在Titanic数据集上应用AdaBoost元算法
一.AdaBoost 元算法的基本原理
AdaBoost是adaptive boosting的缩写,就是自适应boosting。元算法是对于其他算法进行组合的一种方式。
而boosting是在从原始数据集选择S次后得到S个新数据集的一种技术。新数据集和原数据集的大小相等。每个数据集都是通过在原始数据集中随机选择一个样本来进行替换而得到的。这里的替换就意味着可以多次地选择同一样本。这一性质就允许新数据集中可以有重复的值,而原始数据集的某些值在新集合中则不再出现。
在S个数据集建好之后,将某个学习算法分别作用于每个数据集就得到了S个分类器。新的分类器是通过集中关注被已有分类器错分的那些数据来获得的。
当我们要对新数据进行分类时,就可以应用这S个分类器进行分类。其中分类器的权重并不相等,每个权重代表的是其对应分类器在上一轮迭代中的成功度。最后,选择分类器投票结果中最多的类别作为最后的分类结果。
二.算法运行过程:
训练数据中的每个样本,并赋予其一个权重,这些权重构成了向量D。一开始,这些权重都初始化成相等值。首先在训练数据上训练出一个弱分类器并计算该分类器的错误率,然后在同一数据集上再次训练弱分类器。在分类器的第二次训练当中,将会重新调整每个样本的权重,其中第一次分对的样本的权重将会降低,而第一次分错的样本的权重将会升高。为了从所有弱分类器中得到最终的分类结果,AdaBoost为每个分类器都分配了一个权重值alpha,这些alpha值是基于每个弱分类器的错误率进行计算的。其中,错误率机器学习之AdaBoost元算法的定义为:

而alpha的计算公式如下:

计算出alpha值之后,可以对权重向量D进行更新,以使得那些正确分类的样本的权重降低而错分样本的权重升高。D的计算方法如下:
如果某个样本被正确分类,那么该样本的权重更改为:
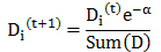
而如果某个样本被错分,那么该样本的权重更改为:
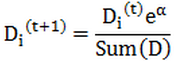
在计算出D之后,AdaBoost又开始进入下一轮迭代。AdaBoost算法会不断地重复训练和调整权重的过程,直到训练错误率为0或者弱分类器的数目达到用户的指定值为止。
三.程序实例:Titanic数据集
1.数据处理:
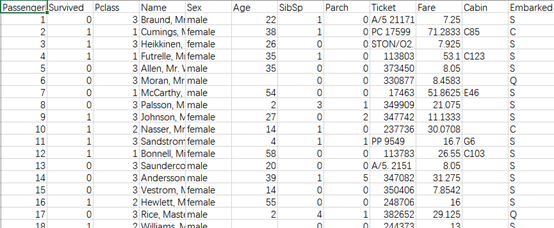
原始数据集
①删除相关性小的数据:Name、SibSp、Ticket、Parch、Embarked
②删除大量数据缺失的Cabin
③用age的平均值来补充缺失数据(train:29.7,test:30.3)
④Fare中的0数值可以看做代表船上的工作人员,他们分布在船的各个部位,因此用中值来替代0(train与test都是14.45)
