用哪个库
0: jdbc:hive2://hadoop3:10000> select current_database();
+----------+
| _c0 |
+----------+
| default |
+----------+
1 row selected (1.36 seconds)
0: jdbc:hive2://hadoop3:10000>
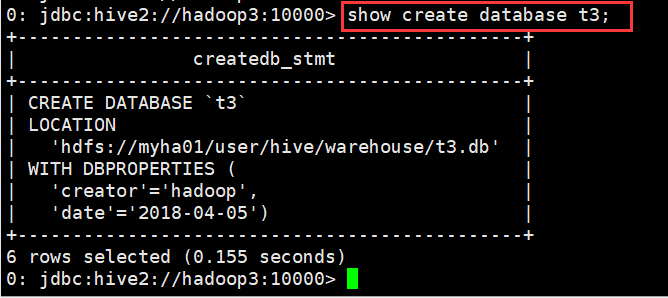
(4)查看创建库的详细语句
0: jdbc:hive2://hadoop3:10000> show create database t3;
+----------------------------------------------+
| createdb_stmt |
+----------------------------------------------+
| CREATE DATABASE `t3` |
| LOCATION |
| 'hdfs://myha01/user/hive/warehouse/t3.db' |
| WITH DBPROPERTIES ( |
| 'creator'='hadoop', |
| 'date'='2018-04-05') |
+----------------------------------------------+
6 rows selected (0.155 seconds)
0: jdbc:hive2://hadoop3:10000>
3、删除库
说明
删除库操作
drop database dbname;
drop database if exists dbname;
默认情况下,hive 不允许删除包含表的数据库,有两种解决办法:
1、 手动删除库下所有表,然后删除库
2、 使用 cascade 关键字
drop database if exists dbname cascade;
默认情况下就是 restrict drop database if exists myhive ==== drop database if exists myhive restrict
示例
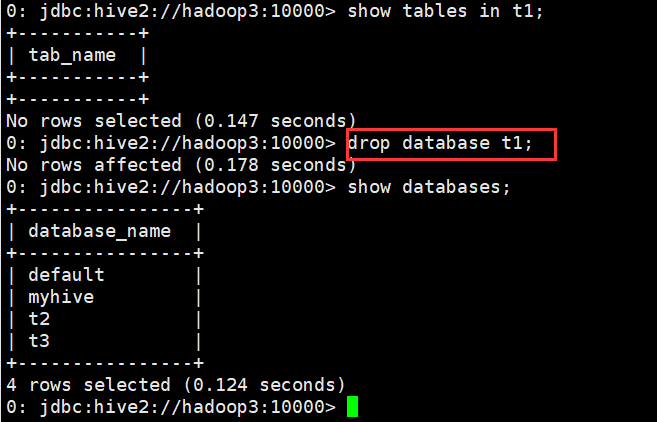
(1)删除不含表的数据库
0: jdbc:hive2://hadoop3:10000> show tables in t1;
+-----------+
| tab_name |
+-----------+
+-----------+
No rows selected (0.147 seconds)
0: jdbc:hive2://hadoop3:10000> drop database t1;
No rows affected (0.178 seconds)
0: jdbc:hive2://hadoop3:10000> show databases;
+----------------+
| database_name |
+----------------+
| default |
| myhive |
| t2 |
| t3 |
+----------------+
4 rows selected (0.124 seconds)
0: jdbc:hive2://hadoop3:10000>
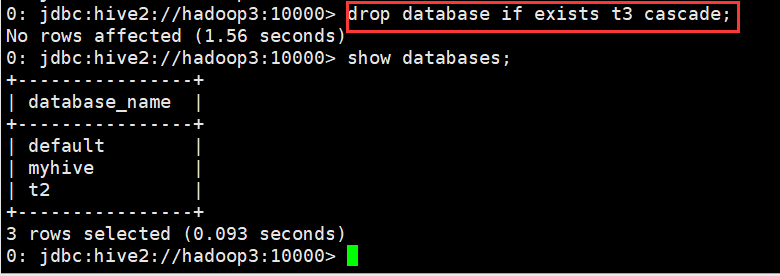
(2)删除含有表的数据库
0: jdbc:hive2://hadoop3:10000> drop database if exists t3 cascade;
No rows affected (1.56 seconds)
0: jdbc:hive2://hadoop3:10000>
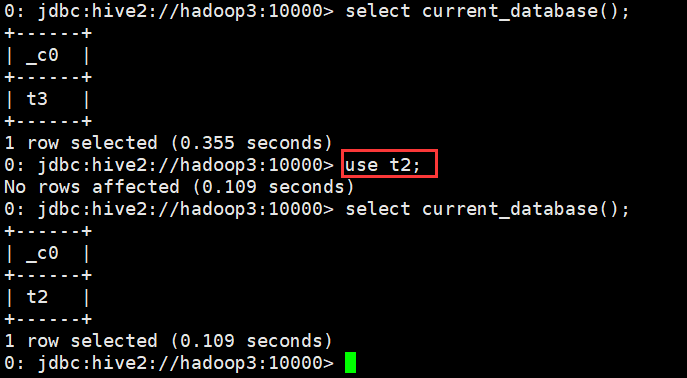
4、切换库
语法
use database_name
示例
0: jdbc:hive2://hadoop3:10000> use t2;
No rows affected (0.109 seconds)
0: jdbc:hive2://hadoop3:10000>
表操作
1、创建表
语法
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name
[(col_name data_type [COMMENT col_comment], ...)]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
[CLUSTERED BY (col_name, col_name, ...)
[SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[ROW FORMAT row_format]
[STORED AS file_format]
[LOCATION hdfs_path]
详情请参见: https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DDL#LanguageManualD DL-CreateTable
•CREATE TABLE 创建一个指定名字的表。如果相同名字的表已经存在,则抛出异常;用户可以用 IF NOT EXIST 选项来忽略这个异常
•EXTERNAL 关键字可以让用户创建一个外部表,在建表的同时指定一个指向实际数据的路径(LOCATION)
•LIKE 允许用户复制现有的表结构,但是不复制数据
•COMMENT可以为表与字段增加描述
•PARTITIONED BY 指定分区
•ROW FORMAT
DELIMITED [FIELDS TERMINATED BY char] [COLLECTION ITEMS TERMINATED BY char]
MAP KEYS TERMINATED BY char] [LINES TERMINATED BY char]
| SERDE serde_name [WITH SERDEPROPERTIES
(property_name=property_value, property_name=property_value, ...)]
