Spark MLlib之协同过滤
原文:http://blog.selfup.cn/1001.html
什么是协同过滤
协同过滤(Collaborative Filtering, 简称CF),wiki上的定义是:简单来说是利用某兴趣相投、拥有共同经验之群体的喜好来推荐使用者感兴趣的资讯,个人透过合作的机制给予资讯相当程度的回应(如评分)并记录下来以达到过滤的目的进而帮助别人筛选资讯,回应不一定局限于特别感兴趣的,特别不感兴趣资讯的纪录也相当重要。
以上定义太拗口,举个简单的例子:我现在多年不看日本anime的新番了,最近突然又想看几部新番,但又不知道这么多新番中看哪些比较好,于是我就找几个同样喜欢日本动漫的朋友来咨询。我第一个想咨询的朋友是和我口味最像的,我们都特别喜欢看《虫师》、《黑之契约者》、《寒蝉》这样的小众动画;我问的第二个朋友和我口味差不多,他特别喜欢看《钢炼》《无头骑士异闻录》这样的动画,我虽然喜欢,但不像他那么喜欢;由于身边喜欢日本动画的朋友不多,剩下第三个可以咨询的是一个宅女,平常经常看腐、宅、基的动漫,完全跟我不是一路人,于是问了下她推荐的片子,并将这些片子打上的黑名单的标签。然后我就开始看第一个朋友推荐的片子了,要是时间特别多又很无聊我可能会看第二个朋友推荐的,但打死我也不会看第三个朋友推荐的。这就是协同过滤的一个简化、小众版。
如何进行相似度度量
接着上面的例子,我可以通过我和其它朋友共同喜欢某个或某类动漫来确定我们的口味是否一样,那么如何以数学或者机器的形式来表示这个“口味一样”呢?通常,是通过“距离”来表示,例如:欧几里得距离、皮尔逊相关度、曼哈顿距离、Jaccard系数等等。
欧几里得距离
欧几里德距离(Euclidean Distance),最初用于计算欧几里得空间中两个点的距离,在二维空间中,就是我们熟悉的两点间的距离,x、y表示两点,维度为n:

相似度:

皮尔逊相关度
皮尔逊相关度(Pearson Correlation Coefficient),用于判断两组数据与某一直线拟合程度的一种度量,取值在[-1,1]之间。当数据不是很规范的时候(如偏差较大),皮尔逊相关度会给出较好的结果。
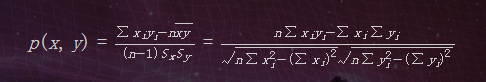
曼哈顿距离
曼哈顿距离(Manhattan distance),就是在欧几里得空间的固定直角坐标系上两点所形成的线段对轴产生的投影的距离总和。

Jaccard系数
Jaccard系数,也称为Tanimoto系数,是Cosine相似度的扩展,也多用于计算文档数据的相似度。通常应用于x为布尔向量,即各分量只取0或1的时候。此时,表示的是x,y的公共特征的占x,y所占有的特征的比例:

计算推荐
根据上述“距离”的算法,我们可以找出与自己“口味一样”的人了,但这并不是目的,目的是找出推荐的物品。一种常用的做法是选出与你兴趣相同的N个人,然后根据这N个人的记录来进行加权推荐。具体如下,假设已经计算出欧几里得相似度:
| 朋友 | 相似度 | 银魂 | S.x银魂 | 食灵零 | S.x食灵零 | 雨月 | S.x雨月 |
|---|---|---|---|---|---|---|---|
| A | 0.95 | 10.0 | 9.5 | 9.0 | 8.55 | - | - |
| B | 0.80 | 8.5 | 6.8 | 7.5 | 6 | 5.0 | 4 |
| C | 0.25 | - | - | 6.5 | 1.625 | 9.0 | 2.25 |
| 总计 | 16.3 | 16.175 | 6.25 | ||||
| Sim.Sum | 1.75 | 2 | 1.05 | ||||
| 总计/Sim.Sum | 9.31 | 8.09 | 5.95 |
其中,S.x开头的表示相似度与评分的乘积,Sim.Sum表示打过分的朋友的相似度之和。可以看出根据三位友人的推荐,我从这三部动漫中应该选择银魂来看。
Item CF与User CF
基于用户的协同过滤(User CF),其基本思想相当简单,基于用户对物品的偏好找到相邻邻居用户,然后将邻居用户喜欢的推荐给当前用户。上述过程就属于User CF。
基于物品的CF(Item CF)的原理和基于用户的CF类似,只是在计算邻居时采用物品本身,而不是从用户的角度,即基于用户对物品的偏好找到相似的物品,然后根据用户的历史偏好,推荐相似的物品给他。
两者的计算复杂度和适用场景皆不同,详细可参见参考资料。
Spark协同过滤实现
训练数据
196 242 3 881250949
186 302 3 891717742
22 377 1 878887116
244 51 2 880606923
166 346 1 886397596
298 474 4 884182806
...
