STL空间分配器源码分析(二)mt_allocator
一、简介
mt allocator 是一种以2的幂次方字节大小为分配单位的空间配置器,支持多线程和单线程。该配置器灵活可调,性能高。
分配器有三个通用组件:一个描述内存池特性的数据,一个包含该池的策略类,该池将实例化类型链接到公共或单个池,以及一个从策略类继承的类,该类是实际的分配器。
描述内存池特性的数据:template<bool _Thread> class __pool;
内存池的策略类:mt allocator提供了两种策略,一种公共内存池,一种专用内存池;
实际的分配器:class __mt_alloc
二、内存池特性描述
struct _Tune
{
// Compile time constants for the default _Tune values.
enum { _S_align = 8 };
enum { _S_max_bytes = 128 };
enum { _S_min_bin = 8 };
enum { _S_chunk_size = 4096 - 4 * sizeof(void*) };
enum { _S_max_threads = 4096 };
enum { _S_freelist_headroom = 10 }; size_t _M_align; //对齐大小,在任何情况下,必须大于等于sizeof(_Block_record),即在32位机器上为4,在64位机器上为8。
size_t _M_max_bytes; //能分配的最大内存块大小,必须远小于_M_chunk_size的大小且必须小于32768
size_t _M_min_bin; //能分配的最小内存块大小,2的幂次方,必须大于等于_M_align且远小于_M_max_bytes
size_t _M_chunk_size; //预先申请的内存块大小,为避免内存碎片和频繁调用new申请小内存,所以先提前申请好大块内存,该值需远大于_M_max_bytes
size_t _M_max_threads; //支持的最大线程数
size_t _M_freelist_headroom; //多线程下,当回收的内存数超过其空闲链表的_M_freelist_headroom %,将内存块直接回收到全局链表中
bool _M_force_new; //是否强制使用new申请 //如下两个构造函数,一个默认构造函数,使用默认值初始化上述控制信息,一个根据入参确定控制信息
explicit
_Tune()
: _M_align(_S_align), _M_max_bytes(_S_max_bytes), _M_min_bin(_S_min_bin),
_M_chunk_size(_S_chunk_size), _M_max_threads(_S_max_threads),
_M_freelist_headroom(_S_freelist_headroom),
_M_force_new(std::getenv("GLIBCXX_FORCE_NEW") ? true : false)
{ } explicit
_Tune(size_t __align, size_t __maxb, size_t __minbin, size_t __chunk,
size_t __maxthreads, size_t __headroom, bool __force)
: _M_align(__align), _M_max_bytes(__maxb), _M_min_bin(__minbin),
_M_chunk_size(__chunk), _M_max_threads(__maxthreads),
_M_freelist_headroom(__headroom), _M_force_new(__force)
{ }
};
三、内存池实现
struct __pool_base
{
typedef unsigned short int _Binmap_type;
typedef std::size_t size_t; struct _Block_address
{
void* _M_initial;
_Block_address* _M_next;
}; const _Tune& _M_get_options() const
{ return _M_options; } void _M_set_options(_Tune __t)
{
if (!_M_init)
_M_options = __t;
} bool _M_check_threshold(size_t __bytes)
{ return __bytes > _M_options._M_max_bytes || _M_options._M_force_new; } size_t _M_get_binmap(size_t __bytes)
{ return _M_binmap[__bytes]; } size_t _M_get_align()
{ return _M_options._M_align; } explicit __pool_base()
: _M_options(_Tune()), _M_binmap(0), _M_init(false) { } explicit __pool_base(const _Tune& __options)
: _M_options(__options), _M_binmap(0), _M_init(false) { } private:
explicit __pool_base(const __pool_base&); __pool_base& operator=(const __pool_base&); protected:
_Tune _M_options;
_Binmap_type* _M_binmap;
bool _M_init; //内存池对象的特性配置(Tune)可以在构造之后,但必须在初始化之前。初始化完成后,该标志置为true
};
上述为内存池的基类实现,类成员包括描述内存池特性的Tune结构,内存块索引的表结构指针(_M_binmap)和初始化标志_M_init,以及部分简单接口。
_M_get_options和_M_set_options用于查设内存池特性参数;
_M_check_threshold用于内存块大小校验,以此判断是否需要调用关键字new申请内存;
_M_get_binmap用于根据申请的内存块大小映射到对应的内存块下标(即子类_M_bin数组下标,下面详细介绍);
_M_get_align获取内存池特性参数之对齐大小;
mt_allocator配置器基于__pool_base实现了单一线程和多线程两种场景使用下的内存池(实际是指定了两种全特化的内存池模板),如下
template<bool _Thread>
class __pool; /*单线程*/
template<>
class __pool<false> : public __pool_base{...};
/*多线程*/
template<>
class __pool<true> : public __pool_base{...};
四、单一线程场景下内存池的实现
template<>
class __pool<false> : public __pool_base
{
public:
/* 表示内存块节点,用来构成内存链表结构 */
union _Block_record
{
_Block_record* _M_next; // 指向下一个内存块的节点
}; /* 用来记录内存单元信息,每个内存单元存储着同一大小的数个内存块 */
struct _Bin_record
{
_Block_record** _M_first; // 指针数组,数组中的每个指针指向第一个空闲块节点,数组的大小等于线程的个数,每个线程占一个数组元素,单线程情况下仅为一个
_Block_address* _M_address; // 内存单元的地址
}; //内存池初始化,内部防止多次初始化
void _M_initialize_once()
{
if (__builtin_expect(_M_init == false, false))
_M_initialize();
} //内存池资源回收
void _M_destroy() throw(); //内存块分配
char* _M_reserve_block(size_t __bytes, const size_t __thread_id); //内存块回收
void _M_reclaim_block(char* __p, size_t __bytes) throw (); size_t _M_get_thread_id() { return 0; } const _Bin_record& _M_get_bin(size_t __which)
{ return _M_bin[__which]; } void _M_adjust_freelist(const _Bin_record&, _Block_record*, size_t) { } explicit __pool()
: _M_bin(0), _M_bin_size(1) { } explicit __pool(const __pool_base::_Tune& __tune)
: __pool_base(__tune), _M_bin(0), _M_bin_size(1) { } private:
_Bin_record* _M_bin; //指向内存单元数组的首地址,数组中每个成员代表着不同内存块大小的内存单元信息
size_t _M_bin_size; //_M_bin数组的大小
void _M_initialize();
};
其中重点在于内存池的结构建立、内存块的申请和回收。
内存池的初始化
先讲讲内存池的建立,前面已经讲到,基类__pool_base定义了一个_M_binmap指针变量,指向一个_Binmap_type数组,这个数组主要用来建立申请的内存块大小和_M_bin数组下标的映射关系,
数组的范围从0到_S_max_bytes(默认128),数组的值 为_M_bin数组的下标(从0到_M_bin_size-1)。_M_bin_size的值也是在这个映射关系建立的过程中计算出来的,而当_M_bin_size计算出后,
即可构建_M_bin数组。_M_binmap和_M_bin的建立都在_M_initialize()函数内实现。
void __pool<false>::_M_initialize()
{
// _M_force_new在首次调用allocate后不能再修改,当_M_force_new为true时,不需建立下面的binMap映射和_M_bin
if (_M_options._M_force_new)
{
_M_init = true;
return;
} // 要点1,根据 _M_max_bytes计算bin的个数,_M_bin_size 静态初始化为1.
size_t __bin_size = _M_options._M_min_bin;
while (_M_options._M_max_bytes > __bin_size)
{
__bin_size <<= 1;
++_M_bin_size;
} // 要点2,建立binMap映射,以便快速定位到bin结构.
