cs231n__2. K-nearest Neighbors
CS231n
2 K-Nearest Neighbors note ---by Orangestar
1. codes:
import numpy as np
class NearestNeighbor:
def __init__(self):
pass
def train(self, X, y):
"""X is N × D where each row is an example.
Y is l-dimension of size N """
# the nearest neighbor classifier simply remembers all the training data
self.Xtr = X
self.ytr = y
def predict(self, X):
"""X is N × D where each row is an example we wish to predict label for"""
num_test = X.shape[0]
# lets make sure that the output type matches the input type
Tpred = np.zeros(num.test, dtype = self.ytr.dtype)
# loop over all test rows
for i in xrange(num_test):
# find the nearest training image to the i'th test image
# using the L1 distance (sum of absolute value differences)
distances = np.sum(np.abs(self.Xtr - X[i,:]), axis = 1)
min_index = np.argmin(distances)
# get the index with smallest distance
Ypred[i] = self.ytr[min_index]
# predict the label of the nearest example
return Ypred
2.
缺点:训练的时间复杂度是O(1),而预测的时间复杂度是O(N)
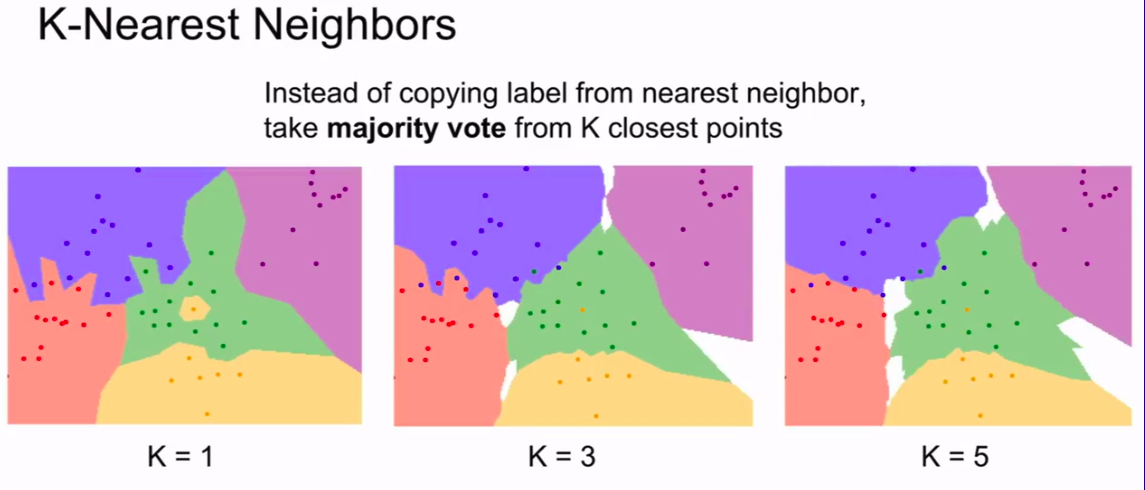
当然,这个算法还可以选择选取K个最近的点,然后加权投票
http://vision.stanford.edu/teaching/cs231n-demos/knn/
