【转载】【翻译】Breaking things is easy///机器学习中安全与隐私问题(对抗性攻击)
我是通过Infaraway的那篇博文才发现cleverhans-blog的博客的,这是一个很有意思的议题 ,特此转载到自己的博客保存学习,稍有修改!
一、背景
直到几年前,机器学习算法在许多有意义的任务上都没有很好地发挥作用,比如识别物体或翻译。因此,当机器学习算法没能做正确的事情时,这是规则,而不是例外。今天,机器学习算法已经进入了下一个发展阶段:当呈现自然产生的输入时,它们可以比人类表现得更好。机器学习还没有达到真正的人类水平,因为当面对一个微不足道的对手时,大多数机器学习算法都失败了。换句话说,我们已经达到了机器学习的目的,但很容易被打破。
这篇博客文章介绍了我们新的Clever Hans博客,我们将讨论攻击者破坏机器学习算法的各种方法。从学术角度讲,我们的话题是机器学习的安全性和保密性。这个博客是由Lan Goodfellow和 Nicolas Papernot共同撰写的。Lan是OpenAI的一名研究科学家,也是宾夕法尼亚州立大学安全研究的博士生。我们共同创建了开源库——cleverhans,用来对机器学习模型的脆弱性进行基准测试。这个博客为我们提供了一种非正式的分享关于机器学习安全和隐私的想法——对于传统的学术出版来说还不够具体,还可以分享与cleverhans 库相关的新闻和更新。
二、机器学习安全与隐私
一个安全的系统是可以依赖的,并且可以保证像预期的一样运行。当我们试图为系统的行为提供保证时,我们会想到一个特定的威胁模型。威胁模型是正式定义的一组关于任何攻击者的能力和目标的假设,这些攻击者可能希望系统的行为发生错误。
到目前为止,大多数机器学习都是用一个非常弱的威胁模型来开发的,在这个模型中并没有对手。机器学习系统的设计只是为了在面对自然时表现出正确的行为。而今天,我们开始设计机器学习系统,即使面对一个恶意的人或一个恶意的机器学习对手,我们也能做出正确的行为。例如,机器学习系统可能在模型训练(学习阶段)或模型预测(推理阶段)时被对手攻击。对手也有不同程度的能力,可能包括对模型内部结构和参数的访问,或者对模型输入和输出的访问。
为了破坏机器学习模型,攻击者可以破坏其机密性、完整性或可用性。这些性质构成了CIA(confidentiality, integrity, or availability)的安全模型。
- 保密性:机器学习系统必须保证未得到授权的用户无法接触到信息。在实际操作中,把保密性作为隐私性来考虑会容易得多,就是说模型不可以泄露敏感数据。比如,假设研究员们设计了一个可以检查病人病历、给病人做诊断的机器学习模型,这样的模型可以对医生的工作起到很大的帮助,但是必须要保证有恶意的人没办法分析这个模型,也没办法把用来训练模型的病人的数据恢复出来。
- 完整性:如果攻击者可以破坏模型的完整性,那么模型的预测结果就可能会偏离预期。比如,垃圾邮件会把自己伪装成正常邮件的样子,造成垃圾邮件识别器的误识别。
- 可用性:系统的可用性也可以成为攻击目标。比如,如果攻击者把一个非常难以识别的东西放在车辆会经过的路边,就有可能迫使一辆自动驾驶汽车进入安全保护模式,然后停车在路边。
三、机器学习攻击方法
当然,到目前为止,所有这些都是假设的。
到目前为止,安全研究人员已经证明了哪些类型的攻击?——本博客的后续文章将会给出更多的例子,但是我们从三个方面开始:在训练时的完整性攻击,在推理过程中的完整性攻击,以及隐私攻击。
3.1 在训练集中下毒 - 在训练时对模型进行完整性攻击
攻击者可以通过修改现有训练数据、或者给训练集增加额外数据的方法来对训练过程的完整性造成影响。比如,假设莫里亚蒂教授要给福尔摩斯栽赃一个罪名,他就可以让一个没被怀疑的同伙送给福尔摩斯一双独特、华丽的靴子。当福尔摩斯穿着这双靴子在他经常协助破案的警察面前出现过以后,这些警察就会把这双靴子和他联系起来。接下来莫里亚蒂教授就可以穿一双同样的靴子去犯罪,留下的脚印会让福尔摩斯成为被怀疑的对象。
干扰机器学习模型的训练过程,体现的攻击策略是当用于生产时让机器学习模型出现更多错误预测。具体来说,这样的方法可以在支持向量机(SVM)的训练集中下毒。由于算法中预测误差是以损失函数的凸点衡量的,这就让攻击者有机会找到对推理表现影响最大的一组点进行攻击[BNL12]。即便在更复杂的模型中也有可能找到高效的攻击点,深度神经网络就是这样,只要它们会用到凸优化。
