从C过渡到C++——换一个视角深入数组[真的存在高效吗?](2)
从C过渡到C++——换一个视角深入数组[真的存在高效吗?](2)
C风格高效的数组遍历
在过渡到C++之前我还是想谈一谈如何书写高效的C的代码,这里的高效指的是C代码的高效,也就是在不开启编译器优化下,C层级的自由化,编译器优化固然很好,但是源代码的高效远远要胜于编译器的优化,因为在大多数情况下,你并不知道优化器到底干了什么。
数组名和指针
考虑如下声明:
int a;
int b[10];
我们把a通常称为一个标量,因为它是一个单一的值,这个变量的类型是一个整数。我们把变量b称为数组,因为它是一些值的集合。下标和数组名一起使用,用于标识该集合中某个特定的值。但是我们使用的时候都是这样的:
b[1]=10;
我们很少考虑一个问题就是b的类型是什么,我们知道b[1]的类型是一个int,这很好理解,你可能会说b是一整个数组,但实际上在c中并不是这样的,b应该是一个指针常量,且这个指针常量指向数组中第一个元素,为什么这样说呢?
例如我们可以实现如下的操作:
//test1
static int sta_var[]={0};
sta_var[0]++;
int *a = NULL;
a = sta_var;
printf("%d",sta_var);
我们在这里声明了一个指针,然后将数组名付给了它,输出结果如下:
同时上述语句更改为如下以后结果也是相同的:
a = &sta_var[0];
这里需要强调的是,指针和数组名并不是完全相同的,数组具有确定的元素数量,而指针只是一个标量值。编译器用数组名来记住这些属性。只有当数组名在表达式中使用的时候,编译器才会为它产生一个指针常量。
只有在两个场合下,数组名并不用指针常量来表示——当数组作为sizeof操作符或者单目操作符&的操作数的时候,sizeof返回整个数组中的长度,而不是指向数组的指针长度。取一个数组名的地址所产生的是一个指向数组的指针,关于指向数组的指针我们晚点再来讨论。
下标引用与指针
结合上边的讲解我们来看一个比较奇怪的东西:
*(sta_var+3)
首先我们知道sta是一个指针,指向整型,所以3这个值根据整型值的长度进行调整。加法运算的结果是另一个指向整形的指针,它所指向的是数组第一个元素向后移动3个整数长度的位置。其次,间接访问操作符访问这个新位置,或者取得那里的值(整型)。
这个东西由另一个常见的形式:
sta_var[3]
也就是下标引用和间接访问完全相同。
如果二者完全相同那么在运行效率上会有差别吗?我们应该使用哪一个呢?和往常一样,这里没有明确的答案,对于大多数人来说,下标更容易理解,尤其是在多维数组当中。所以在可读性方面,下标具有一定的优势。但这个选择可能会影响运行时的效率。
假设这两种方法都是正确的,下标绝对不会比指针更有效率,但指针有时会比下标更有效率。这也是本篇文章所讨论的内容。
为了理解这个问题,让让我们来研究两个循环:
//loop1
int array[10];
for(int a= 0 ; a< 10 ;a++)
array[a] = 1;
第二个loop:
//loop2
for(int *i=array; i < array+10 ;i++)
*i = 0;
对于第一个循环,为了求取下标的值,编译器在程序中插入指令,取得a的值,并把它与整形的长度相乘(整形长度是4)这个乘法需要花费一定的时间和空间,对于第二个循环, 尽管这里不存在下标,但是还是存在乘法运算,这个乘法运算在于每次for循环更新的时候就是指针i进行变化的时候,i++的时候这个1必须与整形的长度进行相乘然后再与指针相加,但是这个乘法有很大区别,乘法执行的是两个整数,也就是1和4,这个乘法在编译的时候只执行一次,程序在运行的时候直接使用这个4。
这里是默认情况未经过编译器优化的测试结果,我们让每一个循环跑10000000遍,看一看需要多久。
修改后两个代码如下:
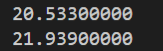
//loop1 21.8792s
start = clock();
for(int j=1;j<10000000;j++)
for(int a= 0 ; a< 1000 ;a++)
array[a] = 1;
stop = clock();
duration = ((double)(stop- start))/CLK_TCK;
printf("%.8f\n",duration);
//loop2
start = clock();