这个网站给出了一个直观的K与图形的关系
这也是其中一个decision boundary
当然,除了用L1(Manhattan)distance
$d_1(I_1,I_2) = \sum_p|I_1^p - I_2^p| $
还可以用L2(Euclidean)distance
\(d_2(I_1,I_2) = \sqrt{\sum_p(I_1^p - I_2^p)^2}\)
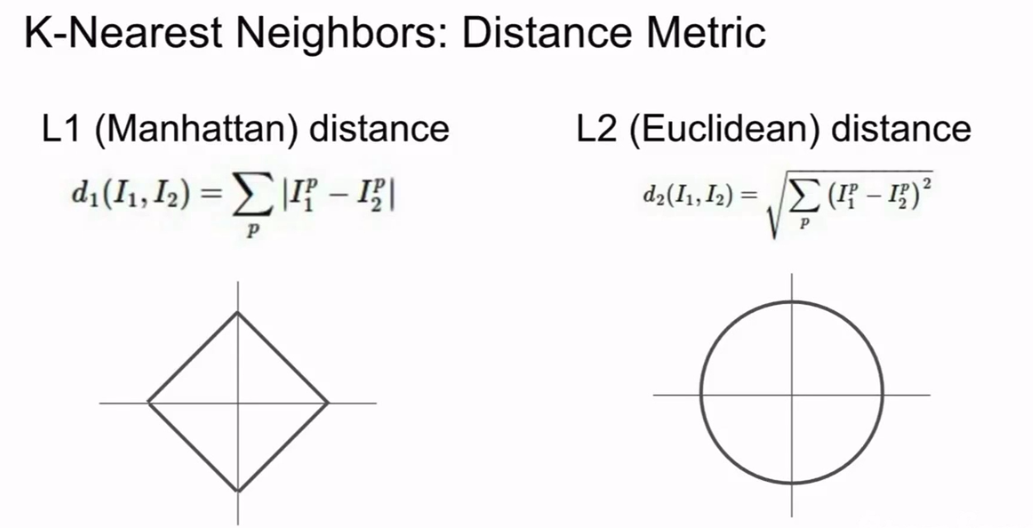
--曼哈顿距离和欧氏距离
注意:Manhattan distance 容易受到坐标轴的影响
总而言之,这些要人为决定的参数叫做超参数Hyperparameters

还有就是,如何选择L1还是L2呢?
这很难回答。但是如果与坐标轴有关的话,可能是L2更好,因为L1有坐标依赖。
但是没有坐标依赖的话可能是L1更加好一点。
当然,最佳方法是两个都尝试一下。看一下哪个更好。
下面总结一下如何选择超参数:
不要盲目选择在训练集中表现最佳的超参数。因为这样可能会过拟合。导致低方差高偏差。
可以将训练集划分。像机器学习上的一样。但是不要划分仅仅2个,训练集和测试集。这样看起来合理,其实很容易对测试集产生依赖性。
更好的方法是,把测试集(training),测试集(test),验证集(validation)
总结一下,我们通常的做法是:
在训练集上用不同超参数来训练算法,然后在验证集上进行评估,然后选择表现最好的超参数。最后的最后,我们在测试集上跑一下,当然,这也是我们要写到报告的数据,这样可以保证你的数据并没有造假。

当然。我们还可以用交叉验证集。cross-validation: split data into folds
这一般在小数据集上用的多,在深度学习不是很常用。
它的基本理念是:我们取出测试集数据,我们将整个数据和往常一样,保留部分数据作为最后使用的测试集,对于剩余的数据集,我们不是把它们分成一个训练集和一个验证集,而是分成很多(folds)份。在这种情况下,我们轮流将每一份都当做一个验证集,然后对每一份进行循环。这样你就会更有信心知道那组超参数的表现更加稳定。
但事实上,我们在深度学习的时候,因为计算量十分大,所以一般不采用!

经过交叉验证方法。会得到这样一组图:
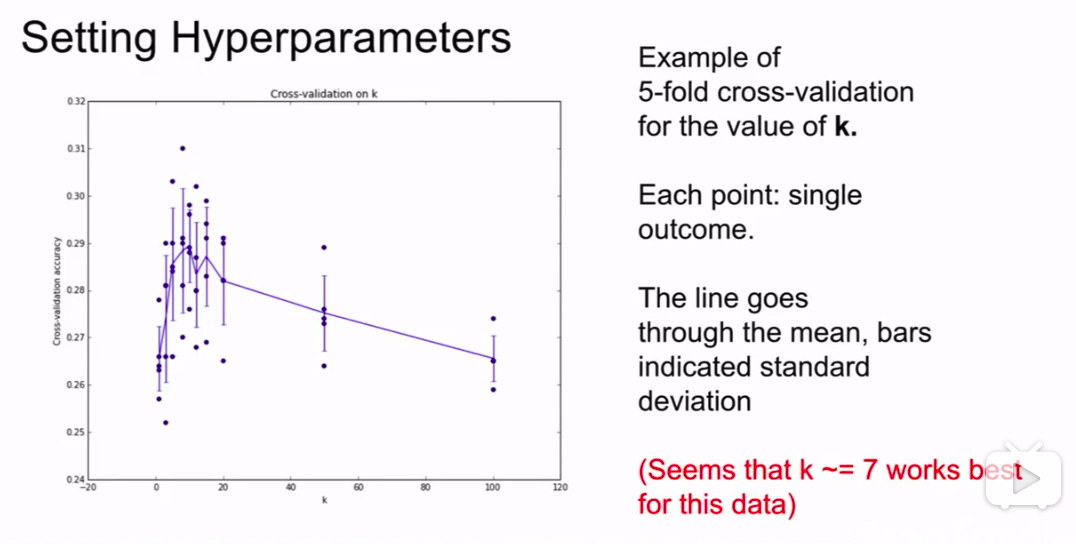
我们可以观察不同的情况下的方差来判别哪一种情况对我们更好。
(一般情况下机器学习都要这样做,画出一个超参数和误差的图)
但是!!KNN基本上不会用到上面提到的问题。
原因是
- 它测试时的运算时间很长!
