45.oracle表类型、数据拆分、表分区
不要做一些没有意义的事情,就比如说你要离职并不打算吃回头草,离职理由中完全没有必要说明“领导的水平太渣,人品太差”此类的原因,而是“个人原因”,当然实在不批准辞职另说。
oracle表类型
表的类型分为:
- 堆表,heap table:数据存储时,行是无序的,对它的访问采用全表扫描。
- 分区表 表>2G
- 索引组织表
- 簇表
- 临时表
- 压缩表
- 嵌套表
其实我们开发要关注的也就是前两种表。
我们日常开发使用的分表分库问题,其实是基于OLTP和OLAP的业务前提,然后对数据做切分,例如储值切分、水平切分。在oracle里早就有这个概念了,就是使用分区的方案
OLTP和OLAP
在互联网时代,海量数据的存储和访问成为系统设计与使用的瓶颈,对海量数据的处理,按照使用场景,主要分为两种类型:联机事务处理(OLTP)和联机分析处理(OLAP)。
联机事务处理(OLTP)也称为面向交易的处理,其中基本特征是原始数据可以立即传达到计算机中心进行处理,并在很短的时间内给出处理结果。(分布式事务)
联机分析处理(OLAP)是指通过多维的方式对数据进行分析、查询和报表,可以同数据挖掘工具、统计分析工具配合使用,增强决策分析能力。


(图片均源自网络)
数据拆分
指通过某个特定的条件和规则,将我们放在同一个数据库中的数据分散放到多个数据库(主机)上面,以达到分散单台设备负载的目的。
垂直切分:按照不同表(或者schema)来分到不同数据库(主机)上,这种切分可以称之为数据的垂直(纵向切分)。
水平切分:根据表中的数据的逻辑关系,将同一个表中的数据按照某种条件拆分到多台数据库(主机)上。
垂直切分最大的特点就是规则简单,实施也方便,尤其适合各个业务的耦合度非常低,相互影响很小,业务逻辑非常清晰的系统。这种系统中,可以很容易做到将不同的业务模块所使用的表拆分到不同的数据库中。根据不同的表来进行拆分,对应用程序的影响也很小。
垂直拆分的优点:
- 业务逻辑清晰
- 可扩展性强
- 维护简单方便
水平拆分的优点:
- 拆分规则做的足够好,基本可以实现库的join操作
- 应用端改造较少,可以稍微轻松实现业务逻辑,但是后期的需求变更维护起来比较麻烦。
- 不存在单库多数据,以及高并发下性能的瓶颈问题,提高系统的稳定性和负载能力
垂直拆分就是最上层的业务逻辑拆分,比如电商的供应商、商品、库存、订单、门户网站等,模块的业务流程清晰可见,最上层拆分即可。
水平拆分:比如涉及到用户信息,订单信息,一般会涉及多个系统,比如用户系统统计用户信息,根据用户级别等划分到不同的库,或者根据用户类型的方式把不同级别的用户分散到不同的数据库节点上,或者按照用户的序号ID,做求模方式等分散等待。(水平拆分一定是在精通业务的前提下进行的,保证拆分的正确性,后去的维护扩展性等;可以根据不同的数据信息,如时间单位年月日、不同类型的角色用户如供应商、会员用户或者按照不同业务规则等去拆分。)
数据拆分的缺点和解决方案
- 引入了分布式事务的问题。(针对不同场景案例,具体分析解决)
- 例如业务逻辑复杂时,可以使用SOA做通用服务,在service层上做多个切面,配置多个事务
- 数据量大且分析逻辑复杂时,使用缓冲库(中间库)、缓存表等数据库设计出来。
- 要求实时性非常改且数据信息、业务逻辑单一,使用第三方数据通信组件,例如消息队列做事务的毁掉服务,或者使用zookeeper建立分布式锁进行数据同步,或者使用直连的netty进行通信、类似webService、restfual等直连请求。
- 跨节点join的问题、跨节点合并、排序、分页等处理数据的问题。
- 通用方案是把数据组织好后放到缓存中取,定时或者实时进行同步。
- 如果要求实时性不是特别高,那么也可以使用中间库的手段去解决。
- 多数据源管理问题。
- 使用类似mycat的代理平台,代理多个数据源。
- 在每个应用程序模块中配置管理自己所需要的一个或者多个数据源,直接访问各个数据库,在模块内完成数据的整合。
分区表介绍
分区表是我们日常开发中最常用的技术,主要针对大数据量、频繁查询数据等需求,有了表分区,我们可以对表进行区间的拆分和组织,提高查询效率。一般来讲,oracle表分区的一个区间数据最好不大于500W条,也就是说500W条数据左右可以划分为一个区间,根据实际业务需求和表分区的性能而定。
oracle11g提供了7种分区,功能很强大,基本满足我们开发九成以上的需求,作为一个优秀的高程/架构方向的程序员,一定要对数据库存储的概念非常透彻,即使我们使用mysql也会有类似的分区技术,早期的mysql多用于水平和垂直“分区”,拆表拆字段的形式。
- range分区
- hash分区
- list分区
- 复合分区
- 间隔分区
- system分区
1.range分区
1.1 分区使用
range分区就是区域分区,按照定义的区域进行划分
语法:
create table(.....)
partition by range(field)(
partition p1 values less than(value),
partition p2 values less than(value),
partition p3 values less than(value)
);
查看分区情况:select * from user_tab_partitions;
查看分区数据:select * from table partition(p1);
修改分区:
添加:alter table tableName add partition p4 values less than(maxvalue);
删除:alter table tableName drop patition p4;
更新数据操作时不可以跨分区操作,会出现错误,需要设置可移动分区才能进行跨区查询。
alter table tableName enable row movement;
那如果开始建立的表是普通的堆表,后期想要改成分区表改如何操作?

