IO模型详解
IO编程包括: 文件读写 操作
StringIO 和 BytesIO 内存中
操作文件和目录 OS
序列化 json pickling
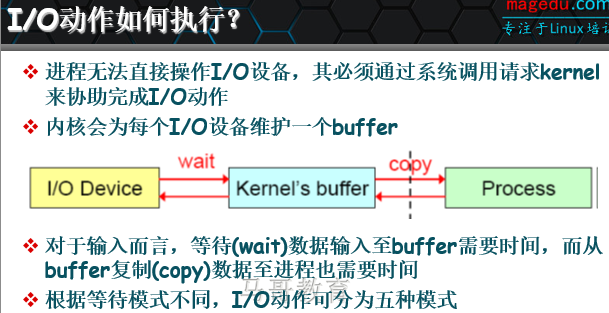
操作系统内核空间(缓冲区)收发数据:
内核态(内核空间)-------------》用户态用户空间()
系统检测到IO操作时切换的速度和效率: 进程切换----------线程切换----------协程切换(最快)
文件描述符(套接字对象): 1 是一个非零整数,不会变
2 收发数据的时候,对于接收端而言,数据先到内核空间,然后copy到用户空间,内核空间数据被清掉
对于一个network IO,它会涉及到两个系统对象,一个是调用这个IO的process (or thread),另一个就是系统内核(kernel)。 当一个IO操作发生时,它会经历两个阶段:
等待数据准备 (Waiting for the data to be ready) 将数据从内核拷贝到进程中 (Copying the data from the kernel to the process)
1 阻塞IO 同步阻塞IO是进程调用内核,内核从磁盘读取数据至内核内存的时候,进程处理等待状态,准备好数据,进程就复活复制数据,第二阶段进程复制数据,进程依然在等待,所以第一第二阶段依然是阻塞的,是同步的IO 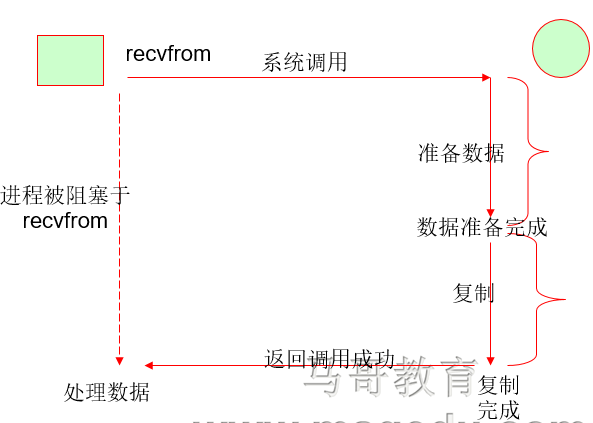
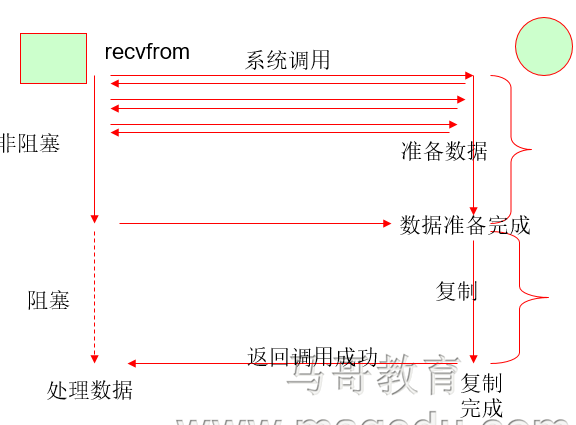
2 非阻塞IO
服务端:
import time
import socket
sk = socket.socket(socket.AF_INET,socket.SOCK_STREAM) sk.bind(('127.0.0.1',6667))
sk.listen(5)
sk.setblocking(False)
while True:
try:
print ('waiting client connection .......')