⑤用0代表female,1代表male
⑥合并test与gender_submission
⑦选定特征值为:Pclass、Sex、Age、Ticket
⑧将整理数据到TXT文件中
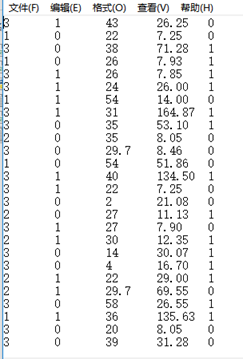
从左到右分别是:Pclass、Sex、Age、Ticket、Survived
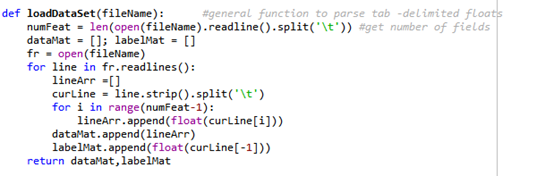
2导入数据
在这个函数里不必指定每个文件中的特征数目,该函数能自动检测出特征的数目。最后一个特征是类别标签。
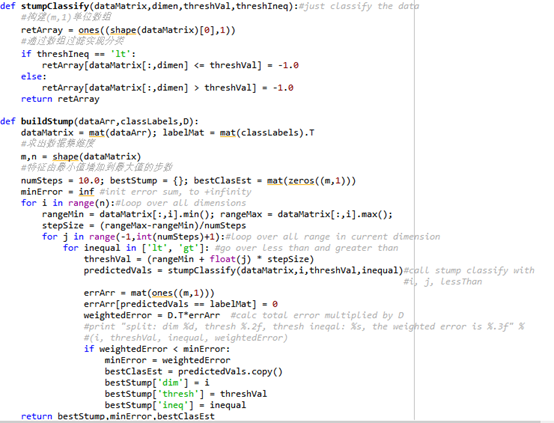
3.完整算法实现
初始化权重向量D,所有权重初始值相等且权重之和等于1.0
迭代用户指定的次数,对每一次迭代:
找到最佳的单层决策树
根据错误率计算本次单层决策树输出结果的权重alpha值并保存
将最佳单层决策树加入到单层决策树数组中
计算新的权重向量D
更新累计类别估计值(类别估计值=alpha*当前单层决策树的预测分类结果)
如果错误率等于0,则退出循环,否则继续迭代直到指定的次数

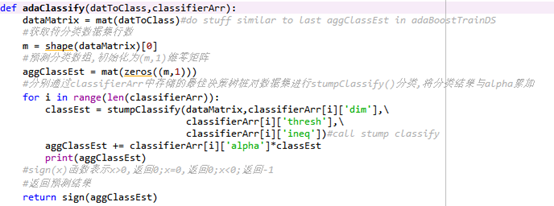
4.测试算法
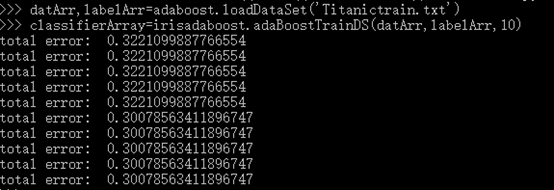
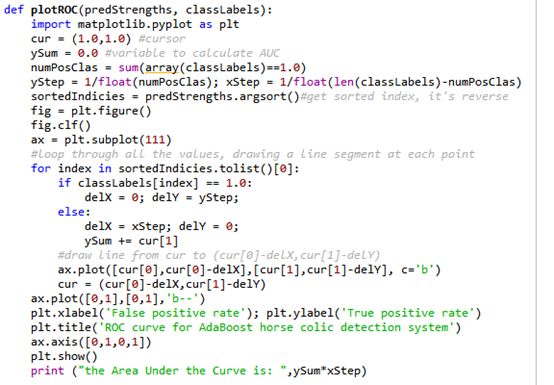
5绘制ROC曲线
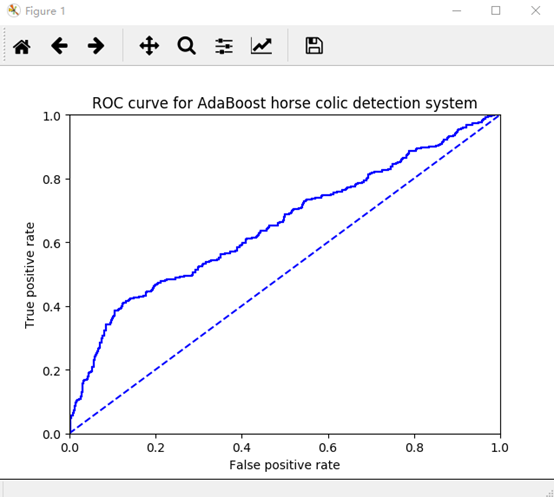
图中有两条线,一条虚线和一条实线。图中的横轴是伪正例的比例(假阳率=FP/(FP+TN)),而纵轴是真正例的比例(真阳率=TP/(TP+FN))。ROC曲线给出的是当阈值变化时假阳率和真阳率的变化情况。左下角的点所对应的是将所有样例判为反例的情况,而右上角的点所对应的则是将所有样例判为正例的情况。虚线给出的是随机猜测的结果曲线。
在理想的情况下,最佳的分类器应该尽可能地处于左上角,这就意味着分类器在假阳率很低的同时获得了很高的真阳率。
四.小结
与逻辑回归相比,AdaBoost 分类器没有过度拟合现象。泛化错误率低,易编码,可以应用在大部分分类器上,无参数调整。 但对离群点敏感。 适用于数值型和标称型数据。
AdaBoost的强大在于把众多个这样的弱分类器组合起来一起发挥功效,最终合成一个强分类器。
在Titanic数据集上应用AdaBoost元算法的更多相关文章
- 使用 AdaBoost 元算法提高分类器性能
前言 有人认为 AdaBoost 是最好的监督学习的方式. 某种程度上因为它是元算法,也就是说它会是几种分类器的组合.这就好比对于一个问题能够咨询多个 "专家" 的意见了. 组合的 ...