const size_t __j = (_M_options._M_max_bytes + 1) * sizeof(_Binmap_type);
_M_binmap = static_cast<_Binmap_type*>(::operator new(__j));
_Binmap_type* __bp = _M_binmap;
_Binmap_type __bin_max = _M_options._M_min_bin;
_Binmap_type __bint = 0;
for (_Binmap_type __ct = 0; __ct <= _M_options._M_max_bytes; ++__ct)
{
if (__ct > __bin_max)
{
__bin_max <<= 1;
++__bint;
}
*__bp++ = __bint;
} // 要点3,初始化 _M_bin及其成员结构
void* __v = ::operator new(sizeof(_Bin_record) * _M_bin_size);
_M_bin = static_cast<_Bin_record*>(__v);
for (size_t __n = 0; __n < _M_bin_size; ++__n)
{
_Bin_record& __bin = _M_bin[__n];
__v = ::operator new(sizeof(_Block_record*));
__bin._M_first = static_cast<_Block_record**>(__v);
__bin._M_first[0] = 0;
__bin._M_address = 0;
}
_M_init = true;
}
现为方便理解代码,假定_M_options均为默认值,即_M_options._M_min_bin = 8,_M_options._M_max_bytes = 128,经过要点1的代码,循环遍历后,计算出_M_bin_size = 5。经过要点2的代码,_M_binmap数组的大小为129,得出如下映射:
_M_binmap[0]~_M_binmap[8] = 0; _M_binmap[9]~_M_binmap[16] = 1; _M_binmap[17]~_M_binmap[32] = 2; _M_binmap[33]~_M_binmap[64] = 3; _M_binmap[65]~_M_binmap[128] = 4; 其值对应着_M_bin数组的下标索引。
可清晰可见,当申请的内存块大小在2^(n-1) + 1 ~ 2^n,均能坐落在同一下标,即同一_M_bin。
当经过要点3的代码,可建立_M_bin数组,数组大小为5。由于是单线程,__bin._M_first数组大小仅为一个,故这里仅new了一个_Block_record*的大小的内存,并让__bin._M_first指向new出来的内存。
内存块的分配
_M_initialize()函数仅建立_M_binmap映射和_M_bin内存单元结构,真正的内存块(分配给上层应用的)并未在这里申请,而是在_M_reserve_block()函数调用的时侯。allocate()会检查_M_binmap._M_first[0],判断是否调用_M_reserve_block()。
allocate()函数内部会调用_M_initialize()和_M_reserve_block()函数。_M_reserve_block()函数的实现如下
char* __pool<false>::_M_reserve_block(size_t __bytes, const size_t __thread_id)
{
// 通过binMap映射和申请的内存块大小__bytes,快速定位到bin结构(__bytes会向上取整,找到对应的2的幂次大小的内存块)
const size_t __which = _M_binmap[__bytes];
_Bin_record& __bin = _M_bin[__which]; //计算可分割的内存块个数,由下可见是将大块内存chunk分割为若干小块block,每块长度为__bytes对应的2的幂次大小
const _Tune& __options = _M_get_options();
const size_t __bin_size = (__options._M_min_bin << __which) + __options._M_align;
size_t __block_count = __options._M_chunk_size - sizeof(_Block_address);
__block_count /= __bin_size; // 动态申请内存大块chunk,chunk前预留一个_Block_address结构,用来存放内存大块的地址信息,
// _Block_address结构内的_M_Next指针用来建立链表结构,此处是将新申请的内存大块插入链表头
void* __v = ::operator new(__options._M_chunk_size);
_Block_address* __address = static_cast<_Block_address*>(__v);
__address->_M_initial = __v;
__address->_M_next = __bin._M_address;
__bin._M_address = __address; //建立内存块的链表结构,链表的头节点为__bin._M_first[__thread_id]
char* __c = static_cast<char*>(__v) + sizeof(_Block_address);
_Block_record* __block = reinterpret_cast<_Block_record*>(__c);
__bin._M_first[__thread_id] = __block;
while (--__block_count > 0)
{
__c += __bin_size;
__block->_M_next = reinterpret_cast<_Block_record*>(__c);
__block = __block->_M_next;
}
__block->_M_next = 0; //这里从链表中取出头节点,作为用户申请的内存返回
__block = __bin._M_first[__thread_id];
__bin._M_first[__thread_id] = __block->_M_next; // 返回内存块的实际可用地址,出于内存对齐要求,内存块首部的align部分不可用,即使sizeof(_Block_record) < _M_align.
return reinterpret_cast<char*>(__block) + __options._M_align;
}
前面讲到内存池特性的时候,结构体Tune内_M_align大小必须大于sizeof(_Block_record),原因便在于此,最后返回给用户的内存需要加上_M_align的偏移,才不会破坏_Block_record建立的链表结构。
_M_reserve_block()函数在当空闲链表为空时调用,会一次申请足够大小的内存块(_M_options._M_chunk_size),分割内存小块,建立好链表结构,并把头节点内存块返回。
当空闲链表的最后一块内存小块取出后,__bin._M_first[__thread_id]重新指向NULL,后面若用户需要重新申请内存,会再一次调用_M_reserve_block()函数执行如上操作,将新申请的内存大块(chunk)
地址信息插入_Block_address构建的链表头。
每一个内存大块(chunk)首部都会预留一个_Block_address结构,其_M_Next指针将每个内存大块地址信息串联起来形成链表。后续内存池的销毁操作_M_destroy()也是依靠此链表逐一来释放内存。
内存块的回收
与_M_reserve_block()函数相对的是_M_reclaim_block()函数,负责内存块的回收,实现如下
void __pool<false>::_M_reclaim_block(char* __p, size_t __bytes) throw ()
{
// 通过binMap映射和申请的内存块大小__bytes,快速定位到bin结构
const size_t __which = _M_binmap[__bytes];
_Bin_record& __bin = _M_bin[__which]; // 申请的时候加上_M_align偏移,这里回收自然要减去
char* __c = __p - _M_get_align();
_Block_record* __block = reinterpret_cast<_Block_record*>(__c); // 单线程对应的链表头节点为__bin._M_first[0],这里将回收的内存块放回链表头
__block->_M_next = __bin._M_first[0];
__bin._M_first[0] = __block;
}
内存池资源回收
与_M_initialize()相对的是_M_destroy()函数,负责整个内存池资源的回收(包括映射表的回收和内存单元结构的回收,内存块的回收等)。
void __pool<false>::_M_destroy() throw()
{
if (_M_init && !_M_options._M_force_new)
{
for (size_t __n = 0; __n < _M_bin_size; ++__n)
{
//循环遍历,释放内存块
_Bin_record& __bin = _M_bin[__n];
while (__bin._M_address)
{
_Block_address* __tmp = __bin._M_address->_M_next;
::operator delete(__bin._M_address->_M_initial);
__bin._M_address = __tmp;
}
::operator delete(__bin._M_first);
}
//释放_M_binmap和_M_bin结构
::operator delete(_M_bin);
::operator delete(_M_binmap);
}
}
五、内存池的策略类实现
在分析多线程场景内存池实现前,先看看mt_allocator空间配置器的另一组件,内存池的策略类。
mt_allocator空间配置器提供了两个不同的策略类,每一个都可以与任何类型的基础池数据一起使用。
第一个策略_common_pool_policy实现了一个公共池。这意味着使用不同类型(比如char和long)实例化的分配器将使用同一个池。这是默认策略。
template<template <bool> class _PoolTp, bool _Thread>
struct __common_pool
{
typedef _PoolTp<_Thread> pool_type;
static pool_type& _S_get_pool()
{
static pool_type _S_pool;
return _S_pool;
}
};
