用Python绘图(数据分析与挖掘实战)
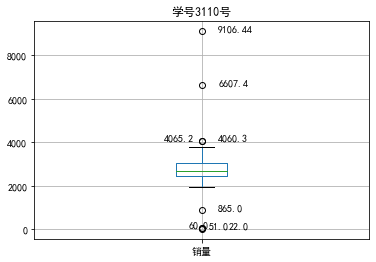
代码1:餐饮日销额数据异常值检测(箱型图)
import pandas as pd
import numpy as np
catering_sale = "D:\\360MoveData\\Users\\86130\\Documents\\Tencent Files\\2268756693\\FileRecv\\catering_sale.xls"
data = pd.read_excel(catering_sale,index_col='日期') #读取数据,指定“日期”列为索引列 print(data.describe()) #使用describe()方法查看数据的基本情况。
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示标签中文
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号 plt.figure() #建立图像
p = data.boxplot(return_type='dict') #画箱型图,直接使用DataFrame的方法
x = p['fliers'][0].get_xdata() #‘flies’为异常值的标签
y = p['fliers'][0].get_ydata()
y.sort() #从小到大排序 for i in range(len(x)):
if i>0:
plt.annotate(y[i],xy=(x[i],y[i]),xytext=(x[i]+0.05-0.8/(y[i]-y[i-1]),y[i]))
else:
plt.annotate(y[i],xy=(x[i],y[i]),xytext=(x[i]+0.08,y[i]))
plt.title('学号3110号')
plt.show()
运行结果如下:
销量
count 200.000000
mean 2755.214700
std 751.029772
min 22.000000
25% 2451.975000
50% 2655.850000
75% 3026.125000
max 9106.440000
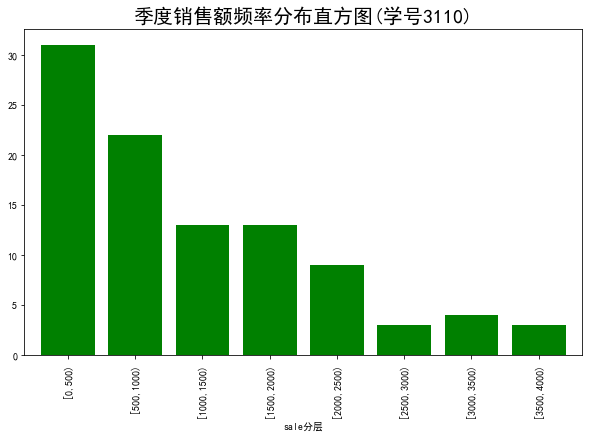
代码2:“捞起生鱼片”的季度销售情况(直方图)
import pandas as pd
import numpy as np
catering_sale = "D:\\360MoveData\\Users\\86130\\Documents\\Tencent Files\\2268756693\\FileRecv\\catering_fish_congee.xls" # 餐饮数据
data = pd.read_excel(catering_sale,names=['date','sale']) # 读取数据,指定“日期”列为索引 bins = [0,500,1000,1500,2000,2500,3000,3500,4000]
labels = ['[0,500)','[500,1000)','[1000,1500)','[1500,2000)',
'[2000,2500)','[2500,3000)','[3000,3500)','[3500,4000)'] data['sale分层'] = pd.cut(data.sale, bins, labels=labels)#cut:分层标记
print(data)
aggResult = data.groupby(by=['sale分层'])['sale'].agg([('sale',np.size)])#groupby:分组函数,可以实现分组操作和组内运算。
print(aggResult)
pAggResult = round(aggResult/aggResult.sum(), 2, ) * 100#round()是python自带的一个函数,用于数字的四舍五入。格式:round(number,digits)
print(pAggResult) import matplotlib.pyplot as plt
plt.figure(figsize=(10,6)) # 设置图框大小尺寸
pAggResult['sale'].plot(kind='bar',width=0.8,fontsize=10,color='g') # 绘制频率直方图
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.title('季度销售额频率分布直方图(学号3110)',fontsize=20)
plt.show()
运行结果如下:
date sale sale分层
0 2014-04-02 900 [500,1000)
1 2014-04-03 1290 [1000,1500)
2 2014-04-04 420 [0,500)
3 2014-04-05 1710 [1500,2000)
4 2014-04-06 1290 [1000,1500)
.. ... ... ...
