python --爬虫基础 --爬猫眼top 100 使用 requests 库的基本操作
import requests
import re
import json
import time def get_page(url): # 获取页数
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'} # 請求頭信息
response = requests.get(url, headers=headers)
if response.status_code == 200: # 判断响应
return response.text
else:
None def parse_one_page(html): # 整理代码
pattern = re.compile(
'<dd>.*?board-index.*?>(.*?)</i>.*?data-src="(.*?)".*?name.*?a.*?>(.*?)</a>.*?star.*?>(.*?)</p>',
re.S) # re.S是非换行匹配空白符,匹配换行内的所有字符
items = re.findall(pattern, html)
for item in items:
yield {
'index': item[0],
'image': item[1],
'title': item[2], # strip(除去字符串左右两端的/N/T)
'actor': item[3].strip()[3:] # 取前三个人的名字 } def write_to_file(content):
with open('result.txt', 'a', encoding='utf -8') as f:
f.write(json.dumps(content, ensure_ascii=False) + '\n') def main(offset): # 定义运行函数
url = 'http://maoyan.com/board/4?offset='+str(offset)
#url = 'http://maoyan.com/board/4?offset=' + str(offset)
html = get_page(url)
for i in parse_one_page(html):
print(i)
write_to_file(i) if __name__ == '__main__':
for i in range(30):
main(i*10)
输出结果
D:\ProgramData\Anaconda3\python.exe C:/Users/Administrator/PycharmProjects/untitled3/pachong/demo1pachong.py
{'index': '1', 'image': 'http://p1.meituan.net/movie/20803f59291c47e1e116c11963ce019e68711.jpg@160w_220h_1e_1c', 'title': '霸王别姬', 'actor': '张国荣,张丰毅,巩俐'}
{'index': '2', 'image': 'http://p0.meituan.net/movie/283292171619cdfd5b240c8fd093f1eb255670.jpg@160w_220h_1e_1c', 'title': '肖申克的救赎', 'actor': '蒂姆·罗宾斯,摩根·弗里曼,鲍勃·冈顿'}
{'index': '3', 'image': 'http://p0.meituan.net/movie/54617769d96807e4d81804284ffe2a27239007.jpg@160w_220h_1e_1c', 'title': '罗马假日', 'actor': '格利高里·派克,奥黛丽·赫本,埃迪·艾伯特'}
{'index': '4', 'image': 'http://p0.meituan.net/movie/e55ec5d18ccc83ba7db68caae54f165f95924.jpg@160w_220h_1e_1c', 'title': '这个杀手不太冷', 'actor': '让·雷诺,加里·奥德曼,娜塔莉·波特曼'}
{'index': '5', 'image': 'http://p1.meituan.net/movie/f5a924f362f050881f2b8f82e852747c118515.jpg@160w_220h_1e_1c', 'title': '教父', 'actor': '马龙·白兰度,阿尔·帕西诺,詹姆斯·肯恩'}
{'index': '6', 'image': 'http://p1.meituan.net/movie/0699ac97c82cf01638aa5023562d6134351277.jpg@160w_220h_1e_1c', 'title': '泰坦尼克号', 'actor': '莱昂纳多·迪卡普里奥,凯特·温丝莱特,比利·赞恩'}
{'index': '7', 'image': 'http://p0.meituan.net/movie/da64660f82b98cdc1b8a3804e69609e041108.jpg@160w_220h_1e_1c', 'title': '唐伯虎点秋香', 'actor': '周星驰,巩俐,郑佩佩'}
{'index': '8', 'image': 'http://p0.meituan.net/movie/b076ce63e9860ecf1ee9839badee5228329384.jpg@160w_220h_1e_1c', 'title': '千与千寻', 'actor': '柊瑠美,入野自由,夏木真理'}
{'index': '9', 'image': 'http://p0.meituan.net/movie/46c29a8b8d8424bdda7715e6fd779c66235684.jpg@160w_220h_1e_1c', 'title': '魂断蓝桥', 'actor': '费雯·丽,罗伯特·泰勒,露塞尔·沃特森'}
{'index': '10', 'image': 'http://p0.meituan.net/movie/230e71d398e0c54730d58dc4bb6e4cca51662.jpg@160w_220h_1e_1c', 'title': '乱世佳人', 'actor': '费雯·丽,克拉克·盖博,奥利维娅·德哈维兰'}
........
