EurekaServer集群配置
一、程序配置
1、pom添加依赖:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-server</artifactId>
</dependency>
(这里因为在pom中通过dependencyManagement配置将spring-cloud-dependencies import进来,所以不需要写版本号)
或者在是使用Spring Initializr创建SpringBoot项目时,添加上起步依赖Eureka Server (路径:Cloud Discovery -- Eureka Server)。
完整pom为:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion> <groupId>com.example</groupId>
<artifactId>microservice-discovery-eureka-ha</artifactId>
<version>0.0.1-SNAPSHOT</version>
<packaging>jar</packaging> <name>microservice-discovery-eureka-ha</name>
<description>Demo project for Spring Boot</description> <parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.1.1.RELEASE</version>
<relativePath/> <!-- lookup parent from repository -->
</parent> <properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<java.version>1.8</java.version>
<spring-cloud.version>Greenwich.M3</spring-cloud.version>
</properties> <dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-server</artifactId>
</dependency> <dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies> <dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>${spring-cloud.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement> <build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build> <repositories>
<repository>
<id>spring-milestones</id>
<name>Spring Milestones</name>
<url>https://repo.spring.io/milestone</url>
<snapshots>
<enabled>false</enabled>
</snapshots>
</repository>
</repositories> </project>
2、在SpringBoot启动类上添加注释@EnableEurekaServer
3、配置application.yml或application.properties
spring:
application:
name: microservice-discovery-eureka-ha ---
spring:
profiles: peer1
server:
port: 8761
eureka:
instance:
hostname: peer1
client:
service-url:
defaultZone: http://peer2:8762/eureka/
register-with-eureka: false #作为对比,这里表示不将peer1注册到Eureka Server集群中,peer2中默认为true
fetch-registry: false #作为对比,这里表示peer1不会从Eureka Server集群获取注册表信息
---
spring:
profiles: peer2
server:
port: 8762
eureka:
instance:
hostname: peer2
client:
service-url:
defaultZone: http://peer1:8761/eureka/
例子程序的github地址是:https://github.com/zjianliu/Eureka-Server
二、程序运行
将程序打包后,执行jar包:
java -jar xxx.jar --spring.profiles.active=peer1
java -ajr xxx.jar --spring.profiles.active=peer2
通过spring.profiles.active指定使用application.yml中配置的哪一个profile启动程序。
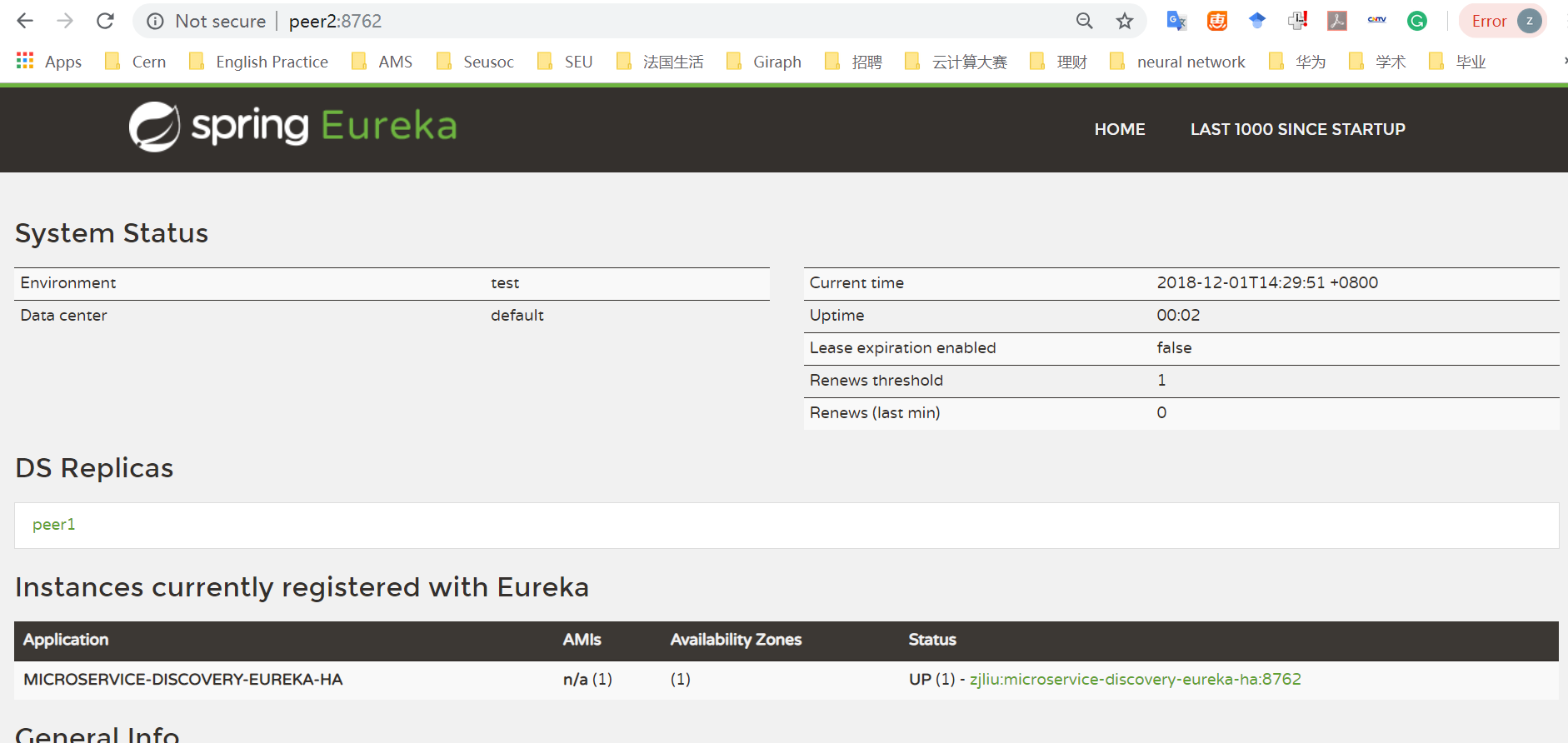
三、程序截图
我们可以看到,peer2将自身注册到Eureka Server集群中了,而peer1没有。
Eureka Server配置启动好之后,我们就可以写微服务,并通过配置将其注册到Eureka Server集群中了

EurekaServer集群配置的更多相关文章
- SpringCloud学习笔记(四):Eureka服务注册与发现、构建步骤、集群配置、Eureka与Zookeeper的比较
简介 Netflix在设计Eureka时遵守的就是AP原则 拓展: 在分布式数据库中的CAP原理 CAP原则又称CAP定理,指的是在一个分布式系统中,Consistency(一致性). Availab ...