for(int j=1;j<10000000;j++)
{
for(int *i=array; i < array+1000 ;i++)
*i = 1;
}
stop = clock();
duration = ((double)(stop- start))/CLK_TCK;
printf("%.8f\n",duration);
我们在不开启优化的情况下运行时间如下:
我们在开启O优化的情况下:
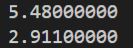
至于这里为什么下边运行效率会高一半我觉得是优化的问题,相同的操作只花费一般的时间,所有开启优化的结果都不能算数。
开启O2优化,就不用说了,他会直接变成0s,因为实际上做的操作是无用功。整个操作都被优化掉了。
我们看看二者的区别在哪里(以下是没有经过优化的代码):
jmp .L5
.L6:
mov eax, DWORD PTR 3916[rbp]
cdqe
mov DWORD PTR -96[rbp+rax*4], 123
add DWORD PTR 3916[rbp], 1
.L5:
cmp DWORD PTR 3916[rbp], 999
jle .L6
使用指针的汇编:
jmp .L5
.L6:
mov rax, QWORD PTR 3912[rbp]
mov DWORD PTR [rax], 123
add QWORD PTR 3912[rbp], 4
.L5:
lea rax, -96[rbp]
add rax, 4000
cmp QWORD PTR 3912[rbp], rax
jb .L6
按照上文的分析我们的数组使用指针效率不应该是更高吗?我们可以看到使用指针的汇编中并没有出现过使用乘法计算的内容:[rbp+rax*4],而是直接使用了4来替代:add QWORD PTR 3912[rbp], 4,那为啥实际上计算时间没有太大差异呢?甚至有些时候指针下标会慢于下标访问呢?
笨蛋的编译器,最重要的原因我觉得就在这里:
.L5:
lea rax, -96[rbp]
add rax, 4000
这里是唯一指针下标多出来的代码。我们的指针并没有将i < array+1000优化掉,即使我们这里所比较的内容是相同的,但是运算的时候为了防止array发生变化,这里又重新计算了一遍加法,也就是说这里在每次循环都要计算一遍加法,这是造成时间变化得最主要原因,所以我们可以这样说这样的写法只能保证:
指针效率≈下标访问的效率
这样的结果是编译器决定的,如果需要查看在某一个机器上的指针运行效率,建议还是查看一下具体的汇编代码,对于一般的for循环我们还是使用下标,这样对于别人来看你的代码的可读性会有很大的提升,如果真的需要大量的遍历或者各种情况,建议使用上文的方法来测量一下运行时间是否真的有一定的进步。
从C过渡到C++——换一个视角深入数组[真的存在高效吗?](2)的更多相关文章
- 从C过渡到C++——换一个视角深入数组[初始化](1)
从C过渡到C++--换一个视角深入数组[初始化](1) 目录 从C过渡到C++--换一个视角深入数组[初始化](1) 数组的初始化 从C入手 作用域 代码块作用域 文件作用域 原型作用域 函数作用域 ...
- 【机器学习基础】——另一个视角解释SVM
SVM的另一种解释 前面已经较为详细地对SVM进行了推导,前面有提到SVM可以利用梯度下降来进行求解,但并未进行详细的解释,本节主要从另一个视角对SVM进行解释,首先先回顾之前有关SVM的有关内容,然 ...
- ytu 1050:写一个函数,使给定的一个二维数组(3×3)转置,即行列互换(水题)
1050: 写一个函数,使给定的一个二维数组(3×3)转置,即行列互换 Time Limit: 1 Sec Memory Limit: 128 MBSubmit: 154 Solved: 112[ ...
- [CareerCup] 13.10 Allocate a 2D Array 分配一个二维数组
13.10 Write a function in C called my2DAlloc which allocates a two-dimensional array. Minimize the n ...
- new一个二维数组
.定义一个二维数组 char **array1 array1 = new char *[x]; for(i=0;i<x;++i) array1[i] = new char[y]; ...用的时候 ...
