论文解读(SEP)《Structural Entropy Guided Graph Hierarchical Pooling》
论文信息
论文标题:Structural Entropy Guided Graph Hierarchical Pooling
论文作者:Junran Wu, Xueyuan Chen, Ke Xu, Shangzhe Li
论文来源:2022,ICLR
论文地址:download
论文代码:download
1 Introduction
之前池化的方法大多是 固定比例的池化 或者 基于逐步池化设计的。本文针对上述问题,设计了 SEP 模型,具体来说,在不分配特定于层的压缩配额的情况下,设计了一种全局优化算法来一次生成针对池化的簇分配矩阵。
然后,本文举例说明了以往的方法在重建环图和网格合成图中的局部结构损伤。除 SEP 外,还进一步设计了两个分类模型,SEP-G 和 SEP-N,分别用于图分类和节点分类。结果表明,SEP 在图分类基准上优于最先进的图池方法,并在节点分类上获得了更好的性能。
池化有两种代表性的工作:
- 基于节点丢弃的池化策略:TopKPool、SAGPool、ASAP
- 基于节点聚类的层次池化:DiffPool
本文贡献:
- 我们在以往的分层池工作中发现了阻碍 GNN 发展的两个关键问题,包括由于固定的压缩配额和逐步池设计而造成的局部结构损伤和次优问题。
- 通过引入结构信息理论,我们提出了一种新的分层池化方法,称为SEP,以解决所揭示的问题。
- 我们在图重建、图分类和节点分类任务上广泛地验证了SEP,与SOTA分层池化方法相比,它们的性能更好。
2 Proposed Method
整体框架图示:
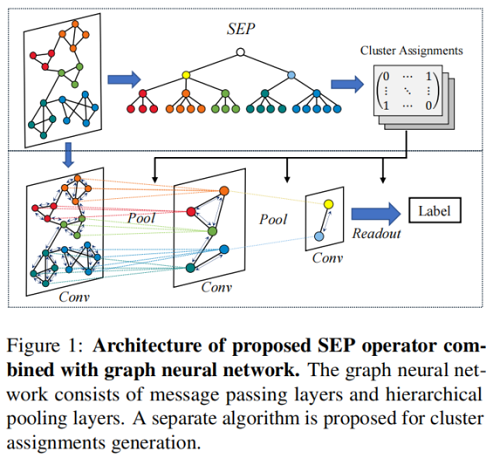
2.1 Preliminaries
$H_{i+1}=\operatorname{Re} L U\left(\tilde{\mathbf{D}}^{-\frac{1}{2}} \tilde{\mathbf{A}} \tilde{\mathbf{D}}^{-\frac{1}{2}} H_{i} W_{i}\right) $
$\mathbf{A}_{i+1}=\mathbf{S}_{i} \mathbf{A}_{i} \mathbf{S}_{i}^{\top} ; \quad \mathbf{P}_{i+1}=\mathbf{S}_{i} H_{i}$
- $\mathbf{A}_{i} \in \mathbb{R}^{n_{i} \times n_{i}}$ 代表第 $i$ 层的邻接矩阵;
- $H_{i} \in \mathbb{R}^{n_{i} \times h}$ 代表第 $i$ 层由 GNN 导出的特征矩阵;
- $\mathbf{P}_{i+1}$ 接收节点隐藏特征 $H_{i}$ 并合并这些特征,以改进新图中 $n_{i+1}$ 簇的初始表示;
2.2 Cluster Assignments via Structural Entropy Minimization
结构熵用来解码图的层次结构,通过结构熵最小化,可以将图的层次结构解码为相应的编码树,使噪声或随机变化产生的干扰最小化。本文认为一种有效的结构熵最小化算法可以揭示层次池化层之间的联系,并消除图中的噪声结构。
编码树 $T$ 上 $G$ 的结构熵的形式化方程可以写为:
${\large \mathcal{H}^{T}(G)=-\sum\limits _{v_{t} \in T} \frac{g_{v_{t}}}{\operatorname{vol}(\mathcal{V})} \log \frac{\operatorname{vol}\left(v_{t}\right)}{\operatorname{vol}\left(v_{t}^{+}\right)}} \quad\quad\quad(3)$
其中,
- $v_{t}$ 是编码树 $T$ 的一个非根节点,同时可以被认为是一个根据编码树 $T$ 划分的节点子集 $\subset \mathcal{V}$;
- $v_{t}^{+}$ 是 $v_{t}$ 的父节点;
- $g_{v_{t}}$ 是指在 $v_{t}$ 的叶节点划分中具有端点的边数;
- $\operatorname{vol}(\mathcal{V})$ 代表 $\mathcal{V}$ 中的叶子节点度的和;
- $\operatorname{vol}\left(v_{t}\right)$ 代表 $v_{t}$ 节点度;
编码树是图的一种自然的层次划分,为了使结构熵最小化 $\mathcal{H}(G)=\min _{\forall T}\left\{\mathcal{H}^{T}(G)\right\}$,本文建立了不同层之间的连接。此外,图中的局部结构将被保留,因为不需要分配图层中特定的节点压缩配额。
首选具有一定高度的自然编码树,因为大多数任务只需要几次固定时间的图粗化。在此背景下,提出了 $G$ 的 $k$ 维结构熵来解码具有固定高度 $k$ 的最优编码树:
$\mathcal{H}^{(k)}(G)= \underset{\forall T: \operatorname{Height}(T)=k}{\text{min}} \left\{\mathcal{H}^{T}(G)\right\} \quad\quad\quad(4)$
本文在 $k$ 维结构熵的指导下,研究了对具有一定高度 $k$ 的编码树进行解密的求解方法。首先,我们定义了三个函数。
Definition 3.1. Let T be any coding tree for graph $G= (\mathcal{V}, \mathcal{E})$, $v_{r}$ is the root node of $T$ and $\mathcal{V}$ are the leaf nodes of $T$ . Given any two nodes $\left(v_{i}, v_{j}\right)$ in $T$ , in which $v_{i} \in v_{r}$.children and $v_{j} \in v_{r}$.children.
