MapReduce程序——WordCount(Windows_Eclipse + Ubuntu14.04_Hadoop2.9.0)
本文主要参考《Hadoop应用开发技术详解(作者:刘刚)》
一、工作环境
Windows7: Eclipse + JDK1.8.0
Ubuntu14.04:Hadoop2.9.0
二、准备工作——导入JAR包
1. 建一个Hadoop专用的工作空间
2. 在工作空间的目录下建一个专门用来存放开发MapReduce程序所需的Hadoop依赖的JAR包的文件夹
所需的JAR包在Ubuntu中$HADOOP_HOME/share/hadoop下,将JAR包复制到刚刚建好的文件夹中

需要的JAR包如下,可能有部分重复:
$HADOOP_HOME/share/hadoop/common & $HADOOP_HOME/share/hadoop/common/lib


$HADOOP_HOME/share/hadoop/hdfs & $HADOOP_HOME/share/hadoop/hdfs/lib


$HADOOP_HOME/share/hadoop/httpfs/tomcat/lib

$HADOOP_HOME/share/hadoop/kms/tomcat/lib

$HADOOP_HOME/share/hadoop/mapreduce & $HADOOP_HOME/share/hadoop/mapreduce/lib


$HADOOP_HOME/share/hadoop/tools/lib
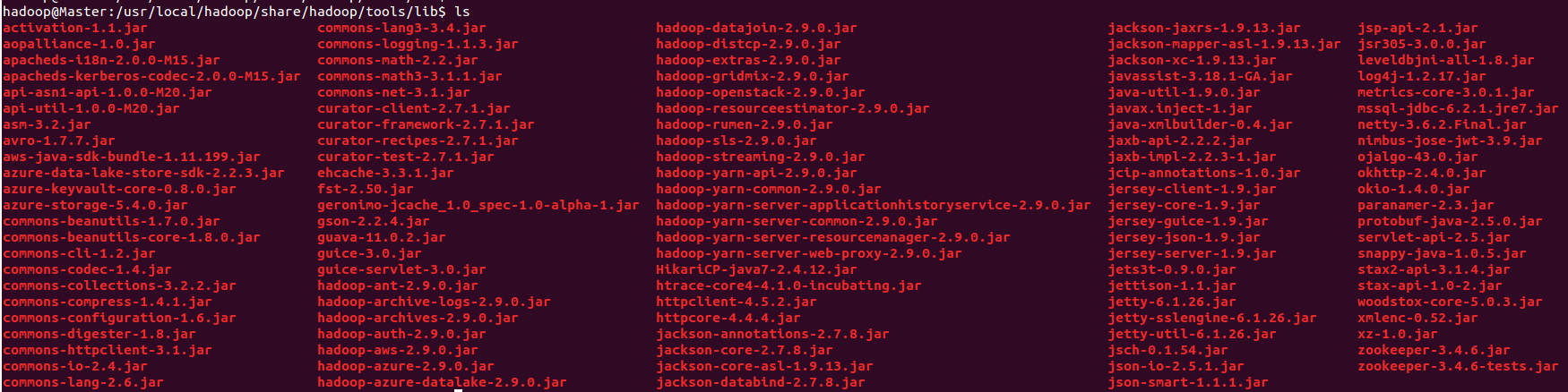
$HADOOP_HOME/share/hadoop/yarn & $HADOOP_HOME/share/hadoop/yarn/lib


3. 新建用户库
Windows → Preference → Java → Build Path → User Libraries → New...
