Java集合(8):Hashtable
一.Hashtable介绍
和HashMap一样,Hashtable 也是一个散列表,它存储的内容是键值对(key-value)映射,它在很大程度上和HashMap的实现差不多。
Hashtable 的函数都是同步的,这意味着它是线程安全的。它的key、value都不可以为null。此外,Hashtable中的映射不是有序的。
1.Hashtable的继承关系
- public class Hashtable<K,V>
- extends Dictionary<K,V>
- implements Map<K,V>, Cloneable, java.io.Serializable
2.Hashtable的类图关系
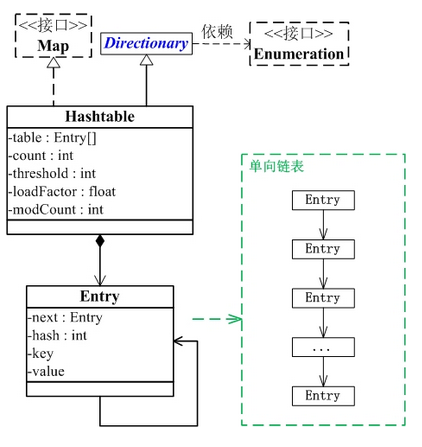
HashTable继承Dictionary类,实现Map接口。其中Dictionary类是任何可将键映射到相应值的类的抽象父类。每个键和每个值都是一个对象。在任何一个 Dictionary 对象中,每个键至多与一个值相关联。Map是”key-value键值对”接口。
二.Hashtable源码解析
1.Hashtable的私有属性
- private transient Entry<?,?>[] table;//table是一个Entry[]数组类型,而Entry实际上就是一个单向链表。
- private transient int count;//count是Hashtable的大小,它是Hashtable保存的键值对的数量。
- private int threshold;//threshold是Hashtable的阈值,用于判断是否需要调整Hashtable的容量。threshold的值="容量*加载因子"。
- private float loadFactor;//loadFactor就是加载因子。
- private transient int modCount = 0;//modCount是用来实现fail-fast机制的
所谓快速失败就是在并发集合中,其进行迭代操作时,若有其他线程对其进行结构性的修改,这时迭代器会立马感知到,并且立即抛出ConcurrentModificationException异常,而不是等到迭代完成之后才告诉你(你已经出错了)。
2.Hashtable的构造方法
- // 默认构造函数。
- public Hashtable() {
- this(11, 0.75f);
- }
- // 指定“容量大小”的构造函数
- public Hashtable(int initialCapacity) {
- this(initialCapacity, 0.75f);
- }
- // 指定“容量大小”和“加载因子”的构造函数
- public Hashtable(int initialCapacity, float loadFactor) {
- if (initialCapacity < 0)//验证初始容量
- throw new IllegalArgumentException("Illegal Capacity: "+ initialCapacity);
- if (loadFactor <= 0 || Float.isNaN(loadFactor))//验证加载因子
- throw new IllegalArgumentException("Illegal Load: "+loadFactor);
- if (initialCapacity==0)
- initialCapacity = 1;
- this.loadFactor = loadFactor;
- table = new Entry[initialCapacity];//初始化table,获得大小为initialCapacity的table数组
- threshold = (int)Math.min(initialCapacity * loadFactor, MAX_ARRAY_SIZE + 1);//计算阀值
- initHashSeedAsNeeded(initialCapacity);//初始化HashSeed值
- }
- // 包含“子Map”的构造函数
- public Hashtable(Map<? extends K, ? extends V> t) {
- this(Math.max(2*t.size(), 11), 0.75f);//设置table容器大小,其值==t.size * 2 + 1
- putAll(t);
- }
3.存储数据put
将指定 key 映射到此哈希表中的指定 value。注意这里键key和值value都不可为空。
- public synchronized V put(K key, V value) {
- if (value == null) {// 确保value不为null
- throw new NullPointerException();
- }
- /*
- * 确保key在table[]是不重复的
- * 处理过程:
- * 1、计算key的hash值,确认在table[]中的索引位置
- * 2、迭代index索引位置,如果该位置处的链表中存在一个一样的key,则替换其value,返回旧值
- */
- Entry tab[] = table;
- int hash = hash(key); //计算key的hash值
- int index = (hash & 0x7FFFFFFF) % tab.length; //确认该key的索引位置
- for (Entry<K,V> e = tab[index] ; e != null ; e = e.next) { //迭代,寻找该key,替换
- if ((e.hash == hash) && e.key.equals(key)) {
- V old = e.value;
- e.value = value;
- return old;
- }
- }
- modCount++;
- if (count >= threshold) { //如果容器中的元素数量已经达到阀值,则进行扩容操作