- 【一起学源码-微服务】Nexflix Eureka 源码十二:EurekaServer集群模式源码分析
前言 前情回顾 上一讲看了Eureka 注册中心的自我保护机制,以及里面提到的bug问题. 哈哈 转眼间都2020年了,这个系列的文章从12.17 一直写到现在,也是不容易哈,每天持续不断学习,输出博 ...
- Ubuntu 14.04中Elasticsearch集群配置
Ubuntu 14.04中Elasticsearch集群配置 前言:本文可用于elasticsearch集群搭建参考.细分为elasticsearch.yml配置和系统配置 达到的目的:各台机器配置成 ...
- Redis 3.0 Cluster集群配置
Redis 3.0 Cluster集群配置 安装环境依赖 安装gcc:yum install gcc 安装zlib:yum install zib 安装ruby:yum install ruby 安装 ...
- MongoDB高可用集群配置的方案
>>高可用集群的解决方案 高可用性即HA(High Availability)指的是通过尽量缩短因日常维护操作(计划)和突发的系统崩溃(非计划)所导致的停机时间,以提高系统和应用的可用性. ...
- MySQL Cluster 7.3.5 集群配置实例(入门篇)
一.环境说明: CentOS6.3(32位) + MySQL Cluster 7.3.5,规划5台机器,资料如下: 节点分布情况: MGM:192.168.137. NDBD1:192.168.137 ...
- MySQL Cluster 7.3.5 集群配置参数优化(优化篇)
按照前面的教程:MySQL Cluster 7.3.5 集群配置实例(入门篇),可快速搭建起基础版的MySQL Cluster集群,但是在生成环境中,还是有很多问题的,即配置参数需要优化下, 当前生产 ...
- 关于ActiveMQ的几种集群配置
ActiveMQ的几种集群配置. Queue consumer clusters 此集群让多个消费者同时消费一个队列,若某个消费者出问题无法消费信息,则未消费掉的消息将被发给其他正常的消费者,结构图如 ...
- solrCloud+tomcat+zookeeper集群配置
solrcolud安装solrCloud+tomcat+zookeeper部署 转载请出自出处:http://eksliang.iteye.com/blog/2107002 http://eksli ...
随机推荐
- Objective-C 构造方法 分类 类的深入研究
构造方法 1.对象创建的原理 new的拆分两部曲 Person *p = [Person alloc]; 分配内存(+alloc) Person *p = [p init]; 初始化(-init) 合 ...
- 服务器返回中文乱码的情况(UTF8编码 -> 转化为 SYSTEM_LOCALE 编码)
服务器乱码 转换使用如下方法 入惨{“msg”} -> utf8编码 -> 转化为 SYSTEM_LOCALE 编码 -> 接受转换后的参数 "sEncoding" ...
- [Clr via C#读书笔记]Cp4类型基础
Cp4类型基础 Object类型 Object是所有类型的基类,有Equals,GetHashCode,ToString,GetType四个公共方法,其中GetHashCode,ToString可以o ...
- html常用小知识
请求重定向:加载页面之后,除了用js做重定向之外,我们还可以直接用<meta>标签做重定向. <meta http-equiv="refresh" content ...
- 最全的Markdown语法
目录 Markdown语法 多级标题 引用与注释 插入代码 行内代码 代码段 图片 超链接 行内超链接 参数式超链接 字体 表格 分割线 多级列表 无序列表 有序列表 多选框 LaTeX公式 行内La ...
- Python实现个性化推荐二
基于内容的推荐引擎是怎么工作的 基于内容的推荐系统,正如你的朋友和同事预期的那样,会考虑商品的实际属性,比如商品描述,商品名,价格等等.如果你以前从没接触过推荐系统,然后现在有人拿枪指着你的头,强迫你 ...
- 业务迁移---web
#本文是做记录使用,不做为任何参考文档# 迁移代码 将源代码scp至新的server上 搭建服务 yum安装nginx服务 yum install nginx #yum安装 service nginx ...
- CodeForces - 792C Divide by Three (DP做法)
C. Divide by Three time limit per test: 1 second memory limit per test: 256 megabytes input: standar ...
- android BadgeView的使用(图片上的文字提醒)
BadgeView主要是继承了TextView,所以实际上就是一个TextView,底层放了一个label,可以自定义背景图,自定义背景颜色,是否显示,显示进入的动画效果以及显示的位置等等: 这是Gi ...
- TCP系列18—重传—8、FACK及SACK reneging下的重传
一.介绍 FACK的全称是forward acknowledgement,FACK通过记录SACK块中系列号最大(forward-most)的SACK块来推测丢包信息,在linux中使用fackets ...