正排索引(forward index)与倒排索引(inverted index)
正常的索引一般是指关系型数据库里的索引。 把不同的数据存放到不同的字段中。如果要实现baidu或google那种搜索,就需要与一条记录的多个字段进行比对,需要 全表扫描,如果数据量比较大的话,性能就很低。
那反过来,如果把mysql中存放在不同字段中字符串,按一定规则拆分成term【词】存放到 一个字段中【套用mysql中的表结构,实际上不是这样处理的】,然后把这些词存放到一个字段中,并在这个字段建立索引。
这样一来,搜索时,只需要查 带有索引的这列就可以了【这一点和关系型数据库 field_name='xxx'一样了】,这一步解决了效率问题
这个term对应所在记录,中这个term所在的原始记录,这一步解决了获取源内容的问题
正排索引(forward index)与倒排索引(inverted index)
正排索引(前向索引) 正排索引也称为"前向索引"。
正向索引的结构如下:
“文档1”的ID > 单词1:出现次数,出现位置列表;单词2:出现次数,出现位置列表;…………。
“文档2”的ID > 此文档出现的关键词列表。

一般是通过key,去找value。
当用户在主页上搜索关键词“华为手机”时,假设只存在正向索引(forward index),那么就需要扫描索引库中的所有文档,找出所有包含关键词“华为手机”的文档,再根据打分模型进行打分,排出名次后呈现给用户。因为互联网上收录在搜索引擎中的文档的数目是个天文数字,这样的索引结构根本无法满足实时返回排名结果的要求。
所以,搜索引擎会将正向索引重新构建为倒排索引,即把文件ID对应到关键词的映射转换为关键词到文件ID的映射,每个关键词都对应着一系列的文件,这些文件中都出现这个关键词。
得到倒排索引的结构如下:
“关键词1”:“文档1”的ID,“文档2”的ID,…………。
“关键词2”:带有此关键词的文档ID列表。

从词的关键字,去找文档。
官网
- https://www.elastic.co/guide/en/elasticsearch/reference/5.x/analysis.html

官网,提供了很多很多。大家自行去看!
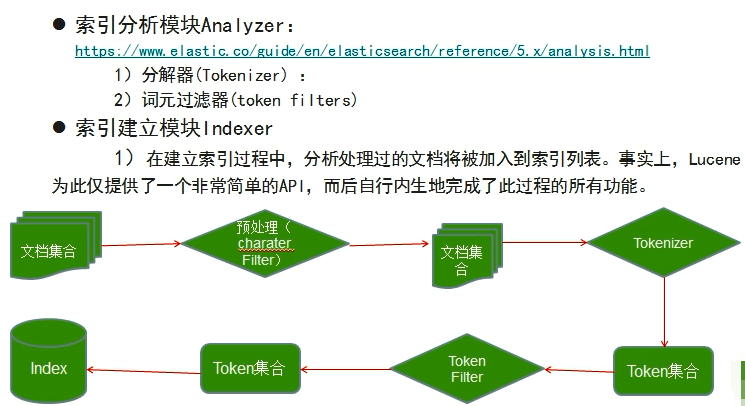
索引分析模块Analyzer
分解器Tokenizer
词元过滤器token filters

经过 Tokenizer

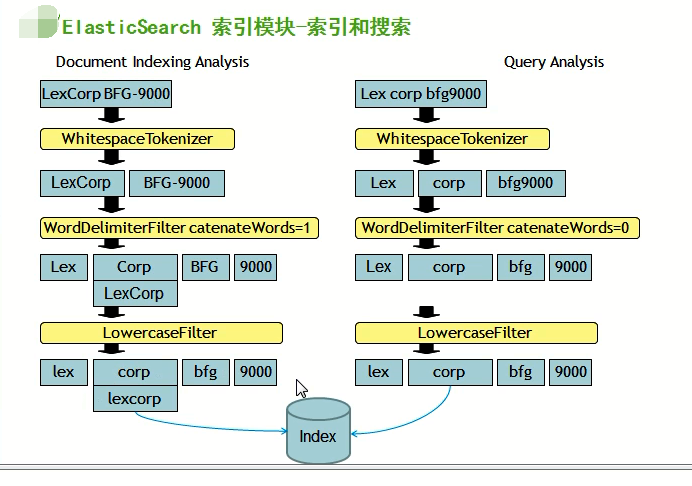

Elasticsearch之IKAnalyzer的过滤停止词
大家,有兴趣,可以看看,英文停用词
- http://www.ranks.nl/stopwords
大家,有兴趣,可以看看,中文停用词