Define a function $\operatorname{MERGE}_{T}\left(v_{i}, v_{j}\right)$ for $T$ to insert a new node $v_{\varepsilon}$ between $v_{r}$ and $\left(v_{i}, v_{j}\right)$ :
$\begin{array}{l}v_{\varepsilon} \cdot \text { children } \leftarrow v_{i} \quad\quad\quad(5) \\v_{\varepsilon} \cdot \text { children } \leftarrow v_{j} \quad\quad\quad(6) \\v_{r}. \text { children } \leftarrow v_{\varepsilon} \quad\quad\quad(7) \end{array}$
Definition 3.2. Following the setting in Definition 3.1, given any two nodes $\left(v_{i}, v_{j}\right)$ , in which $v_{i} \in v_{j} .children$.
Define a function $\operatorname{REMOVE}_{T}\left(v_{i}\right)$ for $T$ to remove $v_{i}$ from $T$ and merge $v_{i} .children$ to $v_{j} .chileren$:
$v_{j} \text {.children } \leftarrow v_{i} \text {.children } \quad\quad\quad(8)$
Definition 3.3. Following the setting in Definition 3.1, given any two nodes $\left(v_{i}, v_{j}\right)$ , in which $v_{i} \in v_{j} .children$ and $\mid Heigth \left(v_{j}\right)-H e i g h t\left(v_{i}\right) \mid>1$ .
Define a function $\operatorname{FILL}\left(v_{i}, v_{j}\right)$ for $T$ to insert a new node $v_{\varepsilon}$ between $v_{i}$ and $v_{j}$ :
$\begin{array}{l}v_{\varepsilon} \text {.children } \leftarrow v_{i} ; \quad\quad\quad(9) \\v_{j} \text {.children } \leftarrow v_{\varepsilon} ;\quad\quad\quad(10) \end{array}$
使用上述 3 个 Definition 构造一个 高度为 $k$ 的编码树:

Stage 1: Bottom to top construction —— 从上到下 构造一棵二进制编码树,将根的两个节点和并乘一个新的划分,最大限度的减少结构熵;
Stage 2: Compress $T$ to the certain height $k$ —— 为满足固定数量的图粗化,需要通过删除节点来压缩之前的全高二进制编码树。每次从 $T$ 中选择一个内部节点,这使得 $T$ 在去除该节点后的结构熵变化最小。
Stage 3: Fill T to avoid cross-layer links —— 在第二阶段结束时,已经在结构熵的指导下得到了一个一定高度为 $k$ 的编码树。但是,由于跨层链接,节点在下一层中没有直接后继,这将导致在基于这种编码树实现分层池时节点丢失。因此,我们需要执行第三个阶段,以确保层间信息传输的完整性,也不需要干扰 $G$ 在编码树 $T$ 上的结构熵。
最终,$G$ 的编码树 $T$ 被获得,其中 $T=\left(\mathcal{V}^{T}, \mathcal{E}^{T}\right)$,$\mathcal{V}^{T}=\left(\mathcal{V}_{0}^{T}, \ldots, \mathcal{V}_{k}^{T}\right)$ 和$\mathcal{V}_{0}^{T}=\mathcal{V}$。此外,从 $\mathcal{E}^{T}$ 中也可以得到簇分配矩阵,即 $\mathbb{S}=\left(\mathbf{S}_{1}, \ldots, \mathbf{S}_{k}\right)$。
Proposition 3.4. Let T be a coding tree after the second stage of Algorithm 1, and given two adjacent nodes $\left(v_{i}, v_{j}\right) in T$ , in which $v_{i} \in v_{j} .children$ and $\mid H e i g \operatorname{th}\left(v_{j}\right)- \operatorname{Height}\left(v_{i}\right) \mid>1$ . Then, $\mathcal{H}^{T}(G)=\mathcal{H}^{T_{F IL L\left(v_{i}, v_{j}\right)}} \;\;(G)$.
