JVM 系列(4)一看就懂的对象内存布局
请点赞关注,你的支持对我意义重大。
Hi,我是小彭。本文已收录到 GitHub · AndroidFamily 中。这里有 Android 进阶成长知识体系,有志同道合的朋友,关注公众号 [彭旭锐] 带你建立核心竞争力。
前言
Java 中一切皆对象,同时对象也是 Java 编程中接触最多的概念,深入理解 Java 对象能够更帮助我们深入地掌握 Java 技术栈。在这篇文章里,我们将从内存的视角,带你深入理解 Java 对象在虚拟机中的表现形式。
学习路线图:
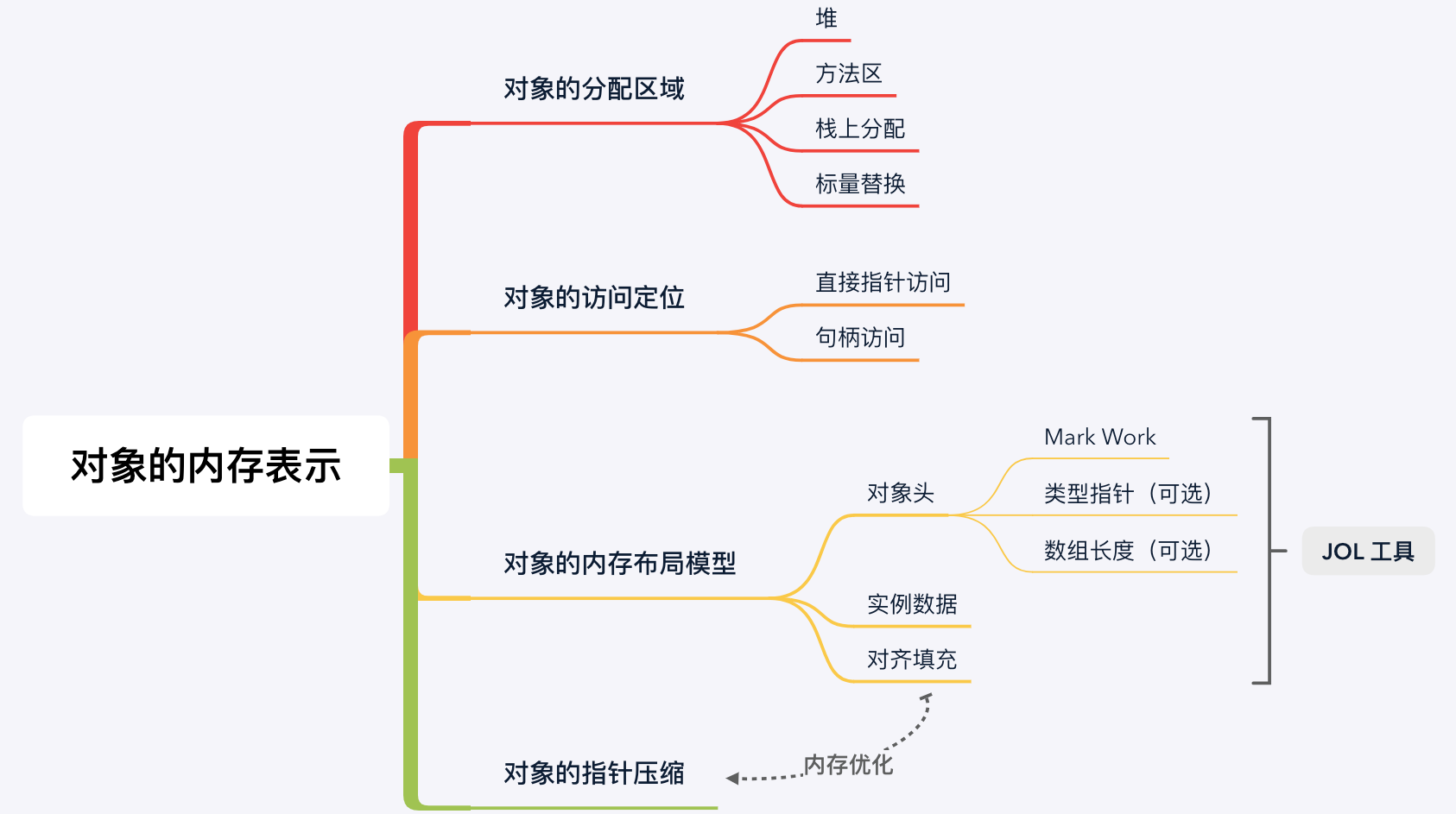
1. 对象在哪里分配?