其中第一列为userid,第二列为movieid,第三列为评分,第四列为timestamp(未使用)。
完整版下载:MovieLens(解压后的u.data文件)。http://files.grouplens.org/datasets/movielens/ml-100k.zip
代码实现
public class UserSideCF implements Serializable {
private static final Pattern TAB = Pattern.compile("\t");
public MatrixFactorizationModel buildModel(RDD<Rating> rdd) { //训练模型
int rank = 10;
int numIterations = 20;
MatrixFactorizationModel model = ALS.train(rdd, rank, numIterations, 0.01);
return model;
}
public RDD<Rating>[] splitData() { //分割数据,一部分用于训练,一部分用于测试
SparkConf sparkConf = new SparkConf().setAppName("JavaALS").setMaster("local[2]");
JavaSparkContext sc = new JavaSparkContext(sparkConf);
JavaRDD<String> lines = sc.textFile("/home/nodin/ml-100k/u.data");
JavaRDD<Rating> ratings = lines.map(line -> {
String[] tok = TAB.split(line);
int x = Integer.parseInt(tok[0]);
int y = Integer.parseInt(tok[1]);
double rating = Double.parseDouble(tok[2]);
return new Rating(x, y, rating);
});
RDD<Rating>[] splits = ratings.rdd().randomSplit(new double[]{0.6,0.4}, 11L);
return splits;
}
public static void main(String[] args) {
UserSideCF cf = new UserSideCF();
RDD<Rating>[] splits = cf.splitData();
MatrixFactorizationModel model = cf.buildModel(splits[0]);
Double MSE = cf.getMSE(splits[0].toJavaRDD(), model);
System.out.println("Mean Squared Error = " + MSE); //训练数据的MSE
Double MSE1 = cf.getMSE(splits[1].toJavaRDD(), model);
System.out.println("Mean Squared Error1 = " + MSE1); //测试数据的MSE
}
public Double getMSE(JavaRDD<Rating> ratings, MatrixFactorizationModel model) { //计算MSE
JavaPairRDD usersProducts = ratings.mapToPair(rating -> new Tuple2<>(rating.user(), rating.product()));
JavaPairRDD<Tuple2<Integer, Integer>, Double> predictions = model.predict(usersProducts.rdd())
.toJavaRDD()
.mapToPair(new PairFunction<Rating, Tuple2<Integer, Integer>, Double>() {
@Override
public Tuple2<Tuple2<Integer, Integer>, Double> call(Rating rating) throws Exception {
return new Tuple2<>(new Tuple2<>(rating.user(), rating.product()), rating.rating());
}
});
JavaPairRDD<Tuple2<Integer, Integer>, Double> ratesAndPreds = ratings
.mapToPair(new PairFunction<Rating, Tuple2<Integer, Integer>, Double>() {
@Override
public Tuple2<Tuple2<Integer, Integer>, Double> call(Rating rating) throws Exception {
return new Tuple2<>(new Tuple2<>(rating.user(), rating.product()), rating.rating());
}
});
JavaPairRDD joins = ratesAndPreds.join(predictions);
return joins.mapToDouble(new DoubleFunction<Tuple2<Tuple2<Integer, Integer>, Tuple2<Double, Double>>>() {
@Override
public double call(Tuple2<Tuple2<Integer, Integer>, Tuple2<Double, Double>> o) throws Exception {
double err = o._2()._1() - o._2()._2();
return err * err;
}
}).mean();
}
}
运行结果
0.6,0.4(训练数据,测试数据) - 0.3706799281981904, 2.4569381099423957(训练数据,测试数据)
0.7,0.3 - 0.40358067085112936, 2.4469113734667935
0.8,0.2 - 0.4335027003381571, 2.0930908173274476
0.9,0.1 - 0.4587619714761296, 1.7213014771993198
参考资料
- MLlib - Collaborative Filtering
- 探索推荐引擎内部的秘密,第 2 部分: 深入推荐引擎相关算法 - 协同过滤
- Movie Recommendation with MLlib
Spark MLlib之协同过滤的更多相关文章
- Spark机器学习之协同过滤算法
Spark机器学习之协同过滤算法 一).协同过滤 1.1 概念 协同过滤是一种借助"集体计算"的途径.它利用大量已有的用户偏好来估计用户对其未接触过的物品的喜好程度.其内在思想是相 ...
- 基于mllib的协同过滤实战(电影推荐)
//加载需要的包 import org.apache.spark.rdd._ import org.apache.spark.mllib.recommendation.{ALS, Rating, Ma ...