__common_pool类仅提供了一个静态接口_S_get_pool,用来获取静态的内存池对象。
template<template <bool> class _PoolTp, bool _Thread>
struct __common_pool_base; template<template <bool> class _PoolTp>
struct __common_pool_base<_PoolTp, false>
: public __common_pool<_PoolTp, false>
{
using __common_pool<_PoolTp, false>::_S_get_pool;
static void _S_initialize_once()
{
static bool __init;
if (__builtin_expect(__init == false, false))
{
_S_get_pool()._M_initialize_once();
__init = true;
}
}
};
__common_pool_base类继承自__common_pool,实现了接口_S_initialize_once,内部会做初始化校验,防止多次初始化(虽然_M_initialize_once内部也做了校验)。上述为__common_pool_base类的单线程偏特化版本
多线程的偏特化如下:
#ifdef __GTHREADS
template<template <bool> class _PoolTp>
struct __common_pool_base<_PoolTp, true>
: public __common_pool<_PoolTp, true>
{
using __common_pool<_PoolTp, true>::_S_get_pool; static void _S_initialize()
{ _S_get_pool()._M_initialize_once(); } static void _S_initialize_once()
{
static bool __init;
if (__builtin_expect(__init == false, false))
{
if (__gthread_active_p())
{
static __gthread_once_t __once = __GTHREAD_ONCE_INIT;
__gthread_once(&__once, _S_initialize);
} //二次检查初始化,在某些系统平台,可能不使用多线程标志编译
_S_get_pool()._M_initialize_once();
__init = true;
}
}
};
#endif
当支持多线程编译时,__GTHREADS置为1,__gthread_active_p()函数检查程序链接方式,是否支持多线程,当支持时,函数返回1。
__gthread_once保证多线程下函数_S_initialize只调用一次,即只做一次初始化。
template<template <bool> class _PoolTp, bool _Thread>
struct __common_pool_policy : public __common_pool_base<_PoolTp, _Thread>
{
template<typename _Tp1, template <bool> class _PoolTp1 = _PoolTp, bool _Thread1 = _Thread>
struct _M_rebind
{ typedef __common_pool_policy<_PoolTp1, _Thread1> other; }; using __common_pool_base<_PoolTp, _Thread>::_S_get_pool;
using __common_pool_base<_PoolTp, _Thread>::_S_initialize_once;
};
__common_pool_policy类继承自__common_pool_base,其作用仅提供了_M_rebind,供mt_allocator空间配置器使用。
template<typename _Tp1, typename _Poolp1 = _Poolp>
struct rebind
{
typedef typename _Poolp1::template _M_rebind<_Tp1>::other pol_type;
typedef __mt_alloc<_Tp1, pol_type> other;
};
第二个策略是_per_type_pool_policy,它为每个实例化类型实现一个单独的池。因此,char和long将使用单独的池,允许按类型调整。
template<typename _Tp, template <bool> class _PoolTp, bool _Thread>
struct __per_type_pool
{
typedef _Tp value_type;
typedef _PoolTp<_Thread> pool_type; static pool_type& _S_get_pool()
{
using std::size_t;
// 这里保证了对齐的字节要大于sizeof(_Block_record)
typedef typename pool_type::_Block_record _Block_record;
const static size_t __a = (__alignof__(_Tp) >= sizeof(_Block_record)
? __alignof__(_Tp) : sizeof(_Block_record)); typedef typename __pool_base::_Tune _Tune;
static _Tune _S_tune(__a, sizeof(_Tp) * 64,
sizeof(_Tp) * 2 >= __a ? sizeof(_Tp) * 2 : __a,
sizeof(_Tp) * size_t(_Tune::_S_chunk_size),
_Tune::_S_max_threads,
_Tune::_S_freelist_headroom,
std::getenv("GLIBCXX_FORCE_NEW") ? true : false);
static pool_type _S_pool(_S_tune);
return _S_pool;
}
}; template<typename _Tp, template <bool> class _PoolTp, bool _Thread>
struct __per_type_pool_base; template<typename _Tp, template <bool> class _PoolTp>
struct __per_type_pool_base<_Tp, _PoolTp, false>
: public __per_type_pool<_Tp, _PoolTp, false>
{
using __per_type_pool<_Tp, _PoolTp, false>::_S_get_pool; static void _S_initialize_once()
{
static bool __init;
if (__builtin_expect(__init == false, false))
{
_S_get_pool()._M_initialize_once();
__init = true;
}
}
}; #ifdef __GTHREADS
template<typename _Tp, template <bool> class _PoolTp>
struct __per_type_pool_base<_Tp, _PoolTp, true>
: public __per_type_pool<_Tp, _PoolTp, true>
{
using __per_type_pool<_Tp, _PoolTp, true>::_S_get_pool; static void _S_initialize()
{ _S_get_pool()._M_initialize_once(); } static void _S_initialize_once()
{
static bool __init;
if (__builtin_expect(__init == false, false))
{
if (__gthread_active_p())
{
static __gthread_once_t __once = __GTHREAD_ONCE_INIT;
__gthread_once(&__once, _S_initialize);
} _S_get_pool()._M_initialize_once();
__init = true;
}
}
};
#endif template<typename _Tp, template <bool> class _PoolTp, bool _Thread>
struct __per_type_pool_policy
: public __per_type_pool_base<_Tp, _PoolTp, _Thread>
{
template<typename _Tp1, template <bool> class _PoolTp1 = _PoolTp, bool _Thread1 = _Thread>
struct _M_rebind
{ typedef __per_type_pool_policy<_Tp1, _PoolTp1, _Thread1> other; }; using __per_type_pool_base<_Tp, _PoolTp, _Thread>::_S_get_pool;
using __per_type_pool_base<_Tp, _PoolTp, _Thread>::_S_initialize_once;
};
__per_type_pool_policy内存池策略类的实现与__common_pool_policy大同小异,区别在于__per_type_pool_policy多提供了一个_Tp的模板参数,使用户可以指定类型建立不同的内存池,其内部内存池的各个特性参数也依赖于数据类型_Tp。
六、多线程场景下的内存池实现
多线程场景下,内存块的申请和释放,需要考虑线程安全性问题,且,同一内存块可能在应用层被交付给不同线程使用,这导致,将会出现这种场景:内存块由线程A申请,由线程B释放回收。
内存池的初始化同样要考虑多线程并发的问题,且若采用前面所述的__per_type_pool_policy内存池策略类,应用层可能会申请创建支持不同数据类型的内存池,这也是一个需要考虑的问题。
先看下内存池的定义
#ifdef __GTHREADS
template<>
class __pool<true> : public __pool_base
{
public:
struct _Thread_record
{
_Thread_record* _M_next; // 用来构建_Thread_record链表,指向下一个_Thread_record节点,最后一个节点的_M_next指向null.
size_t _M_id; // 该线程分配到的ID,从1到_S_max_threads.