在 Java 虚拟机中,Java 堆和方法区是分配对象的主要区域,但是也存在一些特殊情况,例如 TLAB、栈上分配、标量替换等。 这些特殊情况的存在是虚拟机为了进一步优化对象分配和回收的效率而采用的特殊策略,可以作为知识储备。
- 1、Java 堆(Heap): Java 堆是绝大多数对象的分配区域,现代虚拟机会采用分代收集策略,因此 Java 堆又分为新生代、老生代和永生代。如果新生代使用复制算法,又可以分为 Eden 区、From Survivor 区和 To Survivor 区。除了这些每个线程都可以分配对象的区域,如果虚拟机开启了 TLAB 策略,那么虚拟机会在堆中为每个线程预先分配一小块内存,称为线程本地分配缓冲(Thread Local Allocation Buffer,TLAB)。在 TLAB 上分配对象不需要同步锁定,可以加快对象分配速度(TLAB 中的对象依然是线程共享读取的,只是不允许其他线程在该区域分配对象);
- 2、方法区(Method Area): 方法区也是线程共享的区域,堆中存放的是生命周期较短的对象,而方法区中存放的是生命周期较长的对象,通常是一些支撑虚拟机执行的必要对象,将两种对象分开存储体现的是动静分离的思想,有利于内存管理。存储在方法区中的数据包括已加载的 Class 对象、静态字段(本质上是 Class 对象中的实例字段,下文会解释)、常量池(例如 String.intern())和即时编译代码等;
- 3、栈上分配(Stack Allocation): 如果 Java 虚拟机通过逃逸分析后判断一个对象的生命周期不会逃逸到方法外,那么可以选择直接在栈上分配对象,而不是在堆上分配。栈上分配的对象会随着栈帧出栈而销毁,不需要经过垃圾收集,能够缓解垃圾收集器的压力。
- 4、标量替换(Scalar Replacement): 在栈上分配策略的基础上,虚拟机还可以选择将对象分解为多个局部变量再进行栈上分配,连对象都不创建。
2. 对象的访问定位
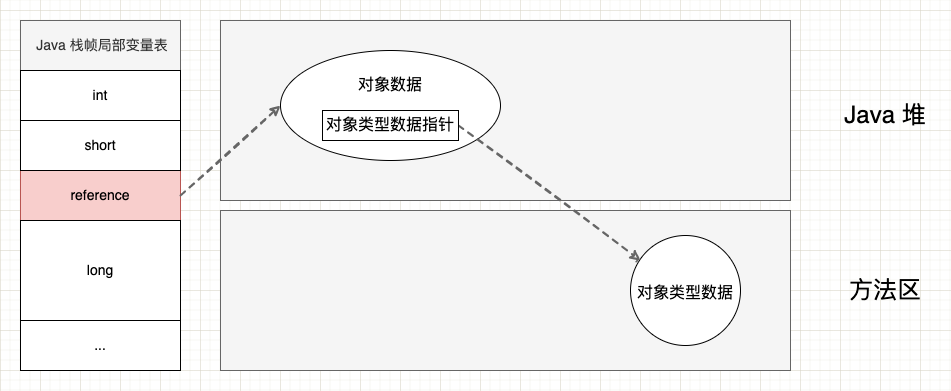
Java 类型分为基础数据类型(int 等)和引用类型(Reference),虽然两者都是数值,但却有本质的区别:基础数据类型本身就代表数据,而引用本身只是一个地址,并不代表对象数据。那么,虚拟机是如何通过引用定位到实际的对象数据呢?具体访问定位方式取决于虚拟机实现,目前有 2 种主流方式:
- 1、直接指针访问: 引用内部持有一个指向对象数据的直接指针,通过该指针就可以直接访问到对象数据。采用这种方式的话,就需要在对象数据中额外使用一个指针来指向对象类型数据;
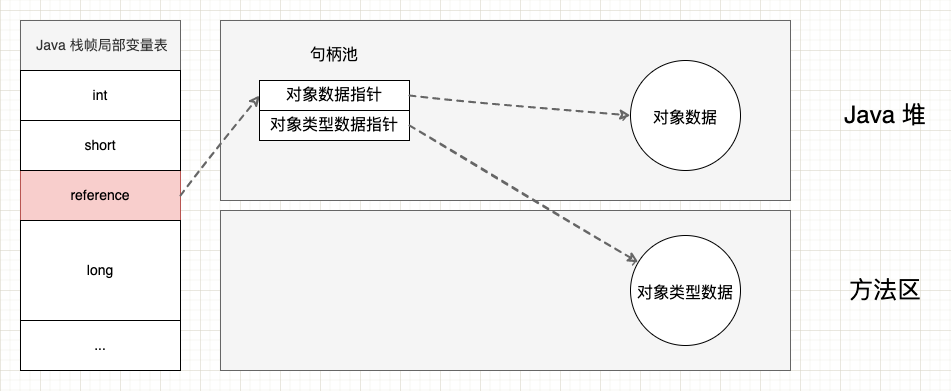
- 2、句柄访问: 引用内部持有一个句柄,而句柄内部持有指向对象数据和类型数据的指针(句柄位于 Java 堆中句柄池)。使用这种方式的话,就不需要在对象数据中记录对象类型数据的指针。