- 用欧几里得距离或者L1这样的衡量标准在用在比较图像上很不合适!
如图:
never used!太惨了
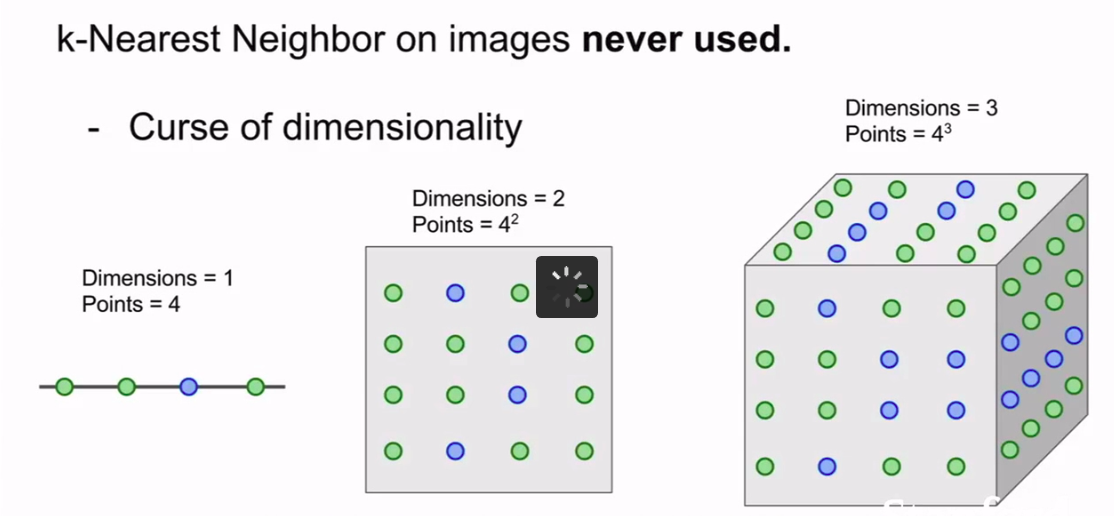
KNN算法还有一个问题:
称之为 :---维度灾难
因为可能样本之间相距很远,所以可能需要用大量的数据和高维度。
cs231n__2. K-nearest Neighbors的更多相关文章
- [机器学习系列] k-近邻算法(K–nearest neighbors)
C++ with Machine Learning -K–nearest neighbors 我本想写C++与人工智能,但是转念一想,人工智能范围太大了,我根本介绍不完也没能力介绍完,所以还是取了他的 ...
- K Nearest Neighbor 算法
文章出处:http://coolshell.cn/articles/8052.html K Nearest Neighbor算法又叫KNN算法,这个算法是机器学习里面一个比较经典的算法, 总体来说KN ...
- 快速近似最近邻搜索库 FLANN - Fast Library for Approximate Nearest Neighbors
What is FLANN? FLANN is a library for performing fast approximate nearest neighbor searches in high ...
- K NEAREST NEIGHBOR 算法(knn)
K Nearest Neighbor算法又叫KNN算法,这个算法是机器学习里面一个比较经典的算法, 总体来说KNN算法是相对比较容易理解的算法.其中的K表示最接近自己的K个数据样本.KNN算法和K-M ...
