二 Hive分桶
二.Hive分桶
1.创建分桶表
create table t_buck (id string ,name string)
clustered by (id) //根据id分桶
sorted by (id) //根据id排序
into 4 buckets //分为4个桶
row format delimited
fields terminated by ',';
向创建的分桶表中插入数据需要是已分桶且排序的。通常是将其他表查询的结果插入桶中才会执行分桶操作。分桶的原理和分区原理差不多,类似HashPartitioner。
2.向分桶表中导入其他表查询后的数据
select id ,name from t_shizhan01 distribute by (id) sort by (id);
或者
insert into t_buck
select id ,name from t_shizhan01 cluster by (id);
可以使用distribute by(id) sort by(id asc) 或是排序和分桶的字段相同的时候使用Cluster by(字段)
注意使用cluster by 就等同于分桶+排序(sort)
3.设置变量,设置分桶为true, 设置reduce数量是分桶的数量个数
set hive.enforce.bucketing = true;
set mapreduce.job.reduces=4;
设置是否分桶及设置reduce的数量。在创建表的时候设置的分桶数量要和此处设置的相匹配,如果此处不设置reduce数量和是否分桶,表对应的空间中只会有一个桶。
执行插入操作后hdfs目录如下:
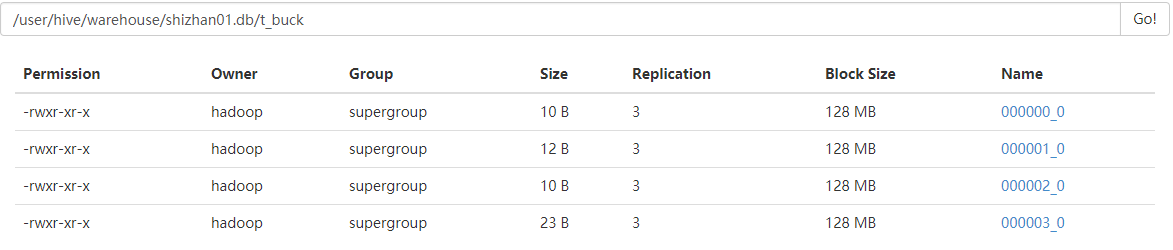
二 Hive分桶的更多相关文章
- Hive分桶
1.简介 分桶表是对列值取哈希值的方式将不同数据放到不同文件中进行存储.对于hive中每一个表,分区都可以进一步进行分桶.由列的哈希值除以桶的个数来决定数据划分到哪个桶里. 2.适用场景 1.数据抽样 ...
- hive分桶 与保存数据的方式
创建分桶的表 create table t_buck(id int ,name string) clustered by (id ) sorted by (id) into 4 buckets ; ...
- hive分桶表bucketed table分桶字段选择与个数确定
为什么分桶 (1)获得更高的查询处理效率.桶为表加上了额外的结构,Hive 在处理有些查询时能利用这个结构.具体而言,连接两个在(包含连接列的)相同列上划分了桶的表,可以使用 Map 端连接 (Map ...
- hive 分桶及抽样调查
1.分桶的概述 分区提供了一个隔离数据和优化查询的遍历方式.不是所有的数据集都可形成合力的分区 对于一张表或者分区,hive可以进一步组织成桶,也就是更为细粒度的数据范围 分区针对的是数据的存储路径( ...
- Hive 学习之路(五)—— Hive 分区表和分桶表
一.分区表 1.1 概念 Hive中的表对应为HDFS上的指定目录,在查询数据时候,默认会对全表进行扫描,这样时间和性能的消耗都非常大. 分区为HDFS上表目录的子目录,数据按照分区存储在子目录中.如 ...
- Hive 系列(五)—— Hive 分区表和分桶表
一.分区表 1.1 概念 Hive 中的表对应为 HDFS 上的指定目录,在查询数据时候,默认会对全表进行扫描,这样时间和性能的消耗都非常大. 分区为 HDFS 上表目录的子目录,数据按照分区存储在子 ...
- 入门大数据---Hive分区表和分桶表
一.分区表 1.1 概念 Hive 中的表对应为 HDFS 上的指定目录,在查询数据时候,默认会对全表进行扫描,这样时间和性能的消耗都非常大. 分区为 HDFS 上表目录的子目录,数据按照分区存储在子 ...
- Hive分区表与分桶
分区表 在Hive Select查询中.通常会扫描整个表内容,会消耗非常多时间做不是必需的工作. 分区表指的是在创建表时,指定partition的分区空间. 分区语法 create table tab ...
- Hive动态分区和分桶(八)
Hive动态分区和分桶 1.Hive动态分区 1.hive的动态分区介绍 hive的静态分区需要用户在插入数据的时候必须手动指定hive的分区字段值,但是这样的话会导致用户的操作复杂度提高,而且在 ...
随机推荐
- SQL rownum的用法
rownum只显示两行记录,第一行是字段名,第二行是满足查询条件的记录.
- Redis启动问题解决方案
linux下redis overcommit_memory的问题 我在启动Redis的时候出现如下警告信息. 警告信息:WARNING overcommit_memory is set to 0! B ...
- Selenium图片上传
方式1: 如果是input类型的标签则可直接赋值 部分代码: driver.find_element_by_name("file").send_keys("E:\\tes ...
- fullCalendar日程管理
//日程安排 function timeTable(id){ var inner = "<div id='calendar'></div>"; $(&quo ...
- 图片左右滚动控件(带倒影)——重写Gallery
转http://blog.csdn.net/ryantang03/article/details/8053643 今天在网上找了些资料,做了一个图片左右滚动的Demo,类似幻灯片播放,同时,图片带倒影 ...
- Go 语言开始
尝试了LiteIDE碰到调试问题无法解决,只有换成了vscode. vscode有个问题, golang.org/x/ 这个包名下的包都下载不了,需要到 https://github.com/gola ...
- C++重载操作符operator
operator是C++关键字,用于对C++进行扩展: 1.可以被重载的操作符:new,new[],delete,delete[],+,-,*,/,%,^,&,|,~,!,=,<,> ...
- Swift_ScrollView _ API详解
Swift_ScrollView _ API详解 GitHub class ViewController: UIViewController,UIScrollViewDelegate { var sc ...
- python 面向对象之添加功能
'''**#实现功能**案列 姓名:王飞 年龄:30 性别:男 工龄:5我承诺,我会认真教课.王飞爱玩象棋 姓名:小明 年龄:15 性别:男 学号:00023102我承诺,我会 好好学习.小明爱玩足球 ...
- (Nagios)-check_hpasm[HP]
Nagios Check_hp HP 2014年11月18日 下午 08:49 https://IP:2381 [root@nagios ~]# tar zxvf check_hp_blad ...