Process finished with exit code 0
本文知识点
1:首先判断需要爬取的网址
http://maoyan.com/board/4?offset=
可以得知 随着点击下一页, offset= 的数字 会以10的倍数增长
2:抓取首页信息
创建 get_page(url)方法 传入参数url
def get_page(url): # 获取页数
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'} # 請求頭信息
response = requests.get(url, headers=headers)
if response.status_code == 200: # 判断响应
return response.text
else:
None def parse_one_page(html): # 整理代码
pattern = re.compile(
'<dd>.*?board-index.*?>(.*?)</i>.*?data-src="(.*?)".*?name.*?a.*?>(.*?)</a>.*?star.*?>(.*?)</p>',
re.S) # re.S是非换行匹配空白符,匹配换行内的所有字符
items = re.findall(pattern, html)
for item in items:
yield {
'index': item[0],
'image': item[1],
'title': item[2], # strip(除去字符串左右两端的/N/T)
'actor': item[3].strip()[3:] # 取前三个人的名字 }
分析原网页的html内容可知
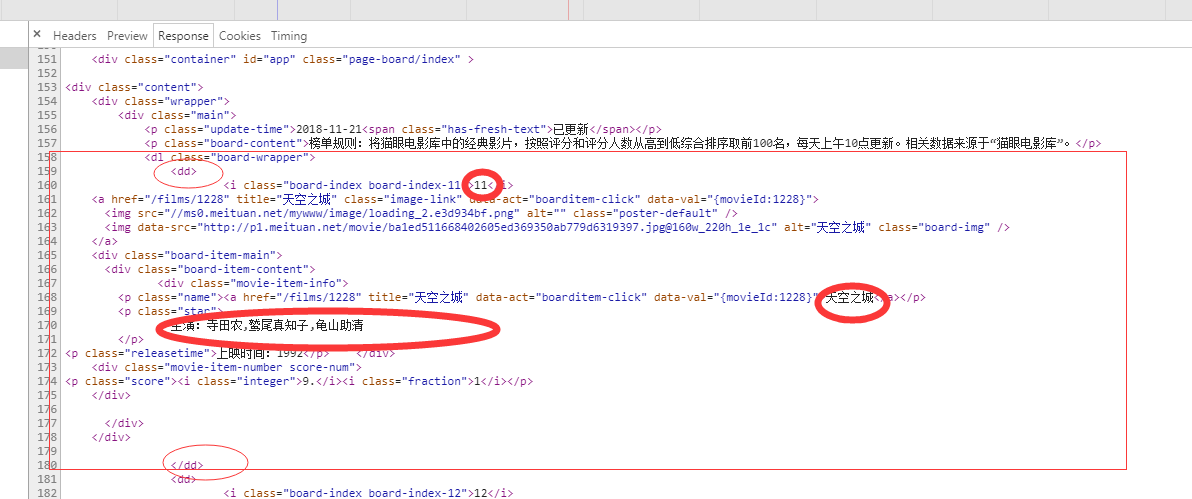
需要的内容在<dd>..</dd>内 之后通过正则提取内容
正则用到的知识点
/w 匹配字母
/W 匹配非字母
/d 匹配任意数字
/D 匹配任意非数字
/s 匹配任意空白符
. 匹配任意除了换行符以外的数字
* 匹配0个或者多个
? 匹配任意0个或1 个正则表达的片段
match() 起始位置匹配正则表达式
compile() 这个方法将正则表达式翻译成正则表达式对象
sub() 类似replace() 替换
findall() 搜索整个字符串.然后配备正则表达式返回的所有内容.,返回为列表内容
修饰符 r.S 使. 匹配包括换行符内的所有内容
<dd>
<i class="board-index board-index-12">12</i>
<a href="/films/9025" title="喜剧之王" class="image-link" data-act="boarditem-click" data-val="{movieId:9025}">
<img src="//ms0.meituan.net/mywww/image/loading_2.e3d934bf.png" alt="" class="poster-default" />
<img data-src="http://p1.meituan.net/movie/18e3191039d5e71562477659301f04aa61905.jpg@160w_220h_1e_1c" alt="喜剧之王" class="board-img" />
</a>
<div class="board-item-main">
<div class="board-item-content">
<div class="movie-item-info">
<p class="name"><a href="/films/9025" title="喜剧之王" data-act="boarditem-click" data-val="{movieId:9025}">喜剧之王</a></p>
<p class="star">
主演:周星驰,莫文蔚,张柏芝
</p>
<p class="releasetime">上映时间:1999-02-13(中国香港)</p> </div>
<div class="movie-item-number score-num">
<p class="score"><i class="integer">9.</i><i class="fraction">2</i></p>
</div>
</div>
</div>
</dd>
比如获取第一段想获取电影排名
正则表达式为
<dd>.*?board-index.*?(.*?)</i>
输出结果 12
其中红色为需要描述的地方,类似获取内容的截取点,绿色的地方为可以贪婪获取的地方(意思就是我给了头 ,给了尾 ' .*? ' 的地方你乐意是什么是什么. 其中('.*?'内的是需要返回的内容))
3 整理获取的内容
现在获取的内容是杂乱的. 需要将匹配的内容处理下.
