强化学习系列之:Deep Q Network (DQN)
文章目录 [隐藏]
我们终于来到了深度强化学习。
1. 强化学习和深度学习结合
机器学习=目标+表示+优化。目标层面的工作关心应该学习到什么样的模型,强化学习应该学习到使得激励函数最大的模型。表示方面的工作关心数据表示成什么样有利于学习,深度学习是最近几年兴起的表示方法,在图像和语音的表示方面有很好的效果。深度强化学习则是两者结合在一起,深度学习负责表示马尔科夫决策过程的状态,强化学习负责把控学习方向。
深度强化学习有三条线:分别是基于价值的深度强化学习,基于策略的深度强化学习和基于模型的深度强化学习。这三种不同类型的深度强化学习用深度神经网络替代了强化学习的不同部件。基于价值的深度强化学习本质上是一个 Q Learning 算法,目标是估计最优策略的 Q 值。 不同的地方在于 Q Learning 中价值函数近似用了深度神经网络。比如 DQN 在 Atari 游戏任务中,输入是 Atari 的游戏画面,因此使用适合图像处理的卷积神经网络(Convolutional Neural Network,CNN)。下图就是 DQN 的框架图。
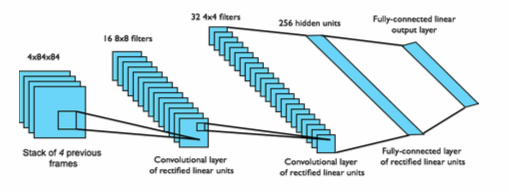
2. Deep Q Network (DQN) 算法
当然了基于价值的深度强化学习不仅仅是把 Q Learning 中的价值函数用深度神经网络近似,还做了其他改进。
这个算法就是著名的 DQN 算法,由 DeepMind 在 2013 年在 NIPS 提出。DQN 算法的主要做法是 Experience Replay,其将系统探索环境得到的数据储存起来,然后随机采样样本更新深度神经网络的参数。

Experience Replay 的动机是:1)深度神经网络作为有监督学习模型,要求数据满足独立同分布,2)但 Q Learning 算法得到的样本前后是有关系的。为了打破数据之间的关联性,Experience Replay 方法通过存储-采样的方法将这个关联性打破了。
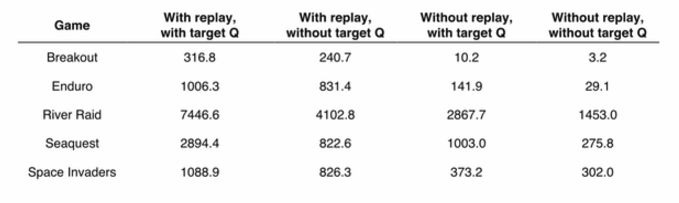
DeepMind 在 2015 年初在 Nature 上发布了文章,引入了 Target Q 的概念,进一步打破数据关联性。Target Q 的概念是用旧的深度神经网络 w^{-} 去得到目标值,下面是带有 Target Q 的 Q Learning 的优化目标。
下图是 Nature 论文上的结果。可以看到,打破数据关联性确实很大程度地提高了效果。
3. 后续发展
DQN 是第一个成功地将深度学习和强化学习结合起来的模型,启发了后续一系列的工作。这些后续工作中比较有名的有 Double DQN, Prioritized Replay 和 Dueling Network。
3.1 Double DQN
Thrun 和 Schwartz 在古老的 1993 年观察到 Q-Learning 的过优化 (overoptimism) 现象 [1],并且指出过优化现象是由于 Q-Learning 算法中的 max 操作造成的。令 (Q^{target}(s,a)) 是目标 Q 值;我们用了价值函数近似,Q^{approx} 是近似 Q 值;令 Y 为近似值和目标之间的误差,即
Q-learning 算法更新步骤将所有的 Q 值更新一遍,这个时候近似值和目标值之间的差值
其中 a’ = argmax_{a} Q^{target}(s’,a)。这时候我们发现,即使 E[Y] = 0 也就是一开始是无偏的近似, Q Learning 中的 max 操作也会导致 E[Z] > 0。这就是过优化现象。为了解决这个问题,Thrun 和 Schwartz 提出了 Double Q 的想法。
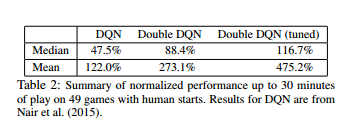
Hasselt 等进一步分析了过优化的现象,并将 Double Q 的想法应用在 DQN 上,从而提出了 Double DQN。Double DQN 训练两个 Q 网络,一个负责选择动作,另一个负责计算。两个 Q 网络交替进行更新,具体算法如下所示。

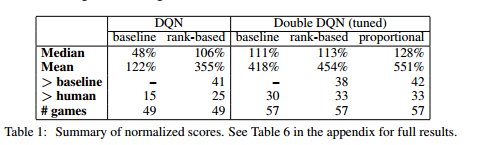
下图是 Hasselt 在论文中报告的实验结果。从实验结果来看,Double DQN 拥有比 DQN 好的效果。
3.2 Prioritized Replay
DQN 用了 Experience Replay 算法,将系统探索环境获得的样本保存起来,然后从中采样出样本以更新模型参数。对于采样,一个常见的改进是改变采样的概率。Prioritized Replay [3] 便是采取了这个策略,采用 TD-err 作为评判标准进行采样。
