算法手记 之 数据结构(堆)(POJ 2051)
一篇读书笔记
书籍简评:《ACM/ICPC 算法训练教程》这本书是余立功主编的,代码来自南京理工大学ACM集训队代码库,所以小编看过之后发现确实很实用,适合集训的时候刷题啊~~,当时是听了集训队final的意见买的,感觉还是不错滴。
相对于其他ACM书籍来说,当然如书名所言,这是一本算法训练书,有着大量的算法实战题目和代码,尽管小编还是发现了些许错误= =,有部分注释的语序习惯也有点不太合我的胃口。实战题目较多是比较水的题,但也正因此才能帮助不少新手入门,个人认为还是一本不错的算法书,当然自学还是需要下不少功夫的。
小编认为这本书主要针对的对象是想要全面了解算法竞赛内容的入门选手,想要单纯研习算法的同学可以啃啃《算法导论》,ACM的大神们加油消灭掉刘汝佳的大黑书吧
刚刚入门的孩纸们要和我一起fighting啊= =
话不多说,进入正题咯, (本节部分概念来源本书P25-2.1.3 堆,其余均为原创)
堆的概念:
数据结构中所说的堆(heap)指的就是一个完全二叉树,当然可以用链表来实现,也可以用一维数组(线性)来模拟实现。
依照堆中存放的数据大小,堆分为两大类,一类是最大堆,一类是最小堆。
- 最大堆:任意一个结点的值都大于等于任一子结点的值,所以最大堆的根(root)一定是maximun。
- 最小堆:任意一个结点的值都小于等于任一子结点的值,所以最小堆的根(root)一定是minimun。
堆的实现:
我们经常听说,heap是一种高效紧凑的数据结构,那么为什么高效而紧凑呢。用一张图来简单介绍吧。(下图中 上下分别为heap数组(用heap[]表示),heap的图示)
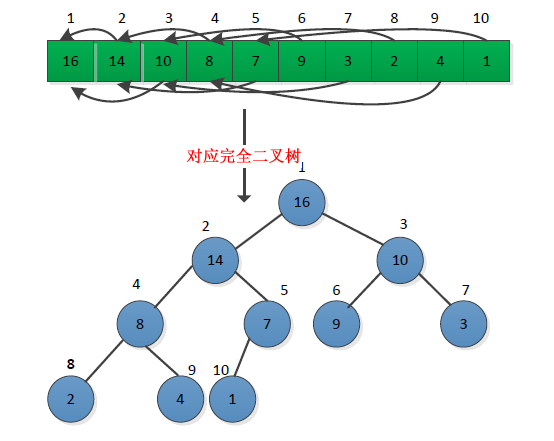
ps:上图中的完全二叉树可以作为heap的图示,上面绿色一栏是对应的数组(array),例如16就是heap[1],14就是heap[2]...依次类推。
我们习惯上把 14 和 10 叫做 16 的子结点,14为16的左儿子,10为16的右儿子。
那么像这样,我们就可以从数组(array)中得到heap[2],heap[3]为heap[1]的子结点,heap[4],heap[5]为heap[2]的子结点....
通过c/c++整形除法规则,得到2/2 = 1 , 3/2 = 1;因此我们把 数据所在位置 满足 s/2 =f 公式的 s 称作 f 的子结点(son), f 称作 s 的父结点(father),这样我们就可以利用数组来紧凑整齐地存储这一系列数据,下一次要调用某一位置 p 的父结点时,直接采用p/2就可以找到 p 的父结点了,同理,子结点就是p*2和p*2+1,这样存储数据是不是很整齐也很便于查找呢。(虽然小编觉得手写这个数据结构的功能时依然会有些繁琐啦= =)
堆的操作:
那么下面我们来看一下这个数据结构的一般操作怎样通过代码实现呢?(多代码预警~~)(入门的孩纸们记得多调试就容易理解了~~fighting!)