使用句柄的优点是当对象在垃圾收集过程中移动存储区域时,虚拟机只需要改变句柄中的指针,而引用保持稳定。而使用直接指针的优点是只需要一次指针跳转就可以访问对象数据,访问速度相对更快。以 Sun HotSpot 虚拟机而言,采用的是直接指针方式,而 Android ART 虚拟机采用的是句柄方式。
// Android ART 虚拟机源码体现:
// Handles are memory locations that contain GC roots. As the mirror::Object*s within a handle are
// GC visible then the GC may move the references within them, something that couldn't be done with
// a wrap pointer. Handles are generally allocated within HandleScopes. Handle is a super-class
// of MutableHandle and doesn't support assignment operations.
template<class T>
class Handle : public ValueObject {
...
}
直接指针访问:
句柄访问:
关于 Java 引用类型的深入分析,见 引用类型
3. 使用 JOL 分析对象内存布局
这一节我们演示使用 JOL(Java Object Layout) 来分析 Java 对象的内存布局。JOL 是 OpenJDK 提供的对象内存布局分析工具,不过它只支持 HotSpot / OpenJDK 虚拟机,在其他虚拟机上使用会报错:
错误日志
java.lang.IllegalStateException: Only HotSpot/OpenJDK VMs are supported
3.1 使用步骤
现在,我们使用 JOL 分析 new Object() 在 HotSpot 虚拟机上的内存布局,模板程序如下:
示例程序
// 步骤一:添加依赖
implementation 'org.openjdk.jol:jol-core:0.11'
// 步骤二:创建对象
Object obj = new Object();
// 步骤三:打印对象内存布局
// 1. 输出虚拟机与对象内存布局相关的信息
System.out.println(VM.current().details());
// 2. 输出对象内存布局信息
System.out.println(ClassLayout.parseInstance(obj).toPrintable());