connection,address = sk.accept() # 进程主动轮询
print("+++",address)
client_messge = connection.recv(1024)
print(type(client_messge,'utf8'))
connection.close()
except Exception as e:
print (e)
time.sleep(4)
客户端:
import time
import socket
sk = socket.socket(socket.AF_INET,socket.SOCK_STREAM)
sk.connect(('127.0.0.1',6667))
while True: sk.sendall('hello'.encode("utf8"))
data = sk.recv(1024)
print(data.decode('utf8'))
优点:能够在等待任务完成的时间里干其他活了(包括提交其他任务,也就是 “后台” 可以有多个任务在同时执行)。
缺点:任务完成的响应延迟增大了,因为每过一段时间才去轮询一次read操作,而任务可能在两次轮询之间的任意时间完成。
这会导致整体数据吞吐量的降低。 3 IO多路复用
IO复用指的是任何一个进程,在某种情况下进程自身只能处理一个IO,但是web是要处理两路IO的,一个是网络IO,另外一个磁盘IO,内核中开发了多路IO或IO复用,进程需要调用IO的时候,都把IO请求交给内核中的select()函数或者poll()函数,最大不能超过1024个,如果超过1024个性能会减少,函数能够处理两个IO,处理网络和磁盘IO
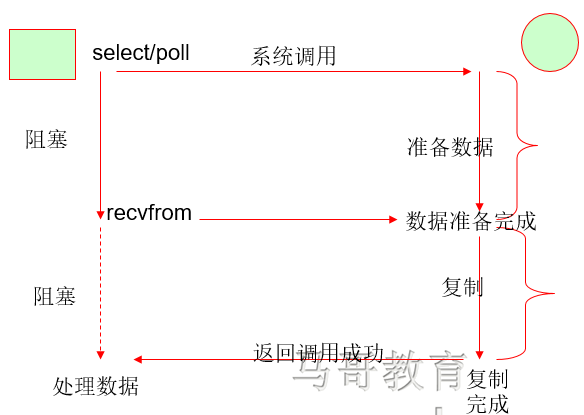
I/O多路复用指:通过一种机制,可以监视多个描述符,一旦某个描述符就绪(一般是读就绪或者写就绪),能够通知程序进行相应的读写操作。
注意:网络操作、文件操作、终端操作等均属于IO操作, 网络IO中:windows只支持Socket操作,其他系统支持其他网络IO操作,但是无法自动检测 普通文件 自从上次读取之后是否已经变化。 注意1:select函数返回结果中如果有文件可读了,那么进程就可以通过调用accept()或recv()来让kernel将位于内核中准备到的数据copy到用户区。
注意2: select的优势在于可以处理多个连接,不适用于单个连接 select方法
句柄列表11, 句柄列表22, 句柄列表33 = select.select(句柄序列1, 句柄序列2, 句柄序列3, 超时时间) 参数: 可接受四个参数(前三个必须)
返回值:三个列表 select方法用来监视文件句柄,如果句柄发生变化,则获取该句柄。
1、当 参数1 序列中的句柄发生可读时(accetp和read),则获取发生变化的句柄并添加到 返回值1 序列中
2、当 参数2 序列中含有句柄时,则将该序列中所有的句柄添加到 返回值2 序列中
3、当 参数3 序列中的句柄发生错误时,则将该发生错误的句柄添加到 返回值3 序列中
4、当 超时时间 未设置,则select会一直阻塞,直到监听的句柄发生变化
当 超时时间 = 1时,那么如果监听的句柄均无任何变化,则select会阻塞 1 秒,之后返回三个空列表,如果监听的句柄有变化,则直接执行。
利用select实现伪同时处理多个Socket客户端请求:服务端
import socket
import select
sk = socket.socket()
sk.bind(('127.0.0.1',8801))
sk.listen(5)
inputs = [sk,]
while True:
r ,w, e = select.select(inputs,[],[]) #[sk,conn1,conn2,conn3....] 只返回有改变的socket和链接对象
for obj in r:
if obj == sk:
conn,addr = obj.accept()
print(conn)
inputs.append(conn)
else: #将列表中有改变的链接对象循环处理
try : #其中一个连接突然断掉时的处理机制 Windows
data = obj.recv(1024)
# if not data:
# inputs.remove(obj)
# continue
print(data.decode('utf8'))
inp = input('>>> :')
obj.sendall(inp.encode('utf8'))
except Exception:
inputs.remove(obj)
print(r)
# 注意1:select函数返回结果中如果有文件可读了,那么进程就可以通过调用accept()或recv()来让kernel将位于内核中准备到的数据copy到用户区。
#
# 注意2: select的优势在于可以处理多个连接,不适用于单个连接
利用select实现伪同时处理多个Socket客户端请求:客户端
import socket
sk = socket.socket()
sk.connect(('127.0.0.1',8080))
while True:
inp = input('>>')
sk.sendall(inp.encode('utf8'))
data = sk.recv(1024)
print(data.decode('utf8'))
此处的Socket服务端相比与原生的Socket,他支持当某一个请求不再发送数据时,服务器端不会等待而是可以去处理其他请求的数据。但是,如果每个请求的耗时比较长时,select版本的服务器端也无法完成同时操作
selectors模块
服务端:
import selectors
