spark(二)
一、spark的提交模式
--master(standalone\YRAN\mesos)
standalone:-client -cluster 如果我们用client模式去提交程序,我们在哪个地方提交的代码,哪个地方就启动driver;如果我们用的是cluster模式去提交,spark会在集群随机挑一台作为driver
./bin/spark-shell --master spark://master:7077 --deploy-mode client 这样打印出的日志信息比较信息,便于调试
YARN:
--client 申请资源 driver-applicationmaster-RM,剩下一样
--cluster driver和applicationmaster在同一台机器上
提交:bin/saprk-submit --master yarn --deploy-mode client (1.6.0版本)

构建一套hadoop集群:
Hadoop
Hive
Hbase
Spark
Zookeeper
二、spark 调优
mapreduce shuffle

未经过优化的shuffle

经过优化的shuffle:


三、spark作业的运行(spark的内存模型)
四、开发调优
原则一:对多次使用的RDD进行持久化
Spark中对于一个RDD执行多次算子的默认原理是这样的:每次你对一个RDD执行一个算子操作时,都会重新从源头处计算一遍,计算出那个RDD来,然后再对这个RDD执行你的算子操作。这种方式的性能是很差的。
因此对于这种情况,我们的建议是:对多次使用的RDD进行持久化。此时Spark就会根据你的持久化策略,将RDD中的数据保存到内存或者磁盘中。以后每次对这个RDD进行算子操作时,都会直接从内存或磁盘中提取持久化的RDD数据,然后执行算子,而不会从源头处重新计算一遍这个RDD,再执行算子操作。
Persist(StorageLevel.MEMORY_ONLY) = cache

原则二:避免创建重复的RDD
通常来说,我们在开发一个Spark作业时,首先是基于某个数据源(比如Hive表或HDFS文件)创建一个初始的RDD;接着对这个RDD执行某个算子操作,然后得到下一个RDD;以此类推,循环往复,直到计算出最终我们需要的结果。在这个过程中,多个RDD会通过不同的算子操作(比如map、reduce等)串起来,这个“RDD串”,就是RDD lineage,也就是“RDD的血缘关系链”。
我们在开发过程中要注意:对于同一份数据,只应该创建一个RDD,不能创建多个RDD来代表同一份数据。
一些Spark初学者在刚开始开发Spark作业时,或者是有经验的工程师在开发RDD lineage极其冗长的Spark作业时,可能会忘了自己之前对于某一份数据已经创建过一个RDD了,从而导致对于同一份数据,创建了多个RDD。这就意味着,我们的Spark作业会进行多次重复计算来创建多个代表相同数据的RDD,进而增加了作业的性能开销
Val rdd1=sc.textFile(“xxxx”);
...
...
Val rdd2=sc.textFile(“xxxx”);
大家注意的是,当我们代码量较大的时候,很有可能就会出现这样的情况。
原则三:尽可能复用RDD
除了要避免在开发过程中对一份完全相同的数据创建多个RDD之外,在对不同的数据执行算子操作时还要尽可能地复用一个RDD。比如说,有一个RDD的数据格式是key-value类型的,另一个rdd是单value类型的,这两个RDD的value数据是完全一样的。那么此时我们可以只使用key-value类型的那个RDD,因为其中已经包含了另一个的数据。对于类似这种多个RDD的数据有重叠或者包含的情况,我们应该尽量复用一个RDD,这样可以尽可能地减少RDD的数量,从而尽可能减少算子执行的次数。
错误用法:
JavaPairRDD<String,Long> rdd1=.....
RDD<String> rdd2=.....
rdd1.reduceBykey(_+_)
--rdd2.map()
正确用法:
rdd1.map( result => result._1).map().filter()
原则四:尽量避免使用shuffle类算子
如果有可能的话,要尽量避免使用shuffle类算子。因为Spark作业运行过程中,最消耗性能的地方就是shuffle过程。shuffle过程,简单来说,就是将分布在集群中多个节点上的同一个key,拉取到同一个节点上,进行聚合或join等操作。比如reduceByKey、join等算子,都会触发shuffle操作。
shuffle过程中,各个节点上的相同key都会先写入本地磁盘文件中,然后其他节点需要通过网络传输拉取各个节点上的磁盘文件中的相同key。而且相同key都拉取到同一个节点进行聚合操作时,还有可能会因为一个节点上处理的key过多,导致内存不够存放,进而溢写到磁盘文件中。因此在shuffle过程中,可能会发生大量的磁盘文件读写的IO操作,以及数据的网络传输操作。磁盘IO和网络数据传输也是shuffle性能较差的主要原因。
因此在我们的开发过程中,能避免则尽可能避免使用reduceByKey、join、distinct、repartition等会进行shuffle的算子,尽量使用map类的非shuffle算子。这样的话,没有shuffle操作或者仅有较少shuffle操作的Spark作业,可以大大减少性能开销。
发生shuffle的算子:
1) 重分区 reparation reparationAndSortWhithInpartition coalesce等
2) Bykey类的算子:reduceBykey groupBykey sortBykey等
3) Join类:join cogroup等
原则五:使用map-side预聚合的shuffle算子
如果因为业务需要,一定要使用shuffle操作,无法用map类的算子来替代,那么尽量使用可以map-side预聚合的算子。
所谓的map-side预聚合,说的是在每个节点本地对相同的key进行一次聚合操作,类似于MapReduce中的本地combin。map-side预聚合之后,每个节点本地就只会有一条相同的key,因为多条相同的key都被聚合起来了。其他节点在拉取所有节点上的相同key时,就会大大减少需要拉取的数据数量,从而也就减少了磁盘IO以及网络传输开销。通常来说,在可能的情况下,建议使用reduceByKey或者aggregateByKey算子来替代掉groupByKey算子。因为reduceByKey和aggregateByKey算子都会使用用户自定义的函数对每个节点本地的相同key进行预聚合。而groupByKey算子是不会进行预聚合的,全量的数据会在集群的各个节点之间分发和传输,性能相对来说比较差。
原则六:使用高性能算子
使用reduceByKey/aggregateByKey替代groupByKey
使用mapPartitions替代普通map
使用foreachPartitions替代foreach
使用filter之后进行coalesce操作
使用repartitionAndSortWithinPartitions替代repartition与sort类操作
groupbykey:

aggregateByKeys:

原则七: 广播变量
有时在开发过程中,会遇到需要在算子函数中使用外部变量的场景(尤其是大变量,比如100M以上的大集合),那么此时就应该使用Spark的广播(Broadcast)功能来提升性能。
在算子函数中使用到外部变量时,默认情况下,Spark会将该变量复制多个副本,通过网络传输到task中,此时每个task都有一个变量副本。如果变量本身比较大的话(比如100M,甚至1G),那么大量的变量副本在网络中传输的性能开销,
以及在各个节点的Executor中占用过多内存导致的频繁GC,都会极大地影响性能。
因此对于上述情况,如果使用的外部变量比较大,建议使用Spark的广播功能,对该变量进行广播。广播后的变量,会保证每个Executor的内存中,只驻留一份变量副本,而Executor中的task执行时共享该Executor中的那份变量副本。这样的话,
可以大大减少变量副本的数量,从而减少网络传输的性能开销,并减少对Executor内存的占用开销,降低GC的频率。

原则八:使用Kryo优化序列化性能
在Spark中,主要有三个地方涉及到了序列化:
1)在算子函数中使用到外部变量时,该变量会被序列化后进行网络传输(见广播大变量”中的讲解)。
2)将自定义的类型作为RDD的泛型类型时(比如JavaRDD,Student是自定义类型),所有自定义类型对象,都会进行序列化。因此这种情况下,也要求自定义的类必须实现Serializable接口。
3)使用可序列化的持久化策略时(比如MEMORY_ONLY_SER),Spark会将RDD中的每个partition都序列化成一个大的字节数组。
对于这三种出现序列化的地方,我们都可以通过使用Kryo序列化类库,来优化序列化和反序列化的性能。Spark默认使用的是Java的序列化机制,也就是ObjectOutputStream/ObjectInputStream API来进行序列化和反序列化。但是Spark同时支持使用Kryo序列化库,
Kryo序列化类库的性能比Java序列化类库的性能要高很多。官方介绍,Kryo序列化机制比Java序列化机制,性能高10倍左右。Spark之所以默认没有使用Kryo作为序列化类库,是因为Kryo要求最好要注册所有需要进行序列化的自定义类型,因此对于开发者来说,这种方式比较麻烦。