输出日志
# Running 64-bit HotSpot VM.
# Using compressed oop with 3-bit shift.
# Using compressed klass with 3-bit shift.
# Objects are 8 bytes aligned.
# Field sizes by type: 4, 1, 1, 2, 2, 4, 4, 8, 8 [bytes]
# Array element sizes: 4, 1, 1, 2, 2, 4, 4, 8, 8 [bytes]
java.lang.Object object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 01 00 00 00 (00000001 00000000 00000000 00000000) (1)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) e5 01 00 f8 (11100101 00000001 00000000 11111000) (-134217243)
12 4 (loss due to the next object alignment)
Instance size: 16 bytes
Space losses: 0 bytes internal + 4 bytes external = 4 bytes total
其中关于虚拟机的信息:
Running 64-bit HotSpot VM.表示运行在 64 位的 HotSpot 虚拟机;Using compressed oop with 3-bit shift.指针压缩(后文解释);Using compressed klass with 3-bit shift.指针压缩(后文解释);Objects are 8 bytes aligned.表示对象按 8 字节对齐(后文解释);Field sizes by type: 4, 1, 1, 2, 2, 4, 4, 8, 8 [bytes]:依次表示引用、boolean、byte、char、short、int、float、long、double 类型占用的长度;Array element sizes: 4, 1, 1, 2, 2, 4, 4, 8, 8 [bytes]:依次表示数组元素长度。
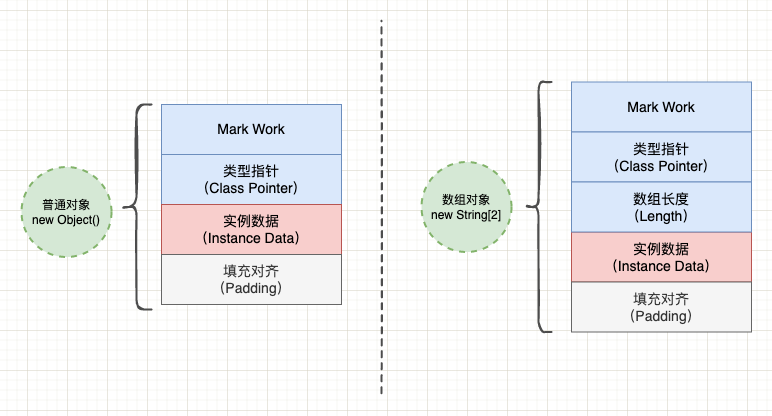
我将 Java 对象的内存布局总结为以下基本模型:
3.2 对象内存布局的基本模型
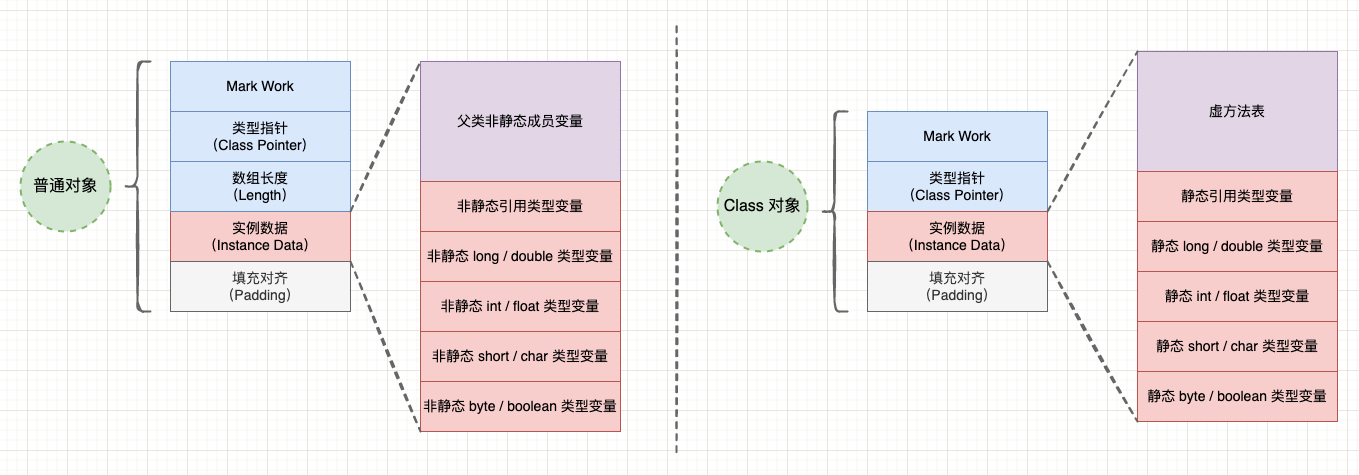
在 Java 虚拟机中,对象的内存布局主要由 3 部分组成:
- 1、对象头(Header): 包括对象的运行时状态信息 Mark Work 和类型指针(直接指针访问方式),数据对象还会记录数组元素个数;
- 2、实例数据(Instance Data): 普通对象的实例数据包括当前类声明的实例字段以及父类声明的实例字段,而 Class 对象的实例数据包括当前类声明的静态字段和方法表等;
- 3、对齐填充(Padding): HotSpot 虚拟机对象的大小必须按 8 字节对齐,如果对象实际占用空间不足 8 字节的倍数,则会在对象末尾增加对齐填充。
关于方法表的作用,见 重载与重写。