- 删除优先级最高的元素-DeleteMin() —— 例如删除-最小堆的heap[1]
此操作分为三步:
- 直接删除根(root);
- 用最后一个元素代替root;
- 将heap向下重新调整;————第三步表示为下方被调用的 调整堆函数 - down(
/* 删除优先级最高的元素 */
/* 最小堆为例 */ /* heap - down_adjustment */
void down(int p) //current_node
{
int q = p*; //left_son_node
int a = heap[p]; while (q < hlength) //hlength指的是heap数组的长,也就是堆中元素总数
{
if(heap[q] > heap[q+]) //find_min_son
q++; if(heap[q] < a) //complete_adjustment
break;
else
{
heap[p] = heap[q];
p = q;
q = p*;
}
}
heap[p] = a;
return;
} /* delete_minimun_node */
int DleteMin()
{
int r = heap[]; //delete_root
heap[] = heap[hlength--];
down(); //this is the key point!!
return r;
/* 删除优先级最高的元素 */
/* 最小堆为例 */ /* heap - down_adjustment */
void down(int p) //current_node
{
int q = p*; //left_son_node
int a = heap[p]; while (q <= hlength) //hlength指的是heap数组的长,也就是堆中元素总数
{
if(q < hlength && heap[q] > heap[q+]) //find_min_son
q++; if(heap[q] < a) //complete_adjustment
break;
else
{
heap[p] = heap[q];
p = q;
q = p*;
}
}
heap[p] = a;
return;
} /* delete_minimun_node */
int DleteMin()
{
int r = heap[]; //delete_root
heap[] = heap[hlength--];
down(); //this is the key point!!
return r;
}
View Heap-Code
- 在堆中插入新元素-Insert(x)——依然以最小堆为例 (不懂的依然记得一步一步地来理解,最好自己调试)
操作步骤为:
- 将待insert的元素x添加到末尾;
- 向上调整;————第二步用被调用的 up() 函数表示;
/* 堆中插入新元素 */
/* 最小堆为例 */ /* heap - up_adjustment */
void up(int p) //current_node
{
int q = p/; //partner_node
int a = heap[p]; while(q > && a < heap[q])
{
heap[p] = heap[q];
p = q;
q = p/;
}
heap[p] = a;
return;
} /* Insert_new_node */
void Insert(int a)
{
heap[++hlength] = a; //加长并将a加到末尾
up(hlength);
}
View Heap-Code
- 将x位置的优先级提升到 p 值:IncreaseKey(x,p);
/* 堆中将x优先级提至p */
void IncreaseKey(int x,int p)
{
if (heap[x] < p) //若heap[x]本身小于p,那么x的优先级本来就比p高
return;
heap[x] = p; //否则将heap[x]赋值为 p
up(x); //调用上方函数up()
}
View Heap-Code
- 数组模拟建堆:Build()——(⊙o⊙)额,原谅我最后才建堆,其实这也是正常顺序啦= =
/* 数组建堆 */
void Build()
{
for (int i = hlength / ; i > ; i++)
down(i); //调用第一次的 调整堆函数
}
View Build_heap-Code
堆的时间度分析:
- 向上和向下调整每层都是常数级别,共log n层,因此 调整堆 的时间度O(log n);
- 插入/删除 只调用一次向上或向下调整,因此都是O(log n);
//Argus-中文貌似是一个神话人物 阿尔戈斯 号称百眼巨人~~
//吼吼吼= =(此情节与题目无关) //循环维持最小堆
//Time:32Ms Memory:176K
#include<iostream>
#include<cstring>
#include<cstdio>
using namespace std; #define MAX 1001 struct Argument {
int name; //编号
int now; //当前执行时间
int period; //周期
friend bool operator < (Argument &a, Argument &b) {
return a.now < b.now || (a.now == b.now && a.name < b.name);
}
}arg[MAX]; int len = ; /*从x向下调整*/
void down(int x)
{
Argument tmp = arg[x];
int next = * x;
for (int next = * x; next < len;next *= )
{
//比较子结点优先级
if (next + < len && arg[next + ] < arg[next])
next++;
//不可下调
if (tmp < arg[next]) break;
//下调
arg[x] = arg[next];
x = next;
}
arg[x] = tmp;
} void createHeap()
{
for (int i = len / ; i > ; i--)
down(i);
} int main()
{ char command[];
while (scanf("%s", command), strcmp(command, "#"))
{
scanf("%d%d", &arg[len].name, &arg[len].period);
arg[len++].now = arg[len].period;
} createHeap(); int k;
scanf("%d", &k);
for (int i = ; i < k; i++)
{
printf("%d\n", arg[].name);
arg[].now += arg[].period;
down();
} return ;
}
算法手记 之 数据结构(堆)(POJ 2051)的更多相关文章
- 算法手记 之 数据结构(线段树详解)(POJ 3468)
依然延续第一篇读书笔记,这一篇是基于<ACM/ICPC 算法训练教程>上关于线段树的讲解的总结和修改(这本书在线段树这里Error非常多),但是总体来说这本书关于具体算法的讲解和案例都是不 ...