原则九:优化数据结构
Java中,有三种类型比较耗费内存:
1)对象,每个Java对象都有对象头、引用等额外的信息,因此比较占用内存空间。
2)字符串,每个字符串内部都有一个字符数组以及长度等额外信息。
3)集合类型,比如HashMap、LinkedList等,因为集合类型内部通常会使用一些内部类来封装集合元素,比如Map.Entry。
因此Spark官方建议,在Spark编码实现中,特别是对于算子函数中的代码,尽量不要使用上述三种数据结构,尽量使用字符串替代对象,使用原始类型(比如Int、Long)替代字符串,使用数组替代集合类型,这样尽可能地减少内存占用,从而降低GC频率,提升性能。
建议:我们在实际的开发中,要做到如上所述,其实不容易。我们要考虑到代码可维护性,如果一个代码里面,完全没有抽象,全部都是字符串的拼接,对于后面的代码维护和修改难度很大。
所以我们应该考虑在合适的时候采取考虑这样的优化方式,因为我们首先得考虑代码的维护性。
五、资源调优
--num -executor 一般设置在 50 -100之间
--executor -memory 6G (4-8G,不要超过队列总内存的二分之一)
--executor-cores (1:3 一个cpu核对应三个task)
--Driver -memory (最好设置为1G)
Spark.default.parallelism 设置task数量,根据核的数量设置,(默认情况下一个HDFSblock文件就对应一个task,所以默认情况下,task数量偏少,所以需要调task数量,根据一个cpu核对应三个task)

六、数据倾斜
数据倾斜现象:
1、最常见的就是99%的task几秒就搞定了,但是其中一两个需要一两小时才能完成。
2、突然报OOM这种情况比较少
数据倾斜的原理:

如何定位代码出现的问题:(看日志、看页面、查看发生shuffle的算子)