3.2 用对抗性的样本让模型出错 - 在推理时进行完整性攻击
实际上,让模型出错是非常简单的一件事情,以至于攻击者都没必要花功夫在机器学习模型的训练参数中下毒。他们只要在推理阶段(模型训练完成之后)的输入上动动手脚,就可以立即让模型得出错误的结果。
要找到能让模型做出错误预测的干扰信息,有一种常用方法是计算对抗性样本 [SZS13].。它们带有的干扰通常很微小,人类很难发现,但它们却能成功地让模型产生错误的预测。比如下面这张图 [GSS14],用机器学习模型识别最左侧的图像,可以正确识别出来这是一只熊猫。但是对这张图像增加了中间所示的噪声之后得到的右侧图像,就会被模型识别成一只长臂猿(而且置信度还非常高)。

值得注意的是,虽然人类无法用肉眼分辨,但是图像中施加的干扰已经足以改变模型的预测结果。确实,这种干扰是在输入领域中通过计算最小的特定模得到的,同时它还能增大模型的预测误差。它可以有效地把本来可以正确分类的图像移过模型判定区域的边界,从而成为另一种分类(错误的)。下面这张图就是对于能分出两个类别的分类器,出现这种现象时的示意。
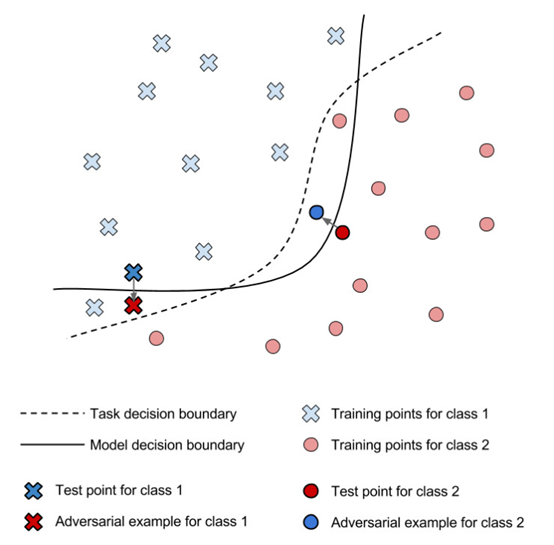
许多基于对抗性样本的攻击需要攻击者知道机器学习模型中的参数,才能把所需的干扰看作一个优化问题计算出来 。另一方面,也有一些后续研究考虑了更现实的威胁模型,这种模型里攻击者只能跟模型互动,给模型提供输入以后观察它的输出。举例来讲,这种状况可以发生在攻击者想要设计出能骗过机器学习评分系统从而得到高排名的网站页面,或者设计出能骗过垃圾邮件筛选器的垃圾邮件的时候。在这些黑盒情境中,机器学习模型的工作方式可以说像神谕一样。发起攻击的策略首先对神谕发起询问,对模型的判定区域边界做出一个估计。这样的估计就成为了一个替代模型,然后利用这个替代模型来制作会被真正的模型分类错误的对抗性样本 [PMG16]。这样的攻击也展现出了对抗性样本的可迁移性:用来解决同样的机器学习任务的不同的模型,即便模型与模型之间的架构或者训练数据不一样,对抗性样本还是会被不同的模型同时误判[SZS13]。
3.3 机器学习中的隐私问题
机器学习中的隐私问题就不需要攻击者也能讲明白了。例如说,机器学习算法缺乏公平性和透明性的问题已经引起领域内越来越多人的担心。事实上,已经有人指出,训练数据中带有的社会偏见会导致最终训练完成后的预测模型也带有这些偏见。下面重点说一说在有攻击者情况下的隐私问题。
攻击者的目的通常是恢复一部分训练机器学习模型所用的数据,或者通过观察模型的预测来推断用户的某些敏感信息。举例来说,智能手机的虚拟键盘就可以通过学习用户的输入习惯,达到更好的预测-自动完成效果。但是,某一个用户的输入习惯下的特定字符序列不应该也出现在别的手机屏幕上,除非已经有一个比例足够大的用户群也会打同样的一串字符。在这样的情况下,隐私攻击会主要在推理阶段发挥作用,不过要缓解这个问题的话,一般都需要在学习算法中增加一些随机性[CMS11]。
比如,攻击者有可能会想办法进行成员推测查询:想要知道模型训练中有没有使用某个特定的训练点。近期就有一篇论文在深度神经网络场景下详细讨论了这个问题。与制作对抗性样本时对梯度的用法相反[SSS16](这可以改变模型对正确答案的置信度),成员推测攻击会沿着梯度方向寻找分类置信度非常高的点。已经部署的模型中也还可以获得有关训练数据的更多总体统计信息[AMS15]。
四、总结
现在是2016年12月。目前,我们知道许多攻击机器学习模式的方法,而且很少有防御的方法。我们希望到2017年12月,我们将有更有效的防御措施。这个博客的目标是推动机器学习安全和隐私的研究状态,通过记录他们所发生的进展,在涉及到这些话题的研究人员的社区内引发讨论,并鼓励新一代的研究人员加入这个社区。
References
[AMS15] Ateniese, G., Mancini, L. V., Spognardi, A., Villani, A., Vitali, D., & Felici, G. (2015). Hacking smart machines with smarter ones: How to extract meaningful data from machine learning classifiers. International Journal of Security and Networks, 10(3), 137-150.