85 2014-06-26 840 [500,1000)
86 2014-06-27 840 [500,1000)
87 2014-06-28 1350 [1000,1500)
88 2014-06-29 1260 [1000,1500)
89 2014-06-30 2700 [2500,3000) [90 rows x 3 columns]
sale
sale分层
[0,500) 28
[500,1000) 20
[1000,1500) 12
[1500,2000) 12
[2000,2500) 8
[2500,3000) 3
[3000,3500) 4
[3500,4000) 3
sale
sale分层
[0,500) 31.0
[500,1000) 22.0
[1000,1500) 13.0
[1500,2000) 13.0
[2000,2500) 9.0
[2500,3000) 3.0
[3000,3500) 4.0
[3500,4000) 3.0
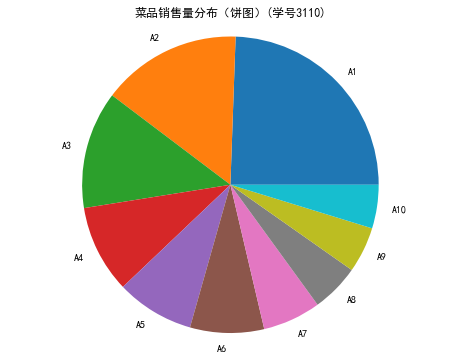
代码3:不同菜品在某段时间的销售量分布情况(饼图)(条形图)
import pandas as pd
import matplotlib.pyplot as plt
catering_dish_profit = "D:\\360MoveData\\Users\\86130\\Documents\\Tencent Files\\2268756693\\FileRecv\\catering_dish_profit.xls"
data = pd.read_excel(catering_dish_profit) #读取数据
print(data.describe())
'''describe() 函数可以查看数据的基本情况,
包括:
count 非空值数、
mean 平均值、
std 标准差、
max 最大值、
min 最小值、
(25%、50%、75%)分位数等。
''' #绘制饼图
x = data['盈利']
labels = data['菜品名']
plt.figure(figsize=(8,6)) #设置画布大小
plt.pie(x,labels=labels) #绘制饼图
plt.rcParams['font.sans-serif'] = 'SimHei'# 添加这条可以让图形显示中文
plt.title('菜品销售量分布(饼图)(学号3110)')
plt.axis('equal')
plt.show()
运行结果如下:
菜品ID 盈利
count 10.000000 10.000000
mean 5547.200000 3753.500000
std 8050.908586 2303.124508
min 14.000000 1782.000000
25% 111.000000 2072.000000
50% 411.500000 3110.500000
75% 13578.000000 4506.750000
max 17154.000000 9173.000000
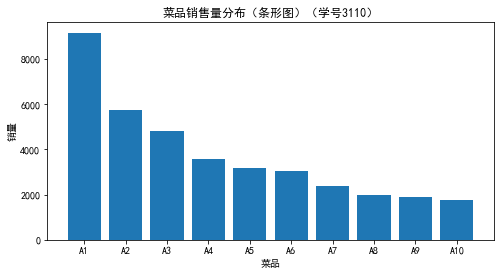
#绘制条形图
x = data['菜品名']
y = data['盈利']
plt.figure(figsize=(8,4))
plt.bar(x,y)
plt.rcParams['font.sans-serif'] = 'SimHei'# 添加这条可以让图形显示中文
plt.xlabel('菜品')
plt.ylabel('销量')
plt.title('菜品销售量分布(条形图)(学号3110)')
plt.show()
运行结果如下:
代码4:不同部门各月份的销售对比情况
#部门之间销售金额比较
import pandas as pd
import matplotlib.pyplot as plt
data=pd.read_excel("D:\\360MoveData\\Users\\86130\\Documents\\Tencent Files\\2268756693\\FileRecv\\dish_sale.xls")
print(data.describe()) plt.figure(figsize=(8,4))
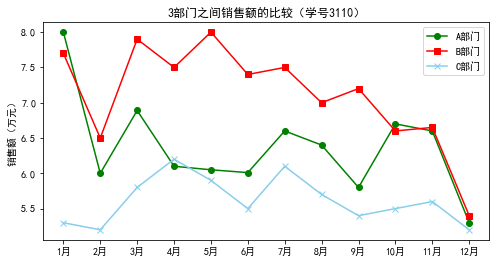