- rehash();
- tab = table;
- hash = hash(key);
- index = (hash & 0x7FFFFFFF) % tab.length;
- }
- Entry<K,V> e = tab[index];// 在索引位置处插入一个新的节点
- tab[index] = new Entry<>(hash, key, value, e);
- count++;//容器中元素+1
- return null;
- }
put方法的整个处理流程是:计算key的hash值,根据hash值获得key在table数组中的索引位置,然后迭代该key处的Entry链表(我们暂且理解为链表),若该链表中存在一个这个的key对象,那么就直接替换其value值即可,否则在将改key-value节点插入该index索引位置处。
过程演示如下:
首先我们假设一个容量为5的table,存在如下的键值对:
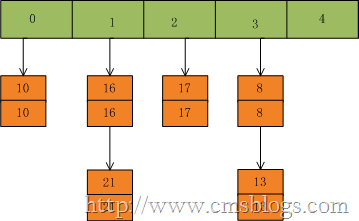
然后我们插入一个数:put(16,22),key=16在table的索引位置为1,同时在1索引位置有两个数,程序对该“链表”进行迭代,发现存在一个key=16,这时要做的工作就是用newValue=22替换oldValue16,并将oldValue=16返回。
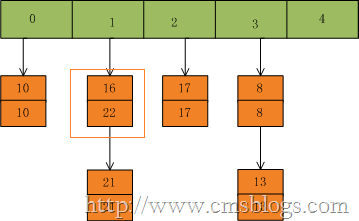
在put(33,33),key=33所在的索引位置为3,并且在该链表中也没有存在某个key=33的节点,所以就将该节点插入该链表的第一个位置。
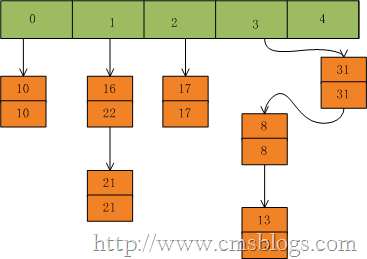
扩容操作:在put方法中,如果需要向table[]中添加Entry元素,会首先进行容量校验,如果容量已经达到了阀值,HashTable就会进行rehash()扩容处理
- protected void rehash() {
- int oldCapacity = table.length;
- Entry<K,V>[] oldMap = table;
- int newCapacity = (oldCapacity << 1) + 1;//新容量=旧容量 * 2 + 1
- if (newCapacity - MAX_ARRAY_SIZE > 0) {
- if (oldCapacity == MAX_ARRAY_SIZE)
- return;
- newCapacity = MAX_ARRAY_SIZE;
- }
- Entry<K,V>[] newMap = new Entry[];//新建一个size = newCapacity 的HashTable
- modCount++;
- threshold = (int)Math.min(newCapacity * loadFactor, MAX_ARRAY_SIZE + 1);//重新计算阀值
- boolean rehash = initHashSeedAsNeeded(newCapacity);//重新计算hashSeed
- table = newMap;
- for (int i = oldCapacity ; i-- > 0 ;) {//将原来的元素拷贝到新的HashTable中
- for (Entry<K,V> old = oldMap[i] ; old != null ; ) {
- Entry<K,V> e = old;
- old = old.next;
- if (rehash) {
- e.hash = hash(e.key);
- }
- int index = (e.hash & 0x7FFFFFFF) % newCapacity;
- e.next = newMap[index];
- newMap[index] = e;
- }
- }
- }
通过上面rehash代码我们可以看到容量扩大两倍+1,同时需要将原来HashTable中的元素一一复制到新的HashTable中,这个过程是比较消耗时间的,同时还需要重新计算hashSeed的,毕竟容量已经变了。
关于阀值:比如初始值11、加载因子默认0.75,那么这个时候阀值threshold=8,当容器中的元素达到8时,HashTable进行一次扩容操作,容量 = 8 * 2 + 1 =17,而阀值threshold=17*0.75 = 13,当容器元素再一次达到阀值时,HashTable还会进行扩容操作,一次类推。
4.数据读取get()
相对于put方法,get方法就会比较简单,处理过程就是计算key的hash值,判断在table数组中的索引位置,然后迭代链表,匹配直到找到相对应key的value,若没有找到返回null。
- public synchronized V get(Object key) {
- Entry tab[] = table;
- int hash = hash(key);
- int index = (hash & 0x7FFFFFFF) % tab.length;
- for (Entry<K,V> e = tab[index] ; e != null ; e = e.next) {
- if ((e.hash == hash) && e.key.equals(key)) {
- return e.value;
- }
- }
- return null;
- }
5.其他方法
三.Hashtable的遍历
1.遍历Hashtable的键值对(效率较高)
第一步:根据entrySet()获取Hashtable的“键值对”的Set集合。
第二步:通过Iterator迭代器遍历“第一步”得到的集合。
- // 假设table是Hashtable对象
- // table中的key是String类型,value是Integer类型
- Integer integ = null;
- Iterator iter = table.entrySet().iterator();
- while(iter.hasNext()) {
- Map.Entry entry = (Map.Entry)iter.next();