};
union _Block_record
{
_Block_record* _M_next; // 用来构建_Block_record链表,将内存块串联成链表形式
size_t _M_thread_id; // 请求该内存块的线程的ID
};
struct _Bin_record
{
_Block_record** _M_first; // 指针数组,数组中的每个指针指向第一个空闲块节点,数组的大小等于线程的个数+1,每个线程占一个数组元素,0号表全局空闲链表
_Block_address* _M_address; // 内存块地址
size_t* _M_free; // 指向一个统计数组,每个数组成员记录了对应线程当前的空闲块个数,数组大小等于线程个数+1
size_t* _M_used; // 指向一个统计数组,数组分两个部分,第一部分(0~_S_max_threads)的每个数组成员记录了对应线程当前的使用块个数,
// 第二部分(_S_max_threads+1 ~ (2*_S_max_threads+1)-1)的每个数组成员记录了各个线程回收的属于当前线程的内存块个数
__gthread_mutex_t* _M_mutex; // 每个bin都有自己的互斥锁,用于在更改块的“所有权”时确保数据完整性。互斥锁在_S_initialize()中初始化。
}; void _M_initialize(__destroy_handler); void _M_initialize_once()
{
if (__builtin_expect(_M_init == false, false))
_M_initialize();
} // 内存池资源回收
void _M_destroy() throw(); // 内存申请
char* _M_reserve_block(size_t __bytes, const size_t __thread_id); // 内存回收
void _M_reclaim_block(char* __p, size_t __bytes) throw (); const _Bin_record& _M_get_bin(size_t __which)
{ return _M_bin[__which]; } // 更新block的线程ID和free、used统计数值
void _M_adjust_freelist(const _Bin_record& __bin, _Block_record* __block, size_t __thread_id)
{
if (__gthread_active_p())
{
__block->_M_thread_id = __thread_id;
--__bin._M_free[__thread_id];
++__bin._M_used[__thread_id];
}
} // 回收线程ID
void _M_destroy_thread_key(void*) throw (); // 分配线程ID
size_t _M_get_thread_id(); explicit __pool()
: _M_bin(0), _M_bin_size(1), _M_thread_freelist(0)
{ } explicit __pool(const __pool_base::_Tune& __tune)
: __pool_base(__tune), _M_bin(0), _M_bin_size(1),
_M_thread_freelist(0)
{ } private:
_Bin_record* _M_bin;
size_t _M_bin_size;
_Thread_record* _M_thread_freelist; //线程ID链表
void* _M_thread_freelist_initial;
void _M_initialize();
};
#endif
与单线程内存池存在如下区别:
- 多了_Thread_record结构,该结构用来记录每个线程的ID信息(该ID有别于系统为线程分配的ID),其由内部进行分配,范围在1~_S_max_threads。_M_next指针将该每个线程的ID信息串联成链表;
- _Block_record结构多了_M_thread_id,用来记录该内存块是由哪个线程分配的,即所有权归属;
- _Bin_record结构多了_M_free、_M_used、_M_mutex。_M_free和_M_used用来记录全局链表和每个线程的链表空闲内存块和已用内存块的统计数值。_M_mutex用来进行加锁保护Bin结构;
- 新增了_M_get_thread_id()和_M_destroy_thread_key()成员函数,负责线程ID的分配和回收;
- 新增了成员变量_M_thread_freelist和_M_thread_freelist_initial。_M_thread_freelist指向了_Thread_record链表结构,_M_thread_freelist_initial貌似没有找到有地方使用;
线程ID的分配和回收
首先mt_allocator.cc内部定义了个__freelist结构,用来管理线程ID的分配和回收,__freelist的定义如下
struct __freelist
{
typedef __gnu_cxx::__pool<true>::_Thread_record _Thread_record;
_Thread_record* _M_thread_freelist; // 指向空闲的(未分配的)线程ID链表
_Thread_record* _M_thread_freelist_array; // 指向一个线程ID链表,包括1~_M_max_threads所有线程的ID
size_t _M_max_threads; // 最大线程数,即_M_thread_freelist_array长度
__gthread_key_t _M_key; // 建立线程私有数据的键值 ~__freelist()
{
if (_M_thread_freelist_array)
{
__gthread_key_delete(_M_key);
::operator delete(static_cast<void*>(_M_thread_freelist_array));
_M_thread_freelist = 0;
}
}
};
定义了如下几个全局的接口函数
// 获取全局静态链表__freelist
__freelist& get_freelist()
{
static __freelist freelist;
return freelist;
} // 获取全局静态链表__freelist的互斥量
__gnu_cxx::__mutex& get_freelist_mutex()
{
static __gnu_cxx::__mutex freelist_mutex;
return freelist_mutex;
} // 线程ID回收
static void _M_destroy_thread_key(void* __id)
{
__freelist& freelist = get_freelist();
{
__gnu_cxx::__scoped_lock sentry(get_freelist_mutex());
uintptr_t _M_id = reinterpret_cast<uintptr_t>(__id); // 线程释放时,将分配给该线程的ID回收,插入空闲链表头
typedef __gnu_cxx::__pool<true>::_Thread_record _Thread_record;
_Thread_record* __tr = &freelist._M_thread_freelist_array[_M_id - 1];
__tr->_M_next = freelist._M_thread_freelist;
freelist._M_thread_freelist = __tr;
}
}
内存池内部也定义了线程ID分配的接口,而线程ID回收的接口不做实现(实际上是在调用__gthread_key_create创建key值时传入了全局函数_M_destroy_thread_key的指针,ID的回收交由gthread负责)
size_t __pool<true>::_M_get_thread_id()
{
if (__gthread_active_p())
{
__freelist& freelist = get_freelist();
void* v = __gthread_getspecific(freelist._M_key);
uintptr_t _M_id = (uintptr_t)v;
// _M_id为0,表示新线程,还未分配ID
if (_M_id == 0)
{
__gnu_cxx::__scoped_lock sentry(get_freelist_mutex());
if (freelist._M_thread_freelist)
{
// 线程ID空闲列表还存在节点,则从链表中取出一个ID分配
_M_id = freelist._M_thread_freelist->_M_id;
freelist._M_thread_freelist = freelist._M_thread_freelist->_M_next;
}
// 设置线程私有数据,即_M_id值
__gthread_setspecific(freelist._M_key, (void*)_M_id);
}
return _M_id >= _M_options._M_max_threads ? 0 : _M_id;
} return 0;
} void __pool<true>::_M_destroy_thread_key(void*) throw () { }
内存池的初始化
与单线程内存池一样,多线程内存池的初始化接口也为_M_initialize,但其内部实现较之有所差异,也较为复杂。
void __pool<true>::_M_initialize()
{
if (_M_options._M_force_new)
{
_M_init = true;
return;
} // 要点1,_M_bin_size的计算和_M_binmap映射的构建
size_t __bin_size = _M_options._M_min_bin;
while (_M_options._M_max_bytes > __bin_size)
{
__bin_size <<= 1;
++_M_bin_size;
} const size_t __j = (_M_options._M_max_bytes + 1) * sizeof(_Binmap_type);
_M_binmap = static_cast<_Binmap_type*>(::operator new(__j));
_Binmap_type* __bp = _M_binmap;
_Binmap_type __bin_max = _M_options._M_min_bin;
_Binmap_type __bint = 0;
for (_Binmap_type __ct = 0; __ct <= _M_options._M_max_bytes; ++__ct)
{
if (__ct > __bin_max)
{
__bin_max <<= 1;
++__bint;
}
*__bp++ = __bint;
} void* __v = ::operator new(sizeof(_Bin_record) * _M_bin_size);
_M_bin = static_cast<_Bin_record*>(__v); if (__gthread_active_p())
{
__freelist& freelist = get_freelist();
__gnu_cxx::__scoped_lock sentry(get_freelist_mutex()); // 要点2,构建全局链表__freelist,两种场景,1为初次构建,2为最大线程数增加
if (!freelist._M_thread_freelist_array
|| freelist._M_max_threads < _M_options._M_max_threads)
{
const size_t __k = sizeof(_Thread_record) * _M_options._M_max_threads;
__v = ::operator new(__k);
_M_thread_freelist = static_cast<_Thread_record*>(__v); // 线程ID从1开始,0留给全局链表用
size_t __i;
for (__i = 1; __i < _M_options._M_max_threads; ++__i)
{
_Thread_record& __tr = _M_thread_freelist[__i - 1];
__tr._M_next = &_M_thread_freelist[__i];
__tr._M_id = __i;
} // 设置最后一个节点。到此为止,_M_thread_freelist链表构建完成,并记录了每个线程的ID
_M_thread_freelist[__i - 1]._M_next = 0;
_M_thread_freelist[__i - 1]._M_id = __i; if (!freelist._M_thread_freelist_array)
{
// 要点3,初次构建链表,初始化freelist(设置链表key值,并将其_M_thread_freelist指向刚构建完成的_M_thread_freelist链表
__gthread_key_create(&freelist._M_key, ::_M_destroy_thread_key);
freelist._M_thread_freelist = _M_thread_freelist;
}
else
{
// 要点4,freelist链表重建
_Thread_record* _M_old_freelist = freelist._M_thread_freelist;
_Thread_record* _M_old_array = freelist._M_thread_freelist_array;
freelist._M_thread_freelist = &_M_thread_freelist[_M_old_freelist - _M_old_array];
while (_M_old_freelist)
{
size_t next_id;
if (_M_old_freelist->_M_next)
next_id = _M_old_freelist->_M_next - _M_old_array;
else
next_id = freelist._M_max_threads;
_M_thread_freelist[_M_old_freelist->_M_id - 1]._M_next = &_M_thread_freelist[next_id];
_M_old_freelist = _M_old_freelist->_M_next;
}
// 旧链表释放
::operator delete(static_cast<void*>(_M_old_array));
}
freelist._M_thread_freelist_array = _M_thread_freelist;
freelist._M_max_threads = _M_options._M_max_threads;
} // 要点5,建立_M_bin数组
const size_t __max_threads = _M_options._M_max_threads + 1;
for (size_t __n = 0; __n < _M_bin_size; ++__n)
{
_Bin_record& __bin = _M_bin[__n];
__v = ::operator new(sizeof(_Block_record*) * __max_threads);
std::memset(__v, 0, sizeof(_Block_record*) * __max_threads);
__bin._M_first = static_cast<_Block_record**>(__v); __bin._M_address = 0; __v = ::operator new(sizeof(size_t) * __max_threads);
std::memset(__v, 0, sizeof(size_t) * __max_threads);
__bin._M_free = static_cast<size_t*>(__v); // 要点6,_M_used分两部分,第一部分是线程已分配出去的内存块计数,第二部分时各个线程回收的内存块计数
__v = ::operator new(sizeof(size_t) * __max_threads + sizeof(_Atomic_word) * __max_threads);
std::memset(__v, 0, (sizeof(size_t) * __max_threads + sizeof(_Atomic_word) * __max_threads));
__bin._M_used = static_cast<size_t*>(__v); __v = ::operator new(sizeof(__gthread_mutex_t));
__bin._M_mutex = static_cast<__gthread_mutex_t*>(__v); // __bin._M_mutex初始化
#ifdef __GTHREAD_MUTEX_INIT
{
// Do not copy a POSIX/gthr mutex once in use.