plt.plot(data['月份'],data['A部门'],color='green',label='A部门',marker='o')
plt.plot(data['月份'],data['B部门'],color='red',label='B部门',marker='s')
plt.plot(data['月份'],data['C部门'],color='skyblue',label='C部门',marker='x')
plt.legend()
plt.ylabel('销售额(万元)')
plt.title('3部门之间销售额的比较(学号3110)')
plt.show()
运行结果如下:
A部门 B部门 C部门
count 12.000000 12.000000 12.000000
mean 6.370833 7.112500 5.616667
std 0.677864 0.734886 0.332575
min 5.300000 5.400000 5.200000
25% 6.007500 6.637500 5.375000
50% 6.250000 7.300000 5.550000
75% 6.625000 7.550000 5.825000
max 8.000000 8.000000 6.200000
#B部门各年份之间销售额的比较
data=pd.read_excel("D:\\360MoveData\\Users\\86130\\Documents\\Tencent Files\\2268756693\\FileRecv\\dish_sale_b.xls")
plt.figure(figsize=(8,4))
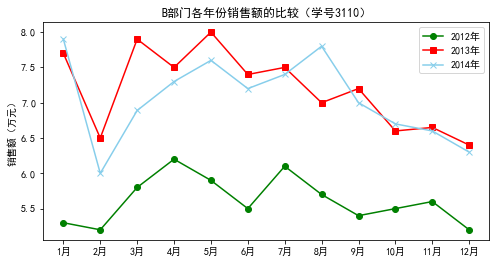
plt.plot(data['月份'],data['2012年'],color='green',label='2012年',marker='o')
plt.plot(data['月份'],data['2013年'],color='red',label='2013年',marker='s')
plt.plot(data['月份'],data['2014年'],color='skyblue',label='2014年',marker='x')
plt.legend()
plt.ylabel('销售额(万元)')
plt.title('B部门各年份销售额的比较(学号3110)')
plt.show()
运行结果如下:
代码5:餐饮销量数据统计量分析
import pandas as pd catering_sale="D:\\360MoveData\\Users\\86130\\Documents\\Tencent Files\\2268756693\\FileRecv\\catering_sale.xls"
data = pd.read_excel(catering_sale,index_col='日期') data = data[(data['销量'] > 400)&(data['销量'] < 5000)] #过滤异常数据
statistics = data.describe() #保存基本统计量 statistics.loc['range'] = statistics.loc['max']-statistics.loc['min'] #极差
statistics.loc['var'] = statistics.loc['std']/statistics.loc['mean'] #变异系数
statistics.loc['dis'] = statistics.loc['75%']-statistics.loc['25%'] #四分位数间距 print(statistics)
运行结果如下:
销量
count 195.000000
mean 2744.595385
std 424.739407
min 865.000000
25% 2460.600000
50% 2655.900000
75% 3023.200000
max 4065.200000
range 3200.200000
var 0.154755
dis 562.600000
代码6:某单位日用电量预测分析(时序图)
import pandas as pd
import matplotlib.pyplot as plt #正常用户电量趋势分析