下图是论文中采用的例子。例子中有 n 个状态,在每个状态系统一半概率采取 “正确” 或者一半概率 “错误”,图中红色虚线是错误动作。一旦系统采取错误动作,游戏结束。只有第 n 个状态 “正确” 朝向第 1 个状态,系统获得奖励 1。在这个例子训练过程中,系统产生无效样本,导致训练效率底下。如果采用 TD-err 作为评判标准进行采样,能够缓解这个问题。

论文报告了 Prioritized Replay 算法效果。从下图来看,Prioritized Replay 效果很好。
3.3 Dueling Network
Baird 在 1993 年提出将 Q 值分解为价值 (Value) 和优势 (Advantage) [4]。
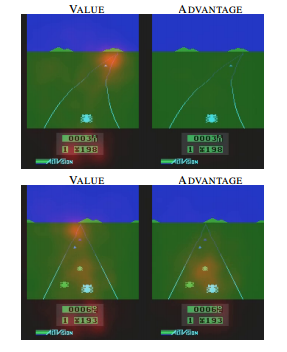
这个想法可以用下面的例子说明 [5]。上面两张图表示,前方无车时,选择什么动作并不会太影响行车状态。这个时候系统关注状态的价值,而对影响动作优势不是很关心。下面两张图表示,前方有车时,选择动作至关重要。这个时候系统需要关心优势了。这个例子说明,Q 值分解为价值和优势更能刻画强化学习的过程。
Wang Z 将这个 idea 应用在深度强化学习中,提出了下面的网络结构 [5]。
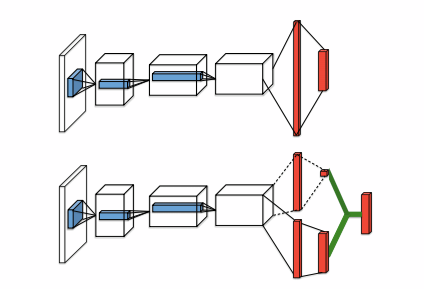
这种网络结构很简单,但获得了很好的效果。
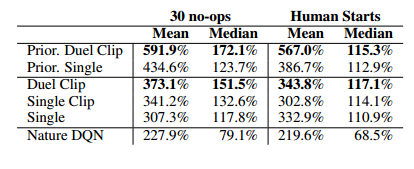
Dueling Network 是一个深度学习的网络结构。它可以结合之前介绍的 Experience Replay、 Double DQN 和 Prioritized Replay 等方法。 作者在论文中报告 Dueling Network 和 Prioritized Replay 结合的效果最好。
4. 总结
上次本来想把基于价值的深度强化学习的 Double DQN, Prioritized Replay 和 Dueling Network 也写了的,写到晚上 2 点。现在补上这部分内容。
从上面介绍来看,DQN、 Double DQN、Prioritized Replay 和 Dueling Network 都能在深度学习出现之前的工作找到一些渊源。深度学习的出现,将这些方法的效果提高了前所未有的高度。
文章结尾欢迎关注我的公众号 AlgorithmDog,每次更新就会有提醒哦~
[1] S. Thrun and A. Schwartz. Issues in using function approximation for reinforcement learning. In M. Mozer, P. Smolensky, D. Touretzky, J. Elman, and A. Weigend, editors, Proceedings of the 1993 Connectionist Models Summer School, Hillsdale, NJ, 1993. Lawrence Erlbaum.
[2] Van Hasselt, Hado, Arthur Guez, and David Silver. “Deep reinforcement learning with double Q-learning.” CoRR, abs/1509.06461 (2015).
[3] Schaul T, Quan J, Antonoglou I, et al. Prioritized experience replay[J]. arXiv preprint arXiv:1511.05952, 2015.
[4] Baird, L.C. Advantage updating. Technical Report WLTR-93-1146,
Wright-Patterson Air Force Base, 1993.
[5] Wang Z, de Freitas N, Lanctot M. Dueling network architectures for deep reinforcement learning[J]. arXiv preprint arXiv:1511.06581, 2015.
强化学习系列之:Deep Q Network (DQN)的更多相关文章
- Deep Q Network(DQN)原理解析
1. 前言 在前面的章节中我们介绍了时序差分算法(TD)和Q-Learning,当状态和动作空间是离散且维数不高时可使用Q-Table储存每个状态动作对的Q值,而当状态和动作空间是高维连续时,使用Q- ...