__gthread_mutex_t __tmp = __GTHREAD_MUTEX_INIT;
*__bin._M_mutex = __tmp;
}
#else
{ __GTHREAD_MUTEX_INIT_FUNCTION(__bin._M_mutex); }
#endif
}
}
else
{
// 不支持多线程,构建方式形如单线程
for (size_t __n = 0; __n < _M_bin_size; ++__n)
{
_Bin_record& __bin = _M_bin[__n];
__v = ::operator new(sizeof(_Block_record*));
__bin._M_first = static_cast<_Block_record**>(__v);
__bin._M_first[0] = 0;
__bin._M_address = 0;
}
}
_M_init = true;
}
#endif
内存池实现了两个版本的初始化函数,另一版本如下,其实现与void __pool<true>::_M_initialize();完全一样
void __pool<true>::_M_initialize(__destroy_handler);
上述代码,按注释要点详细说明
要点1,_M_bin_size的计算和_M_binmap映射的构建,其方式如同单线程内存池的初始化部分,可参考前面单线程章节的说明;
要点2,该if分支用来判断全局链表freelist是否需要建立或重建,根据其判断有两种可能性:
freelist._M_thread_freelist_array为空,表示链表是未经初始化,链表初始化后,_M_thread_freelist_array指针会指向构建好的_Thread_record数组,包含1~_M_max_threads 的所有线程ID节点;
freelist._M_max_threads < _M_options._M_max_threads 条件为真。这涉及到前面描述的内存池策略类__per_type_pool_policy,应用层可能会创建多个支持不同数据类型的内存池,其创建的时机不定,创建的内存池所支持的最大线程数也不定,
当第二次创建的内存池的_M_max_threads 比首次的大时,此时全局链表freelist的线程ID列表已经不够分配,且第二次创建时,freelist可能已经变化很大了,有的线程ID分配出去,有的回收回来。所以这种场景下,重建freelist时很有必要的。
要点3,freelist初始化时,要为其指定key值,__gthread_key_create()为线程私有数据创建key值,实现一键多值,即通过相同的key值,每个线程可以取得各自的不同的私有数据(此为线程ID)。
要点4,freelist链表的重建,_M_old_freelist 和_M_old_array 分别指向旧的freelist的空闲链表和全部链表。通过其差值,可定位到空闲链表的第一个节点,freelist._M_thread_freelist便指向了第一个空闲节点。随后,遍历旧的空闲链表节点,next_id计算
出了下一个要链接的节点下标(下一个空闲的节点,或者是扩容的节点即_M_thread_freelist[freelist._M_max_threads]),_M_old_freelist->_M_id - 1计算出当前节点下标,并让当前节点指向下一节点。这一过程重新指定了_Thread_record数组内成员的链接关系。
为方便理解,举如下例子,假设旧的空闲列表ID为3,5,6,7, _Thread_record数组为1,2,3,4,5,6,7,8,新建的 _Thread_record数组为1,2,3,4,5,6,7,8,9,10。
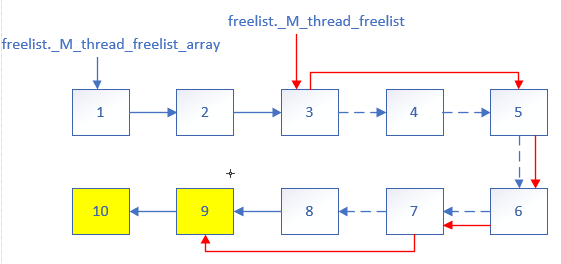
上图描述了整个freelist重建的过程,节点1~10为新建的_Thread_record数组,他们在内存布局上是连续的。相对于旧的freelist,9和10 节点是扩容的节点,红色箭头则表示重建过程中新的链接关系,虚线箭头则为旧的且已失效的链接关系。
最终freelist._M_thread_freelist_array指向新建的_Thread_record数组首地址,freelist._M_thread_freelist指向新建的、第一个空闲的节点的地址。
要点5,根据前面计算的_M_bin_size构建_M_bin数组,类同单线程_M_bin数组的构建,区别是要多构建used和free数组。
要点6,used数组分成两部分,第一部分为每个线程已分配的内存块计数,大小为_M_options._M_max_threads + 1,第二部分为各个线程回收的内存块计数,总大小以为_M_options._M_max_threads + 1。两部分第一个元素都是全局链表的
计数,后面按线程ID排序,是每个线程各自的计数。线程回收内存块时,会根据内存块首部信息的线程ID,得之该内存块是由哪个线程分配,将其第二部分的回收计数更新。
内存块的分配
内存池的分配原则:1,先从本线程空闲链表分出内存块;2,若本线程空闲链表为空,再从全局空闲链表同步内存块到本线程空闲链表,同时分出内存块;3、若全局空闲链表也为空,直接new一块新内存,分到本线程空闲链表上,同时分出
内存块。
1点的处理在mt_allocator的分配函数allocate()内,在后续章节介绍。
_M_reserve_block()函数处理上述2和3点,仅当本线程空闲链表为空时调用。
char* __pool<true>::_M_reserve_block(size_t __bytes, const size_t __thread_id)
{
// 根据申请的字节,计算内存大块所能分割的内存小块的个数
const size_t __which = _M_binmap[__bytes];
const _Tune& __options = _M_get_options();
const size_t __bin_size = ((__options._M_min_bin << __which) + __options._M_align);
size_t __block_count = __options._M_chunk_size - sizeof(_Block_address);
__block_count /= __bin_size; _Bin_record& __bin = _M_bin[__which];
_Block_record* __block = 0;
if (__gthread_active_p())
{
// 要点1,更新used计数器
const size_t __max_threads = __options._M_max_threads + 1;
_Atomic_word* const __reclaimed_base = reinterpret_cast<_Atomic_word*>(__bin._M_used + __max_threads);
const _Atomic_word __reclaimed = __reclaimed_base[__thread_id];
__bin._M_used[__thread_id] -= __reclaimed;
__atomic_add(&__reclaimed_base[__thread_id], -__reclaimed); __gthread_mutex_lock(__bin._M_mutex);
if (__bin._M_first[0] == 0)
{
// 全局空闲链表为空,需要重新向系统申请内存,申请的内存直接放如线程的空闲链表,不放全局链表
// 申请的chunk内存要更新首部信息,并将首部信息与旧的chunk块串联成链表,插入链表头
void* __v = ::operator new(__options._M_chunk_size);
_Block_address* __address = static_cast<_Block_address*>(__v);
__address->_M_initial = __v;
__address->_M_next = __bin._M_address;
__bin._M_address = __address;
__gthread_mutex_unlock(__bin._M_mutex); // 不需加锁,因为更新的是自己线程的空闲链表,这里将申请的chunk块分割并串联成链表结构
char* __c = static_cast<char*>(__v) + sizeof(_Block_address);
__block = reinterpret_cast<_Block_record*>(__c);
__bin._M_free[__thread_id] = __block_count;
__bin._M_first[__thread_id] = __block;
while (--__block_count > 0)
{
__c += __bin_size;
__block->_M_next = reinterpret_cast<_Block_record*>(__c);
__block = __block->_M_next;
}
__block->_M_next = 0;
}
else
{
// 全局空闲链表不为空,将全局链表空闲节点更新到本线程的空闲链表上
__bin._M_first[__thread_id] = __bin._M_first[0];
if (__block_count >= __bin._M_free[0])
{
// 内存块不足__block_count,将全局链表所有内存节点更新过来,改变指向和计数即可
__bin._M_free[__thread_id] = __bin._M_free[0];
__bin._M_free[0] = 0;
__bin._M_first[0] = 0;
}
else
{
// 内存块充足,只从全局链表更新__block_count个内存块,其余保留在全局链表
__bin._M_free[__thread_id] = __block_count;
__bin._M_free[0] -= __block_count;
__block = __bin._M_first[0];
while (--__block_count > 0)
__block = __block->_M_next;
__bin._M_first[0] = __block->_M_next;
__block->_M_next = 0;
}