看到如下界面:
点击OK后看到如下界面:
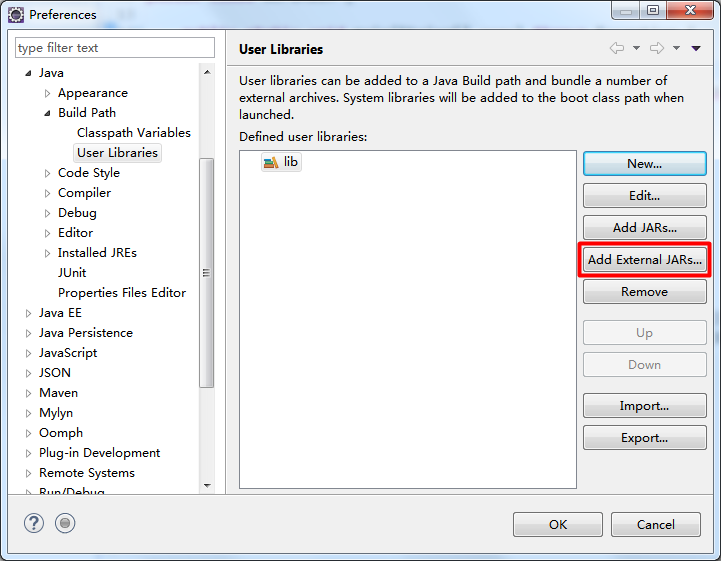
点击Add External JARs... → 在刚刚建好的文件夹中选中所有JAR包 → 打开 → OK
用户库创建成功!
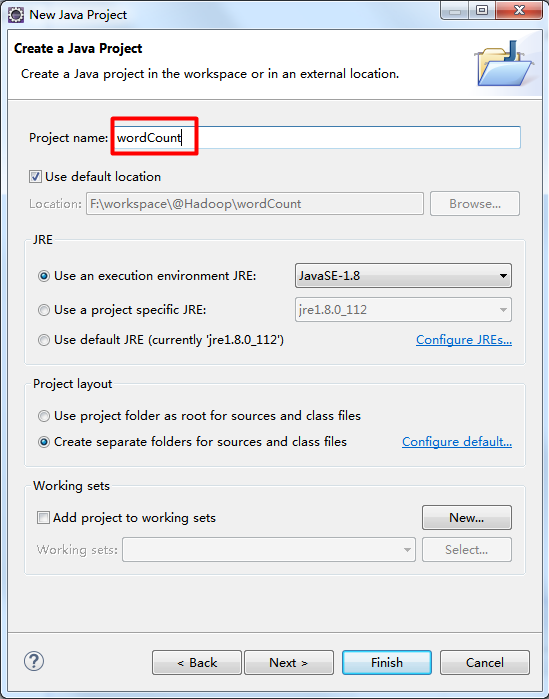
三、创建一个Java工程
File → New → Java Project
除了红框的内容,其他选项默认
右击项目名 → Build Path → Add Libraries... → User Library → 选中建好的用户库
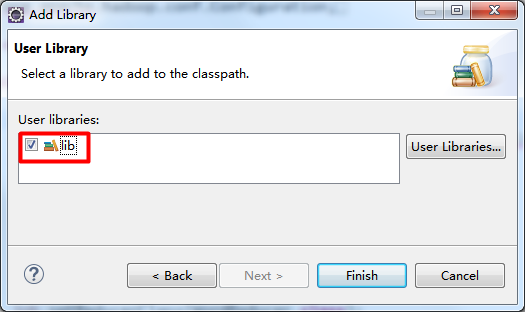
四、MapReduce代码的实现
1. WordMapper类
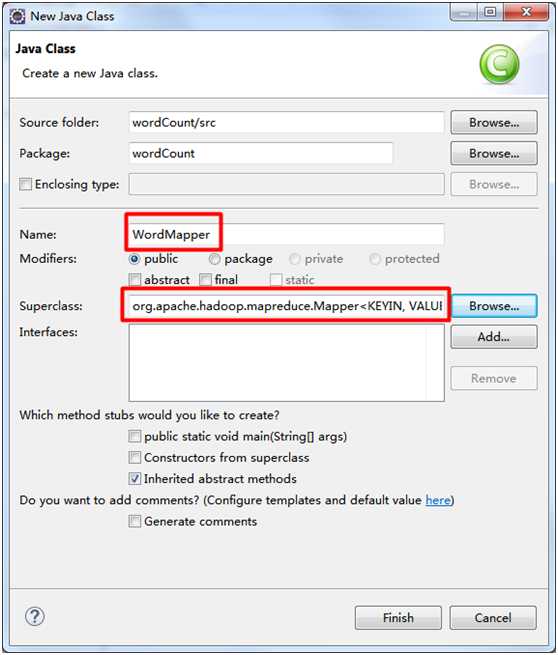
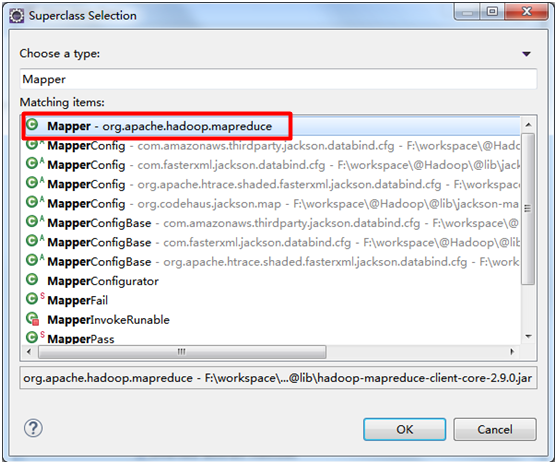
package wordCount; import java.io.IOException;
import java.util.StringTokenizer; import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper; // 继承Mapper接口,设置Map的输入类型为<Object, Text>,输出类型为<Text, IntWritable>
public class WordMapper extends Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1); // one表示单词出现一次
private Text word = new Text(); // word用于存储切下来的词
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString()); // 对输入的行切词
while (itr.hasMoreTokens()) {
word.set(itr.nextToken()); // 切下来的单词存入word
context.write(word, one);
}
}
}
2. WordReducer类
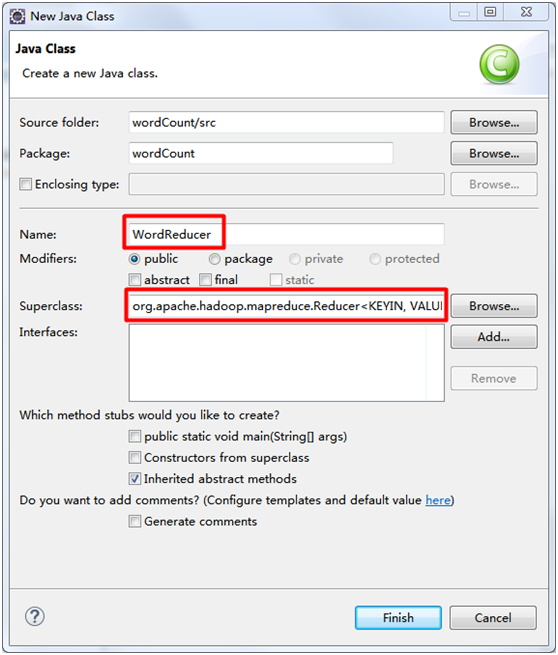
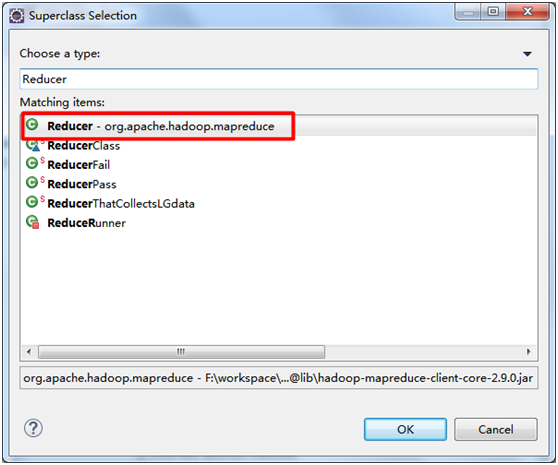