- 【转】【强化学习】Deep Q Network(DQN)算法详解
原文地址:https://blog.csdn.net/qq_30615903/article/details/80744083 DQN(Deep Q-Learning)是将深度学习deeplearni ...
- 深度增强学习--Deep Q Network
从这里开始换个游戏演示,cartpole游戏 Deep Q Network 实例代码 import sys import gym import pylab import random import n ...
- 强化学习之六:Deep Q-Network and Beyond
本文是对Arthur Juliani在Medium平台发布的强化学习系列教程的个人中文翻译,该翻译是基于个人分享知识的目的进行的,欢迎交流!(This article is my personal t ...
- AlphaGo的前世今生(一)Deep Q Network and Game Search Tree:Road to AI Revolution
这一个专题将会是有关AlphaGo的前世今生以及其带来的AI革命,总共分成三节.本人水平有限,如有错误还望指正.如需转载,须征得本人同意. Road to AI Revolution(通往AI革命之路 ...
- 深度强化学习:入门(Deep Reinforcement Learning: Scratching the surface)
RL的方案 两个主要对象:Agent和Environment Agent观察Environment,做出Action,这个Action会对Environment造成一定影响和改变,继而Agent会从新 ...
- 强化学习复习笔记 - DEEP
Outline 激活函数 使用逼近器的特点: 较少数量的参数表达复杂的函数 (计算复杂度) 对一个权重的调整可以影响到很多的点 (泛化能力) 多种特征表示和逼近器结构 (多样性) 激活函数 Sigmo ...
- 【转】强化学习(一)Deep Q-Network
原文地址:https://www.hhyz.me/2018/08/05/2018-08-05-RL/ 1. 前言 虽然将深度学习和增强学习结合的想法在几年前就有人尝试,但真正成功的开端就是DeepMi ...
- 深度强化学习(Deep Reinforcement Learning)入门:RL base & DQN-DDPG-A3C introduction
转自https://zhuanlan.zhihu.com/p/25239682 过去的一段时间在深度强化学习领域投入了不少精力,工作中也在应用DRL解决业务问题.子曰:温故而知新,在进一步深入研究和应 ...
随机推荐
- 【kuangbin】计算几何部分最新模板
二维几何部分 // `计算几何模板` ; const double inf = 1e20; const double pi = acos(-1.0); ; //`Compares a double t ...
- C++类的构造函数及定义
定义一个普通的类时,一定要定义它自己的构造函数.原因有三:第一个原因是编译器只有在发现类不包含任何构造函数的情况下才会替我们生成一个默认的构造函数,一旦我们定义了一些其他的构造函数,那么除非我们再定义 ...
- 不支持这个操作系统WNT_6.3I_64
安装winserver2012驱动时,经常会因为版本的关系,出现向后兼容问题: 编辑驱动安装配置ini, 添加向后兼容的标识即可:WNT_6.3I_64= Win81_64 删除system下的程序( ...
- SpringMVC初写(五)拦截器
在系统开发过程中,拦截器的使用可以使我们实现一些需求.如:登录认证,权限管理等,拦截器的工作核心就是将一些工作流程进行统一处理 拦截器和过滤器的区别: 过滤器过滤的是请求路径,拦截器拦截的各层方法的映 ...
- java处理数据库的CRUD
package com.lhy.jdbc.util; import java.sql.Connection; import java.sql.PreparedStatement; import jav ...
- javac的命令(-Xbootclasspath、-classpath与-sourcepath等)
当编译源文件时,编译器常常需要识别出类型的有关信息.对于源文件中使用.扩展或实现的每个类或接口,编译器都需要其类型信息.这包括在源文件中没有明确提及.但通过继承提供信息的类和接口. 例如,当扩展 ja ...
- unity编辑器教程
https://blog.csdn.net/candycat1992/article/details/52067975
- Integer 与 int -- 自动装箱(autoboxing)与自动拆箱(unboxing)
转载于 http://www.ticmy.com/?p=110 jdk1.5引入了自动装箱(autoboxing)与自动拆箱(unboxing),这方便了集合类以及一些方法的调用,同时也使初学者对其感 ...
- [PY3]——pwd | grp 模块
pwd和grp模块都非常简单粗暴,各自分别下面都只有三个函数,来根据/etc/passwd./etc/group文件获取相关信息 getpwuid(UID):根据UID获取用户信息,返回一个list ...
- jQuery适用技巧笔记整合
1.关于页面元素的引用 通过jquery的$()引用元素包括通过id.class.元素名以及元素的层级关系及dom或者xpath条件等方法,且返回的对象为jquery对象(集合对象),不能直接调用do ...