Hadoop MapReduce编程 API入门系列之压缩和计数器(三十)
不多说,直接上代码。
Hadoop MapReduce编程 API入门系列之小文件合并(二十九)
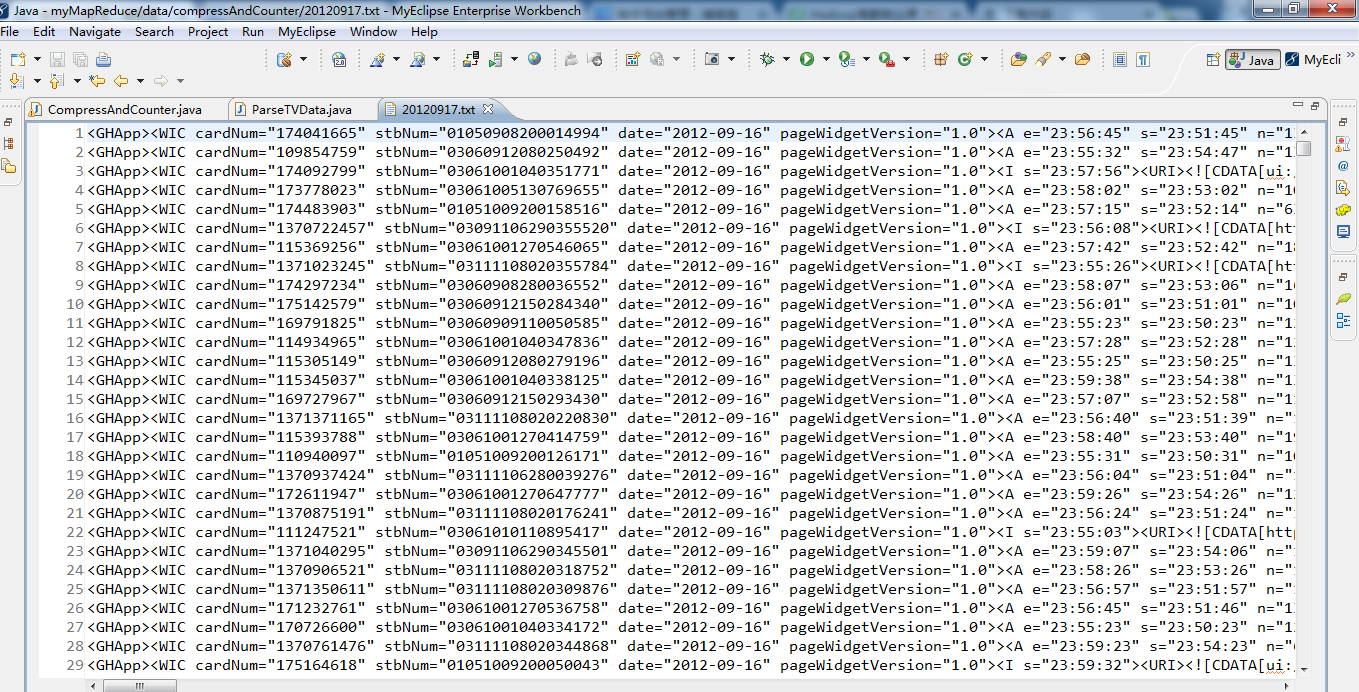
生成的结果,作为输入源。


代码
package zhouls.bigdata.myMapReduce.ParseTVDataCompressAndCounter;
import java.net.URI;
import java.util.List;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.compress.GzipCodec;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
/**
*
* @function 统计无效数据和对输出结果进行压缩
* @author 小讲
*
*/
public class CompressAndCounter extends Configured implements Tool
{
// 定义枚举对象
public static enum LOG_PROCESSOR_COUNTER
{
BAD_RECORDS
};
/**
*
* @function Mapper 解析数据,统计无效数据,并输出有效数据
*
*/
public static class CompressAndCounterMap extends Mapper<LongWritable, Text, Text, Text>
{
protected void map(LongWritable key, Text value, Context context) throws java.io.IOException, InterruptedException
{
// 解析每条机顶盒记录,返回list集合
List<String> list = ParseTVData.transData(value.toString()); //调用ParseTVData.java下的transData方法
int length = list.size();
// 无效记录
if (length == 0)
{
// 动态自定义计数器
context.getCounter("ErrorRecordCounter", "ERROR_Record_TVData").increment(1);
// 枚举声明计数器
context.getCounter(LOG_PROCESSOR_COUNTER.BAD_RECORDS).increment(1);
} else
{
for (String validateRecord : list)
{
//输出解析数据
context.write(new Text(validateRecord), new Text(""));
}
}
}
}
/**
* @function 任务驱动方法
*
*/
@Override
public int run(String[] args) throws Exception
{
// TODO Auto-generated method stub
//读取配置文件