用户在建表的时候可以自定义 SerDe 或者使用自带的 SerDe。如果没有指定 ROW FORMAT 或者 ROW FORMAT DELIMITED,将会使用自带的 SerDe。在建表的时候,
用户还需要为表指定列,用户在指定表的列的同时也会指定自定义的 SerDe,Hive 通过 SerDe 确定表的具体的列的数据。
•STORED AS
SEQUENCEFILE //序列化文件
| TEXTFILE //普通的文本文件格式
| RCFILE //行列存储相结合的文件
| INPUTFORMAT input_format_classname OUTPUTFORMAT output_format_classname //自定义文件格式
如果文件数据是纯文本,可以使用 STORED AS TEXTFILE。如果数据需要压缩,使用 STORED AS SEQUENCE 。
•LOCATION指定表在HDFS的存储路径
最佳实践:
如果一份数据已经存储在HDFS上,并且要被多个用户或者客户端使用,最好创建外部表
反之,最好创建内部表。
如果不指定,就按照默认的规则存储在默认的仓库路径中。
示例
使用t2数据库进行操作
(1)创建默认的内部表
0: jdbc:hive2://hadoop3:10000> create table student(id int, name string, sex string, age int,department string) row format delimited fields terminated by ",";
No rows affected (0.222 seconds)
0: jdbc:hive2://hadoop3:10000> desc student;
+-------------+------------+----------+
| col_name | data_type | comment |
+-------------+------------+----------+
| id | int | |
| name | string | |
| sex | string | |
| age | int | |
| department | string | |
+-------------+------------+----------+
5 rows selected (0.168 seconds)
0: jdbc:hive2://hadoop3:10000>

(2)外部表
0: jdbc:hive2://hadoop3:10000> create external table student_ext
(id int, name string, sex string, age int,department string) row format delimited fields terminated by "," location "/hive/student";
No rows affected (0.248 seconds)
0: jdbc:hive2://hadoop3:10000>
(3)分区表
0: jdbc:hive2://hadoop3:10000> create external table student_ptn(id int, name string, sex string, age int,department string)
. . . . . . . . . . . . . . .> partitioned by (city string)
. . . . . . . . . . . . . . .> row format delimited fields terminated by ","
. . . . . . . . . . . . . . .> location "/hive/student_ptn";
No rows affected (0.24 seconds)
0: jdbc:hive2://hadoop3:10000>
添加分区
0: jdbc:hive2://hadoop3:10000> alter table student_ptn add partition(city="beijing");
No rows affected (0.269 seconds)
0: jdbc:hive2://hadoop3:10000> alter table student_ptn add partition(city="shenzhen");
No rows affected (0.236 seconds)
0: jdbc:hive2://hadoop3:10000>
如果某张表是分区表。那么每个分区的定义,其实就表现为了这张表的数据存储目录下的一个子目录
如果是分区表。那么数据文件一定要存储在某个分区中,而不能直接存储在表中。
(4)分桶表
0: jdbc:hive2://hadoop3:10000> create external table student_bck(id int, name string, sex string, age int,department string)
. . . . . . . . . . . . . . .> clustered by (id) sorted by (id asc, name desc) into 4 buckets
. . . . . . . . . . . . . . .> row format delimited fields terminated by ","
. . . . . . . . . . . . . . .> location "/hive/student_bck";
No rows affected (0.216 seconds)
0: jdbc:hive2://hadoop3:10000>
(5)使用CTAS创建表
作用: 就是从一个查询SQL的结果来创建一个表进行存储
现象student表中导入数据
0: jdbc:hive2://hadoop3:10000> load data local inpath "/home/hadoop/student.txt" into table student;
No rows affected (0.715 seconds)
0: jdbc:hive2://hadoop3:10000> select * from student;
+-------------+---------------+--------------+--------------+---------------------+
| student.id | student.name | student.sex | student.age | student.department |
+-------------+---------------+--------------+--------------+---------------------+
| 95002 | 刘晨 | 女 | 19 | IS |
| 95017 | 王风娟 | 女 | 18 | IS |
| 95018 | 王一 | 女 | 19 | IS |
| 95013 | 冯伟 | 男 | 21 | CS |
| 95014 | 王小丽 | 女 | 19 | CS |
| 95019 | 邢小丽 | 女 | 19 | IS |
| 95020 | 赵钱 | 男 | 21 | IS |
| 95003 | 王敏 | 女 | 22 | MA |
| 95004 | 张立 | 男 | 19 | IS |
| 95012 | 孙花 | 女 | 20 | CS |
| 95010 | 孔小涛 | 男 | 19 | CS |
| 95005 | 刘刚 | 男 | 18 | MA |
| 95006 | 孙庆 | 男 | 23 | CS |
| 95007 | 易思玲 | 女 | 19 | MA |
| 95008 | 李娜 | 女 | 18 | CS |
| 95021 | 周二 | 男 | 17 | MA |
| 95022 | 郑明 | 男 | 20 | MA |
| 95001 | 李勇 | 男 | 20 | CS |
| 95011 | 包小柏 | 男 | 18 | MA |
| 95009 | 梦圆圆 | 女 | 18 | MA |
| 95015 | 王君 | 男 | 18 | MA |
+-------------+---------------+--------------+--------------+---------------------+
21 rows selected (0.342 seconds)
0: jdbc:hive2://hadoop3:10000>
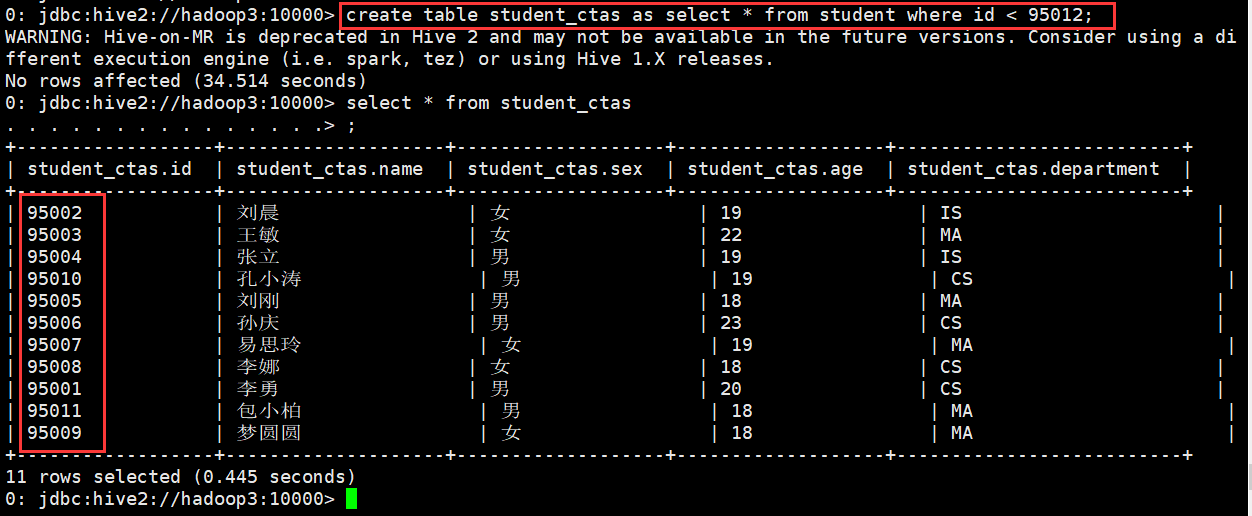
使用CTAS创建表
0: jdbc:hive2://hadoop3:10000> create table student_ctas as select * from student where id < 95012;
WARNING: Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution
engine (i.e. spark, tez) or using Hive 1.X releases.