import socket
sock = socket.socket()
sock.bind(('127.0.0.1',8801))
sock.listen(5) sel = selectors.DefaultSelector() #根据平台选择最佳的IO多路复用机制,例如 linux系统 选择epoll 机制 def accept(sock,mask):
conn,addr = sock.accept()
print('accepted',conn,'from',addr) sel.register(conn,selectors.EVENT_READ,read) #注册 相当于添加到列表
def read(conn,mask):
try:
data = conn.recv(1000)
print(data.decode('utf8'))
data2 = input('>>')
conn.send(data2.encode('utf8'))
except Exception:
sel.unregister(conn) sel.register(sock,selectors.EVENT_READ,accept) #注册事件 while True:
events = sel.select() #监听 [(key1,mask),(key2,mask),(key3,mask),]
for key,mask in events:
print(key.data) #accept read
print(key.fileobj) #sock conn
key.data(key.fileobj,mask) #触发函数
4 异步IO
用户进程发起read操作之后,立刻就可以开始去做其它的事。而另一方面,从kernel的角度,当它受到一个asynchronous read之后,
首先它会立刻返回,所以不会对用户进程产生任何block。然后,kernel会等待数据准备完成,然后将数据拷贝到用户内存,当这一切
都完成之后,kernel会给用户进程发送一个signal,告诉它read操作完成了 五种IO模型的比较

通过3个函数实现 最大连接数没有上限
第一个函数:创建epoll句柄,将所有的fd拷贝到内核空间,只需要拷贝一次
第二个函数 :回调函数 某一函数或者动作完成之后会触发的函数
为所有的fd绑定一个回调函数,一旦有数据访问则触发该回调函数
回调函数将fd放到链表中
第三个函数 判断链表是否为空 补充:
select select最早于1983年出现在4.2BSD中,它通过一个select()系统调用来监视多个文件描述符的数组,当select()返回后,该数组中就绪的文件描述符便会被内核修改标志位,使得进程可以获得这些文件描述符从而进行后续的读写操作。
select目前几乎在所有的平台上支持,其良好跨平台支持也是它的一个优点,事实上从现在看来,这也是它所剩不多的优点之一。
select的一个缺点在于单个进程能够监视的文件描述符的数量存在最大限制,在Linux上一般为1024,不过可以通过修改宏定义甚至重新编译内核的方式提升这一限制。
另外,select()所维护的存储大量文件描述符的数据结构,随着文件描述符数量的增大,其复制的开销也线性增长。同时,由于网络响应时间的延迟使得大量TCP连接处于非活跃状态,但调用select()会对所有socket进行一次线性扫描,所以这也浪费了一定的开销。 poll poll在1986年诞生于System V Release 3,它和select在本质上没有多大差别,但是poll没有最大文件描述符数量的限制。
poll和select同样存在一个缺点就是,包含大量文件描述符的数组被整体复制于用户态和内核的地址空间之间,而不论这些文件描述符是否就绪,它的开销随着文件描述符数量的增加而线性增大。
另外,select()和poll()将就绪的文件描述符告诉进程后,如果进程没有对其进行IO操作,那么下次调用select()和poll()的时候将再次报告这些文件描述符,所以它们一般不会丢失就绪的消息,这种方式称为水平触发(Level Triggered)。 epoll 直到Linux2.6才出现了由内核直接支持的实现方法,那就是epoll,它几乎具备了之前所说的一切优点,被公认为Linux2.6下性能最好的多路I/O就绪通知方法。
epoll可以同时支持水平触发和边缘触发(Edge Triggered,只告诉进程哪些文件描述符刚刚变为就绪状态,它只说一遍,如果我们没有采取行动,那么它将不会再次告知,这种方式称为边缘触发),理论上边缘触发的性能要更高一些,但是代码实现相当复杂。
epoll同样只告知那些就绪的文件描述符,而且当我们调用epoll_wait()获得就绪文件描述符时,返回的不是实际的描述符,而是一个代表就绪描述符数量的值,你只需要去epoll指定的一个数组中依次取得相应数量的文件描述符即可,这里也使用了内存映射(mmap)技术,<br>这样便彻底省掉了这些文件描述符在系统调用时复制的开销。
另一个本质的改进在于epoll采用基于事件的就绪通知方式。在select/poll中,进程只有在调用一定的方法后,内核才对所有监视的文件描述符进行扫描,而epoll事先通过epoll_ctl()来注册一个文件描述符,一旦基于某个文件描述符就绪时,<br>内核会采用类似callback的回调机制,迅速激活这个文件描述符,当进程调用epoll_wait()时便得到通知。
IO模型详解的更多相关文章
- 并发编程——IO模型详解
我是一个Python技术小白,对于我而言,多任务处理一般就借助于多进程以及多线程的方式,在多任务处理中如果涉及到IO操作,则会接触到同步.异步.阻塞.非阻塞等相关概念,当然也是并发编程的基础. ...