def parse_one_page(html): # 整理代码
pattern = re.compile(
'<dd>.*?board-index.*?>(.*?)</i>.*?data-src="(.*?)".*?name.*?a.*?>(.*?)</a>.*?star.*?>(.*?)</p>',
re.S) # re.S是非换行匹配空白符,匹配换行内的所有字符
items = re.findall(pattern, html)
for item in items:
yield {
'index': item[0],
'image': item[1],
'title': item[2], # strip(除去字符串左右两端的/N/T)
'actor': item[3].strip()[3:] # 取前三个人的名字 }
其中 re.compile() , re.findall() 方法已经介绍. r.S是解释符
在利用生成器 yield 将内容生成字典的形式
4,写入文件
def write_to_file(content):
with open('result.txt', 'a', encoding='utf -8') as f:
f.write(json.dumps(content, ensure_ascii=False) + '\n')
获取字典通过json的dumps()方法实现字典的序列化
并且指定ensure_ascii 为False 这样可以保证输出的中文内容
大概就是这样. 内容不足后续补充
python --爬虫基础 --爬猫眼top 100 使用 requests 库的基本操作的更多相关文章
- python --爬虫基础 --爬取今日头条 使用 requests 库的基本操作, Ajax
'''思路一: 由于是Ajax的网页,需要先往下划几下看看XHR的内容变化二:分析js中的代码内容三:获取一页中的内容四:获取图片五:保存在本地 使用的库1. requests 网页获取库 2.fro ...
- Python爬虫笔记一(来自MOOC) Requests库入门
Python爬虫笔记一(来自MOOC) 提示:本文是我在中国大学MOOC里面自学以及敲的一部分代码,纯一个记录文,如果刚好有人也是看的这个课,方便搬运在自己电脑上运行. 课程为:北京理工大学-嵩天-P ...
- Python爬虫基础--爬取车模照片
import urllib from urllib import request, parse from lxml import etree class CarModel: def __init__( ...
- python爬虫-基础入门-爬取整个网站《3》
python爬虫-基础入门-爬取整个网站<3> 描述: 前两章粗略的讲述了python2.python3爬取整个网站,这章节简单的记录一下python2.python3的区别 python ...
- python爬虫-基础入门-爬取整个网站《2》
python爬虫-基础入门-爬取整个网站<2> 描述: 开场白已在<python爬虫-基础入门-爬取整个网站<1>>中描述过了,这里不在描述,只附上 python3 ...
- python爬虫-基础入门-爬取整个网站《1》
python爬虫-基础入门-爬取整个网站<1> 描述: 使用环境:python2.7.15 ,开发工具:pycharm,现爬取一个网站页面(http://www.baidu.com)所有数 ...
- Python爬虫基础
前言 Python非常适合用来开发网页爬虫,理由如下: 1.抓取网页本身的接口 相比与其他静态编程语言,如java,c#,c++,python抓取网页文档的接口更简洁:相比其他动态脚本语言,如perl ...
- from appium import webdriver 使用python爬虫,批量爬取抖音app视频(requests+Fiddler+appium)
使用python爬虫,批量爬取抖音app视频(requests+Fiddler+appium) - 北平吴彦祖 - 博客园 https://www.cnblogs.com/stevenshushu/p ...
- python爬虫-基础入门-python爬虫突破封锁
python爬虫-基础入门-python爬虫突破封锁 >> 相关概念 >> request概念:是从客户端向服务器发出请求,包括用户提交的信息及客户端的一些信息.客户端可通过H ...
随机推荐
- py学习之FTP
1.FTP之参数解析与命令分发 a) 层级目录如下 b) 配置文件如下 #!/usr/bin/env python # -*- coding:utf8 -*- import socket sk=soc ...
- requests.session之set trust_env to disable environment searches for proxies
import requests s = requests.Session() s.trust_env = False This will prevent requests getting any in ...
- http://www.atool.org/keytype.php#0-tsina-1-53371-397232819ff9a47a7b7e80a40613cfe1
http://www.atool.org/keytype.php#0-tsina-1-53371-397232819ff9a47a7b7e80a40613cfe1
- Mybatis之Configuration初始化(配置文件.xml的解析)
源码解读第一步我觉着应该从Mybatis如何解析配置文件开始. 1.先不看跟Spring集成如何解析,先看从SqlSessionFactoryBuilder如果解析的. String resouce ...
- FZU 1977 Pandora adventure (DP)
题意:给定一个图,X表示不能走,O表示必须要走,*表示可走可不走,问你多少种走的法,使得形成一个回路. 析: 代码如下: #pragma comment(linker, "/STACK:10 ...
- linux相关文章链接
薄荷开元网 http://www.mintos.org/
- 加载 bean.xml 的几种方式 (java or web project)
1. java project ApplicationContext ctx = new ClassPathXmlApplicationContext("classpath:bean1.xm ...
- linux每天一小步---head命令详解
1 命令功能 head命令用来查看文件的前多少行或多少字节的内容(默认显示10行) 2 命令语法 head [选项参数] [文件名] 3 命令参数 -q 显示多个文件的内容时不显示文件 ...
- Linux 基础教程 32-解压缩命令
将文件压缩后对提升数据传输效率,降低传输带宽,管理备份数据都有非常重要的功能,因此文件压缩解压技能就成为必备技能.相对于Windows中的文件解压缩工具百花争艳,在Linux中的解压缩工具则要 ...
- openGL中的原理理解1---一个视图需要支持OGL需要配置,GLenbalView的理解
OpenGL的绘图机制是 OpenGL的绘图方式与Windows一般的绘图方式是不同的,主要区别如下: (1)Windows采用的是GDI(Graphy Device Interface 图形设备接口 ...