来看一下效果:

插入时注意范围,必须要在分区内:

要想把3200插入那么就要添加一个能包含3500的分区:

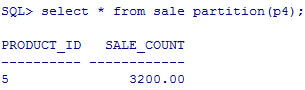
下面的报错信息大概意思是,更新会导致分区改变:

可以配置行移动,完了以后就上面就可以更新了:

1.2 分区索引
分区之后是可以提高查询效率,单页仅仅是添加了数据的范围,所以必要的情况下需要建立分区索引,从而进一步提高效率。
分区索引答题上可以分为两大类,一类叫做local,一类叫做global。
local:在每个分区上建立索引。
global:一种是在全局上建立索引,这种方式分不分区都一样,一般不使用。还有一种是自定义数据区间的索引,也叫作前缀索引,这个是很有意义的,自定义区域时注意必须要maxvalue。
另外要注意的是:在分区上建立的索引必须是分区字段列。
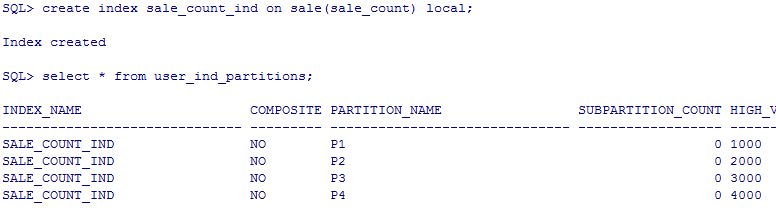
local方式语法:create index idxName on table(field) local;
查看分区索引:select * from user_ind_partitions;
global 自定义全局(前缀)索引语法:
create index idxname on table(field) global
partition by range(field)
(
partition p1 values less than(value),
partition p2 values less than(maxValue)
);
global 全局索引方式语法:create index idxname on table(field) global;(一般不使用)
一般采用的分区索引方式是:local
2.hash分区
hash分区实现均匀的负载分配,添加hash分区可以重新分布数据。
--建立散列分区表
create table my_emp
(
empno number,
ename varchar2(10)
)
prtition by hash(empno)
(
partition p1,
partition p2
);
3.list分区
create table pcity(
)
partition by list(city)
(
partition china values('qinhuangdao','hangzhou'),
partition america values('washington'),
partition other values('a','b')
)
4.复合分区
create table stud(
sno number,
sname varchar2(10)
)
partition by range(sno)
subpartition by hash(sname)
subpartition 4
(
partition p1 values less than(1000),
partition p2 values less than(2000),
partition p3 values less than(maxvalue)
);
上面的意思是先按照sno分为三个区域,再在各个分区里按照hash再分区。
5.间隔分区
interval partition 是一种自动化的分区,可以指定时间间隔进行分区,是oracle11g的新特性,这个功能在实际工作中很常用。
interval patitioning实际上是range分区的引申,最终实现range分区自动化。
语法:
create table interval_sale(
sid int,sdate timestamp
)
partition by range(sdate)
interval(numtoyminterval(1,'MONTH'))
(
partition p1 values less than(timestamp'2017-03-26 00:00:00')
)
从2017-03-26之后,每隔一个月创建一个分区。
分区就粗暴地理解成把一张表中数据分开存储在多个物理表中。
45.oracle表类型、数据拆分、表分区的更多相关文章
- 使用头文件cfloat中的符号常量获知浮点类型数据的表数范围---gyy整理
使用头文件cfloat中的符号常量获知浮点类型数据的表数范围 cfloat头文件包含了系统的浮点数的长度限制 头文件climits中的符号常量是获知整型数据的表数范围,并不能获取浮点类型数据的表数范围 ...
- 解决 Oracle exp导出表数据时空表不能导出的问题
一.不能导出空表的原因 1.Oracle11g默认对空表不分配segment,故使用exp导出Oracle11g数据库时,空表不会导出. 2.设置deferred_segment_creation 参 ...
- Django——8 关系表的数据操作 表关联对象的访问 多表查询
Django 关系表中的数据操作 表关联对象的访问 关联对象的add方法 create方法 remove方法 clear方法 多表查询 查询补充 聚合查询 分组查询 F查询 Q查询 关系表的数据操作 ...
- oracle 表空间 数据文件 表的关系