package wordCount; import java.io.IOException; import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer; // 继承Reducer接口,设置Reduce的输入类型为<Text, IntWritable>,输出类型为<Text, IntWritable>
public class WordReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable(); // result记录单词的频数
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
// 对获取的<key, IntWritable>计算value的和
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum); // 将频数设置到result中
context.write(key, result); // 收集结果
}
}
3. WordMain驱动类
package wordCount; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser; public class WordMain { public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
// 检查运行命令
if (otherArgs.length != 2) {
System.err.println("Usage: wordCount <in> <out>");
System.exit(2);
}
// 配置作业名
Job job = new Job(conf, "word count");
// 配置作业的各个类
job.setJarByClass(WordMain.class);
job.setMapperClass(WordMapper.class);
job.setCombinerClass(WordReducer.class);
job.setReducerClass(WordReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
五、打包成JAR文件
右击项目名 → Export → Java → JAR file
看到如下界面:
除了红框的内容,其他选项默认
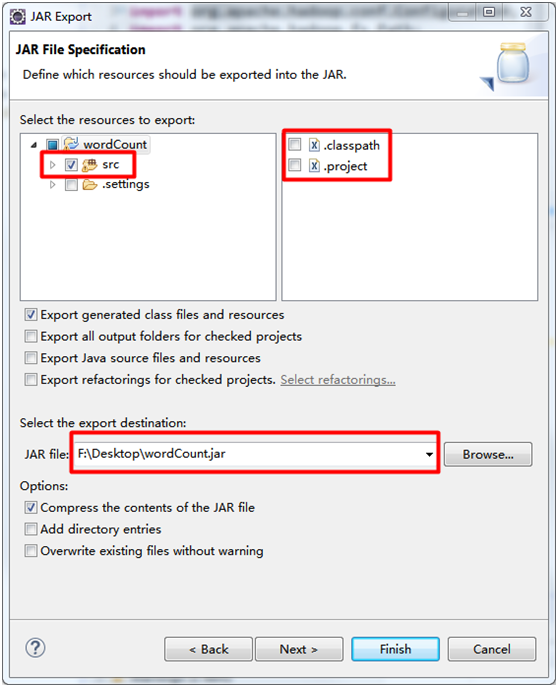
点击Finish
JAR文件生成成功!
六、部署和运行