4. 对象内存布局详解
这一节开始,我们详细解释对象内存布局的模型。
4.1 对象头(Header)**
- Mark Work: Mark Work 是对象的运行时状态信息,包括哈希码、分代年龄、锁状态、偏向锁信息等。由于 Mark Work 是与对象实例数据无关的额外存储成本,因此虚拟机选择将其设计为带状态的数据结构,会根据对象当前的不同状态而定义不同的含义;
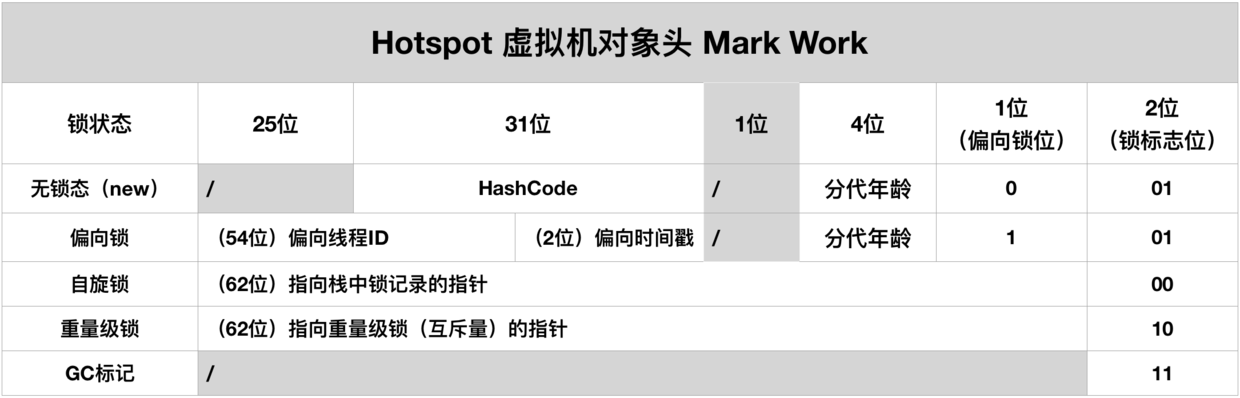
- 类型指针(Class Pointer): 指向对象类型数据的指针,只有虚拟机采用直接指针的对象访问定位方式才需要在对象上记录类型指针,而采用句柄的对象访问定位方式不需要此指针;
- 数组长度: 数组类型的元素长度是不能提前确定的,但在创建对象后又是固定的,所以数组对象的对象头中会记录数组对象中实际元素的个数。
以下演示查看数组对象的对象头中的数组长度字段:
示例程序
char [] str = new char[2];
System.out.println(ClassLayout.parseInstance(str).toPrintable());
输出日志
[C object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 01 00 00 00 (00000001 00000000 00000000 00000000) (1)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) 41 00 00 f8 (01000001 00000000 00000000 11111000) (-134217663)
12 4 (object header) 【数组长度:2】02 00 00 00 (00000010 00000000 00000000 00000000) (2)
16 4 char [C.<elements> N/A
20 4 (loss due to the next object alignment)
Instance size: 24 bytes
Space losses: 0 bytes internal + 4 bytes external = 4 bytes total
可以看到,对象头中有一块 4 字节的区域,显示该数组长度为 2。
4.2 实例数据(Instance Data)
普通对象和 Class 对象的实例数据区域是不同的,需要分开讨论:
- 1、普通对象: 包括当前类声明的实例字段以及父类声明的实例字段,不包括类的静态字段;
- 2、Class 对象: 包括当前类声明的静态字段和方法表等
其中,父类声明的实例字段会放在子类实例字段之前,而字段间的并不是按照源码中的声明顺序排列的,而是相同宽度的字段会分配在一起:引用类型 > long/double > int/float > short/char > byte/boolean。如果虚拟机开启 CompactFields 策略,那么子类较窄的字段有可能插入到父类变量的空隙中。
4.3 对齐填充(Padding)
HotSpot 虚拟机对象的大小必须按 8 字节对齐,如果对象实际占用空间不足 8 字节的倍数,则会在对象末尾增加对齐填充。 对齐填充不仅能够保证对象的起始位置是规整的,同时也是实现指针压缩的一个前提。
5. 什么是指针压缩?