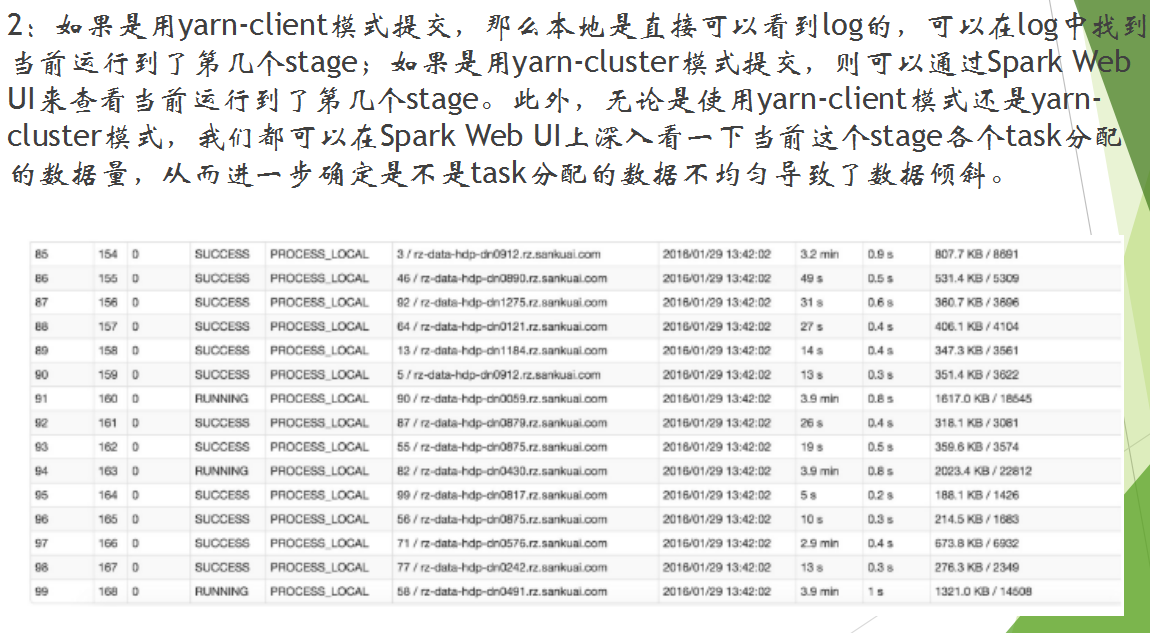
如何解决数据倾斜:
解决方案一:Hive ETL预处理
方案适用场景:导致数据倾斜的是Hive表。如果该Hive表中的数据本身很不均匀(比如某个key对应了100万数据,其他key才对应了10条数据),而且业务场景需要频繁使用Spark对Hive表执行某个分析操作,那么比较适合使用这种技术方案。
方案实现思路:此时可以评估一下,是否可以通过Hive来进行数据预处理(即通过Hive ETL预先对数据按照key进行聚合,或者是预先和其他表进行join),然后在Spark作业中针对的数据源就不是原来的Hive表了,而是预处理后的Hive表。此时由于数据已经预先进行过聚合或join操作了,那么在Spark作业中也就不需要使用原先的shuffle类算子执行这类操作了。
方案实现原理:这种方案从根源上解决了数据倾斜,因为彻底避免了在Spark中执行shuffle类算子,那么肯定就不会有数据倾斜的问题了。但是这里也要提醒一下大家,这种方式属于治标不治本。因为毕竟数据本身就存在分布不均匀的问题,所以Hive ETL中进行group by或者join等shuffle操作时,还是会出现数据倾斜,导致Hive ETL的速度很慢。我们只是把数据倾斜的发生提前到了Hive ETL中,避免Spark程序发生数据倾斜而已。
方案优点:实现起来简单便捷,效果还非常好,完全规避掉了数据倾斜,Spark作业的性能会大幅度提升。
方案缺点:治标不治本,Hive ETL中还是会发生数据倾斜。
解决方案二:过滤少数导致倾斜的key
方案适用场景:如果发现导致倾斜的key就少数几个,而且对计算本身的影响并不大的话,那么很适合使用这种方案。比如99%的key就对应10条数据,但是只有一个key对应了100万数据,从而导致了数据倾斜。
方案实现思路:如果我们判断那少数几个数据量特别多的key,对作业的执行和计算结果不是特别重要的话,那么干脆就直接过滤掉那少数几个key。比如,在Spark SQL中可以使用where子句过滤掉这些key或者在Spark Core中对RDD执行filter算子过滤掉这些key。如果需要每次作业执行时,动态判定哪些key的数据量最多然后再进行过滤,那么可以使用sample算子对RDD进行采样,然后计算出每个key的数量,取数据量最多的key过滤掉即可。
方案实现原理:将导致数据倾斜的key给过滤掉之后,这些key就不会参与计算了,自然不可能产生数据倾斜。
方案优点:实现简单,而且效果也很好,可以完全规避掉数据倾斜。
方案缺点:适用场景不多,大多数情况下,导致倾斜的key还是很多的,并不是只有少数几个。
方案实践经验:在项目中我们也采用过这种方案解决数据倾斜。有一次发现某一天Spark作业在运行的时候突然OOM了,追查之后发现,是Hive表中的某一个key在那天数据异常,导致数据量暴增。因此就采取每次执行前先进行采样,计算出样本中数据量最大的几个key之后,直接在程序中将那些key给过滤掉。
解决方案三:提高shuffle操作的并行度
方案适用场景:如果我们必须要对数据倾斜迎难而上,那么建议优先使用这种方案,因为这是处理数据倾斜最简单的一种方案。
方案实现思路:在对RDD执行shuffle算子时,给shuffle算子传入一个参数,比如reduceByKey(1000),该参数就设置了这个shuffle算子执行时shuffle read task的数量。对于Spark SQL中的shuffle类语句,比如group by、join等,需要设置一个参数,即spark.sql.shuffle.partitions,该参数代表了shuffle read task的并行度,该值默认是200,对于很多场景来说都有点过小。
方案实现原理:增加shuffle read task的数量,可以让原本分配给一个task的多个key分配给多个task,从而让每个task处理比原来更少的数据。举例来说,如果原本有5个key,每个key对应10条数据,这5个key都是分配给一个task的,那么这个task就要处理50条数据。而增加了shuffle read task以后,每个task就分配到一个key,即每个task就处理10条数据,那么自然每个task的执行时间都会变短了。具体原理如下图所示。
方案优点:实现起来比较简单,可以有效缓解和减轻数据倾斜的影响。
方案缺点:只是缓解了数据倾斜而已,没有彻底根除问题,根据实践经验来看,其效果有限。
方案实践经验:该方案通常无法彻底解决数据倾斜,因为如果出现一些极端情况,比如某个key对应的数据量有100万,那么无论你的task数量增加到多少,这个对应着100万数据的key肯定还是会分配到一个task中去处理,因此注定还是会发生数据倾斜的。所以这种方案只能说是在发现数据倾斜时尝试使用的第一种手段,尝试去用嘴简单的方法缓解数据倾斜而已,或者是和其他方案结合起来使用。