No rows affected (34.514 seconds)
0: jdbc:hive2://hadoop3:10000> select * from student_ctas
. . . . . . . . . . . . . . .> ;
+------------------+--------------------+-------------------+-------------------+--------------------------+
| student_ctas.id | student_ctas.name | student_ctas.sex | student_ctas.age | student_ctas.department |
+------------------+--------------------+-------------------+-------------------+--------------------------+
| 95002 | 刘晨 | 女 | 19 | IS |
| 95003 | 王敏 | 女 | 22 | MA |
| 95004 | 张立 | 男 | 19 | IS |
| 95010 | 孔小涛 | 男 | 19 | CS |
| 95005 | 刘刚 | 男 | 18 | MA |
| 95006 | 孙庆 | 男 | 23 | CS |
| 95007 | 易思玲 | 女 | 19 | MA |
| 95008 | 李娜 | 女 | 18 | CS |
| 95001 | 李勇 | 男 | 20 | CS |
| 95011 | 包小柏 | 男 | 18 | MA |
| 95009 | 梦圆圆 | 女 | 18 | MA |
+------------------+--------------------+-------------------+-------------------+--------------------------+
11 rows selected (0.445 seconds)
0: jdbc:hive2://hadoop3:10000>
(6)复制表结构
0: jdbc:hive2://hadoop3:10000> create table student_copy like student;
No rows affected (0.217 seconds)
0: jdbc:hive2://hadoop3:10000>
注意:
如果在table的前面没有加external关键字,那么复制出来的新表。无论如何都是内部表
如果在table的前面有加external关键字,那么复制出来的新表。无论如何都是外部表

2、查看表
(1)查看表列表
查看当前使用的数据库中有哪些表
0: jdbc:hive2://hadoop3:10000> show tables;
+---------------+
| tab_name |
+---------------+
| student |
| student_bck |
| student_copy |
| student_ctas |
| student_ext |
| student_ptn |
+---------------+
6 rows selected (0.163 seconds)
0: jdbc:hive2://hadoop3:10000>
查看非当前使用的数据库中有哪些表
0: jdbc:hive2://hadoop3:10000> show tables in myhive;
+-----------+
| tab_name |
+-----------+
| student |
+-----------+
1 row selected (0.144 seconds)
0: jdbc:hive2://hadoop3:10000>
查看数据库中以xxx开头的表
0: jdbc:hive2://hadoop3:10000> show tables like 'student_c*';
+---------------+
| tab_name |
+---------------+
| student_copy |
| student_ctas |
+---------------+
2 rows selected (0.13 seconds)
0: jdbc:hive2://hadoop3:10000>
(2)查看表的详细信息
查看表的信息
0: jdbc:hive2://hadoop3:10000> desc student;
+-------------+------------+----------+
| col_name | data_type | comment |
+-------------+------------+----------+
| id | int | |
| name | string | |
| sex | string | |
| age | int | |
| department | string | |