__gthread_mutex_unlock(__bin._M_mutex);
}
}
else
{
// 不支持多线程,构建方式形如单线程
void* __v = ::operator new(__options._M_chunk_size);
_Block_address* __address = static_cast<_Block_address*>(__v);
__address->_M_initial = __v;
__address->_M_next = __bin._M_address;
__bin._M_address = __address; char* __c = static_cast<char*>(__v) + sizeof(_Block_address);
__block = reinterpret_cast<_Block_record*>(__c);
__bin._M_first[0] = __block;
while (--__block_count > 0)
{
__c += __bin_size;
__block->_M_next = reinterpret_cast<_Block_record*>(__c);
__block = __block->_M_next;
}
__block->_M_next = 0;
} // 取出链表头节点为返回的内存块
__block = __bin._M_first[__thread_id];
__bin._M_first[__thread_id] = __block->_M_next; // 更新计数器,同时内存块要标识线程ID,表示是这个线程申请的内存块
if (__gthread_active_p())
{
__block->_M_thread_id = __thread_id;
--__bin._M_free[__thread_id];
++__bin._M_used[__thread_id];
} return reinterpret_cast<char*>(__block) + __options._M_align;
}
要点1的注释,更新used计数器,通过used数组的第二部分,得知其他线程回收的内存块计数后(再次说明,同一内存块,可能由线程A申请,但由线程B回收),需要更新计数值,第二部分因为涉及多线程访问,所以这里用了__atomic_add
的原子操作,保证线程安全。每次调用_M_reserve_block()函数,都会更新used数值。
内存块的回收
void __pool<true>::_M_reclaim_block(char* __p, size_t __bytes) throw ()
{
// 定位_M_bin结构
const size_t __which = _M_binmap[__bytes];
const _Bin_record& __bin = _M_bin[__which]; char* __c = __p - _M_get_align();
_Block_record* __block = reinterpret_cast<_Block_record*>(__c);
if (__gthread_active_p())
{
const size_t __thread_id = _M_get_thread_id();
const _Tune& __options = _M_get_options(); // 阈值计算,不同大小的内存块链表,其阈值也不同
const size_t __limit = (100 * (_M_bin_size - __which) * __options._M_freelist_headroom); // remove 初步计算,为free * headroom
size_t __remove = __bin._M_free[__thread_id];
__remove *= __options._M_freelist_headroom; const size_t __max_threads = __options._M_max_threads + 1;
_Atomic_word* const __reclaimed_base = reinterpret_cast<_Atomic_word*>(__bin._M_used + __max_threads);
const _Atomic_word __reclaimed = __reclaimed_base[__thread_id]; // __net_used为真正在使用还没回收的内存计数
const size_t __net_used = __bin._M_used[__thread_id] - __reclaimed; // 要点1,当回收个数超过1024时才更新计数器
if (__reclaimed > 1024)
{
__bin._M_used[__thread_id] -= __reclaimed;
__atomic_add(&__reclaimed_base[__thread_id], -__reclaimed);
} // 判断是否要调整,调整的话是调整多少
if (__remove >= __net_used)
__remove -= __net_used;
else
__remove = 0; // 要点2,满足条件才进行空闲链表调整
if (__remove > __limit && __remove > __bin._M_free[__thread_id])
{
// 调整本线程的空闲链表,更新free计数,tmp最终指向要移除的最后一个节点
_Block_record* __first = __bin._M_first[__thread_id];
_Block_record* __tmp = __first;
__remove /= __options._M_freelist_headroom;
const size_t __removed = __remove;
while (--__remove > 0)
__tmp = __tmp->_M_next;
__bin._M_first[__thread_id] = __tmp->_M_next;
__bin._M_free[__thread_id] -= __removed; // 从本线程空闲链表移至全局链表,更新全局链表计数
__gthread_mutex_lock(__bin._M_mutex);
__tmp->_M_next = __bin._M_first[0];
__bin._M_first[0] = __first;
__bin._M_free[0] += __removed;
__gthread_mutex_unlock(__bin._M_mutex);
} // 如果内存块是本线程申请,也是本线程回收,直接更新本线程的used数值,否则向其他线程的used第二部分更新计数(递增回收个数)
if (__block->_M_thread_id == __thread_id)
--__bin._M_used[__thread_id];
else
__atomic_add(&__reclaimed_base[__block->_M_thread_id], 1); // 回收内存块到当前线程空闲链表,并更新free计数
__block->_M_next = __bin._M_first[__thread_id];
__bin._M_first[__thread_id] = __block; ++__bin._M_free[__thread_id];
}
else
{
// 不支持多线程,则回收到全局链表,插入链表头
__block->_M_next = __bin._M_first[0];
__bin._M_first[0] = __block;
}
}
mt_allocator的内存池,对于内存块的回收有一个原则,即不能无限制地把内存块回收至线程的空闲链表。这可能会导致线程的空闲链表大幅增长,而其他线程的空闲链表最终为空,无法分配而重新向系统申请内存。考虑一个场景,多线程应用,其中线程A仅负责
内存块申请,线程B仅负责内存块回收,内存块多线程共享,随着进程不断运行,线程A的空闲内存链表耗尽,再new申请,再耗尽,而线程B的空闲内存链表持续增长。这种设计明显不合理。所以,mt_allocator要求,线程的空闲链表free计数超过used计数的某种比值
条件时,需要将调整空闲链表,将其部分回收至全局链表。这也是前面刚开始Tune._M_freelist_headroom设计的意义所在。
_M_reclaim_block()函数的设计考虑了这点。注意代码注释中的要点2,空闲链表调整要同时满足了两个条件。
条件1,__remove > __limit,__limit对于不同大小的内存块来说,计算结果也不同,可把100 * (_M_bin_size - __which)看成系数a,内存块约大,系数越小,最终结果为a * headroom。而__remove,初始为free * headroom,前面先经过一层判断,
__remove>= net_used。当__remove< net_used,即free < net_used/headroom时,是不需调整的,也就是headroom可以看作used与free的比值。当__remove>= net_used时,最终remove还要减去used,计算出要调整的数值(这个数值乘了headroom,这也是最终调整
过程中__remove除以headroom的原因)。
条件2,__remove > __bin._M_free[__thread_id],可理解为当移除的个数 * headroom 超过空闲链表个数时,才进行调整。
为什么加这两个限定条件,而不是直接if(__remove / headroom > 0)或if(__remove > 0)。我的理解是,要限制空闲链表调整的次数,防止频繁地调整(因为回收到全局链表,全局链表是多线程共享资源,需要加锁,有性能开销)。否则,当free与used比值达到阈
值临界时,后面每回收一个内存块,都会触发一次空闲列表调整,即触发加锁和解锁的动作,产生竞争,导致性能开销。
注释要点1,if (__reclaimed > 1024)的判断,当回收计数超过1024时才进行计数值更新,我的理解也是出于性能考虑,不用每次_M_reclaim_block()接口调用都更新一次计数值。
内存池的资源回收