解决方案四:两阶段聚合(局部聚合+全局聚合)
方案适用场景:对RDD执行reduceByKey等聚合类shuffle算子或者在Spark SQL中使用group by语句进行分组聚合时,比较适用这种方案。
方案实现思路:这个方案的核心实现思路就是进行两阶段聚合。第一次是局部聚合,先给每个key都打上一个随机数,比如10以内的随机数,此时原先一样的key就变成不一样的了,比如(hello, 1) (hello, 1) (hello, 1) (hello, 1),就会变成(1_hello, 1) (1_hello, 1) (2_hello, 1) (2_hello, 1)。接着对打上随机数后的数据,执行reduceByKey等聚合操作,进行局部聚合,那么局部聚合结果,就会变成了(1_hello, 2) (2_hello, 2)。然后将各个key的前缀给去掉,就会变成(hello,2)(hello,2),再次进行全局聚合操作,就可以得到最终结果了,比如(hello, 4)。
方案实现原理:将原本相同的key通过附加随机前缀的方式,变成多个不同的key,就可以让原本被一个task处理的数据分散到多个task上去做局部聚合,进而解决单个task处理数据量过多的问题。接着去除掉随机前缀,再次进行全局聚合,就可以得到最终的结果。具体原理见下图。
方案优点:对于聚合类的shuffle操作导致的数据倾斜,效果是非常不错的。通常都可以解决掉数据倾斜,或者至少是大幅度缓解数据倾斜,将Spark作业的性能提升数倍以上。
方案缺点:仅仅适用于聚合类的shuffle操作,适用范围相对较窄。如果是join类的shuffle操作,还得用其他的解决方案。
画图讲解