- 写入数据到Plist文件中时,第一次要创建一个空的数组,否则写入文件失败
#pragma mark - 保存数据到本地Plist文件中 - (void)saveValidateCountWithDate:(NSString *)date count:(NSString *) ...
- [原]Java面试题-输入一个整型数组,找出最大值、最小值,并交换。
[Date]2013-09-19 [Author]wintys (wintys@gmail.com) http://wintys.cnblogs.com [Content]: 1.面试题 输入一个整型 ...
- c语言题目:找出一个二维数组的“鞍点”,即该位置上的元素在该行上最大,在该列上最小。也可能没有鞍点
//题目:找出一个二维数组的“鞍点”,即该位置上的元素在该行上最大,在该列上最小.也可能没有鞍点. // #include "stdio.h" #include <stdli ...
- 如何判断一个变量是数组Array类型
在很多时候,我们都需要对一个变量进行数组类型的判断.JavaScript中如何判断一个变量是数组Array类型呢?我最近研究了一下,并分享给大家,希望能对大家有所帮助. JavaScript中检测对象 ...
随机推荐
- 深入探究MinimalApi是如何在Swagger中展示的
前言 之前看到技术群里有同学讨论说对于MinimalApi能接入到Swagger中感到很神奇,加上Swagger的数据本身是支持OpenApi2.0和OpenApi3.0使得swagger.json成 ...
- Linux切换中英文输入
使用xshell登录Linux服务器后,输入的命令正确但是提示命令不存在,这是什么鬼. 通过移动光标可以发现两种字体的宽度不一样 解决方法 shift + 空格 进行切换
- 树莓派开发笔记(十七):树莓派4B+上Qt多用户连接操作Mysql数据库同步(单条数据悲观锁)
前言 安装了mysq数据库,最终时为了实现在一个树莓派上实现多用户多进程操作的同步问题,避免数据并发出现一些错误,本篇安装了远程服务并且讲述了使用Qt进行悲观锁for update操作,命令行进行 ...
- Javaweb-IDEA 中Maven的操作
1. 在idea中使用Maven 启动idea 创建一个MavenWeb项目 3.等待项目初始化完毕 4. 观察maven仓库中多了哪些东西 5. idea中的maven设置 注意:idea项目创成功 ...
- 我大抵是卷上瘾了,横竖睡不着!竟让一个Bug,搞我两次!
作者:小傅哥 博客:https://bugstack.cn 沉淀.分享.成长,让自己和他人都能有所收获! 一.前言:一个Bug 没想到一个Bug,竟然搞我两次! 我大抵是卷上瘾了,横竖都睡不着,坐起来 ...
- freeswitch拨打分机号
概述 电话语音服务中,有一种稍微复杂的场景,就是总机分机的落地场景,客户拨打总机号码之后,需要再拨打分机号转接到指定的话机. 分机号的拨打一般在总机接通之后,会有语音提示,总机收号之后转接分机. 分机 ...
- 719. 找出第 K 小的数对距离
719. 找出第 K 小的数对距离 这道题其实有那么一点二分猜答案的意思,也有很多类似题目,只不过这道题确实表达的不是很清晰不容易想到,题没问题,我的问题.既然是猜答案,那么二分边界自然就是距离最大值 ...
- Cayley 定理与扩展 Cayley 定理
Cayley 定理 节点个数为 \(n\) 的无根标号树的个数为 \(n^{n−2}\) . 这个结论在很多计数类题目中出现,要证明它首先需要了解 \(\text{Prufer}\) 序列的相关内容. ...
- 【cartographer_ros】五: 发布和订阅陀螺仪Imu信息
上一节介绍了里程计Odometry传感数据的订阅和发布. 本节会介绍陀螺仪Imu数据的发布和订阅.陀螺仪在cartographer中主要用于前端位置预估和后端优化. 目录 1:sensor_msgs/ ...
- 基于.NetCore开发博客项目 StarBlog - (15) 生成随机尺寸图片
系列文章 基于.NetCore开发博客项目 StarBlog - (1) 为什么需要自己写一个博客? 基于.NetCore开发博客项目 StarBlog - (2) 环境准备和创建项目 基于.NetC ...