#ifdef __GTHREADS
void __pool<true>::_M_destroy() throw()
{
if (_M_init && !_M_options._M_force_new)
{
if (__gthread_active_p())
{
for (size_t __n = 0; __n < _M_bin_size; ++__n)
{
_Bin_record& __bin = _M_bin[__n];
while (__bin._M_address)
{
_Block_address* __tmp = __bin._M_address->_M_next;
::operator delete(__bin._M_address->_M_initial);
__bin._M_address = __tmp;
}
::operator delete(__bin._M_first);
::operator delete(__bin._M_free);
::operator delete(__bin._M_used);
::operator delete(__bin._M_mutex);
}
}
else
{
for (size_t __n = 0; __n < _M_bin_size; ++__n)
{
_Bin_record& __bin = _M_bin[__n];
while (__bin._M_address)
{
_Block_address* __tmp = __bin._M_address->_M_next;
::operator delete(__bin._M_address->_M_initial);
__bin._M_address = __tmp;
}
::operator delete(__bin._M_first);
}
}
::operator delete(_M_bin);
::operator delete(_M_binmap);
}
}
多线程内存池资源回收类似单线程内存池,包括映射表的回收和内存单元结构的回收,内存块的回收,还额外多了free和used统计数组,mutex互斥量等。
分配器mt_allocator
前面花了大量篇幅描述了mt_allocator定制的内存池实现细节。现在回到主线mt_allocator的实现上。根据STL空间配置器的实现需求,其必须对外提供allocate()、deallocate()、construct()、destroy()四个接口,分别用于内存分配、回收,对象的构造和析构。allocate()、deallocate()的实现依赖于上述的内存池实现,在了解内存池的实现细节后,allocate()、deallocate()函数将更容易理解。
先看一下mt_allocator的基类实现
template<typename _Tp>
class __mt_alloc_base
{
public:
typedef std::size_t size_type;
typedef std::ptrdiff_t difference_type;
typedef _Tp* pointer;
typedef const _Tp* const_pointer;
typedef _Tp& reference;
typedef const _Tp& const_reference;
typedef _Tp value_type; #if __cplusplus >= 201103L
// _GLIBCXX_RESOLVE_LIB_DEFECTS
// 2103. propagate_on_container_move_assignment
typedef std::true_type propagate_on_container_move_assignment;
#endif pointer
address(reference __x) const _GLIBCXX_NOEXCEPT
{ return std::__addressof(__x); } const_pointer
address(const_reference __x) const _GLIBCXX_NOEXCEPT
{ return std::__addressof(__x); } size_type
max_size() const _GLIBCXX_USE_NOEXCEPT
{ return size_type(-1) / sizeof(_Tp); } #if __cplusplus >= 201103L
template<typename _Up, typename... _Args>
void
construct(_Up* __p, _Args&&... __args)
{ ::new((void *)__p) _Up(std::forward<_Args>(__args)...); } template<typename _Up>
void
destroy(_Up* __p) { __p->~_Up(); }
#else
void
construct(pointer __p, const _Tp& __val)
{ ::new((void *)__p) _Tp(__val); } void
destroy(pointer __p) { __p->~_Tp(); }
#endif
};
__mt_alloc_base基类主要实现了address()、max_size()、construct()、destroy()函数,其细节于STL空间分配器源码分析(一)中关于std::new_allocator配置器的介绍中已描述,此处不做细讲。
重点看下子类__mt_alloc的实现,也就是真正对外使用的空间配置器。
template<typename _Tp, typename _Poolp = __common_pool_policy<__pool, __thread_default> >
class __mt_alloc : public __mt_alloc_base<_Tp>
{
public:
typedef std::size_t size_type;
typedef std::ptrdiff_t difference_type;
typedef _Tp* pointer;
typedef const _Tp* const_pointer;
typedef _Tp& reference;
typedef const _Tp& const_reference;
typedef _Tp value_type;
typedef _Poolp __policy_type;
typedef typename _Poolp::pool_type __pool_type; template<typename _Tp1, typename _Poolp1 = _Poolp>
struct rebind
{
typedef typename _Poolp1::template _M_rebind<_Tp1>::other pol_type;
typedef __mt_alloc<_Tp1, pol_type> other;
};
__mt_alloc() _GLIBCXX_USE_NOEXCEPT { }
__mt_alloc(const __mt_alloc&) _GLIBCXX_USE_NOEXCEPT { } template<typename _Tp1, typename _Poolp1>
__mt_alloc(const __mt_alloc<_Tp1, _Poolp1>&) _GLIBCXX_USE_NOEXCEPT { } ~__mt_alloc() _GLIBCXX_USE_NOEXCEPT { } _GLIBCXX_NODISCARD pointer
allocate(size_type __n, const void* = 0); void
deallocate(pointer __p, size_type __n); const __pool_base::_Tune
_M_get_options()
{
return __policy_type::_S_get_pool()._M_get_options();
} void
_M_set_options(__pool_base::_Tune __t)
{ __policy_type::_S_get_pool()._M_set_options(__t); }
};
mt_allocator接受两个模板参数,一个数据类型_Tp,一个内存池策略类,默认使用__common_pool_policy。__common_pool_policy是个模板类,同样接受两个模板参数,__pool是内存池,__thread_default是多线程标志,支持多线程池时
为true,否则为false。
#ifdef __GTHREADS
#define __thread_default true
#else
#define __thread_default false
#endif
mt_allocator重点看allocate()和deallocate()的实现。
template<typename _Tp, typename _Poolp>
_GLIBCXX_NODISCARD typename __mt_alloc<_Tp, _Poolp>::pointer
__mt_alloc<_Tp, _Poolp>::
allocate(size_type __n, const void*)
{
// 先做校验,申请的字节大小超过支持的最大字节数,直接抛出异常
if (__n > this->max_size())
std::__throw_bad_alloc(); #if __cpp_aligned_new
// 字节对齐处理,满足条件直接使用operator new分配内存,类同std::new_allocator
if (alignof(_Tp) > __STDCPP_DEFAULT_NEW_ALIGNMENT__)
{
std::align_val_t __al = std::align_val_t(alignof(_Tp));
return static_cast<_Tp*>(::operator new(__n * sizeof(_Tp), __al));
}
#endif // 内存池的初始化,主要是建立binmap映射和bin数组,多线程下还要建立_M_thread_freelist,全局静态freelist链表的初始化或重建