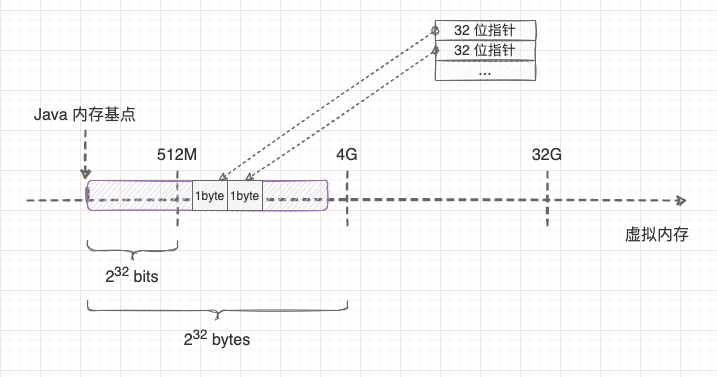
我们都知道 CPU 有 32 位和 64 位的区别,这里的位数决定了 CPU 在内存中的寻址能力,32 位的指针可以表示 4G 的内存空间,而 64 位的指针可以表示一个非常大的天文数字。但是,目前市场上计算机的内存中不可能有这么大的空间,因此 64 位指针中很多高位比特其实是被浪费掉的。 为了提高内存利用效率,Java 虚拟机会采用指针压缩的方式,让 32 位指针不仅可以表示 4G 内存空间,还可以表示略大于 4G (不超过 32 G)的内存空间。这样就可以在使用较大堆内存的情况下继续使用 32 位的指针变量,从而减少程序内存占用。 但是,32 位指针怎么可能表示超过 4G 内存空间?我们把 64 位指针的高 32 位截断之后,剩下的 32 位指针也最多只能表示 4G 空间呀?
在解释这个问题之前,我先解释下为什么 32 位指针可以表示 4G 内存空间呢? 细心的同学会发现,你用 $2^{32}$ 计算也只是得到 512M 而已,那么 4G 是怎么计算出来的呢?其实啊,操作系统中最小的内存分配单位是字节,而不是比特位,操作系统无法按位访问内存,只能按字节访问内存。因此,32 位指针其实是表示 $2^{32}bytes$ ,而不是 $2^{32}bits$,算起来就是 4G 内存空间。
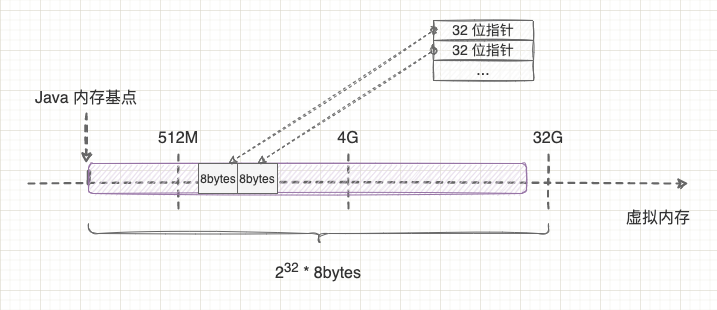
理解了 4G 的计算问题后,再解释 32 位指针如何表示 32G 内存空间就很简单了。 这就拐回到上一节提到的对象 8 字节对齐了。操作系统将 8 个比特位组合成 1 个字节,等于说只需要标记每 8 个位的编号,而 Java 虚拟机在保证对象按 8 字节对齐后,也可以只需要标记每 8 个字节的编号,而不需要标记每个字节的编号。因此,32 位指针其实是表示 $2^{32}*8bytes$,算起来就是 32G 内存空间了。如下图所示:
提示: 在上文使用 JOL 分析对象内存布局时,输入日志
Using compressed oop with 3-bit shift.就表示对象是按 8 字节对齐,指针按 3 位位移。
那对象对齐填充继续放大的话,32 位指针是不是可以表示更大的内存空间了?对。 同理,对齐填充放大到 16 位对齐,则可以表示 64G 空间,放大到 32 位对齐,则可以表示 128G 空间。但是,放大对齐填充等于放大了每个对象的平大小,对齐越大填充的空间会越快抵消指针压缩所减少的空间,得不偿失。因此,Java 虚拟机的选择是在内存空间超过 32G 时,放弃指针压缩策略,而不是一味增大对齐填充。
6. 总结