- // 获取key
- key = (String)entry.getKey();
- // 获取value
- integ = (Integer)entry.getValue();
- }
2.通过Iterator遍历Hashtable的键(效率较低)
第一步:根据keySet()获取Hashtable的“键”的Set集合。
第二步:通过Iterator迭代器遍历“第一步”得到的集合。
- // 假设table是Hashtable对象
- // table中的key是String类型,value是Integer类型
- String key = null;
- Integer integ = null;
- Iterator iter = table.keySet().iterator();
- while (iter.hasNext()) {
- // 获取key
- key = (String)iter.next();
- // 根据key,获取value
- integ = (Integer)table.get(key);
- }
3.通过Iterator遍历Hashtable的值
第一步:根据value()获取Hashtable的“值”的集合。
第二步:通过Iterator迭代器遍历“第一步”得到的集合。
- // 假设table是Hashtable对象
- // table中的key是String类型,value是Integer类型
- Integer value = null;
- Collection c = table.values();
- Iterator iter= c.iterator();
- while (iter.hasNext()) {
- value = (Integer)iter.next();
- }
4.通过Enumeration遍历Hashtable的键(效率较高)
第一步:根据keys()获取Hashtable的集合。
第二步:通过Enumeration遍历“第一步”得到的集合。
- Enumeration enu = table.keys();
- while(enu.hasMoreElements()) {
- System.out.println(enu.nextElement());
- }
5.通过Enumeration遍历Hashtable的值(效率较高)
第一步:根据elements()获取Hashtable的集合。
第二步:通过Enumeration遍历“第一步”得到的集合。
- Enumeration enu = table.elements();
- while(enu.hasMoreElements()) {
- System.out.println(enu.nextElement());
- }
四.HashTable和HashMap的比较
HashTable的应用非常广泛,HashMap是新框架中用来代替HashTable的类,也就是说建议使用HashMap。
下面着重比较一下二者的区别:
1.继承不同
Hashtable是基于陈旧的Dictionary类的,HashMap是java 1.2引进的Map接口的一个实现。
2.同步
Hashtable 中的方法是同步的,保证了Hashtable中的对象是线程安全的。
HashMap中的方法在缺省情况下是非同步的,HashMap中的对象并不是线程安全的。在多线程并发的环境下,可以直接使用Hashtable,但是要使用HashMap的话就要自己增加同步处理了。
3.效率
单线程中, HashMap的效率大于Hashtable。因为同步的要求会影响执行的效率,所以如果你不需要线程安全的集合,HashMap是Hashtable的轻量级实现,这样可以避免由于同步带来的不必要的性能开销,从而提高效率。
4.null值
Hashtable中,key和value都不允许出现null值,否则出现NullPointerException。
在HashMap中,null可以作为键,这样的键只有一个;可以有一个或多个键所对应的值为null。当get()方法返回null值时,即可以表示 HashMap中没有该键,也可以表示该键所对应的值为null。因此,在HashMap中不能由get()方法来判断HashMap中是否存在某个键,而应该用containsKey()方法来判断。
5.遍历方式
Hashtable、HashMap都使用了 Iterator。而由于历史原因,Hashtable还使用了Enumeration的方式。
6.容量
Hashtable和HashMap它们两个内部实现方式的数组的初始大小和扩容的方式。
HashTable中hash数组默认大小是11,增加的方式是 old*2+1。
HashMap中hash数组的默认大小是16,而且一定是2的指数。
小结:
无论什么时候有多个线程访问相同实例的可能时,就应该使用Hashtable,反之使用HashMap。非线程安全的数据结构能带来更好的性能。
如果在将来有一种可能—你需要按顺序获得键值对的方案时,HashMap是一个很好的选择,因为有HashMap的一个子类 LinkedHashMap。所以如果你想可预测的按顺序迭代(默认按插入的顺序),你可以很方便用LinkedHashMap替换HashMap。反观要是使用的Hashtable就没那么简单了。同时如果有多个线程访问HashMap,Collections.synchronizedMap()可以代替,总的来说HashMap更灵活。
http://blog.csdn.net/zheng0518/article/details/42199477
http://www.cnblogs.com/devinzhang/archive/2012/01/13/2321481.html
Java集合(8):Hashtable的更多相关文章
- 【java基础】java集合之HashTable,HashSet,HashMap
[一]HashSet (1)HashSet内部维护的是一个HashMap,具体原理见java集合之HashMap [二]HashTable (1)HashTable内部维护的是一个Entry的数组.E ...