+-------------+------------+----------+
5 rows selected (0.149 seconds)
0: jdbc:hive2://hadoop3:10000>
查看表的详细信息(格式不友好)
0: jdbc:hive2://hadoop3:10000> desc extended student;
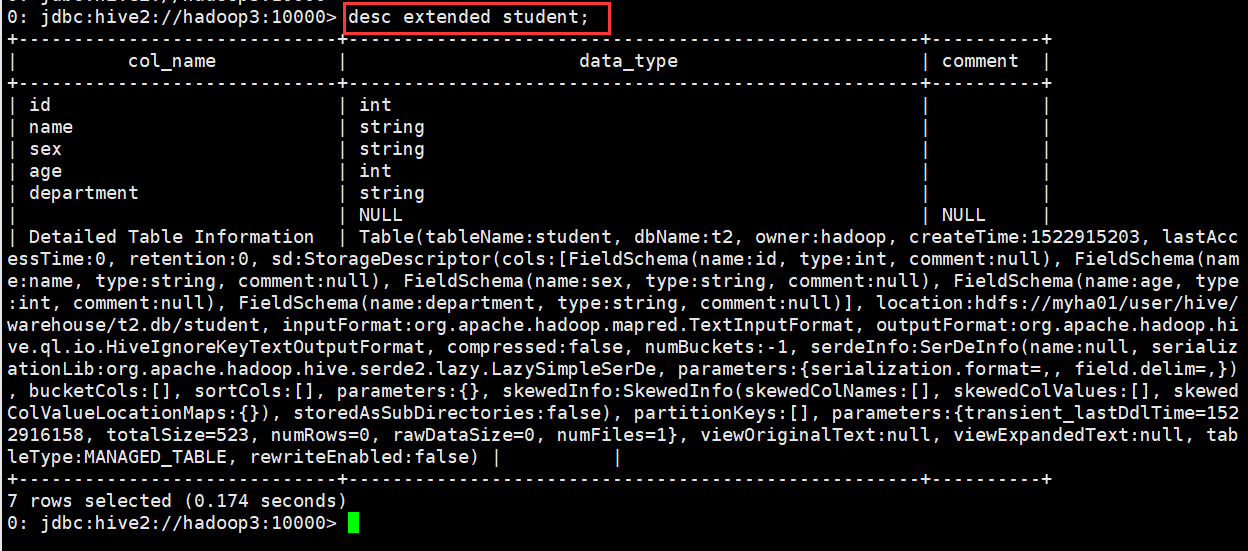
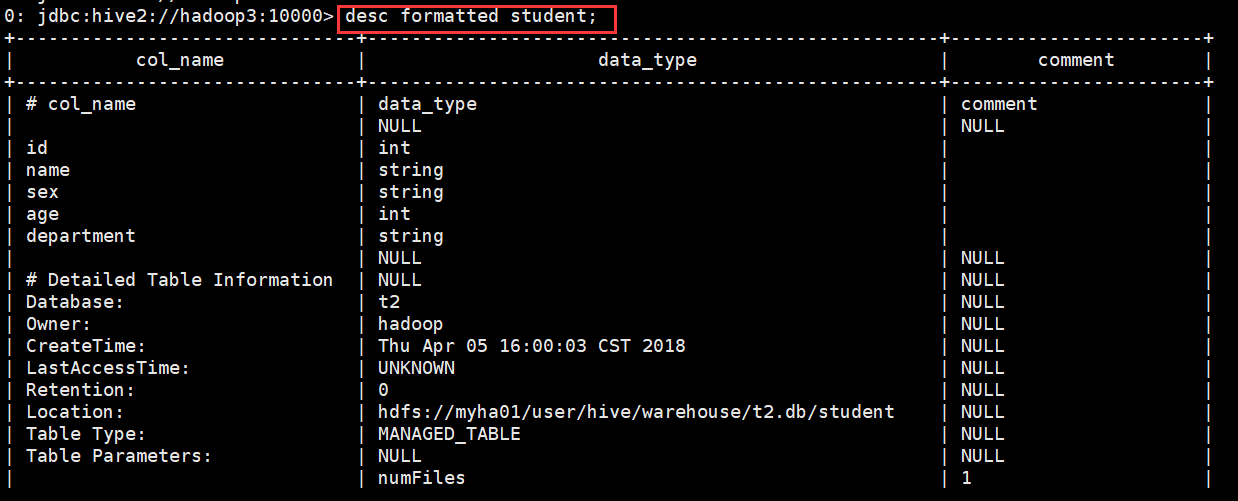
查看表的详细信息(格式友好)
0: jdbc:hive2://hadoop3:10000> desc formatted student;
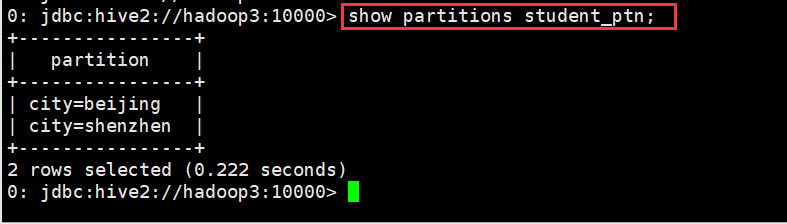
查看分区信息
0: jdbc:hive2://hadoop3:10000> show partitions student_ptn;
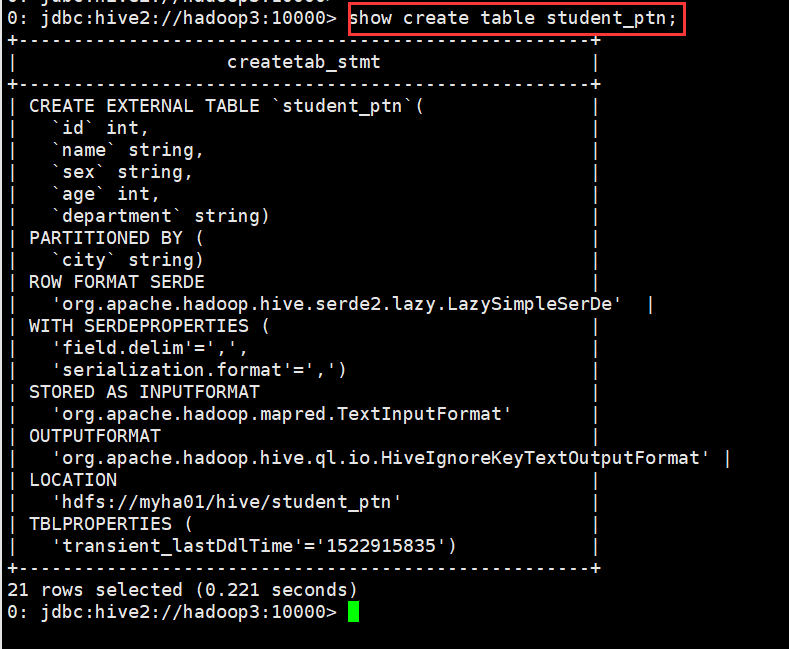
(3)查看表的详细建表语句
0: jdbc:hive2://hadoop3:10000> show create table student_ptn;
3、修改表
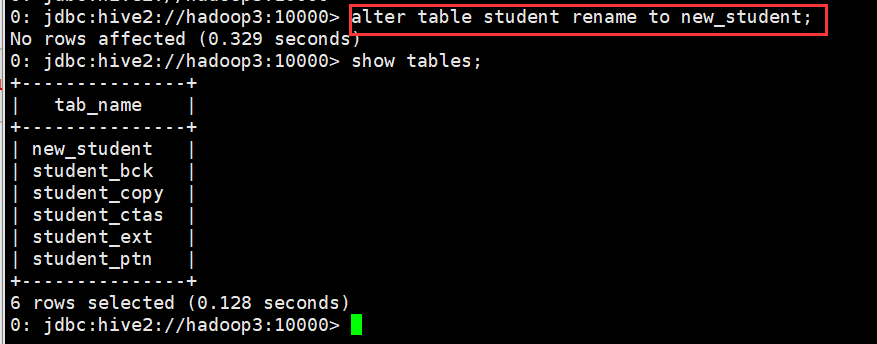
(1)修改表名
0: jdbc:hive2://hadoop3:10000> alter table student rename to new_student;
(2)修改字段定义
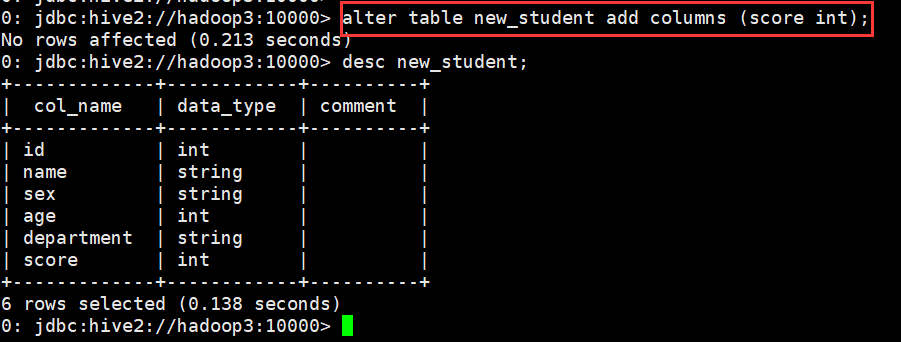
A. 增加一个字段
0: jdbc:hive2://hadoop3:10000> alter table new_student add columns (score int);
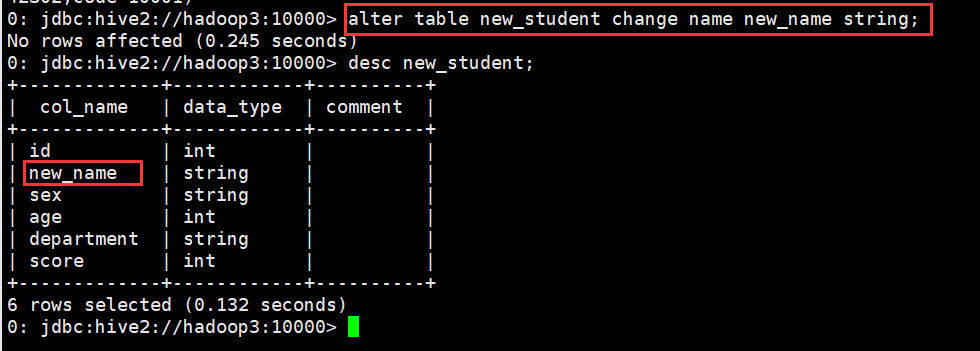
B. 修改一个字段的定义
0: jdbc:hive2://hadoop3:10000> alter table new_student change name new_name string;
C. 删除一个字段
不支持
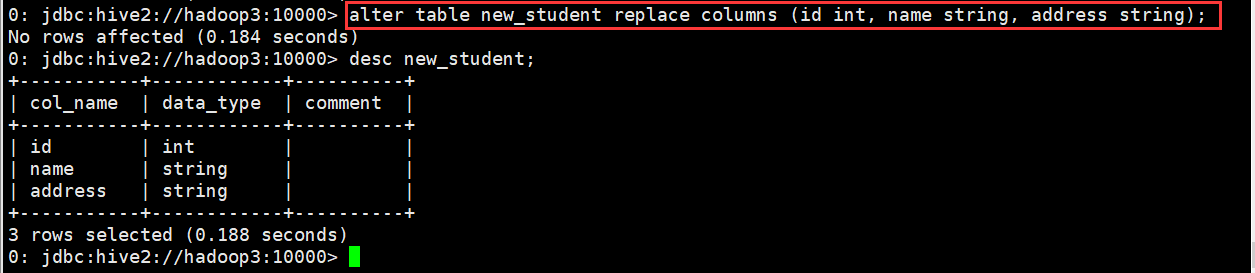
D. 替换所有字段
0: jdbc:hive2://hadoop3:10000> alter table new_student replace columns (id int, name string, address string);