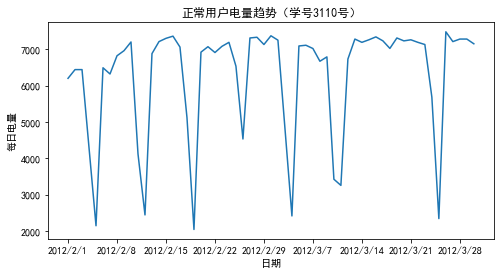
df_normal = pd.read_csv("D:\\360MoveData\\Users\\86130\\Documents\\Tencent Files\\2268756693\\FileRecv\\user.csv")
plt.figure(figsize=(8,4))
plt.plot(df_normal["Date"],df_normal["Eletricity"])
plt.xlabel("日期") x_major_locator = plt.MultipleLocator(7) #设置x轴刻度间隔
ax = plt.gca()
ax.xaxis.set_major_locator(x_major_locator)
plt.ylabel("每日电量")
plt.title("正常用户电量趋势(学号3110号)")
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.show #窃电用户用电趋势分析
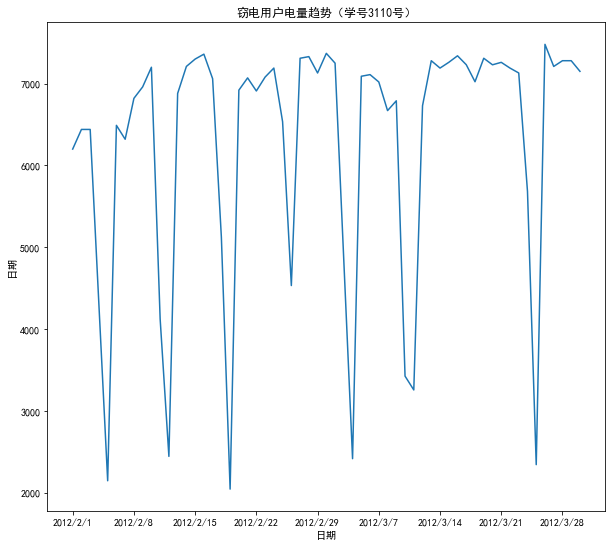
df_steal = pd.read_csv("D:\\360MoveData\\Users\\86130\\Documents\\Tencent Files\\2268756693\\FileRecv\\user.csv")
plt.figure(figsize=(10,9))
plt.plot(df_steal["Date"],df_steal["Eletricity"])
plt.xlabel("日期")
plt.ylabel("日期") x_major_locator = plt.MultipleLocator(7) #设置x轴刻度间隔
ax = plt.gca()
ax.xaxis.set_major_locator(x_major_locator)
plt.title("窃电用户电量趋势(学号3110号)")
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.show
运行结果如下:
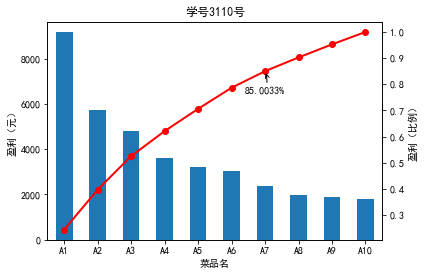
代码7:绘制菜品盈利数据帕累托图
#菜品盈利数据帕累托图
from __future__ import print_function
import pandas as pd #初始化参数
dish_profit = "D:\\360MoveData\\Users\\86130\\Documents\\Tencent Files\\2268756693\\FileRecv\\catering_dish_profit.xls"#餐饮菜品盈利数据
data = pd.read_excel(dish_profit, index_col = u'菜品名')
data = data[u'盈利'].copy()
data.sort_values(ascending = False) import matplotlib.pyplot as plt #导入图像库
plt.rcParams['font.sans-serif'] = ['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False #用来正常显示负号 plt.figure()
data.plot(kind='bar')
plt.ylabel(u'盈利(元)')
p = 1.0*data.cumsum()/data.sum()
p.plot(color = 'r', secondary_y = True, style = '-o',linewidth = 2)
plt.annotate(format(p[6], '.4%'), xy = (6, p[6]), xytext=(6*0.9, p[6]*0.9), arrowprops=dict(arrowstyle="->", connectionstyle="arc3,rad=.2")) #添加注释,即85%处的标记。这里包括了指定箭头样式。
plt.ylabel(u'盈利(比例)')
plt.title('学号3110号')
plt.show()