- NGINX的IO模型详解
普及: 用户空间与内核空间: 现在操作系统都是采用虚拟存储器,那么对32位操作系统而言,它的寻址空间(虚拟存储空间)为4G(2的32次方).操作系统的核心是内核,独立于普通的应用程序,可以访问受保护的 ...
- 28、vSocket模型详解及select应用详解
在上片文章已经讲过了TCP协议的基本结构和构成并举例,也粗略的讲过了SOCKET,但是讲解的并不完善,这里详细讲解下关于SOCKET的编程的I/O复用函数. 1.I/O复用:selec函数 在介绍so ...
- 无所不能的Embedding6 - 跨入Transformer时代~模型详解&代码实现
上一章我们聊了聊quick-thought通过干掉decoder加快训练, CNN-LSTM用CNN作为Encoder并行计算来提速等方法,这一章看看抛开CNN和RNN,transformer是如何只 ...
- 图解机器学习 | LightGBM模型详解
作者:韩信子@ShowMeAI 教程地址:http://www.showmeai.tech/tutorials/34 本文地址:http://www.showmeai.tech/article-det ...
- flink内存模型详解与案例
任务提交时的一些yarn设置(通用客户端模式) 指定并行度 -p 5 \ 指定yarn队列 -Dyarn.appl ...
- ASP.NET Core的配置(2):配置模型详解
在上面一章我们以实例演示的方式介绍了几种读取配置的几种方式,其中涉及到三个重要的对象,它们分别是承载结构化配置信息的Configuration,提供原始配置源数据的ConfigurationProvi ...
- java中的io系统详解 - ilibaba的专栏 - 博客频道 - CSDN.NET
java中的io系统详解 - ilibaba的专栏 - 博客频道 - CSDN.NET 亲,“社区之星”已经一周岁了! 社区福利快来领取免费参加MDCC大会机会哦 Tag功能介绍—我们 ...
- JAVA IO 类库详解
JAVA IO类库详解 一.InputStream类 1.表示字节输入流的所有类的超类,是一个抽象类. 2.类的方法 方法 参数 功能详述 InputStream 构造方法 available 如果用 ...
随机推荐
- LeetCode之Symmetric Tree
</pre>Given a binary tree, check whether it is a mirror of itself (ie, symmetric around its ce ...
- 爬虫之Xpath详解
XPath介绍 XPath 是一门在 XML 文档中查找信息的语言.XPath 可用来在 XML 文档中对元素和属性进行遍历. XPath 是 W3C XSLT 标准的主要元素,并且 XQuery 和 ...
- Python慢,为啥还有大公司用?
PyCon 是全世界最大的以 Python 编程语言 为主题的技术大会,大会由 Python 社区组织,每年举办一次.在 Python 2017 上,Instagram 的工程师们带来了一个有关 Py ...
- HTTP request is unauthorized with client authentication scheme 'Anonymous'. The authentication header received from the server was 'NTLM'。
情况:WCF服务在浏览器中可以正常浏览,但是通过程序调用提示: HTTP request is unauthorized with client authentication scheme 'Anon ...
- 20165324 2017-2018-2 《Java程序设计》课程总结
20165324 2017-2018-2 <Java程序设计>课程总结 每周作业链接汇总 预备作业1:20165324 我期望的师生关系 预备作业2:20165324 学习基础与C语言学习 ...
- CSS3、SVG、Canvas、WebGL动画精选整理
一.CSS3动画 名称 用途 链接 阴影波纹特效 1.元素hover效果 2.突出表现效果 http://www.jq22.com/code80 横板导航菜单动画 导航菜单 http://www.jq ...
- Spring MVC 流程
1. 检查是否为上传文件. 2. 通过HandlerMapping获取HandlerExecutionChain: DispatcherServlet 中包含:handlerMappings , 遍历 ...
- IDEA 编译报错: 未结束的字符串文字
最近在搞新项目,同事用的eclipse开发,而我用的是ide,项目初始是由同事创建的,项目编码是UTF-8,而我开发的ide工具默认是GBK编码,导致在编译的时候报错: 未结束的字符串文字 这个问题就 ...
- WebSocket使用SuperWebSocket结合WindowsService实现实时消息
SuperWebSocket在WebService中的应用 最开始使用是寄托在IIS中,发布之后测试时半个小时就会断开,所以改为WindowsService 1. 新建Windows服务项目[Test ...
- windows安装VisualSVN Server