- Java集合之Hashtable
和HashMap一样,Hashtable也是一个散列表,存储的内容也是键值对key-value映射.它继承了Dictionary,并实现了Map.Cloneable.io.Serializable接口 ...
- Java集合——HashMap,HashTable,ConcurrentHashMap区别
Map:“键值”对映射的抽象接口.该映射不包括重复的键,一个键对应一个值. SortedMap:有序的键值对接口,继承Map接口. NavigableMap:继承SortedMap,具有了针对给定搜索 ...
- Java集合之Hashtable源码分析
概述 Hashtable也是基于哈希表实现的, 与map相似, 不过Hashtable是线程安全的, Hashtable不允许 key或value为null. 成员变量 Hashtable的数据结构和 ...
- Java集合专题总结(1):HashMap 和 HashTable 源码学习和面试总结
2017年的秋招彻底结束了,感觉Java上面的最常见的集合相关的问题就是hash--系列和一些常用并发集合和队列,堆等结合算法一起考察,不完全统计,本人经历:先后百度.唯品会.58同城.新浪微博.趣分 ...
- Java 集合系列11之 Hashtable详细介绍(源码解析)和使用示例
概要 前一章,我们学习了HashMap.这一章,我们对Hashtable进行学习.我们先对Hashtable有个整体认识,然后再学习它的源码,最后再通过实例来学会使用Hashtable.第1部分 Ha ...
- HashSet HashTable HashMap的区别 及其Java集合介绍
(1)HashSet是set的一个实现类,hashMap是Map的一个实现类,同时hashMap是hashTable的替代品(为什么后面会讲到). (2)HashSet以对象作为元素,而HashMap ...
- Java 集合系列14之 Map总结(HashMap, Hashtable, TreeMap, WeakHashMap等使用场景)
概要 学完了Map的全部内容,我们再回头开开Map的框架图. 本章内容包括:第1部分 Map概括第2部分 HashMap和Hashtable异同第3部分 HashMap和WeakHashMap异同 转 ...
- Java 集合系列 10 Hashtable详细介绍(源码解析)和使用示例
java 集合系列目录: Java 集合系列 01 总体框架 Java 集合系列 02 Collection架构 Java 集合系列 03 ArrayList详细介绍(源码解析)和使用示例 Java ...
- Java 集合系列 11 hashmap 和 hashtable 的区别
java 集合系列目录: Java 集合系列 01 总体框架 Java 集合系列 02 Collection架构 Java 集合系列 03 ArrayList详细介绍(源码解析)和使用示例 Java ...
随机推荐
- 【vijos】1781 同余方程(拓展欧几里得)
https://vijos.org/p/1781 学习了下拓欧.. 求exgcd时,因为 a*x1+b*y1=a*x2+b*y2=b*x2+(a-b*[a/b])*y2 然后移项得 a*x1+b*y1 ...
- Ubuntu14.4下搭配WEB服务器(apache + php + mysql)
今天,趁着自己动手安装web服务器的余热,将Ubuntu14.4搭配WEB服务器的过程记录下来. “一切皆文件”. 说明:网上关于类似搭配web服务器的教程,案例不计其数,但自己亲自动手“试试”,一定 ...
- (转)servlet setCharacterEncoding setContentType
转自:http://blog.csdn.net/fancylovejava/article/details/7700683 编码中的setCharacterEncoding 理解 1.pageEnco ...
- plsql数组、表和对象
--数组DECLARE TYPE test_plsql_varray IS VARRAY(100) OF VARCHAR2(20); temp_varray1 test_PLSQL_VARRAY := ...
- 源码分析——Action代理类的工作
Action代理类的新建 通过<Struts2 源码分析——调结者(Dispatcher)之执行action>章节我们知道执行action请求,最后会落到Dispatcher类的serv ...
- 记一次Project插件开发
一.开发背景 最近在使用微软的Office Project 2010 进行项目管理,看到排的满满的计划任务,一个个地被执行完毕,还是很有成就感的.其实,不光是在工作中可以使用Project进行项目进度 ...
- 【BZOJ1816】[Cqoi2010]扑克牌 二分
[BZOJ1816][Cqoi2010]扑克牌 Description 你有n种牌,第i种牌的数目为ci.另外有一种特殊的牌:joker,它的数目是m.你可以用每种牌各一张来组成一套牌,也可以用一张j ...
- LeetCode-Integer Breaks
Given a positive integer n, break it into the sum of at least two positive integers and maximize the ...
- textarea输入字符有限制
function limitedNumberOfInputCharacters(limitedNumber, string){ var strLength = 0; if(string !== nul ...
- pc端和移动端的区别
以下都是自己的个人理解,说错了希望大家多交流交流.1,普通pc端开发与移动端开发区别.普通pc端开发,我理解就是你拿电脑打开的网页都算[这相信大部分人都知道].那么移动端开发工程师,说白了就很好理解了 ...