运行结果如下:
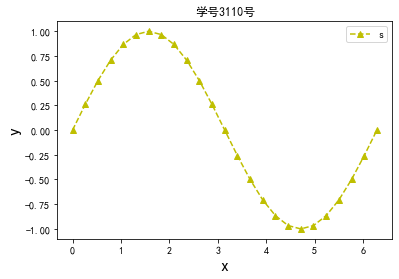
代码8:绘制一条正弦虚线
import pandas as pd
import numpy as np
x=np.linspace(0,2*np.pi,25,endpoint=True)#范围是0~2π,25为点数
s=np.sin(x) #计算对应x的正弦值
plt.figure()
plt.plot(x,s,'y--^',)#控制图形格式为黄色带^虚线
plt.xlabel("x",fontdict={'size':16})
plt.ylabel("y",fontdict={'size':16})
plt.legend("sin(x)")
plt.title('学号3110号')
plt.show()
运行结果如下:
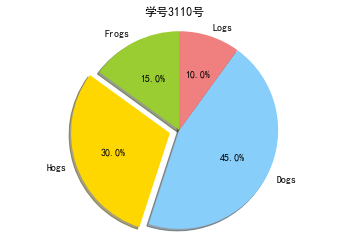
代码9:绘制饼图
#绘制饼图
import matplotlib.pyplot as plt
labels = 'Frogs','Hogs','Dogs','Logs' #定义标签
sizes = [15,30,45,10] #每一块的比例
colors = ['yellowgreen','gold','lightskyblue','lightcoral'] #每一块的颜色
explode = (0,0.1,0,0) #突出显示,这里仅仅突出显示第二块(即Hogs) plt.pie(sizes,explode=explode,labels=labels,colors=colors,autopct='%1.1f%%',shadow=True,startangle=90)
plt.axis('equal') #显示为圆(避免比例压缩为椭圆)
plt.title('学号3110号')
plt.show()
运行结果如下:
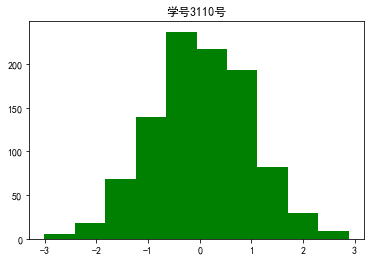
代码10:绘制二维条形直方图
import matplotlib.pyplot as plt
import numpy as np
x = np.random.randn(1000) #1000个服从正态分布的随机数
plt.hist(x,10,color='g') #分成10组绘制直方图,颜色为绿色
plt.title('学号3110号')
plt.show
运行结果如下:
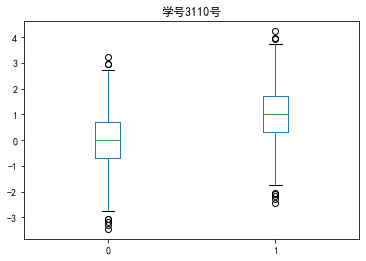
代码11:绘制箱型图
#绘制箱型图
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
x = np.random.randn(1000) #1000个服从正态分布的随机数
D = pd.DataFrame([x,x+1]).T #构造两列的DataFrame
D.plot(kind='box') #调用Series内置的绘图方法绘图,用kind参数指定箱型图(box)
plt.title('学号3110号')
plt.show()
运行结果如下:
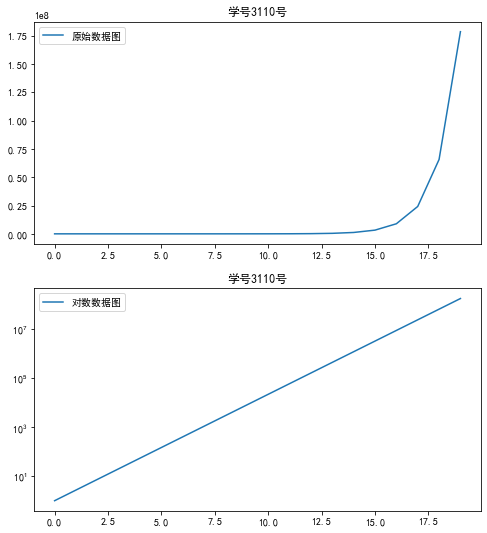
代码12:使用plot(logy=True)函数进行绘图
#绘制y轴的对数图形的对比图
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False #用来正常显示负号
import numpy as np
import pandas as pd x = pd.Series(np.exp(np.arange(20)))
plt.figure(figsize=(8,9)) #设置画布大小
ax1 = plt.subplot(2,1,1)
x.plot(label='原始数据图',legend=True)
plt.title('学号3110号') ax1 = plt.subplot(2,1,2)
x.plot(logy=True,label='对数数据图',legend=True)
plt.title('学号3110号')
plt.show()
运行结果如下:
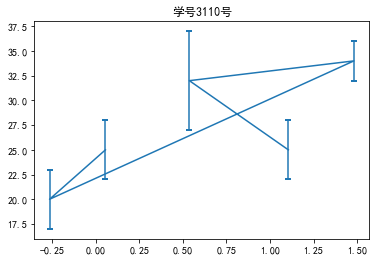
代码13:绘制误差棒图