Proof:
2.3 Graph Neural Network for Graph Classification
图分类框架如下:
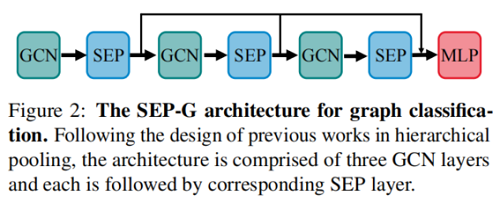
图表示如下:
$h_{G}=\operatorname{Concat}\left(\operatorname{Readout}\left(S E P_{i}\left(G C N_{i}\left(H_{i}, \mathbf{A}_{i}\right), \mathbf{S}_{i}\right)\right)\right.\quad\quad \mid \forall i \in\{1,2,3\})\quad\quad\quad(14)$
Proposition 3.5. Given a permutation matrix $\mathcal{P} \in \{0,1\}^{n \times n}$ , then $\operatorname{SEP}(A, H)=\operatorname{SEP}\left(\mathcal{P} A \mathcal{P}^{\top}, \mathcal{P} H\right)$ (i.e., SEP is permutation invariant).
2.4 Graph Neural Network for Node Classification
节点分类框架如下:
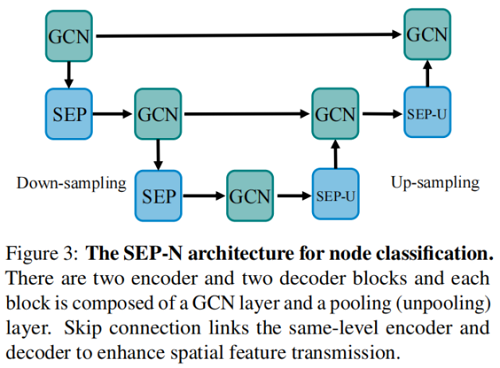
除了将图转换为高级表示的功能外,我们还可以采用相同的矩阵 $S_i$ 来展开压缩图表示 $H_i$,并将 $A_i$ 结构到原始空间:
$\mathbf{A}_{i+1}=\mathbf{S}_{i}^{\top} \mathbf{A}_{i} \mathbf{S}_{i} ; \quad \mathbf{P}_{i+1}=\mathbf{S}_{i}^{\top} H_{i}\quad\quad\quad(15)$
3 Experiments
3.1 Graph Reconstruction
Confifiguration
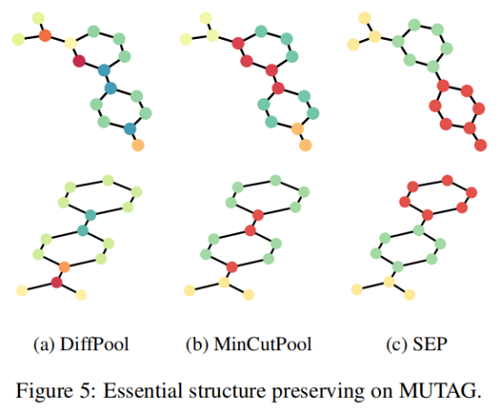
Figure 4 展示了使用原始图和使用不同池化方法重构的图:

我们选择 TopKPool 来表示节点丢弃设计的方法,选择 MinCutPool 来表示节点聚类设计的方法。我们首先注意到 TopKPool 的重建结果,其中原始图的基本形状甚至无法识别。这证实了节点下降方法会导致严重的信息缺失,并意味着节点下降方法在图分类中的性能较差。另一方面,MinCutPool 确实保留了原始图形的基本形状。但是,我们仍然可以看到环的边缘和网格中心的显著扭曲,这代表了环和网格的关键结构,这验证了图中的局部结构会被人为指定的节点压缩配额破坏的假设。相反地,SEP 几乎重建了环,并保留了网格中心的基本结构,这表明我们的池化方法获得了原始图的关键结构信息。
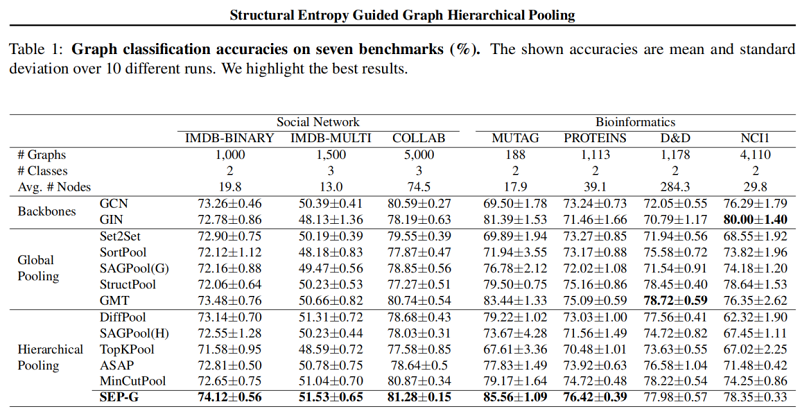
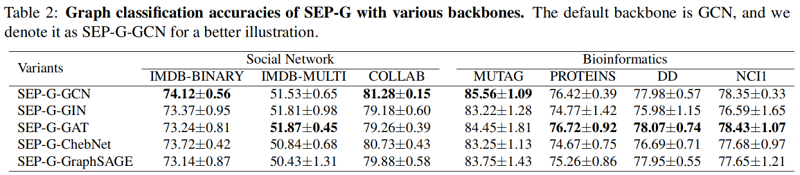
3.2 Graph Classifification
图分类结果:
聚类可视化
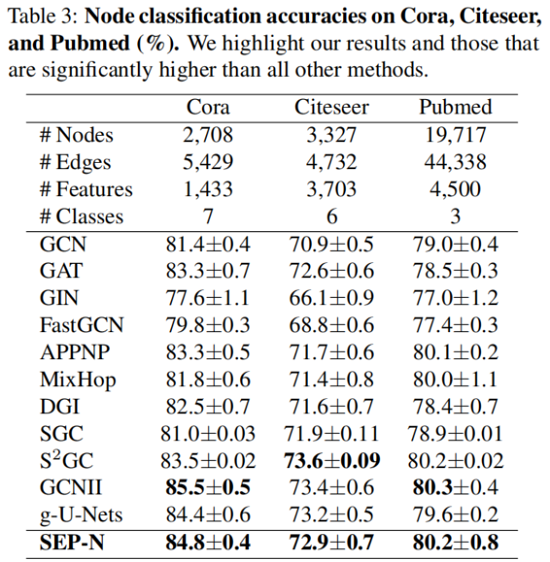
3.3 Node Classification
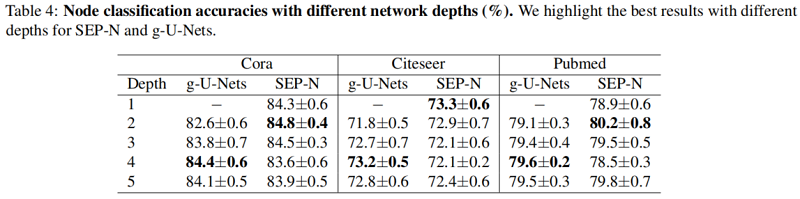
4 Conclusions
在本文中,我们开发了一个优化算法来解决现有的分层池方法的几个局限性。特别是,在结构熵最小化的指导下,我们的池化方法SEP不仅可以捕获池化层之间的连通性,而且还可以解决由于节点压缩的超参数而导致的局部结构破坏的问题。在提出的SEP基础上,我们引入了两种学习模型,SEP-G和SEP-n,分别用于图分类和节点分类。实验结果表明,SEP-G在图分类方面取得了显著的改进,并且SEP-N在节点分类任务上取得了优于其他gnn的性能。结构熵和节点特征的结合是未来工作的一个有趣的方向。
论文解读(SEP)《Structural Entropy Guided Graph Hierarchical Pooling》的更多相关文章
- 论文解读(NWR)《Graph Auto-Encoder via Neighborhood Wasserstein Reconstruction》
论文信息 论文标题:Graph Auto-Encoder via Neighborhood Wasserstein Reconstruction论文作者:Shaked Brody, Uri Alon, ...
- 论文解读(gCooL)《Graph Communal Contrastive Learning》
论文信息 论文标题:Graph Communal Contrastive Learning论文作者:Bolian Li, Baoyu Jing, Hanghang Tong论文来源:2022, WWW ...