(用智能机器入侵智能机器:如何从机器学习分类器中提取有意义的数据。)
[BS16] Barocas, S., & Selbst, A. D. (2016). Big data’s disparate impact. California Law Review, 104.
(大数据的不同影响)
[BNL12] Biggio, B., Nelson, B., & Laskov, P. (2012). Poisoning attacks against support vector machines. arXiv preprint arXiv:1206.6389.
(针对支持向量机中毒攻击)
[CMS11] Chaudhuri, K., Monteleoni, C., & Sarwate, A. D. (2011). Differentially private empirical risk minimization. Journal of Machine Learning Research, 12(Mar), 1069-1109.
(差异的私人经验风险最小化)(感觉翻译不对,读过再修改)
[GSS03] Garfinkel, S., Spafford, G., & Schwartz, A. (2003). Practical UNIX and Internet security. O’Reilly Media, Inc.
(实用unix与网络安全)
[GSS14] Goodfellow, I. J., Shlens, J., & Szegedy, C. (2014). Explaining and harnessing adversarial examples. arXiv preprint arXiv:1412.6572.
(解释和利用敌对的例子)
[PMG16] Papernot, N., McDaniel, P., Goodfellow, I., Jha, S., Berkay Celik, Z., & Swami, A. (2016). Practical Black-Box Attacks against Deep Learning Systems using Adversarial Examples. arXiv preprint arXiv:1602.02697.
(实用的黑盒攻击深度学习系统采用对抗性的例子)
[PMS16] Papernot, N., McDaniel, P., Sinha, A., & Wellman, M. (2016). Towards the Science of Security and Privacy in Machine Learning. arXiv preprint arXiv:1611.03814.
(在机器学习中对安全和隐私的科学)
[SSS16] Shokri, R., Stronati, M., & Shmatikov, V. (2016). Membership Inference Attacks against Machine Learning Models. arXiv preprint arXiv:1610.05820.
(基于机器学习模型的成员推断攻击)
[SZS13] Szegedy, C., Zaremba, W., Sutskever, I., Bruna, J., Erhan, D., Goodfellow, I., & Fergus, R. (2013). Intriguing properties of neural networks. arXiv preprint arXiv:1312.6199.
(神经网络的有趣性质)
【转载】【翻译】Breaking things is easy///机器学习中安全与隐私问题(对抗性攻击)的更多相关文章
- paper 126:[转载] 机器学习中的范数规则化之(一)L0、L1与L2范数
机器学习中的范数规则化之(一)L0.L1与L2范数 zouxy09@qq.com http://blog.csdn.net/zouxy09 今天我们聊聊机器学习中出现的非常频繁的问题:过拟合与规则化. ...
- 机器学习中的范数规则化-L0,L1和L2范式(转载)
机器学习中的范数规则化之(一)L0.L1与L2范数 zouxy09@qq.com http://blog.csdn.net/zouxy09 今天我们聊聊机器学习中出现的非常频繁的问题:过拟合与规则化. ...
- 机器学习中的数学(1)-回归(regression)、梯度下降(gradient descent)
版权声明: 本文由LeftNotEasy所有,发布于http://leftnoteasy.cnblogs.com.如果转载,请注明出处,在未经作者同意下将本文用于商业用途,将追究其法律责任. 前言: ...