数据文件是表空间的容器,增加数据文件是增大表空间的容量,而不是往表空间里添加数据因此数据文件肯定能添加,如果表空间用完了,再添加新的数据就会报错你可以这样理解,数据库是一个箱子,表空间是箱子里的抽屉, ...
- ORACLE中 大量数据插入表 SQL
declare g_commit_count number; cursor cu1 is select gl_flexfields_pkg.get_description_sql(gcc.chart_ ...
- 利用spark将表中数据拆分
i# coding:utf-8from pyspark.sql import SparkSession import os if __name__ == '__main__': os.environ[ ...
- Oracle一条数据多表连插
insert all into T_TRAIN_MARSHALLING <trim prefix="(GKEY," suffix=")" suffixOv ...
- Oracle数据库字段数据拆分成多行(REGEXP_SUBSTR函数)
做多选功能时为了简便,会在某个字段中存储多个值,保存时虽然省事,但后续的查询统计时还需要拆分数据才行,因此这时需要将字段内的值分成多行以便后续使用. 下面这个例子实现了字段内数据的拆分: --创建测试 ...
- 【Oracle】删除(释放)数据文件/表空间流程
oracle删除(释放)数据文件/表空间流程 生产环境:数据库里空间不足,niptest 表空间251G,只使用了17G 再alter database datafile '...../niptest ...
- 浅谈MySql的存储引擎(表类型)
来源:http://www.cnblogs.com/lina1006/archive/2011/04/29/2032894.html 什么是MySql数据库 通常意义上,数据库也就是数据的集合,具体到 ...
随机推荐
- 关于网页头图标ico的问题
今天同事问了我一个比较奇怪的问题,对于我来说,可能和编码没什么关系,但是确实是头一次注意到,所以把问题记录了下来,方便以后积累经验. 问题就是: 在本地的网页中设置了头图标 <link rel= ...
- MYISM表并发写请求过多 导致无法被读取解决方案
MyISAM锁调度是如何实现的呢,这也是一个很关键的问题.例如,当一个进程请求某个MyISAM表的读锁,同时另一个进程也请求同一表的写锁,此时MySQL将会如优先处理进程呢?通过研究表明,写进程将先获 ...
- MySql创建多表关联的步骤
一,一对多表的创建 1.创建主表 create table HostTable( cid varchar(32) primary key, cname varchar(100)); 2.创建从表 cr ...
- .bat文件打开指定网页,并运行jar包
@echo off Start "" "C:\Users\Lenovo\AppData\Local\Google\Chrome\Application\chrome.ex ...
- java中时间
格式转化 SimpleDateFormat package day1211.common; import java.sql.Date;import java.sql.Timestamp;import ...
- 洛谷P1486 [NOI2004]郁闷的出纳员(splay)
题目描述 OIER公司是一家大型专业化软件公司,有着数以万计的员工.作为一名出纳员,我的任务之一便是统计每位员工的工资.这本来是一份不错的工作,但是令人郁闷的是,我们的老板反复无常,经常调整员工的工资 ...
- After Upgrade To Release 12.1.3 Users Receive "Function Not Available To This Responsibility" Error While Selecting Sub Menus Under Diagnostics (Doc ID 1200743.1)
APPLIES TO: Oracle Application Object Library - Version 12.1.3 to 12.1.3 [Release 12.1] Information ...
- 咏南中间件新增SQL日志
为了方便开发时跟踪调试SQL语句的执行情况,咏南中间件新增SQL日志,所有执行过的SQL都会写入SQL日志文件中. SQLDEBUG设为1,启用:设为0,停止写SQL日志.
- 利用SQL表生成按日期序列的唯一ID
1. 创建一个表,用于存现在最大的ID SELECT [ID],[PreFix],[Code] FROM [DocumentNO] 2. 增加SP,利用锁表,生成相应的ID Create PROCED ...
- linux下切换用户出现This account is currently not available
今天在一台新服务器下切换用户的时候出现“This account is currently not available”错误上网检索了一 下发现是用户的shell禁止登录的问题 解决办法:比如我是 s ...