- 机器学习技法-AdaBoost元算法
课程地址:https://class.coursera.org/ntumltwo-002/lecture 重要!重要!重要~ 一.Adaptive Boosting 的动机 通过组合多个弱分类器(hy ...
- 第九篇:使用 AdaBoost 元算法提高分类器性能
前言 有人认为 AdaBoost 是最好的监督学习的方式. 某种程度上因为它是元算法,也就是说它会是几种分类器的组合.这就好比对于一个问题能够咨询多个 "专家" 的意见了. 组合的 ...
- 机器学习算法( 七、AdaBoost元算法)
一.概述 当做重要决定时,大家可能都会考虑吸取多个专家而不只是一个人的意见.机器学习处理问题时又何尝不是如此?这就是元算法(meta-algorithm)背后的思路.元算法是对其他算法进行组合的一种方 ...
- 机器学习实战 - 读书笔记(07) - 利用AdaBoost元算法提高分类性能
前言 最近在看Peter Harrington写的"机器学习实战",这是我的学习笔记,这次是第7章 - 利用AdaBoost元算法提高分类性能. 核心思想 在使用某个特定的算法是, ...
- 《机器学习实战第7章:利用AdaBoost元算法提高分类性能》
import numpy as np import matplotlib.pyplot as plt def loadSimpData(): dataMat = np.matrix([[1., 2.1 ...
- 【转载】 机器学习实战 - 读书笔记(07) - 利用AdaBoost元算法提高分类性能
原文地址: https://www.cnblogs.com/steven-yang/p/5686473.html ------------------------------------------- ...
- 机器学习——AdaBoost元算法
当做重要决定时,我们可能会考虑吸取多个专家而不只是一个人的意见.机器学习处理问题也是这样,这就是元算法(meta-algorithm)背后的思路. 元算法是对其他算法进行组合的一种方式,其中最流行的一 ...
- 利用AdaBoost元算法提高分类性能
当做重要决定时,大家可能都会吸取多个专家而不只是一个人的意见.机器学习处理问题时又何尝不是如此?这就是元算法背后的思路.元算法是对其他算法进行组合的一种方式. 自举汇聚法(bootstrap aggr ...
随机推荐
- 沉淀再出发:spring boot的理解
沉淀再出发:spring boot的理解 一.前言 关于spring boot,我们肯定听过了很多遍了,其实最本质的东西就是COC(convention over configuration),将各种 ...
- [EffectiveC++]item17:以独立语句将newed对象置入智能指针
Store newed objects in smart pointers in standalone statements
- Ubuntu 12.04中MyEclipse 10.6+下载+安装+破解
至于MyEclipse在Ubuntu的安装教程网上很多,那我为什么我还写这篇文章呢?这次重装Ubuntu之后, 在安装MyEclipse 10.6过程中遇到了一个问题,所以把MyEclipse的安装方 ...
- PHP版本解密openrtb中的价格
Decrypt Price Confirmations 原文地址 https://developers.google.com/ad-exchange/rtb/response-guide/decryp ...
- Bean Definition从加载、解析、处理、注册到BeanFactory的过程。
为了弄清楚Bean是怎么来的,花费了大把功夫,现在要把Bean Definition的加载.解析.处理.注册到bean工厂的过程记下来.这只是bean definition 的加载.解析.处理.注册过 ...
- ubuntu服务器下tomcat安装(不推荐使用apt-get)
最近在阿里云服务器上装tomcat,一开始为了省事直接使用了apt-get安装,结果整个程序被拆开散到了好多地方,尤其是像网上说要把打包好了.war文件放到webapps文件夹下,但是开始并没有在/u ...
- 「CF741DArpa’s letter-marked tree and Mehrdad’s Dokhtar-kosh paths」
题目 这题目名字怎么这么长 zky学长讲过的题 非常显然,就是重排之后能形成回文串的话,最多只能有一个字母出现奇数次 又发现这个字符集大小只有\(22\),于是套路的使用状压,把每一条边转化成一个二进 ...
- WEB安全 php+mysql5注入防御(一)
注入利用函数: concat()函数将多个字符串连接成一个字符串 database() 当前数据库,用途:获取数据 version() 数据库版本,用途:利用版本特性,如5.0版本下的informat ...
- Linux内存管理学习笔记——内存寻址
最近开始想稍微深入一点地学习Linux内核,主要参考内容是<深入理解Linux内核>和<深入理解Linux内核架构>以及源码,经验有限,只能分析出有限的内容,看完这遍以后再更深 ...
- WebRTC博客推荐
1. http://www.cnblogs.com/lingyunhu/ 2. http://www.jianshu.com/u/eadc7531ecb8