到这里,对象的内存布局就将完了。我们讲到了对象的分配区域、对象数据的访问定位方式以及对象内部的布局形式。下一篇,我们继续深入挖掘 Java 引用类型的实现原理。关注我,带你建立核心竞争力,我们下次见。
参考资料
- 深入理解 Java 虚拟机(第 3 版)(第 1、3、13 章) —— 周志明 著
- 深入理解 Android:Java 虚拟机 ART(第 8.7 章 · 类的加载、链接和初始化) —— 邓凡平 著
- Java 并发编程的艺术(第 2 章 · Java 并发机制的底层实现原理)—— 方腾飞、魏鹏、程晓明 著
- JVM Anatomy Quark #23: Compressed References —— Aleksey Shipilёv 著
- JVM Anatomy Quark #24: Object Alignment —— Aleksey Shipilёv 著
你的点赞对我意义重大!微信搜索公众号 [彭旭锐],希望大家可以一起讨论技术,找到志同道合的朋友,我们下次见!
享受阳光。

JVM 系列(4)一看就懂的对象内存布局的更多相关文章
- 好文章系列C/C++——图说C++对象模型:对象内存布局详解
注:收藏好文章,得出自己的笔记,以查漏补缺! ------>原文链接:http://blog.jobbole.com/101583/ 前言 本文可加深对C++对象的内存布局.虚表指针.虚 ...
- JVM之对象创建、对象内存布局、对象访问定位
对象创建 类加载过后可以直接确定一个对象的大小 对象栈上分配是通过逃逸分析判定.标量替换实现的,即把不存在逃逸的对象拆散,将成员变量恢复到基本类型,直接在栈上创建若干个成员变量 选择哪种分配方式由Ja ...
- 99.9%的Java程序员都说不清的问题:JVM中的对象内存布局?
本文转载自公众号:石彬的架构笔记,阅读大约需要8分钟. 作者:李瑞杰 目前就职于阿里巴巴,资深 JVM 研究人员 在 Java 程序中,我们拥有多种新建对象的方式.除了最为常见的 new 语句之外,我 ...
- java源码剖析: 对象内存布局、JVM锁以及优化
一.目录 1.启蒙知识预热:CAS原理+JVM对象头内存存储结构 2.JVM中锁优化:锁粗化.锁消除.偏向锁.轻量级锁.自旋锁. 3.总结:偏向锁.轻量级锁,重量级锁的优缺点. 二.启蒙知识预热 开启 ...
- 「每日五分钟,玩转JVM」:对象内存布局
概览 一个对象根据不同情况可以被划分成两种情况,当对象是一个非数组对象的时候,对象头,实例数据,对齐填充在内存中三分天下,而数组对象中在对象头中多了一个用于描述数组对象长度的部分 对象头 对象头分为两 ...