(3)修改分区信息
A. 添加分区
静态分区
添加一个
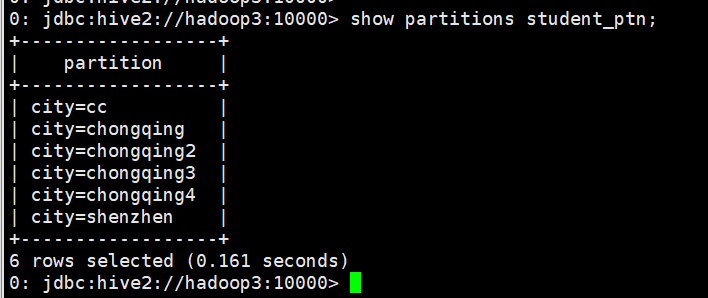
0: jdbc:hive2://hadoop3:10000> alter table student_ptn add partition(city="chongqing");
添加多个
0: jdbc:hive2://hadoop3:10000> alter table student_ptn add partition(city="chongqing2") partition(city="chongqing3") partition(city="chongqing4");
动态分区
先向student_ptn表中插入数据,数据格式如下图
0: jdbc:hive2://hadoop3:10000> load data local inpath "/home/hadoop/student.txt" into table student_ptn partition(city="beijing");
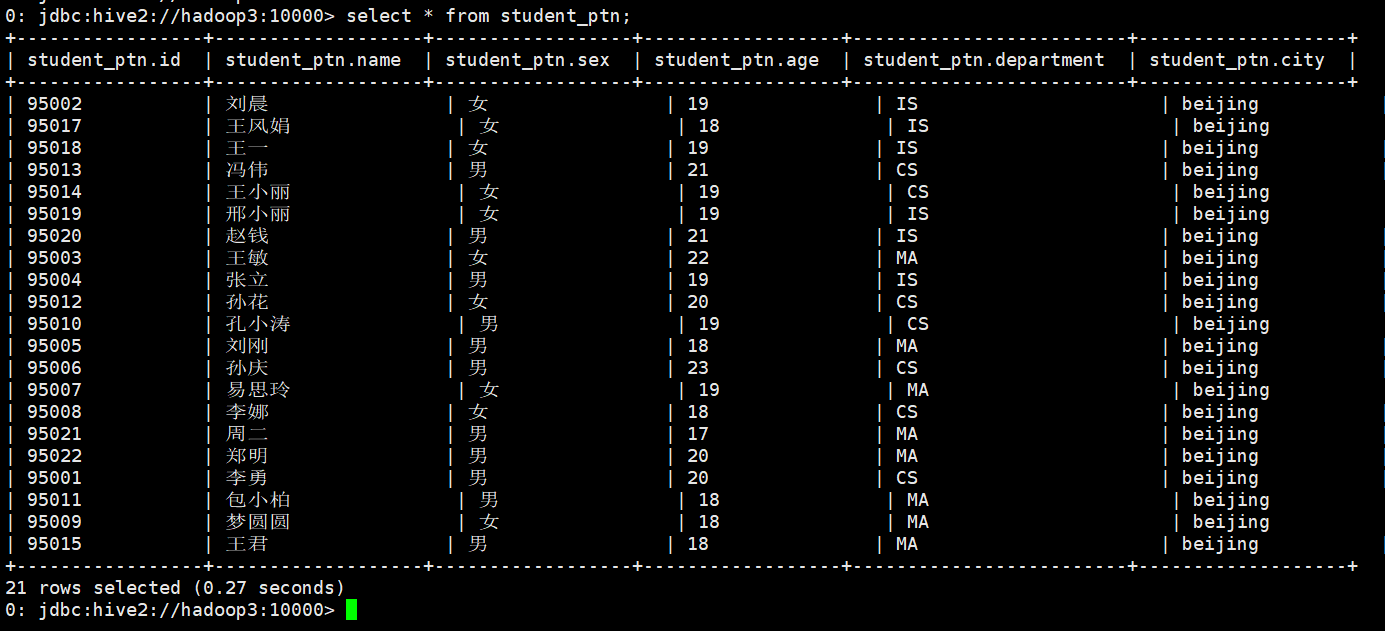
现在我把这张表的内容直接插入到另一张表student_ptn_age中,并实现sex为动态分区(不指定到底是哪中性别,让系统自己分配决定)
首先创建student_ptn_age并指定分区为age
0: jdbc:hive2://hadoop3:10000> create table student_ptn_age(id int,name string,sex string,department string) partitioned by (age int);
从student_ptn表中查询数据并插入student_ptn_age表中
0: jdbc:hive2://hadoop3:10000> insert overwrite table student_ptn_age partition(age)
. . . . . . . . . . . . . . .> select id,name,sex,department,age from student_ptn;
WARNING: Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
No rows affected (27.905 seconds)
0: jdbc:hive2://hadoop3:10000>
