Deep Learning 阅读笔记:Convolutional Auto-Encoders 卷积神经网络的自编码表达
需要搭建一个比较复杂的CNN网络,希望通过预训练来提高CNN的表现。
上网找了一下,关于CAE(Convolutional Auto-Encoders)的文章还真是少,勉强只能找到一篇瑞士的文章、
Stacked Convolutional Auto-Encoders for Hierarchical Feature Extraction
干货少,不过好歹有对模型的描述,拿来看看。

概述:
本文提出了一种卷积神经网络的自编码表达,用于对卷积神经网络进行预训练。
具体内容:
原文废话挺多,我只关心模型——CAE:
卷积层的获得: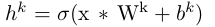
再表达: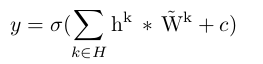
其中“ * ”表示卷积;再表达的系数矩阵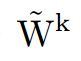 是卷积矩阵
是卷积矩阵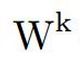 在两个维度上的翻转(rot180)。
在两个维度上的翻转(rot180)。
关于CAE的具体结构论文讲得不清不楚(果真是水),这里有两个明显的问题:一是两次用同样大小卷积核做的卷积如何恢复原来图像的大小,论文中提到full convolution和valid convolution,大概是指两次卷积的卷积方法不同;另一个就是用卷积核的反转卷积隐藏层的意义和作用何在,这个实在是无端端冒出来的计算方法;
输出的误差使用均方误差MSE:
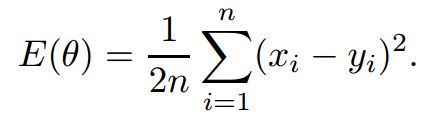
偏导的求法:
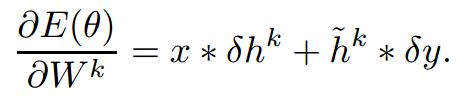
deltaH和deltaY分别是隐藏层和输出层的敏感度。这里又有问题:只有一个隐藏层怎么来敏感度?如果是反向传播怎么传播过去?论文此处的“ * ”还是代表的是卷积吗?如果是的话用的是full还是valid?为什么用隐藏层和敏感度做运算而不是卷积核?这个公式到底怎么来的?(天到底是我太水还是论文太渣)
接着论文提到了在非监督学习下的non-overlapping maxpooling。说这东西真是厉害,maxpooling抹去了区域非最大值,因此引入稀疏性。强大到甚至连稀疏性惩罚项都不用就可以获得好结果。(你给我讲清楚为什么啊喂!)
试验结果:
论文使用MNIST和CIFAR10数据库各做了4组实验,每组训练20个features,结果如下:
MNIST:

CIFAR10:

其中a)是简单的CAE,b)引入了30%噪声,C)引入maxpooling,D)引入maxpooling和30%噪声。
单从这两组结果来看有maxpooling的CAE,通过训练获得较好特征。
与其他方法对比:
文中最后利用CAE做pretraining训练一个6层隐藏层的CNN,与无pretraining的CNN相比,其实提高不明显。
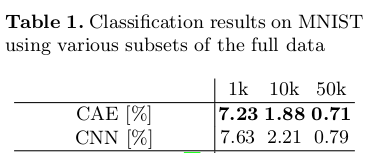