1. 把刚刚生成的JAR文件发送到Hadoop集群的Master节点的$HADOOP_HOME下面
2. 在Master节点的$HADOOP_HOME下面创建两个待统计词频的文件,file1.txt和file2.txt
file1.txt
Hello, I love coding
Are you OK?
Hello, I love hadoop
Are you OK?
file2.txt
Hello I love coding
Are you OK ?
Hello I love hadoop
Are you OK ?
3. 上传文件到HDFS系统中
$ hdfs dfs -put ./file* input
查看是否上传成功
$ hdfs dfs -ls input
4. 运行程序
$ hdfs dfs -rm -r output #如果HDFS系统中存在output目录
$ hadoop jar wordCount.jar wordCount.WordMain input/file* output
5. 查看运行结果
$ hdfs dfs -cat output/*

以上
MapReduce程序——WordCount(Windows_Eclipse + Ubuntu14.04_Hadoop2.9.0)的更多相关文章
- 编写简单的Mapreduce程序并部署在Hadoop2.2.0上运行
今天主要来说说怎么在Hadoop2.2.0分布式上面运行写好的 Mapreduce 程序. 可以在eclipse写好程序,export或用fatjar打包成jar文件. 先给出这个程序所依赖的Mave ...
- 第一个MapReduce程序——WordCount
通常我们在学习一门语言的时候,写的第一个程序就是Hello World.而在学习Hadoop时,我们要写的第一个程序就是词频统计WordCount程序. 一.MapReduce简介 1.1 MapRe ...
- Hadoop 6、第一个mapreduce程序 WordCount
1.程序代码 Map: import java.io.IOException; import org.apache.hadoop.io.IntWritable; import org.apache.h ...
- MapReduce程序(一)——wordCount
写在前面:WordCount的功能是统计输入文件中每个单词出现的次数.基本解决思路就是将文本内容切分成单词,将其中相同的单词聚集在一起,统计其数量作为该单词的出现次数输出. 1.MapReduce之w ...