# 使用pyplot的errorbar()函数可以快速绘制误差棒图,errorbar()函数的语法格式如下所示:
# errorbar(x,y, yerr=None, xerr=None, fmt='', ecolor=None,
# elinewidth=None, capsize=None, barsabove=False, lolims=False,
# uplims=False, xlolims=False, xuplims=False, errorevery=1,
# capthick=None, *, data=None, **kwargs) # 该函数常用参数的含义如下。
# ·x,y:表示数据点的位置。
# ·xerr,yerr:表示数据的误差范围。
# ·fmt:表示数据点的标记样式和数据点之间连接线的样式。
# ·ecolor:表示误差棒的线条颜色。
# ·elinewidth:表示误差棒的线条宽度。
# ·capsize:表示误差棒边界横杆的大小。
# ·capthick:表示误差棒边界横杆的厚度。 # 使用errorbar()函数绘制一个误差棒图,代码如下。 import numpy as np
import matplotlib.pyplot as plt
x = np.random.randn(5)
y = (25, 32, 34, 20, 25)
y_offset = (3, 5, 2, 3, 3)
plt.errorbar(x, y, yerr=y_offset, capsize=3, capthick=2)
plt.title('学号3110号')
plt.show() #绘制误差棒图
# import matplotlib.pyplot as plt
# plt.rcParams['font.sans-serif'] = ['SimHei'] #用来正常显示中文标签
# plt.rcParams['axes.unicode_minus'] = False #用来正常显示负号
# import numpy as np
# import pandas as pd # error = np.random.randn(10) #定义误差列
# y = pd.Series(np.sin(np.arange(10))) #均值数据列
# y.plot(yerr=error) #绘制误差图
# plt.title('学号10号')
# plt.show()
运行结果如下:
总结:
在数据可视化中,我们主要使用pandas作为数据探索和分析工具,通常绘图工具都是Matplotlib和pandas结合使用。一方面,Matplotlib是绘图工具的基础,pandas绘图依赖于它;另一方面,pandas绘图有着简单直接的优势,因此,两者互相结合,往往能够以最高的效率做出符合我们需要的图。
用Python绘图(数据分析与挖掘实战)的更多相关文章
- 【读书笔记与思考】《python数据分析与挖掘实战》-张良均
[读书笔记与思考]<python数据分析与挖掘实战>-张良均 最近看一些机器学习相关书籍,主要是为了拓宽视野.在阅读这本书前最吸引我的地方是实战篇,我通读全书后给我印象最深的还是实战篇.基 ...
- 学习参考《Python数据分析与挖掘实战(张良均等)》中文PDF+源代码
学习Python的主要语法后,想利用python进行数据分析,感觉<Python数据分析与挖掘实战>可以用来学习参考,理论联系实际,能够操作数据进行验证,基础理论的内容对于新手而言还是挺有 ...
- python数据分析与挖掘实战
<python数据分析与挖掘实战>PDF&源代码&张良均 下载:链接:https://pan.baidu.com/s/1TYb3WZOU0R5VbSbH6JfQXw提取码: ...
- python 数据分析与挖掘实战01
python 数据分析与挖掘实战 day 01 08/02 这种从数据中"淘金",从大量数据包括文本中挖掘出隐含的.未知的.对决策有潜在价值关系.模式或者趋势,并用这些知识和规则建 ...
- python数据分析与挖掘实战第二版pdf-------详细代码与实现
[书名]:PYTHON数据分析与挖掘实战 第2版[作者]:张良均,谭立云,刘名军,江建明著[出版社]:北京:机械工业出版社[时间]:2020[页数]:340[isbn]:9787111640028 学 ...