感想:看完这篇文章对我想构建的CAE貌似没有太大的帮助,因为此文章在实践方面的细节和数学过程的推导都是一笔带过,没有详尽描述。(到底是我水还是文章水)
Deep Learning 阅读笔记:Convolutional Auto-Encoders 卷积神经网络的自编码表达的更多相关文章
- Spark MLlib Deep Learning Convolution Neural Network (深度学习-卷积神经网络)3.1
3.Spark MLlib Deep Learning Convolution Neural Network (深度学习-卷积神经网络)3.1 http://blog.csdn.net/sunbow0 ...
- Spark MLlib Deep Learning Convolution Neural Network (深度学习-卷积神经网络)3.2
3.Spark MLlib Deep Learning Convolution Neural Network(深度学习-卷积神经网络)3.2 http://blog.csdn.net/sunbow0 ...
- Spark MLlib Deep Learning Convolution Neural Network (深度学习-卷积神经网络)3.3
3.Spark MLlib Deep Learning Convolution Neural Network(深度学习-卷积神经网络)3.3 http://blog.csdn.net/sunbow0 ...
- “Deep models under the GAN: information leakage from collaborative deep learning”阅读笔记
一.摘要 指出深度学习在机器学习场景下的优势,以及深度学习快速崛起的原因.随后点出研究者对于深度学习隐私问题的考虑.作者提出了一种强力的攻击方法,在其攻击下任何分布式.联邦式.或者中心化的深度学习方法 ...
- Neural Networks and Deep Learning 课程笔记(第二周)神经网络的编程基础 (Basics of Neural Network programming)
总结 一.处理数据 1.1 向量化(vectorization) (height, width, 3) ===> 展开shape为(heigh*width*3, m)的向量 1.2 特征归一化( ...
- Deep Learning系统实训之三:卷积神经网络
边界填充(padding):卷积过程中,越靠近图片中间位置的像素点越容易被卷积计算多次,越靠近边缘的像素点被卷积计算的次数越少,填充就是为了使原来边缘像素点的位置变得相对靠近中部,而我们又不想让填充的 ...
- Deep Learning 学习笔记(7):神经网络的求解 与 反向传播算法(Back Propagation)
反向传播算法(Back Propagation): 引言: 在逻辑回归中,我们使用梯度下降法求参数方程的最优解. 这种方法在神经网络中并不能直接使用, 因为神经网络有多层参数(最少两层),(?为何不能 ...
- Deep Learning 学习笔记(6):神经网络( Neural Network )
神经元: 在神经网络的模型中,神经元可以表示如下 神经元的左边是其输入,包括变量x1.x2.x3与常数项1, 右边是神经元的输出 神经元的输出函数被称为激活函数(activation function ...
- Deep Learning论文笔记之(四)CNN卷积神经网络推导和实现(转)
Deep Learning论文笔记之(四)CNN卷积神经网络推导和实现 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些论文, ...
随机推荐
- Android Studio3.0 新特性 ~ New Features in Android Studio Preview (译文)
原文地址:https://developer.android.google.cn/studio/preview/features/index.html 最新Android Studio版本是Andro ...
- Openstack认证过程
01.登陆界面或命令行通过RESTful API向Keystone获取认证信息: 02.Keystone通过用户请求认证信息,并生成auth-token返回给对应的认证请求: 03.界面或命令行通过R ...
- 原生js实现div拖拽+按下鼠标计时
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <style> ...
- 关于FreeMarker自定义TemplateDirectiveModel
[转载来源:http://zwllxs.iteye.com/blog/2036826] java代码如下: import freemarker.core.Environment; import fre ...
- 每天一个linux命令(性能、优化):【转载】free命令
free命令可以显示Linux系统中空闲的.已用的物理内存及swap内存,及被内核使用的buffer.在Linux系统监控的工具中,free命令是最经常使用的命令之一. 1.命令格式: free [参 ...
- BZOJ4517 Sdoi2016 排列计数 【DP+组合计数】*
BZOJ4517 Sdoi2016 排列计数 Description 求有多少种长度为 n 的序列 A,满足以下条件: 1 ~ n 这 n 个数在序列中各出现了一次 若第 i 个数 A[i] 的值为 ...
- 将 async/await 异步代码转换为安全的不会死锁的同步代码
在 async/await 异步模型(即 TAP Task-based Asynchronous Pattern)出现以前,有大量的同步代码存在于代码库中,以至于这些代码全部迁移到 async/awa ...
- 《DSP using MATLAB》示例Example7.3
由图上可以看出,与幅度谱对应的相位谱是分段线性函数,而与振幅谱对应的相位谱是真正线性函数. 幅度谱和振幅谱的区别也很明显.
- flask第二十篇——模板【3】
请关注公众号:自动化测试实战 现在我们通过查询字符串的方式给render_template传参,我们就要用到flask库的flask.request.args.get()函数先获取参数,在index. ...
- 完美解决github访问速度慢[转]
1. 修改本地hosts文件 windows系统的hosts文件的位置如下:C:\Windows\System32\drivers\etc\hosts mac/linux系统的hosts文件的位置如下 ...