- 使用Eclipse编译运行MapReduce程序 Hadoop2.6.0_Ubuntu/CentOS
使用Eclipse编译运行MapReduce程序 Hadoop2.6.0_Ubuntu/CentOS 2014-10-10 (updated: 2016-05-22) 64246 153 本教程介绍 ...
- mapreduce程序编写(WordCount)
折腾了半天.终于编写成功了第一个自己的mapreduce程序,并通过打jar包的方式运行起来了. 运行环境: windows 64bit eclipse 64bit jdk6.0 64bit 一.工程 ...
- 使用命令行编译打包运行自己的MapReduce程序 Hadoop2.6.0
使用命令行编译打包运行自己的MapReduce程序 Hadoop2.6.0 网上的 MapReduce WordCount 教程对于如何编译 WordCount.java 几乎是一笔带过… 而有写到的 ...
- 运行第一个MapReduce程序,WordCount
1.安装Eclipse 安装后如果无法启动重新配置Java路径(如果之前配置了Java) 2.下载安装eclipse的hadoop插件 注意版本对应,放到/uer/lib/eclipse/plugin ...
- Hadoop实战5:MapReduce编程-WordCount统计单词个数-eclipse-java-windows环境
Hadoop研发在java环境的拓展 一 背景 由于一直使用hadoop streaming形式编写mapreduce程序,所以目前的hadoop程序局限于python语言.下面为了拓展java语言研 ...
随机推荐
- html常见兼容性问题
html常见兼容性问题? 1.双边距BUG float引起的 使用display 2.3像素问题 使用float引起的 使用dislpay:inline -3px 3.超链接hover 点击后失效 ...
- flask大全
django:重武器,内部包含了非常多组件:ORM.Form.ModelForm.缓存.Session,中间件,信号等... flask:短小精悍.内部没有太多组件,第三方组件非常丰富 1.初识fla ...
- Java 语言基础之数组(一)
数组定义及格式: 数组: 同一种类型数据的集合, 就是一个容器 定义数组格式1: 元素类型[] 数组名 = new 元素类型[元素个数(即数组长度)]; 说明: 数组是一个容器.而容器属于一个实体,实 ...
- 用java求一个整数各位数字之和
/* * 用java求一个整数各位数字之和 */ public class Test02 { public static void main(String[] args) { System.out.p ...
- Python面向对象中的“私有化”
Python面向对象中的“私有化” Python并不直接支持私有方式,而要靠程序员自己把握在外部进行特性修改的时机. 为了让方法或者特性变为私有(从外部无法访问),只要在它的名字前面加上双下划线即可. ...
- Linux网络调试工具资料链接
Dropbox: https://huoding.com/2016/12/15/574 Tcpdump: http://roclinux.cn/?p=2474
- (2.2)学习笔记之mysql基础操作(登录及账户权限设置)
本系列学习笔记主要讲如下几个方面: 本文笔记[三:mysql登录][四:账户权限设置][五:mysql数据库安全配置] 三.mysql登录 常用登录方式如下: 四.账户权限设置 (4.1)查看用户表, ...
- ngs中reads mapping-pku的生信课程
4.NGS中的reads mapping 顾名思义,就是将测序的得到的DNA定位在基因组上. 因为二代测序的得到的序列是较短的,reads mapping很好地解决了这个问题. 本质上reads ma ...
- 阿里、腾讯、京东、微软,各家算法&数据挖掘岗位面经大起底!
阿里.腾讯.京东.微软,各家算法&数据挖掘岗位面经大起底! 2016-02-24 36大数据 36大数据 作者: 江少华 摘要: 从2015年8月到2015年10月,花了3个月时间找工作,先后 ...
- Xcode 错误问题以及解决方法(后期遇到还会添加)
1,/Applications/Xcode.app/Contents/Developer/Platforms/iPhoneSimulator.platform/Developer/SDKs/iPhon ...