Configuration conf = new Configuration();
//文件系统接口
URI uri = new URI("hdfs://HadoopMaster:9000");
//输出路径
Path mypath = new Path(args[1]);
// 创建FileSystem对象
FileSystem hdfs = FileSystem.get(uri, conf);
if (hdfs.isDirectory(mypath))
{
//删除已经存在的文件路径
hdfs.delete(mypath, true);
}
Job job = new Job(conf, "CompressAndCounter");//新建一个任务
job.setJarByClass(CompressAndCounter.class);//设置主类
job.setMapperClass(CompressAndCounterMap.class);//只有 Mapper
job.setOutputKeyClass(Text.class);//输出 key 类型
job.setOutputValueClass(Text.class);//输出 value 类型
FileInputFormat.addInputPath(job, new Path(args[0]));//输入路径
FileOutputFormat.setOutputPath(job, new Path(args[1]));//输出路径
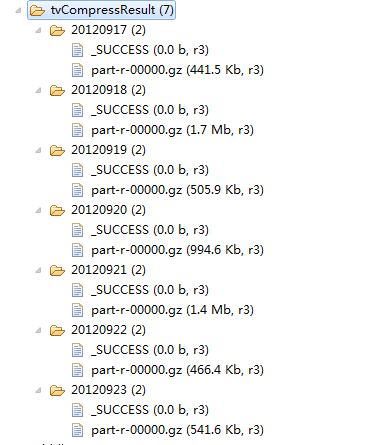
FileOutputFormat.setCompressOutput(job, true);//对输出结果设置压缩
FileOutputFormat.setOutputCompressorClass(job, GzipCodec.class);//设置压缩类型
job.waitForCompletion(true);//提交任务
return 0;
}
/**
* @function main 方法
* @param args 输入 输出路径
* @throws Exception
*/
public static void main(String[] args) throws Exception
{
String[] date = {"20120917","20120918","20120919","20120920","20120921","20120922","20120923"};
int ec = 1;
for(String dt:date)
{
String[] args0 = { "hdfs://HadoopMaster:9000/middle/tv/"+dt+".txt",
"hdfs://HadoopMaster:9000/junior/tvCompressResult/"+dt };
// String[] args0 = { "./data/compressAndCounter/"+dt+".txt",
// "hdfs://HadoopMaster:9000/junior/tvCompressResult/"+dt };
ec = ToolRunner.run(new Configuration(), new CompressAndCounter(), args0);