- 算法手记 之 数据结构(并查集详解)(POJ1703)
<ACM/ICPC算法训练教程>读书笔记-这一次补上并查集的部分.将对并查集的思想进行详细阐述,并附上本人AC掉POJ1703的Code. 在一些有N个元素的集合应用问题中,通常会将每个元 ...
- 基本数据结构——堆(Heap)的基本概念及其操作
基本数据结构――堆的基本概念及其操作 小广告:福建安溪一中在线评测系统 Online Judge 在我刚听到堆这个名词的时候,我认为它是一堆东西的集合... 但其实吧它是利用完全二叉树的结构来维护一组 ...
- C 数据结构堆
引言 - 数据结构堆 堆结构都很耳熟, 从堆排序到优先级队列, 我们总会看见它的身影. 相关的资料太多了, 堆 - https://zh.wikipedia.org/wiki/%E5%A0%86%E7 ...
- java数据结构----堆
1.堆:堆是一种树,由它实现的优先级队列的插入和删除的时间复杂度都是O(logn),用堆实现的优先级队列虽然和数组实现相比较删除慢了些,但插入的时间快的多了.当速度很重要且有很多插入操作时,可以选择堆 ...
- 在 Prim 算法中使用 pb_ds 堆优化
在 Prim 算法中使用 pb_ds 堆优化 Prim 算法用于求最小生成树(Minimum Spanning Tree,简称 MST),其本质是一种贪心的加点法.对于一个各点相互连通的无向图而言,P ...
- 算法设计和数据结构学习_5(BST&AVL&红黑树简单介绍)
前言: 节主要是给出BST,AVL和红黑树的C++代码,方便自己以后的查阅,其代码依旧是data structures and algorithm analysis in c++ (second ed ...
- 数据结构-堆 Java实现
数据结构-堆 Java实现. 实现堆自动增长 /** * 数据结构-堆. 自动增长 * */ public class Heap<T extends Comparable> { priva ...
- 数据结构 - 堆(Heap)
数据结构 - 堆(Heap) 1.堆的定义 堆的形式满足完全二叉树的定义: 若 i < ceil(n/2) ,则节点i为分支节点,否则为叶子节点 叶子节点只可能在最大的两层出现,而最大层次上的叶 ...
随机推荐
- 【9-7】XML学习笔记01
Tips XML标签大小写敏感: XML文件一般使用国际化通用的编码“utf-8”,所以平时看到的XML文件的头部都会有这样的代码: <?xml version="1.0" ...
- mouse scrollings and zooming operations in linux & windows are opposite
mouse scrollings and zooming operations in linux & windows are opposite. windows中, 鼠标滚动的方向是: 查看页 ...
- 查看mysql数据库的数据引擎
1, SHOW VARIABLES LIKE 'storage_engine'; 2,show table status from 数据库库名 where name='表名',例: mysql> ...
- java.lang.reflect.Method
java.lang.reflect.Method 一.Method类是什么 Method是一个类,位于java.lang.reflect包下. 在Java反射中 Method类描述的是 类的方法信息, ...
- 连接到kali linux服务器上的MySQL服务器错误
前言:想把数据库什么的都放在虚拟机kali Linux里,但无奈出了好多错误. 首先:可以参照上一篇文章开启kali服务器端的远程连接功能,上一篇文章 然后:使用window端的sqlyog(MySQ ...
- SQL Server2005主从复制实现
转自:http://blog.csdn.net/gaojier1000/article/details/5805814 一. 准备工作:1 .在发布服务器上建立一个共享目录,作为发布快照文件的 ...
- EF方便的添加一条信息...
//刚开始通过EF添加数据都是这样的...↓ var db = new DBEntities() T_User t_userinfo = new T_User() { Type = "typ ...
- AlwaysOn可用性组功能测试(一)--AlwaysOn故障转移测试
具体测试环境请参考: AlwaysOn可用性组测试环境安装与配置(一)--SQL群集环境搭建 AlwaysOn可用性组测试环境安装与配置(二)--AlwaysOn配置(界面与T-SQL) 一. Alw ...
- Android 4.4以上的存储读写权限
最近遇到一个奇怪现象,直接往Android的SD卡根目录写入文件,报异常:open failed EACCES:permission denied. 已经在manifest.xml中加入android ...
- 《深入浅出WPF》笔记一
1.项目模板 Visual Studio自动配置编译器参数,并准备好一套基本的源代码. 2.App.xaml/App.xaml.cs 声明程序的进程,并指定程序的主窗体. 3.Attribute和Pr ...