解决方案五:将reduce join转为map join
方案适用场景:在对RDD使用join类操作,或者是在Spark SQL中使用join语句时,而且join操作中的一个RDD或表的数据量比较小(比如几百M或者一两G),比较适用此方案。
方案实现思路:不使用join算子进行连接操作,而使用Broadcast变量与map类算子实现join操作,进而完全规避掉shuffle类的操作,彻底避免数据倾斜的发生和出现。将较小RDD中的数据直接通过collect算子拉取到Driver端的内存中来,然后对其创建一个Broadcast变量;接着对另外一个RDD执行map类算子,在算子函数内,从Broadcast变量中获取较小RDD的全量数据,与当前RDD的每一条数据按照连接key进行比对,如果连接key相同的话,那么就将两个RDD的数据用你需要的方式连接起来。
方案实现原理:普通的join是会走shuffle过程的,而一旦shuffle,就相当于会将相同key的数据拉取到一个shuffle read task中再进行join,此时就是reduce join。但是如果一个RDD是比较小的,则可以采用广播小RDD全量数据+map算子来实现与join同样的效果,也就是map join,此时就不会发生shuffle操作,也就不会发生数据倾斜。具体原理如下图所示。
方案优点:对join操作导致的数据倾斜,效果非常好,因为根本就不会发生shuffle,也就根本不会发生数据倾斜。
方案缺点:适用场景较少,因为这个方案只适用于一个大表和一个小表的情况。毕竟我们需要将小表进行广播,此时会比较消耗内存资源,driver和每个Executor内存中都会驻留一份小RDD的全量数据。如果我们广播出去的RDD数据比较大,比如10G以上,那么就可能发生内存溢出了。因此并不适合两个都是大表的情况。
解决方案六:采样倾斜key并分拆join操作
方案适用场景:两个RDD/Hive表进行join的时候,如果数据量都比较大,无法采用“解决方案五”,那么此时可以看一下两个RDD/Hive表中的key分布情况。如果出现数据倾斜,是因为其中某一个RDD/Hive表中的少数几个key的数据量过大,而另一个RDD/Hive表中的所有key都分布比较均匀,那么采用这个解决方案是比较合适的。
方案实现思路:
对包含少数几个数据量过大的key的那个RDD,通过sample算子采样出一份样本来,然后统计一下每个key的数量,计算出来数据量最大的是哪几个key。
然后将这几个key对应的数据从原来的RDD中拆分出来,形成一个单独的RDD,并给每个key都打上n以内的随机数作为前缀,而不会导致倾斜的大部分key形成另外一个RDD。
接着将需要join的另一个RDD,也过滤出来那几个倾斜key对应的数据并形成一个单独的RDD,将每条数据膨胀成n条数据,这n条数据都按顺序附加一个0~n的前缀,不会导致倾斜的大部分key也形成另外一个RDD。
再将附加了随机前缀的独立RDD与另一个膨胀n倍的独立RDD进行join,此时就可以将原先相同的key打散成n份,分散到多个task中去进行join了。
而另外两个普通的RDD就照常join即可。
最后将两次join的结果使用union算子合并起来即可,就是最终的join结果。
方案实现原理:对于join导致的数据倾斜,如果只是某几个key导致了倾斜,可以将少数几个key分拆成独立RDD,并附加随机前缀打散成n份去进行join,此时这几个key对应的数据就不会集中在少数几个task上,而是分散到多个task进行join了。具体原理见下图。
方案优点:对于join导致的数据倾斜,如果只是某几个key导致了倾斜,采用该方式可以用最有效的方式打散key进行join。而且只需要针对少数倾斜key对应的数据进行扩容n倍,不需要对全量数据进行扩容。避免了占用过多内存。
方案缺点:如果导致倾斜的key特别多的话,比如成千上万个key都导致数据倾斜,那么这种方式也不适合。
画图讲解
解决方案七:
方案适用场景:如果在进行join操作时,RDD中有大量的key导致数据倾斜,那么进行分拆key也没什么意义,此时就只能使用最后一种方案来解决问题了。
方案实现思路: 该方案的实现思路基本和“解决方案六”类似,首先查看RDD/Hive表中的数据分布情况,找到那个造成数据倾斜的RDD/Hive表,比如有多个key都对应了超过1万条数据。
然后将该RDD的每条数据都打上一个n以内的随机前缀。 同时对另外一个正常的RDD进行扩容,将每条数据都扩容成n条数据,扩容出来的每条数据都依次打上一个0~n的前缀。 最后将两个处理后的RDD进行join即可。
方案实现原理:将原先一样的key通过附加随机前缀变成不一样的key,然后就可以将这些处理后的“不同key”分散到多个task中去处理,而不是让一个task处理大量的相同key。该方案与“解决方案六”的不同之处就在于,上一种方案是尽量只对少数倾斜key对应的数据进行特殊处理,由于处理过程需要扩容RDD,因此上一种方案扩容RDD后对内存的占用并不大;而这一种方案是针对有大量倾斜key的情况,没法将部分key拆分出来进行单独处理,因此只能对整个RDD进行数据扩容,对内存资源要求很高。
方案优点:对join类型的数据倾斜基本都可以处理,而且效果也相对比较显著,性能提升效果非常不错。
方案缺点:该方案更多的是缓解数据倾斜,而不是彻底避免数据倾斜。而且需要对整个RDD进行扩容,对内存资源要求很高。