}
System.exit(ec);
}
}
package zhouls.bigdata.myMapReduce.ParseTVDataCompressAndCounter;
import java.util.ArrayList;
import java.util.List;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
/**
*
* @function 解析数据
*
*
*/
public class ParseTVData
{
/**
* @function 使用 Jsoup 工具,解析输入数据,
* @param text
* @return list
*/
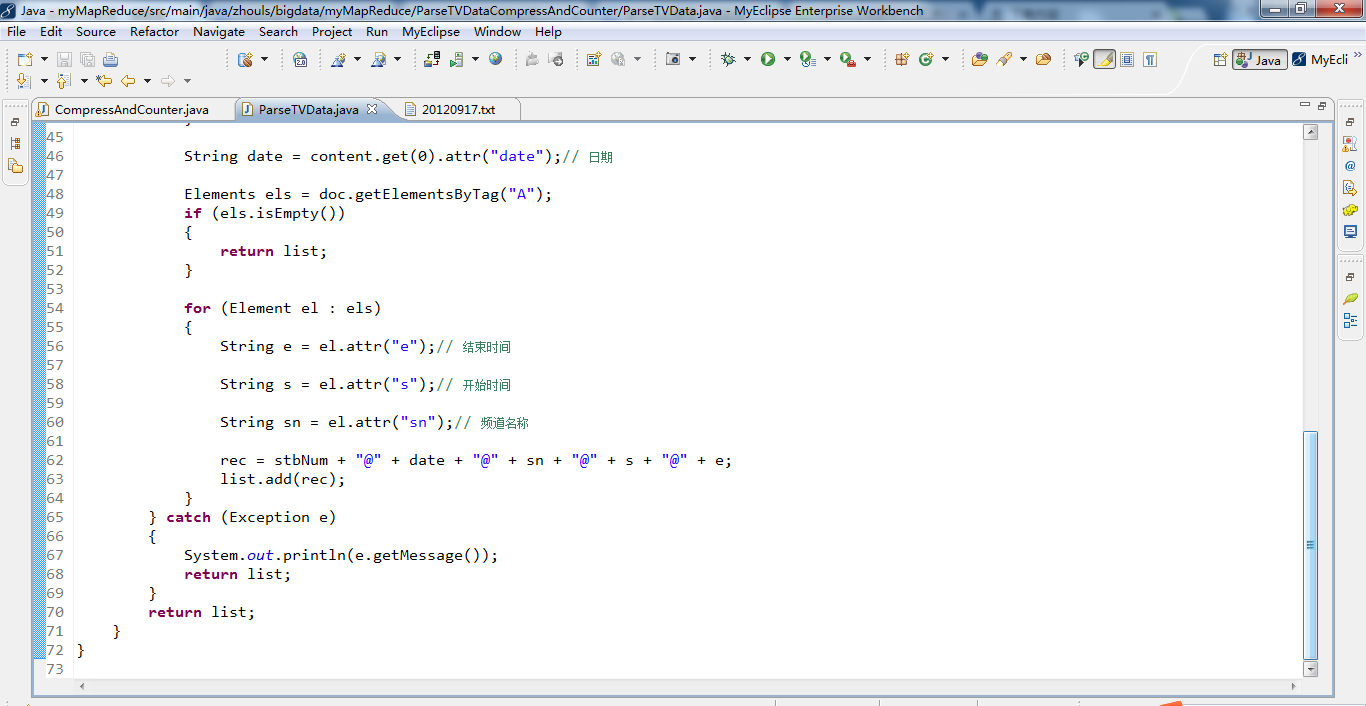
public static List<String> transData(String text)
{
List<String> list = new ArrayList<String>();
Document doc;
String rec = "";
try
{
doc = Jsoup.parse(text);// jsoup解析数据
Elements content = doc.getElementsByTag("WIC");
String num = content.get(0).attr("cardNum");// 记录编号
if (num == null || num.equals(""))
{
num = " ";
}
String stbNum = content.get(0).attr("stbNum");// 机顶盒号
if (stbNum.equals(""))
{
return list;
}
String date = content.get(0).attr("date");// 日期
Elements els = doc.getElementsByTag("A");
if (els.isEmpty())
{
return list;
}
for (Element el : els)
{
String e = el.attr("e");// 结束时间
String s = el.attr("s");// 开始时间
String sn = el.attr("sn");// 频道名称
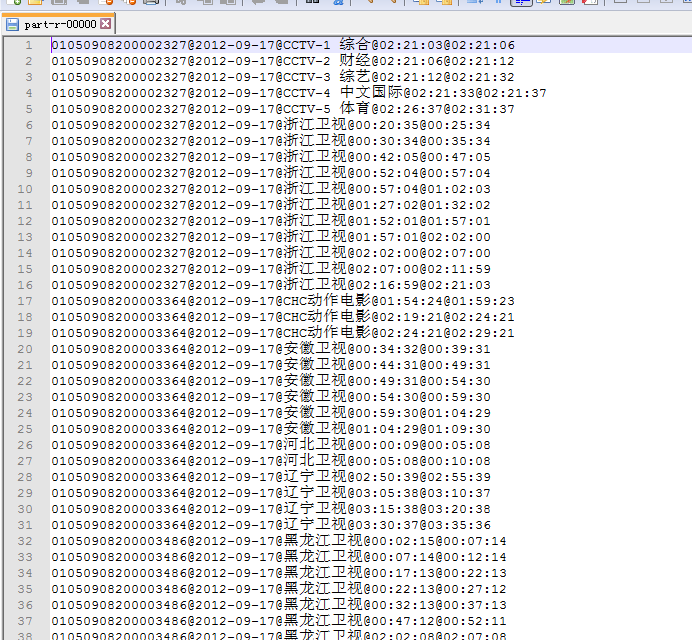
rec = stbNum + "@" + date + "@" + sn + "@" + s + "@" + e;
list.add(rec);
}
} catch (Exception e)
{
System.out.println(e.getMessage());
return list;
}
return list;
}
}
Hadoop MapReduce编程 API入门系列之压缩和计数器(三十)的更多相关文章
- Hadoop MapReduce编程 API入门系列之薪水统计(三十一)
不多说,直接上代码. 代码 package zhouls.bigdata.myMapReduce.SalaryCount; import java.io.IOException; import jav ...