Elasticsearch之中文分词器

Elasticsearch之几个重要的分词器
作者:大数据和人工智能躺过的坑
出处:http://www.cnblogs.com/zlslch/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文链接,否则保留追究法律责任的权利。 如果您认为这篇文章还不错或者有所收获,您可以通过右边的“打赏”功能 打赏我一杯咖啡【物质支持】,也可以点击右下角的【好文要顶】按钮【精神支持】,因为这两种支持都是我继续写作,分享的最大动力!
正排索引(forward index)与倒排索引(inverted index)的更多相关文章
- 正排索引(forward index)与倒排索引(inverted index) (转)
一.正排索引(前向索引) 正排索引也称为"前向索引".它是创建倒排索引的基础,具有以下字段. (1)LocalId字段(表中简称"Lid"):表示一个文档的局部 ...
- 后端程序员之路 35、Index搜索引擎实现分析4-最终的正排索引与倒排索引
# index_box 提供搜索功能的实现- 持有std::vector<ITEM> _buffer; 存储所有文章信息- 持有ForwardIndex _forward_index; ...
- es倒排索引和正排索引
搜索的时候,要依靠倒排索引:排序的时候,需要依靠正排索引,看到每个document的每个field,然后进行排序,所谓的正排索引,其实就是doc values.在建立索引的时候,一方面会建立倒排索引, ...
- Elasticsearch由浅入深(十)搜索引擎:相关度评分 TF&IDF算法、doc value正排索引、解密query、fetch phrase原理、Bouncing Results问题、基于scoll技术滚动搜索大量数据
相关度评分 TF&IDF算法 Elasticsearch的相关度评分(relevance score)算法采用的是term frequency/inverse document frequen ...
- 16 doc values 【正排索引】
搜索的时候,要依靠倒排索引:排序的时候,需要依靠正排索引,看到每个document的每个field,然后进行排序,所谓的正排索引,其实就是doc values 在建立索引的时候,一方面会建立倒排索引, ...
- 52.基于doc value正排索引的聚合内部原理
主要知识点: 本节没有太懂,以后复习时补上 聚合分析的内部原理是什么????aggs,term,metric avg max,执行一个聚合操作的时候,内部原理是怎样的呢?用了什么样的数据结 ...
- Elasticsearch的索引模块(正排索引、倒排索引、索引分析模块Analyzer、索引和搜索、停用词、中文分词器)
正向索引的结构如下: “文档1”的ID > 单词1:出现次数,出现位置列表:单词2:出现次数,出现位置列表:…………. “文档2”的ID > 此文档出现的关键词列表. 一般是通过key,去 ...
- ElasticSearch(二十一)正排和倒排索引
1.区别 搜索的时候,要依靠倒排索引:排序的时候,需要依靠正排索引,看到每个document的每个field,然后进行排序,所谓的正排索引,其实就是doc values 在建立索引的时候,一方面会建立 ...
- ES系列七、ES-倒排索引详解
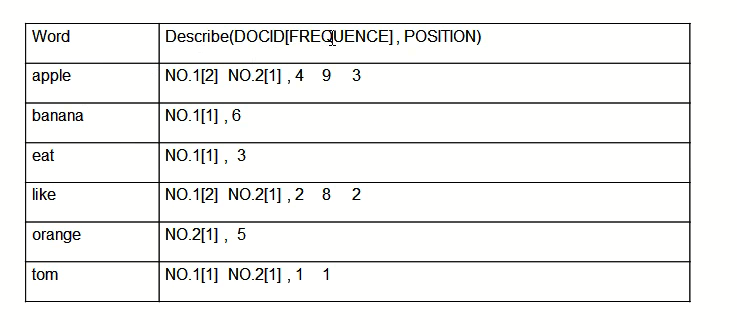
1.单词——文档矩阵 单词-文档矩阵是表达两者之间所具有的一种包含关系的概念模型,图3-1展示了其含义.图3-1的每列代表一个文档,每行代表一个单词,打对勾的位置代表包含关系. 图3-1 单词-文档矩 ...
随机推荐
- Log4net日志
log4net简介(摘抄于百度百科): log4net库是Apache log4j框架在Microsoft .NET平台的实现,是一个帮助程序员将日志信息输出到各种目标(控制台.文件.数据库 ...
- Qt自动填写表单并点击按钮,包括调用js方法
本篇博客参阅了很多其他大牛的文章,具体找不到了,还望包涵>_< 因为其他博客大都是只有主要代码,对于像我这种菜鸟,根本摸不着头脑,以此想总结一下,帮助新手尽快实现功能... 主要是调用了C ...
- IdentityServer4与ocelot实现认证与客户端统一入口
关于IdentityServer4与ocelot博客园里已经有很多介绍我这里就不再重复了. ocelot与IdentityServer4组合认证博客园里也有很多,但大多使用ocelot内置的认证,而且 ...
- MicroPython (一)点亮我的Led
工具 : putty F429Discovery 开发板 Notepad++ 注意:不知道为什么 其他的终端工具有问题,推荐 putty 基本没有发现问题 putty 实时调试 使用putty 打开U ...
- 二十、Node.js- WEB 服务器 (三)静态文件托管、 路 由
1.Nodejs 静态文件托管 上一讲的静态 web 服务器封装 项目结构: Web服务器封装成的模块:router.js代码: var http=require('http'); var fs=re ...
- python 图像识别
这是一个最简单的图像识别,将图片加载后直接利用Python的一个识别引擎进行识别 将图片中的数字通过 pytesseract.image_to_string(image)识别后将结果存入到本地的txt ...
- numpy 数组运算
数组的减法:不同维数
- 线程概要 Java
线程 进程和线程的区别 串行:初期的计算机只能串行执行任务,大量时间等待用户输入 批处理:预先将用户的指令集中成清单,批量串行处理用户指令,仍然无法并发执行 进程:进程独占内存空间,保存各自运行状态, ...
- Ubuntu定时任务设置
设置很简单,但如果误入歧途,会耽误很多时间 步骤如下: 1. 以root执行:vi /etc/crontab 2. 在文件最后添加cron配置(每天凌晨四点执行,并将日志输出到/data/cron.l ...
- django Form数据读取问题
1.在我学习django的过程中,我学习到了一个关于表单验证的问题 2.我们从前端post一个表单,通过urls配置,传给对应的view方法 3.然后再传给Form验证 4.一开始我是很好奇,在vie ...