补充:
1、企业中hadoop用的最多的是CDH版本,现在我们用的是Apache版本 (CDH\apache版本都是免费)
CDH有
cdh3.x 对应hadoop hadoop1
cdh4.x(HDFS HA+Fderation/CM管理hadoop集群/Cloudera Manager) 对应hadoop hadoop0.20.2
cdh5.x (HDFS/YARN) 对应hadoop hadoop 2.0.0
(HA两种实现:共享文件的方式,QJM)
2、一年工作经验面试问题
cdh 5.1.3(2014年底--2015年) 用的hadoop 版本2.3.0 spark (没有用)
cdh5.3.0(2015年年底-2016) hadoop2.5.0 spark 1.3.0(spark1.5.0或者spark1.6.0)
3、spark application :
(1)Driver:Main sparkcontext(初始化程序入口这是最重要的一件事)
(2)excutor:JVM (进程) 运行我们的task任务
4、Java 中堆内存分为:
永久区
新生区
养老区
5、发生shuffle的算子:
1) 重分区 reparation reparationAndSortWhithInpartition coalesce等
2) Bykey类的算子:reduceBykey groupBykey sortBykey等
3) Join类:join cogroup等
spark(二)的更多相关文章
- PC结束 Spark 二次开发 收到自己主动,并允许好友请求
本次Spark二次开发是为了客服模块的开发, 能让用户一旦点击该客服则直接自己主动加入好友.而客服放则需自己主动加入好友,不同弹出对话框进行允许,这方便的广大客服. 如今废话不多说,直接上代码. pa ...
- openfire spark 二次 开发 服务插件
==================== 废话 begin ============================ 最近老大让我为研发平台增加即时通讯功能.告诉我用comet 在web端实现即 ...
- Spark 二项逻辑回归__二分类
package Spark_MLlib import org.apache.spark.ml.Pipeline import org.apache.spark.ml.classification.{B ...
- Spark(二): 内存管理
Spark 作为一个以擅长内存计算为优势的计算引擎,内存管理方案是其非常重要的模块: Spark的内存可以大体归为两类:execution和storage,前者包括shuffles.joins.sor ...
- 配置spark历史服务(spark二)
1. 编辑spark-defaults.conf位置文件 添加spark.eventLog.enabled和spark.eventLog.dir的配置修改spark.eventLog.dir为我们之前 ...
- Spark(二十一)【SparkSQL读取Kudu,写入Kafka】
目录 SparkSQL读取Kudu,写出到Kafka 1. pom.xml 依赖 2.将KafkaProducer利用lazy val的方式进行包装, 创建KafkaSink 3.利用广播变量,将Ka ...
- Spark(二十)【SparkSQL将CSV导入Kudu】
目录 SparkSql 将CSV导入kudu pom 依赖 scala 代码 启动脚本 SparkSql 将CSV导入kudu pom 依赖 <properties> <spark. ...
- spark二次排序
数据: 2012,01,01,52012,01,02,452012,01,03,352012,01,04,102012,02,04,102012,02,03,182012,02,01,222012,0 ...
- Spark(二)【sc.textfile的分区策略源码分析】
sparkcontext.textFile()返回的是HadoopRDD! 关于HadoopRDD的官方介绍,使用的是旧版的hadoop api ctrl+F12搜索 HadoopRDD的getPar ...
随机推荐
- maven 手动安装jar包
1.问题 maven有时候在pom文件引入jar包会报错,所以可以通过手动导入jar包的方式导入. 2.解决: 通过maven命令导入jar包, mvn install:install-file -D ...
- 如何解决Django与Vue语法的冲突
当我们在django web框架中,使用vue的时候,会遇到语法冲突.因为vue使用{{}},而django也使用{{}},因此会冲突. 解决办法1:在django1.5以后,加入了标签:{% ver ...
- CSP201604-2:俄罗斯方块
引言:CSP(http://www.cspro.org/lead/application/ccf/login.jsp)是由中国计算机学会(CCF)发起的"计算机职业资格认证"考试, ...
- 高可用Kubernetes集群-10. 部署kube-proxy
十二.部署kube-proxy 1. 创建kube-proxy证书 1)创建kube-proxy证书签名请求 # kube-proxy提取CN作为客户端的用户名,即system:kube-proxy. ...
- BZOJ 1901 Zju2112 Dynamic Rankings 树状数组套线段树
题意概述:带修改求区间第k大. 分析: 我们知道不带修改的时候直接上主席树就可以了对吧?两个版本号里面的节点一起走在线段树上二分,复杂度是O((N+M)logN). 然而这里可以修改,主席树显然是凉了 ...
- Scrum立会报告+燃尽图(06)选题
此作业要求参见:[https://edu.cnblogs.com/campus/nenu/2018fall/homework/2195] 一.小组介绍 组长:王一可 组员:范靖旋,王硕,赵佳璐,范洪达 ...
- 进阶系列(9)——linq
一.揭开linq的神秘面纱(一)概述 LINQ的全称是Language Integrated Query,中文译成“语言集成查询”.LINQ作为一种查询技术,首先要解决数据源的封装,大致使用了三大组 ...
- 软工实践-Alpha 冲刺 (8/10)
队名:起床一起肝活队 组长博客:博客链接 作业博客:班级博客本次作业的链接 组员情况 组员1(队长):白晨曦 过去两天完成了哪些任务 描述: 已经解决登录注册等基本功能的界面. 完成非功能的主界面制作 ...
- XCode 6.4 Alcatraz 安装的插件不可用
升级Xcode 6.4后插件都不可用了,解决办法: 1.在 Alcatraz中删除插件并退出Xcode: 2.重新打开Xcode 并安装: 3.退出Xcode: 4.进入Xcode,会提示如图,点击 ...
- Codeforces Beta Round #8 C. Looking for Order 状压dp
题目链接: http://codeforces.com/problemset/problem/8/C C. Looking for Order time limit per test:4 second ...