- 论文解读 - Composition Based Multi Relational Graph Convolutional Networks
1 简介 随着图卷积神经网络在近年来的不断发展,其对于图结构数据的建模能力愈发强大.然而现阶段的工作大多针对简单无向图或者异质图的表示学习,对图中边存在方向和类型的特殊图----多关系图(Multi- ...
- 论文解读(GMI)《Graph Representation Learning via Graphical Mutual Information Maximization》2
Paper Information 论文作者:Zhen Peng.Wenbing Huang.Minnan Luo.Q. Zheng.Yu Rong.Tingyang Xu.Junzhou Huang ...
- 论文解读(GMI)《Graph Representation Learning via Graphical Mutual Information Maximization》
Paper Information 论文作者:Zhen Peng.Wenbing Huang.Minnan Luo.Q. Zheng.Yu Rong.Tingyang Xu.Junzhou Huang ...
- 论文解读(GRCCA)《 Graph Representation Learning via Contrasting Cluster Assignments》
论文信息 论文标题:Graph Representation Learning via Contrasting Cluster Assignments论文作者:Chun-Yang Zhang, Hon ...
- 论文解读(GCA)《Graph Contrastive Learning with Adaptive Augmentation》
论文信息 论文标题:Graph Contrastive Learning with Adaptive Augmentation论文作者:Yanqiao Zhu.Yichen Xu3.Feng Yu4. ...
- 论文解读(GCC)《Graph Contrastive Clustering》
论文信息 论文标题:Graph Contrastive Clustering论文作者:Huasong Zhong, Jianlong Wu, Chong Chen, Jianqiang Huang, ...
- 论文解读(AGE)《Adaptive Graph Encoder for Attributed Graph Embedding》
论文信息 论文标题:Adaptive Graph Encoder for Attributed Graph Embedding论文作者:Gayan K. Kulatilleke, Marius Por ...
随机推荐
- 物联网无线数传通信模块设备常见的几种Modbus网关
物联网无线数传通信常见的几种Modbus网关 以下提到Modbus网关均指Modbus RTU转Modbus TCP,并不涉及对Modbus ASCII数据帧的处理,Modbus ASCII仅支持透明 ...
- JAVA学习之第一个HelloWorld程序
第一个HelloWorld程序 第一步,创建java类型的文件 第二步,在创建文件的目录中打开cmd窗口 第三步,使用javac 命令将java文件编译为.class类型的字节码文件 第四步,使用ja ...
- 『忘了再学』Shell基础 — 31、字符处理相关命令
目录 1.排序命令sort (1)sort命令介绍 (2)练习 2.取消重复行命令uniq 3.统计命令wc 1.排序命令sort (1)sort命令介绍 sort命令可针对文本文件的内容,以行为单位 ...
- Xilinx DMA的几种方式与架构
DMA是direct memory access,在FPGA系统中,常用的几种DMA需求: 1. 在PL内部无PS(CPU这里统一称为PS)持续干预搬移数据,常见的接口形态为AXIS与AXI,AXI与 ...
- Mac安装Brew包管理系统
Mac安装Brew包管理系统 前言 为什么需要安装brew 作为一个开发人员, 习惯了使用centos的yum和ubuntu的apt, 在mac中有没有这两个工具的平替? 有, 就是Brew. Bre ...
- SAP APO-供需匹配
供需匹配包含主要功能"匹配能力"(CTM)和一个用于分配库存的附加功能. 在高级计划和优化中,SDM组件为这些应用程序提供跨工厂供应策略- 生产计划和详细计划(PP / DS) 供 ...
- 用Python爬取文章,并转PDF格式电子书
wkhtmltopdf [软件],这个是必学准备好的,不然这个案例是实现不出来的 获取文章内容代码 (https://jq.qq.com/?_wv=1027&k=QgGWqAVF) 发送请求, ...
- 飞鱼CRM
直接放干货吧,今日头条飞鱼CRM的PHP调用方法,点我跳转. 很简单的两个方法,加密时重要的是有一个空格,必须要有,这个也是坑了我很长时间的一个坑. 接下来具体说一下飞鱼CRM系统接口加密的方法. & ...
- 动态树 — Link_Cut_Tree
[模板]动态树(Link Cut Tree) Link-cut-tree是一种维护动态森林的数据结构,在需要动态加边/删边的时候就需要LCT来维护. Link-cut-tree的核心是轻重链划分,每条 ...
- 实战模拟│JWT 登录认证
目录 Token 认证流程 Token 认证优点 JWT 结构 JWT 基本使用 实战:使用 JWT 登录认证 Token 认证流程 作为目前最流行的跨域认证解决方案,JWT(JSON Web Tok ...