- jvm系列 (二) ---垃圾收集器与内存分配策略
垃圾收集器与内存分配策略 前言:本文基于<深入java虚拟机>再加上个人的理解以及其他相关资料,对内容进行整理浓缩总结.本文中的图来自网络,感谢图的作者.如果有不正确的地方,欢迎指出. 目 ...
- jvm系列 (五) ---类的加载机制
类的加载机制 目录 jvm系列(一):jvm内存区域与溢出 jvm系列(二):垃圾收集器与内存分配策略 jvm系列(三):锁的优化 jvm系列 (四) ---强.软.弱.虚引用 我的博客目录 什么是类 ...
- jvm系列 (五) ---类加载机制
类的加载机制 目录 jvm系列(一):jvm内存区域与溢出 jvm系列(二):垃圾收集器与内存分配策略 jvm系列(三):锁的优化 jvm系列 (四) ---强.软.弱.虚引用 我的博客目录 什么是类 ...
- jvm系列 (一) ---jvm内存区域与溢出
jvm内存区域与溢出 目录 jvm系列(一):jvm内存区域与溢出 jvm系列(二):垃圾收集器与内存分配策略 为什么学习jvm 木板原理,最短的一块板决定一个水的深度,当一个系统垃圾收集成为瓶颈的时 ...
随机推荐
- Vue2-组件通讯传值
Vue2组件通讯传值 方法 Slot插槽--父向子内容分发,子组件只读 mixin混入--定义公共变量或方法,mixin数据不共享,组件中mixin实例互不影响 provide+inject--依赖注 ...
- sqlserver2008 数据库中查询存储过程的的创建修改和执行时间,以及比较常见的系统视图和存储过程
因为各种原因数据库中存在大量无用的存储过程,想查询存储过程的最后执行情况,处理长期不使用的存储过程 下面这条语句可以查询存储过程创建 修改和执行的最后时间: SELECT a.name AS 存储过程 ...
- jeecgboot-vue3笔记(三)弹窗的使用
需求描述 点击按钮,弹窗窗体(子组件),确定后在子组件中完成业务逻辑处理(例如添加记录),然后回调父组件刷新以显示最近记录. 实现步骤 子组件 子组件定义BasicModal <BasicMod ...
- Mysql优化基础之Explain工具
字段解释 id:代表sql中查询语句的序列号,序列号越大则执行的优先级越高,序号一样谁在前谁先执行.id为null则最后执行 select_type:查询类型,表示当前被分析的sql语句的查询的复杂度 ...
- Eclipse for Python开发环境部署
Eclipse for Python开发环境部署 工欲善其事,必先利其器. 对开发人员来说,顺手的开发工具必定事半功倍.自学编程的小白不知道该选择那个开发工具,Eclipse作为一个功能强大且开源免费 ...
- 整数分解、for循环阶乘
整数分解 整数分解是什么呢??我们可以这样理解 我们写一个 3位数求出它的个位十位和百位 . 那么我们来写一个小的测试来看一下! public static void main(String[] ar ...
- SQL Server各版本序列号/激活码/License/秘钥
SQL Server 2019 Enterprise:HMWJ3-KY3J2-NMVD7-KG4JR-X2G8G Enterprise Core:2C9JR-K3RNG-QD4M4-JQ2HR-846 ...
- 使用SSH连接Windows Server 2019 Core
更新记录 本文迁移自Panda666原博客,原发布时间:2021年7月7日. 一.说明 Windows Server 2019 Core,是纯命令行的Windows Server版本,没有办法使用GU ...
- 一款超级好用的3Dmax模型插件 支持模型多格式批量转换
对于模型设计师来说模型格式转换是最常见的事,但是每一款建模软件所支持的格式各有不同,模型互导操作太麻烦 为了解决这个难题,老子云平台研发了一款基于3dmax软件的模型格式转换插件,支持多种模型格式想换 ...
- css做旋转相册效果
css做旋转相册效果 <!DOCTYPE html> <html> <head> <meta charset="UTF-8"> &l ...