- Hadoop MapReduce编程 API入门系列之Crime数据分析(二十五)(未完)
不多说,直接上代码. 一共12列,我们只需提取有用的列:第二列(犯罪类型).第四列(一周的哪一天).第五列(具体时间)和第七列(犯罪场所). 思路分析 基于项目的需求,我们通过以下几步完成: 1.首先 ...
- Hadoop MapReduce编程 API入门系列之网页排序(二十八)
不多说,直接上代码. Map output bytes=247 Map output materialized bytes=275 Input split bytes=139 Combine inpu ...
- Hadoop MapReduce编程 API入门系列之二次排序(十六)
不多说,直接上代码. -- ::, INFO [org.apache.hadoop.metrics.jvm.JvmMetrics] - Initializing JVM Metrics with pr ...
- Hadoop MapReduce编程 API入门系列之分区和合并(十四)
不多说,直接上代码. 代码 package zhouls.bigdata.myMapReduce.Star; import java.io.IOException; import org.apache ...
- Hadoop MapReduce编程 API入门系列之挖掘气象数据版本3(九)
不多说,直接上干货! 下面,是版本1. Hadoop MapReduce编程 API入门系列之挖掘气象数据版本1(一) 下面是版本2. Hadoop MapReduce编程 API入门系列之挖掘气象数 ...
- Hadoop MapReduce编程 API入门系列之挖掘气象数据版本2(十)
下面,是版本1. Hadoop MapReduce编程 API入门系列之挖掘气象数据版本1(一) 这篇博文,包括了,实际生产开发非常重要的,单元测试和调试代码.这里不多赘述,直接送上代码. MRUni ...
- Hadoop MapReduce编程 API入门系列之计数器(二十七)
不多说,直接上代码. MapReduce 计数器是什么? 计数器是用来记录job的执行进度和状态的.它的作用可以理解为日志.我们可以在程序的某个位置插入计数器,记录数据或者进度的变化情况. Ma ...
- Hadoop MapReduce编程 API入门系列之join(二十六)(未完)
不多说,直接上代码. 天气记录数据库 Station ID Timestamp Temperature 气象站数据库 Station ID Station Name 气象站和天气记录合并之后的示意图如 ...
随机推荐
- POJ 1236 SCC+缩点
题意:一张有向图,一问至少给几个点发送软件,才能让所有点都能收到软件:二问是至少添加几条边才能让整个图是一个连通分量: 分析:一般求连通分量都会求缩点,在这里缩点之后,生成一张新的图,在新的图中求每一 ...
- iscroll动态加载数据完美解决方案
@{ Layout = null; } <!DOCTYPE html> <html> <head> <meta charset="utf-8&quo ...
- 【学习笔记】Oracle-1.安装及配置
Win7旗舰版安装Oracle_11gR1_database: http://my.oschina.net/laiwanshan/blog/89951 Oracle用户登陆 sqlplus sys/ ...
- python知识点记录(一):
1.如何使print输出不换行: 在print语句末尾加上一个英文逗号. 2.安装第三方模块时,用pip和easy_install是一样的.下载一个setuptools.exe安装好就有easy_in ...
- mysql source命令超大文件导入方法总结
本文章来给各位朋友介绍利用mysql source命令超大文件导入方法总结,下面收集了两种解决办法,一种是把数据库分文件导出然后再导入,另一种是修改my.ini配置文件,下面我一一给各位朋友介绍. 导 ...
- bk.
http://ol.tgbus.com/zt2013/gzsnew/ 巴士盘点 十大游戏工作室 http://bbs.3dmgame.com/forum.php?mod=viewthread& ...
- 数迹学——Asp.Net MVC4入门指南(3):添加一个视图
方法返回值 ActionResult(方法执行后的结果) 例子1 public ActionResult methordName() { return "string"; } 例 ...
- (转) Deep learning architecture diagrams
FastML Machine learning made easy RSS Home Contents Popular Links Backgrounds About Deep learning ar ...
- oracle返回多个参数
CREATE OR REPLACE PACKAGE BODY get_form_no_pub IS /*================================================ ...
- linux网络编程-(socket套接字编程UDP传输)
今天我们来介绍一下在linux网络环境下使用socket套接字实现两个进程下文件的上传,下载,和退出操作! 在socket套接字编程中,我们当然可以基于TCP的传输协议来进行传输,但是在文件的传输中, ...