- ML 07、机器学习中的距离度量
机器学习算法 原理.实现与实践 —— 距离的度量 声明:本篇文章内容大部分转载于July于CSDN的文章:从K近邻算法.距离度量谈到KD树.SIFT+BBF算法,对内容格式与公式进行了重新整理.同时, ...
- 机器学习中的算法-决策树模型组合之随机森林与GBDT
机器学习中的算法(1)-决策树模型组合之随机森林与GBDT 版权声明: 本文由LeftNotEasy发布于http://leftnoteasy.cnblogs.com, 本文可以被全部的转载或者部分使 ...
- 机器学习中应用到的各种距离介绍(附上Matlab代码)
转载于博客:各种距离 在做分类时常常需要估算不同样本之间的相似性度量(SimilarityMeasurement),这时通常采用的方法就是计算样本间的"距离"(Distance). ...
- 偏差(Bias)和方差(Variance)——机器学习中的模型选择zz
模型性能的度量 在监督学习中,已知样本 ,要求拟合出一个模型(函数),其预测值与样本实际值的误差最小. 考虑到样本数据其实是采样,并不是真实值本身,假设真实模型(函数)是,则采样值,其中代表噪音,其均 ...
- 机器学习中的算法(2)-支持向量机(SVM)基础
版权声明:本文由LeftNotEasy发布于http://leftnoteasy.cnblogs.com, 本文可以被全部的转载或者部分使用,但请注明出处,如果有问题,请联系wheeleast@gma ...
- 机器学习中的规则化范数(L0, L1, L2, 核范数)
目录: 一.L0,L1范数 二.L2范数 三.核范数 今天我们聊聊机器学习中出现的非常频繁的问题:过拟合与规则化.我们先简单的来理解下常用的L0.L1.L2和核范数规则化.最后聊下规则化项参数的选择问 ...
随机推荐
- Java开发小技巧(五):HttpClient工具类
前言 大多数Java应用程序都会通过HTTP协议来调用接口访问各种网络资源,JDK也提供了相应的HTTP工具包,但是使用起来不够方便灵活,所以我们可以利用Apache的HttpClient来封装一个具 ...
- 使用bison和yacc制作脚本语言(2)
我们先来想一下语法 一般脚本语言不需要定义类型直接在赋值的时候确定 我们主要考虑一下变量的类型 a = 1; b = 1.1; c = "str"; 一般来讲,我们使用这三种类型, ...
- 函数调用方法之__cdecl与_stdcall
在debug VS c工程文件时,碰到cannot convert from 'int (__cdecl *)(char *)' to 'xxx'这个问题,发现问题在于typedef函数指针类型时,将 ...
- jenkins里面使用shell 获取jira的sprint信息
需求 项目需要在jenkins自动发布中加入version.html来跟踪项目发布的版本信息,需要获取到jira中当前sprint的名字,和一个sprint中的发布次数(我这里用文件把次数存起来的傻方 ...
- DevExpress通过girdcontrol实现分页
简介:DevExpress中如何实现GridControl的分页功能, 主要是利用DataNavigator和GridControl组合,自定义事件实现分页功能 接下来,我们就去实现分页功能,先看下效 ...
- 12 垃圾回收GC
1.垃圾回收 1.) 小整数对象池 #提前建立好的 Python 对小整数的定义是 [-5, 257) 这些整数对象是提前建立好的,不会被垃圾回收.在一个 Python 的程序中,所有位于这个范 ...
- CakePHP2.x 发送邮件
cake提供了多种发送邮件的方法,并且简单实用.以2.x为例 第一步 创建并添加邮件配置信息 拷贝app\Config\email.php.default 为email.php 打开在EmailCon ...
- 关于DataTable.Select方法偶尔无法正确查到数据的处理方法
项目中经常用DataTable在内存中存储并操作数据,在进行报表开发的时候,报表的各种过滤功能用这个内存表可以大现身手,但最近在使用过程中却遇到一个奇怪的现象,现将该问题及处理方法记录一下.这是在做护 ...
- 「日常训练」Equation(HDU-5937)
题意与分析 时隔一个月之后来补题.说写掉的肯定会写掉. 题意是这样的:给1~9这些数字,每个数字有\(X_i\)个,问总共能凑成多少个不同的等式\(A+B=C\)(\(A,B,C\)均为1位,\(1+ ...
- 应用UserDefaults储存游戏分数和最高分
应用UserDefaults储存游戏分数和最高分 我们在GameScene.swift里 private var currentScore:SKLabelNode! // 当前分数节点 private ...