__policy_type::_S_initialize_once(); // 这里会检验内存池的_M_max_bytes和_M_force_new,如果超过_M_max_bytes或者_M_force_new为true,则用operator new申请内存
__pool_type& __pool = __policy_type::_S_get_pool();
const size_type __bytes = __n * sizeof(_Tp);
if (__pool._M_check_threshold(__bytes))
{
void* __ret = ::operator new(__bytes);
return static_cast<_Tp*>(__ret);
} // 定位到_M_bin的下标,同时分配线程ID(如果之前未分配的话)
const size_type __which = __pool._M_get_binmap(__bytes);
const size_type __thread_id = __pool._M_get_thread_id(); // 定位到_M_bin结构
char* __c;
typedef typename __pool_type::_Bin_record _Bin_record;
const _Bin_record& __bin = __pool._M_get_bin(__which);
if (__bin._M_first[__thread_id])
{
// 如果本线程的内存块空闲链表非空,直接从空闲链表取内存块返回给应用层
typedef typename __pool_type::_Block_record _Block_record;
_Block_record* __block = __bin._M_first[__thread_id];
__bin._M_first[__thread_id] = __block->_M_next; // 该接口单线程下不做处理,多线程下更新bin的used和free计数,同时更新该内存块的线程ID,标记所属
__pool._M_adjust_freelist(__bin, __block, __thread_id);
__c = reinterpret_cast<char*>(__block) + __pool._M_get_align();
}
else
{
// 空闲链表为空,尝试从全局链表取,或者向系统new申请
__c = __pool._M_reserve_block(__bytes, __thread_id);
}
return static_cast<_Tp*>(static_cast<void*>(__c));
}
allocate()可能调用到了_S_initialize_once()和_M_reserve_block()接口,其具体实现细节已于上面分析。
deallocate()的实现如下
template<typename _Tp, typename _Poolp>
void __mt_alloc<_Tp, _Poolp>::
deallocate(pointer __p, size_type __n)
{
if (__builtin_expect(__p != 0, true))
{
#if __cpp_aligned_new
// 内存对齐处理,满足条件直接调用operator delete回收内存,类同std::new_allocator
if (alignof(_Tp) > __STDCPP_DEFAULT_NEW_ALIGNMENT__)
{
::operator delete(__p, std::align_val_t(alignof(_Tp)));
return;
}
#endif // 请求的块大小超过 _M_max_bytes 直接用operator delete回收,对照之前allocate一样的处理方式,否则调用_M_reclaim_block通过内存池回收
__pool_type& __pool = __policy_type::_S_get_pool();
const size_type __bytes = __n * sizeof(_Tp);
if (__pool._M_check_threshold(__bytes))
::operator delete(__p);
else
__pool._M_reclaim_block(reinterpret_cast<char*>(__p), __bytes);
}
}
deallocate()可能调用_M_reclaim_block(),其回收内存块的细节在内存池一节已介绍。
至此,mt_allocator的绝大部分代码实现都已分析完毕。
STL空间分配器源码分析(二)mt_allocator的更多相关文章
- STL空间分配器源码分析(一)
一.摘要 STL的空间分配器(allocator)定义于命名空间std内,主要为STL容器提供内存的分配和释放.对象的构造和析构的统一管理.空间分配器的实现细节,对于容器来说完全透明,容器不需关注内存 ...
- STL空间分配器源码分析(三)pool_allocator
一.摘要 pool_allocator是一种基于单锁内存池的空间分配器,其内部采用内存池思想,通过构建16个空闲内存块队列,来进行内存的申请和回收处理.每个空闲队列管理的内存块大小固定,且均为8的倍数 ...
- Fresco 源码分析(二) Fresco客户端与服务端交互(1) 解决遗留的Q1问题
4.2 Fresco客户端与服务端的交互(一) 解决Q1问题 从这篇博客开始,我们开始讨论客户端与服务端是如何交互的,这个交互的入口,我们从Q1问题入手(博客按照这样的问题入手,是因为当时我也是从这里 ...
- 框架-springmvc源码分析(二)
框架-springmvc源码分析(二) 参考: http://www.cnblogs.com/leftthen/p/5207787.html http://www.cnblogs.com/leftth ...
- Tomcat源码分析二:先看看Tomcat的整体架构
Tomcat源码分析二:先看看Tomcat的整体架构 Tomcat架构图 我们先来看一张比较经典的Tomcat架构图: 从这张图中,我们可以看出Tomcat中含有Server.Service.Conn ...
- 十、Spring之BeanFactory源码分析(二)
Spring之BeanFactory源码分析(二) 前言 在前面我们简单的分析了BeanFactory的结构,ListableBeanFactory,HierarchicalBeanFactory,A ...
- Vue源码分析(二) : Vue实例挂载
Vue源码分析(二) : Vue实例挂载 author: @TiffanysBear 实例挂载主要是 $mount 方法的实现,在 src/platforms/web/entry-runtime-wi ...
- 多线程之美8一 AbstractQueuedSynchronizer源码分析<二>
目录 AQS的源码分析 该篇主要分析AQS的ConditionObject,是AQS的内部类,实现等待通知机制. 1.条件队列 条件队列与AQS中的同步队列有所不同,结构图如下: 两者区别: 1.链表 ...
- ReactNative 4Android源码分析二: 《JNI智能指针之实现篇》
文/Tamic http://blog.csdn.net/sk719887916/article/details/53462268 回顾 上一篇介绍了<ReactNative4Android源码 ...
随机推荐
- Docker的4种网络模式详细介绍
docker run创建Docker容器时,可以用–net选项指定容器的网络模式,Docker有以下4种网络模式: bridge模式:使用–net =bridge指定: host模式:使用–net = ...
- 6月29日学习总结 Django自带的用户认证
Django自带的用户认证 我们在开发一个网站的时候,无可避免的要设计.实现网站的用户系统.此时我们需要实现包括但不限于用户注册.用户登录.用户认证.注销.修改密码等功能,这还真是个麻烦的事情呢. D ...
- vue学习过程总结(01)- 开发环境的搭建
1.本地vue开发环境的搭建 1.1.下载NodeJs.下载地址:https://nodejs.org/en/download/ node.js的相关结束以及教程:https://www.runoob ...
- Blazor 003 : Razor的基础语法
上文,我们通过剖析一个最简单的 Blazor WASM 项目,讲明白了 Razor 文件是什么,以及它被转译成 C#后长什么样子.也介绍了 Razor 中最简单的一个语法:Razor Expressi ...
- leetcode刷题1--动态规划法回文串2
题目是: Given a string s,partition s such that every substring of the partition is a palindrome Return ...
- Oracle问题解决记录
一.前言 oracle这么一个庞大的东西,出点问题真是太常见了.开个博客,用于记录遇到的问题吧. 持续更新. 二.问题列表 归档日志满,引起的问题. 一台服务器,用了很久了,某天,出现了磁盘空间占满的 ...
- 利用 ps 怎么显示所有的进程? 怎么利用 ps 查看指定进程的信息?
ps -ef (system v 输出)ps -aux bsd 格式输出ps -ef | grep pid
- 是否可以从一个static方法内部调用非static方法?
不可以.静态成员不能调用非静态成员. 非static方法属于对象,必须创建一个对象后,才可以在通过该对象来调用static方法.而static方法调用时不需要创建对象,通过类就可以调用该方法.也就是说 ...
- 什么是Spring的依赖注入?
依赖注入,是IOC的一个方面,是个通常的概念,它有多种解释.这概念是说你不用创建对象,而只需要描述它如何被创建.你不在代码里直接组装你的组件和服务,但是要在配置文件里描述哪些组件需要哪些服务,之后一个 ...
- RabbitMQ踩坑记
之前我们给我们的系统加了一个使用SpringAOP+RabbitMQ+WebSocket进行实时消息通知功能(https://www.cnblogs.com/little-sheep/p/993488 ...