- Approximate Nearest Neighbors.接近最近邻搜索
(一):次优最近邻:http://en.wikipedia.org/wiki/Nearest_neighbor_search 有少量修改:如有疑问,请看链接原文.....1.Survey:Neares ...
- K nearest neighbor cs229
vectorized code 带来的好处. import numpy as np from sklearn.datasets import fetch_mldata import time impo ...
- K近邻(K Nearest Neighbor-KNN)原理讲解及实现
算法原理 K最近邻(k-Nearest Neighbor)算法是比较简单的机器学习算法.它采用测量不同特征值之间的距离方法进行分类.它的思想很简单:如果一个样本在特征空间中的k个最近邻(最相似)的样本 ...
- K-Means和K Nearest Neighbor
来自酷壳: http://coolshell.cn/articles/7779.html http://coolshell.cn/articles/8052.html
- sklearn:最近邻搜索sklearn.neighbors
http://blog.csdn.net/pipisorry/article/details/53156836 ball tree k-d tree也有问题[最近邻查找算法kd-tree].矩形并不是 ...
- K临近算法
K临近算法原理 K临近算法(K-Nearest Neighbor, KNN)是最简单的监督学习分类算法之一.(有之一吗?) 对于一个应用样本点,K临近算法寻找距它最近的k个训练样本点即K个Neares ...
随机推荐
- vue2.x引入threejs
@ 目录 vue2.x引入threejs npm安装 使用指定版本: 其他插件 实例 强调 vue2.x引入threejs npm安装 npm install three 使用指定版本: npm in ...
- 适合生产制造企业用的ERP系统有哪些?
什么叫适合?匹配很重要!同是生产制造企业,规模不同.行业不同.发展阶段不同.生产模式不同.管理理念不同,适用的ERP自然也不同.不同规模的企业选用不同的系统,如过你是大型企业,业务管理都比较标准规范, ...
- WPF开发经验-实现Win10虚拟触摸键盘
一 引入 项目有个需求,需要实现纯触控操作进行键盘输入.项目部署在Win10系统上,考虑有两种方案来实现. 通过调用Win10自带的触摸键盘来实现: 通过WPF实现一个触摸键盘来实现: 二 调用Win ...
- centos7 安装RabbitMQ3.6.15 以及各种报错
成功图镇楼 各个版本之间的差异不大,安装前要确保rabbitmq 的版本和 elang的版本一致.预防各种错乱. 注意点:(重要!!重要!!) * 同时安装的时候最好确保rabbitmq和erlang ...
- 深入浅出redis缓存应用
0.1.索引 https://blog.waterflow.link/articles/1663169309611 1.只读缓存 只读缓存的流程是这样的: 当查询请求过来时,先从redis中查询数据, ...
- zk系列二:zookeeper实战之分布式统一配置获取
前面介绍了zk的一些基础知识,这篇文章主要介绍下如何在java环境下获取zk的配置信息:主要基于zk的监听器以及回调函数通过响应式编程的思想将核心代码糅合成一个工具类,几乎做到了拿来即用: 在分布式集 ...
- 使用@Transactional注解的方法所在的类获取不到注解的解决方案
前段时间遇到一个问题,一个service叫做A吧,有多个实现类分别是B,C,D,需要根据前端传的不同参数去匹配不同的实现类,我就自定义了一个注解@OrderDeal放在B,C,D上面,然后匹配前端传的 ...
- 4.django-模板
在django中,模板引擎(DTL)是一种可以让开发者将服务端数据填充到html页面中的完成渲染的技术 模板引擎的原理分为以下三步: 在项目配置文件中指定保存模板文件的的模板目录,一般设置在项目根目录 ...
- K8s如何启用cgroup2支持?
什么是 cgroup ️Reference: control groups(控制组),通常被称为cgroup,是Linux内核的一项功能.它允许将进程组织成分层的组,然后限制和监控各种资源的使用. 内 ...
- win10系统VMWare16 Pro 安装CentOS8
目录 一.本机环境与问题解决 二.下载软件 三.VMWare16 Pro安装 四.CentOS8 安装 一.本机环境与问题解决 装了好几遍,感觉坑都踩了一遍,泪奔~,还好终于跑起来了! 查看电脑是否开 ...