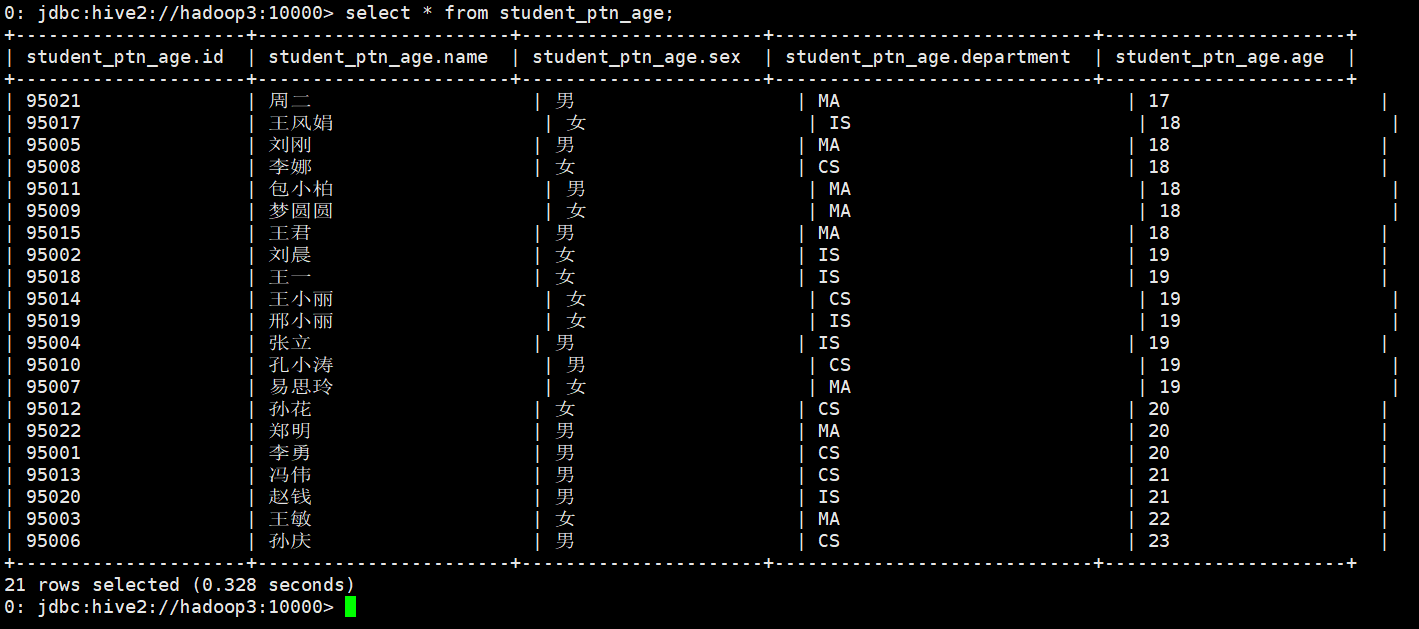
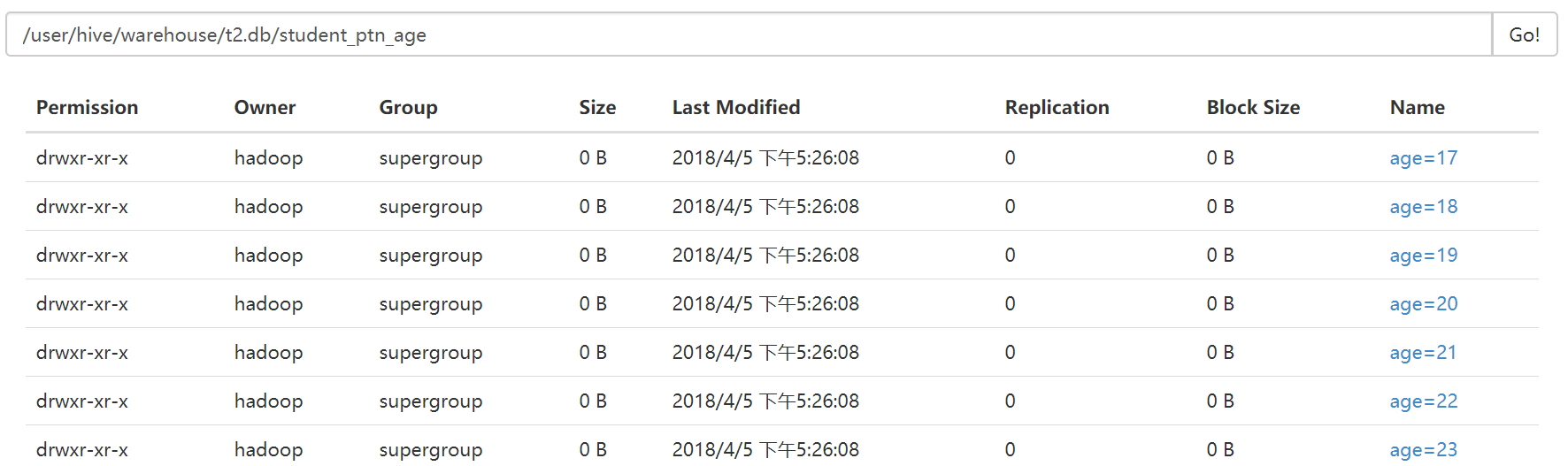
B. 修改分区
修改分区,一般来说,都是指修改分区的数据存储目录
在添加分区的时候,直接指定当前分区的数据存储目录
0: jdbc:hive2://hadoop3:10000> alter table student_ptn add if not exists partition(city='beijing')
. . . . . . . . . . . . . . .> location '/student_ptn_beijing' partition(city='cc') location '/student_cc';
No rows affected (0.306 seconds)
0: jdbc:hive2://hadoop3:10000>
修改已经指定好的分区的数据存储目录
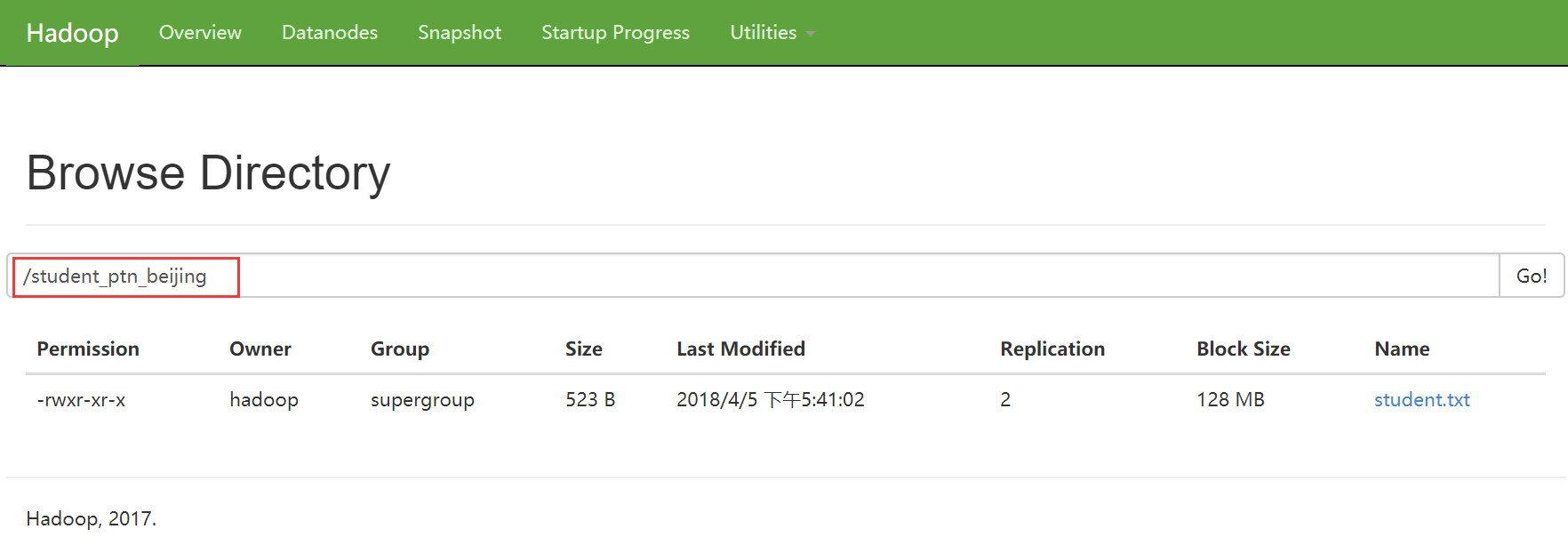
0: jdbc:hive2://hadoop3:10000> alter table student_ptn partition (city='beijing') set location '/student_ptn_beijing';
此时原先的分区文件夹仍存在,但是在往分区添加数据时,只会添加到新的分区目录
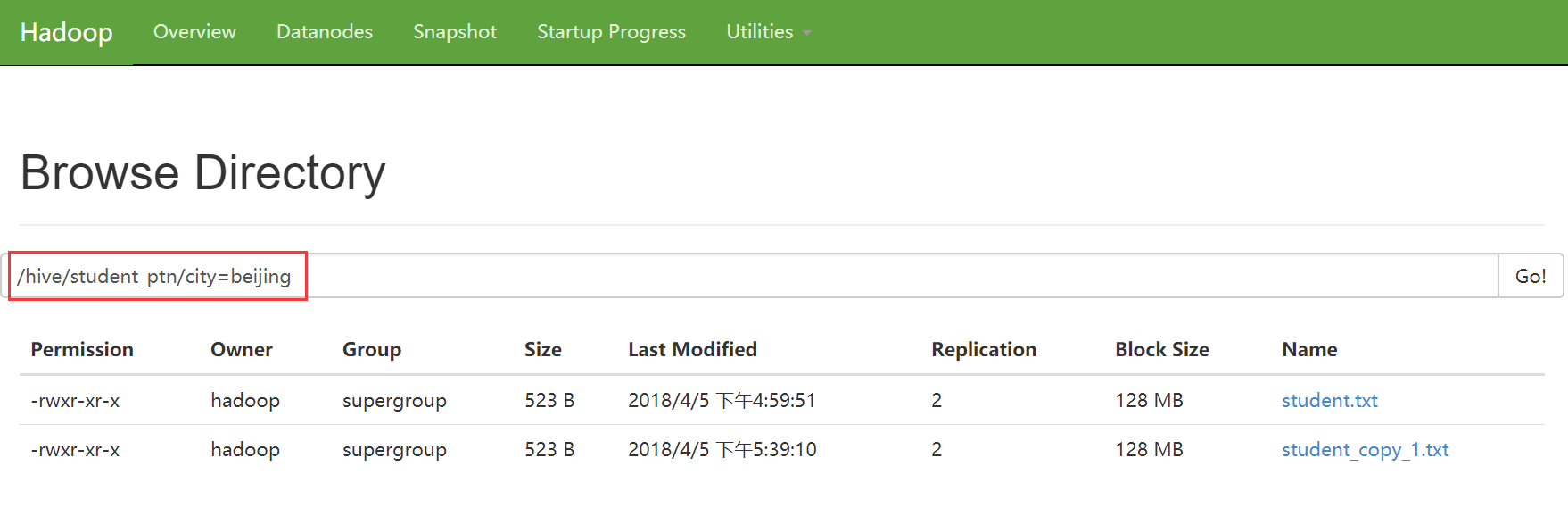
C. 删除分区
0: jdbc:hive2://hadoop3:10000> alter table student_ptn drop partition (city='beijing');
4、删除表
0: jdbc:hive2://hadoop3:10000> drop table new_student;
5、清空表
0: jdbc:hive2://hadoop3:10000> truncate table student_ptn;
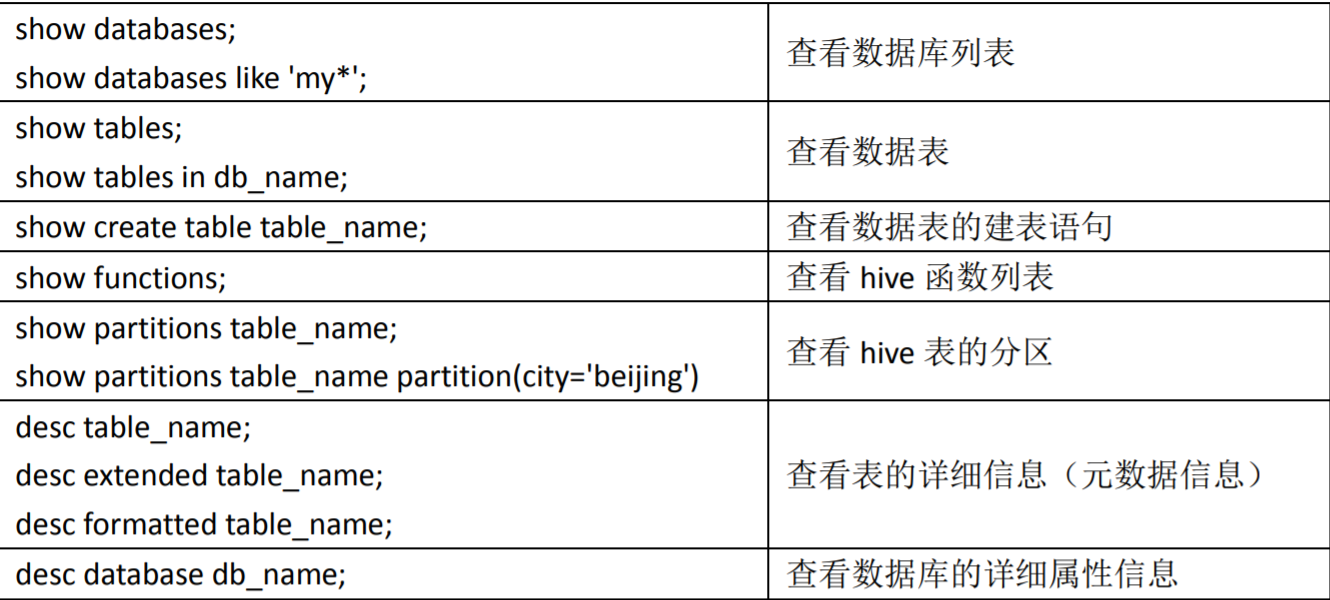
其他辅助命令

Apache Hive (七)Hive的DDL操作的更多相关文章
- Hive数据类型和DDL操作
hive命令 在Linux下的命令行中直接输入如下命令,可以查看帮助信息: # hive -help 常用的如-e.-f参数. 使用-e参数,可以直接在命令行传递SQL语句进行hive表数据的查询: ...