- 《MATLAB数据分析与挖掘实战》赠书活动
<MATLAB数据分析与挖掘实战>是泰迪科技在数据挖掘领域探索10余年经验总结与华南师大.韩山师院.广东工大.广技师 等高校资深讲师联合倾力打造的巅峰之作.全书以实践和实用为宗旨,深度 ...
- R学习:《R语言数据分析与挖掘实战》PDF代码
分三个部分:基础篇.实战篇.提高篇.基础篇介绍了数据挖掘的基本原理,实战篇介绍了一个个真实案例,通过对案例深入浅出的剖析,使读者在不知不觉中通过案例实践获得数据挖掘项目经验,同时快速领悟看似难懂的数据 ...
- 《Python数据分析与挖掘实战》读书笔记
大致扫了一遍,具体的代码基本都没看了,毕竟我还不懂python,并且在手机端的排版,这些代码没法看. 有收获,至少了解到以下几点: 一. Python的语法挺有意思的 有一些类似于JavaSc ...
- 《Python数据分析与挖掘实战》-第四章-数据预处理
点我看原版
- python数据分析与挖掘实战————银行分控模型(几种算法模型的比较)
一.神经网络算法: 1 import pandas as pd 2 from keras.models import Sequential 3 from keras.layers.core impor ...
随机推荐
- python-py文件打包成exe可执行文件
方法一::打包完成后可以直接被他人使用,他人不用安装python环境的 可以使用pyinstaller模块实现将python项目打包成exe执行文件 """ 先安装模块 ...
- day33 过滤器filter & 监听器listener & 利用反射创建BaseServlet实现调用自定义业务方法
Filter过滤器 Fileter可以实现: 1)客户端的请求访问servlet之前拦截这些请求,对用户请求进行预处理 2)对HttpServletResponse进行后处理: 注意 多个Filter ...
- day32 6 请求转发与重定向的区别、session会话对象 & cookie & 8 应用程序上下文对象ServletContext & 5 请求转发与jsp页面内置对象
1 请求转发与重定向的区别 2 session与cookie的区别 3 过滤器与监听器的区别 4 web-inf目录 web-inf目录是安全目录,无法从客户端访问,只能通过(服务端的)servlet ...
- MySQL进阶实战1,数据类型与三范式
一.选择优化的数据类型 MySQL支持的数据类型非常多,选择正确的数据类型对于获得高性能至关重要. 1.更小的 一般情况下,应该尽量使用较小的数据类型,更小的数据类型通常更快,因为占用更少的磁盘.内存 ...
- editorial 专栏
社论 22.10.1 solution for pl_er 密码是我的名字的拼音 全小写无空格 社论 22.10.2 solution for Simu. 密码是联考密码 社论 22.10.4 sol ...
- Java反射与安全问题
1.Java反射机制 Java反射机制是指在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法:对于任意一个对象,都能够调用它的任意一个方法和属性:这种动态获取的信息以及动态调用对象的方法的 ...
- TypeScript 之 Type
Type 描述:全称叫做 '类型别名',为类型字面量提供名称.比 Interface 支持更丰富的类型系统特性. Type 与 Interface 区别 Interface 只能描述对象的形状,Typ ...
- Django框架三板斧本质-jsonResponse对象-form表单上传文件request对象方法-FBV与CBV区别
目录 一:视图层 2.三板斧(HttpResponse对象) 4.HttpResponse() 5.render() 6.redirect() 7.也可以是一个完整的URL 二:三板斧本质 1.Dja ...
- Mqttnet内存与性能改进录
1 MQTTnet介绍 MQTTnet是一个高性能的 .NET MQTT库,它提供MQTT客户端和MQTT服务器的功能,支持到最新MQTT5协议版本,支持.Net Framework4.5.2版本或以 ...
- 基于.NetCore开发博客项目 StarBlog - (23) 文章列表接口分页、过滤、搜索、排序
前言 上一篇留的坑,火速补上. 在之前的第6篇中,已经有初步介绍,本文做一些补充,已经搞定这部分的同学可以快速跳过,基于.NetCore开发博客项目 StarBlog - (6) 页面开发之博客文章列 ...