- Spark 基于物品的协同过滤算法实现
J由于 Spark MLlib 中协同过滤算法只提供了基于模型的协同过滤算法,在网上也没有找到有很好的实现,所以尝试自己实现基于物品的协同过滤算法(使用余弦相似度距离) 算法介绍 基于物品的协同过滤算 ...
- 【转载】协同过滤 & Spark机器学习实战
因为协同过滤内容比较多,就新开一篇文章啦~~ 聚类和线性回归的实战,可以看:http://www.cnblogs.com/charlesblc/p/6159187.html 协同过滤实战,仍然参考:h ...
- 【机器学习笔记一】协同过滤算法 - ALS
参考资料 [1]<Spark MLlib 机器学习实践> [2]http://blog.csdn.net/u011239443/article/details/51752904 [3]线性 ...
- 基于Spark Mllib,SparkSQL的电影推荐系统
本文测试的Spark版本是1.3.1 本文将在Spark集群上搭建一个简单的小型的电影推荐系统,以为之后的完整项目做铺垫和知识积累 整个系统的工作流程描述如下: 1.某电影网站拥有可观的电影资源和用户 ...
- SparkMLlib—协同过滤推荐算法,电影推荐系统,物品喜好推荐
SparkMLlib-协同过滤推荐算法,电影推荐系统,物品喜好推荐 一.协同过滤 1.1 显示vs隐式反馈 1.2 实例介绍 1.2.1 数据说明 评分数据说明(ratings.data) 用户信息( ...
- Spark(十一) -- Mllib API编程 线性回归、KMeans、协同过滤演示
本文测试的Spark版本是1.3.1 在使用Spark的机器学习算法库之前,需要先了解Mllib中几个基础的概念和专门用于机器学习的数据类型 特征向量Vector: Vector的概念是和数学中的向量 ...
- Spark MLlib协同过滤算法
算法说明 协同过滤(Collaborative Filtering,简称CF,WIKI上的定义是:简单来说是利用某个兴趣相投.拥有共同经验之群体的喜好来推荐感兴趣的资讯给使用者,个人透过合作的机制给予 ...
随机推荐
- ex26 纠正练习
题目中给出的代码如下: def break_words(stuff): """This function will break up words for us." ...
- 腾讯优测| 让Android屏幕适配开发更简单-Google百分比布
文/腾讯优测工程师 吴宇焕 腾讯优测优社区干货精选~ 相信开发同学都被安卓设备碎片化的问题折磨过,市面上安卓手机的主流屏幕尺寸种类繁多,给适配造成很大的困难.就算搞定了屏幕尺寸问题,各种分辨率又让人眼 ...
- Java设计模式(十一) 享元模式
原创文章,同步发自作者个人博客 http://www.jasongj.com/design_pattern/flyweight/.转载请注明出处 享元模式介绍 享元模式适用场景 面向对象技术可以很好的 ...
- 使用STL离散化
把原来的数组a复制一份拷贝b 用sort先把数组a排序 用unique消除a里面重复的元素 对于b中的每一个元素,用lower_bound找到它在a中的位置,也就是离散化之后的编号. 没了. #inc ...
- HDU 3966 Aragorn's Story
题意:给一棵树,并给定各个点权的值,然后有3种操作:I C1 C2 K: 把C1与C2的路径上的所有点权值加上KD C1 C2 K:把C1与C2的路径上的所有点权值减去KQ C:查询节点编号为C的权值 ...
- 【转】关于.net framework4.0以及4.5安装失败,“安装时发生严重错误”……
也不知道管不管用,先记着 今天忽然想装一个vs2010,然后装了好几遍,每次都在安装.net4.0的时候失败.好吧,我自己手动装行么.于是手动去装.net 4.0. 结果在还是返回"安装时发 ...
- java比较两个字符串是否相等
从c 到c++ 到 c# 到 JavaScript 判断两个字符串是否相等,用==号都可以.奇葩的java怎么可以只能用equals()这个函数.只是因为String是引用类型吗??!!哭笑不得.. ...
- List remove注意点
public class ListTest { public static void main(String[] args) { // TODO Auto-generated method stub ...
- 07 Linux su和sudo命令的区别
一. 使用 su 命令临时切换用户身份 1.su 的适用条件和威力 su命令就是切换用户的工具,怎么理解呢?比如我们以普通用户beinan登录的,但要添加用户任务,执行useradd ,beinan用 ...
- 写MYSQL存储过程遇到的一个小BUG
DELIMITER $$ USE `income_new`$$ DROP PROCEDURE IF EXISTS `a`$$ CREATE DEFINER=`income_new`@`%` PROCE ...