- [Apache Doris] Apache Doris 元数据设计及DDL操作源码阅读
元数据设计 如上图,Doris 的元数据主要存储4类数据: 用户数据信息.包括数据库.表的 Schema.分片信息等. 各类作业信息.如导入作业,Clone 作业.SchemaChange 作业等. ...
- Hive的DDL操作
DDL:data definittion language 数据定义语言 主要是定义或改变表的结构.数据类型.表之间的链接和约束等初始化操作 DML:data manipulation languag ...
- Hive学习笔记(三)-- DML和DDL操作
01-Hive表的DDL操作--修改表 创建一个分区表并加载数据 查询数据 修改表 加载数据 查询一下 另外一个命令查询表的分区 如何删除一个分区呢 查询一个,分区被删除了 修改表名 查询改名的新表的 ...
- HADOOP docker(七):hive权限管理
1. hive权限简介1.1 hive中的用户与组1.2 使用场景1.3 权限模型1.3 hive的超级用户2. 授权管理2.1 开启权限管理2.2 实现超级用户2.3 实现hiveserver2用户 ...
- Hive 文件格式 & Hive操作(外部表、内部表、区、桶、视图、索引、join用法、内置操作符与函数、复合类型、用户自定义函数UDF、查询优化和权限控制)
本博文的主要内容如下: Hive文件存储格式 Hive 操作之表操作:创建外.内部表 Hive操作之表操作:表查询 Hive操作之表操作:数据加载 Hive操作之表操作:插入单表.插入多表 Hive语 ...
- Hive的基本知识与操作
Hive的基本知识与操作 目录 Hive的基本知识与操作 Hive的基本概念 为什么使用Hive? Hive的特点: Hive的优缺点: Hive应用场景 Hive架构 Client Metastor ...
- Hive数据据类型 DDL DML
Hive的基本数据类型 DDL DML: 基本数据类型 对于Hive而言String类型相当于数据库的varchar类型,该类型是一个可变的字符串,不过它不能声明其中最多能存储多少个字符,理论上它可以 ...
- Hive命令行经常使用操作(数据库操作,表操作)
数据库操作 查看全部的数据库 hive> show databases ; 使用数据库default hive> use default; 查看数据库信息 hive > descri ...
- Apache Hudi 与 Hive 集成手册
1. Hudi表对应的Hive外部表介绍 Hudi源表对应一份HDFS数据,可以通过Spark,Flink 组件或者Hudi客户端将Hudi表的数据映射为Hive外部表,基于该外部表, Hive可以方 ...
随机推荐
- pymongo和mongodbengine之间的区别
pymongo是一个mongo driver,可以用来连接数据库以及对数据库进行操作,但是是用mongo自己的用来操作数据库的语句进行操作数据库,而mongodbengine就像是sqlalchemy ...
- nginx fastcgi 优化
fastcgi_cache_path /usr/local/nginx/fastcgi_cache levels=1:2 keys_zone=TEST:10m inactive=5m; fastcgi ...
- C#机器学习插件 ---- AForge.NET
目录 简介 主要架构 特点 学习之旅 简介 AForge.NET是一个专门为开发者和研究者基于C#框架设计的,这个框架提供了不同的类库和关于类库的资源,还有很多应用程序例子,包括计算机视觉与人工智能, ...
- php+ajax+jquery 定时刷新页面数据
testajax.php <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http: ...
- bzoj 3779 重组病毒——LCT维护子树信息
题目:https://www.lydsy.com/JudgeOnline/problem.php?id=3779 调了很久……已经懒得写题解了.https://www.cnblogs.com/Zinn ...
- (转)Tomcat迁移JBoss杂症—不识别及不能解析web.xml
本文介绍了在将tomcat下的web工程迁移到jboss下面时遇到的问题 背景: Tomcat 7.0 JBoss AS 4.2.2 IED: Eclipse Java EE IDE for Web ...
- JavaFX 之窗口大小自由拉伸(四)
一.问题场景 同样的,隐藏掉窗体的默认标题栏也会导致窗体大小自由拉伸功能的失效. 二.解决思路 判断鼠标在窗体的位置,改变鼠标样式,给窗体组件添加拖拽事件监听器,根据鼠标移动位置改变窗体大小. 三.代 ...
- 相关TableLayoutPanel分页显示自定义控件
public partial class AcrossGrid : UserControl { /// <summary> /// 一页数量 /// </summary> ; ...
- 多分类下的ROC曲线和AUC
本文主要介绍一下多分类下的ROC曲线绘制和AUC计算,并以鸢尾花数据为例,简单用python进行一下说明.如果对ROC和AUC二分类下的概念不是很了解,可以先参考下这篇文章:http://blog.c ...
- sys模块的问题,深浅COPY的应用场景,元祖与购物车程序练习-打印彩色\033[31;1m--------\033[0m
打印彩色:%s为变量,格式化 print("Added %s into shopping cart,your current balance is \033[31;1m%s\033[0m&q ...