(一)elasticsearch 编译和启动
1.准备
先从github官网上clone elasticsearch源码到本地,选择合适的分支。笔者这里选用的是7.4.0(与笔者工作环境使用的分支一致),此版本编译需要jdk11。
2.编译
Readme 中说明了编译命令
./gradlew assemble
执行此命令,等待1h左右即可,根据机器性能可能会有差异
> Task :x-pack:plugin:sql:qa:compileJava
注: /Users/xxx/IdeaProjects/elasticsearch-my/x-pack/plugin/sql/qa/src/main/java/org/elasticsearch/xpack/sql/qa/jdbc/CsvTestUtils.java使用或覆盖了已过时的 API。
注: 有关详细信息, 请使用 -Xlint:deprecation 重新编译。
BUILD SUCCESSFUL in 52m 0s
947 actionable tasks: 946 executed, 1 up-to-date编译过程中可能会遇到的问题:
FAILURE: Build failed with an exception.
* What went wrong:
a problem occurred running Docker from [/usr/local/bin/docker] yet it is required to run the following tasks:
:distribution:docker:buildDockerImage
:distribution:docker:buildOssDockerImage
the problem is that Docker exited with exit code [1] with standard error output [Cannot connect to the Docker daemon at unix:///var/run/docker.sock. Is the docker daemon running?]
you can address this by attending to the reported issue, removing the offending tasks from being executed, or by passing -Dbuild.docker=false新版本 elasticsearch 编译过程依赖docker,启动docker后台或者注释掉以下代码
文件路径:/distribution/docker/build.gradle
void addBuildDockerImage(final boolean oss) {
// final Task buildDockerImageTask = task(taskName("build", oss, "DockerImage"), type: LoggedExec) {
// dependsOn taskName("copy", oss, "DockerContext")
// List<String> tags
// if (oss) {
// tags = [
// "docker.elastic.co/elasticsearch/elasticsearch-oss:${VersionProperties.elasticsearch}",
// "elasticsearch-oss:test"
// ]
// } else {
// tags = [
// "elasticsearch:${VersionProperties.elasticsearch}",
// "docker.elastic.co/elasticsearch/elasticsearch:${VersionProperties.elasticsearch}",
// "docker.elastic.co/elasticsearch/elasticsearch-full:${VersionProperties.elasticsearch}",
// "elasticsearch:test",
// ]
// }
// executable 'docker'
// final List<String> dockerArgs = ['build', files(oss), '--pull', '--no-cache']
// for (final String tag : tags) {
// dockerArgs.add('--tag')
// dockerArgs.add(tag)
// }
// args dockerArgs.toArray()
// }
// BuildPlugin.requireDocker(buildDockerImageTask)
}
for (final boolean oss : [false, true]) {
addCopyDockerContextTask(oss)
addBuildDockerImage(oss)
}
//assemble.dependsOn "buildOssDockerImage"
//assemble.dependsOn "buildDockerImage"3.启动
启动elasticsearch 服务,启动类是 org.elasticsearch.bootstrap.Elasticsearch
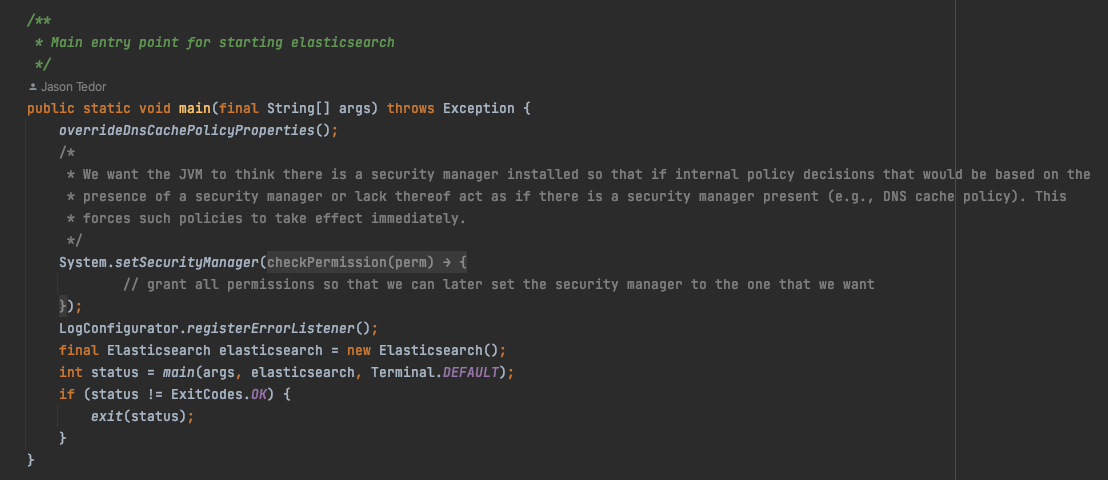
启动过程中可能会出现的问题:
问题1:
the system property [es.path.conf] must be set在vm启动项加入参数:-Des.path.conf=/Users/xxx/IdeaProjects/elasticsearch-my/config,然后将配置文件elasticsearch.yml ,log4j2.properties, modules 复制到这个目录
项目中有配置文件的例子
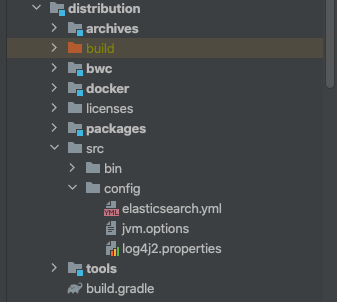
笔者是这样配置的
# Use a descriptive name for your cluster:
#
cluster.name: my-application
#
# ------------------------------------ Node ------------------------------------
#
# Use a descriptive name for the node:
#
node.name: tiger
#
# Add custom attributes to the node:
#
#node.attr.rack: r1
#
# ----------------------------------- Paths ------------------------------------
#
# Path to directory where to store the data (separate multiple locations by comma):
#
path.data: /Users/xxx/IdeaProjects/elasticsearch-my/home/data
#
# Path to log files:
#
path.logs: /Users/xxx/IdeaProjects/elasticsearch-my/home/datamodules 包在发行版elasticsearch中可以找到,这里就不自行编译了
问题2:
Exception in thread "main" java.lang.IllegalStateException: path.home is not configured
at org.elasticsearch.env.Environment.<init>(Environment.java:104)
at org.elasticsearch.env.Environment.<init>(Environment.java:95)
at org.elasticsearch.node.InternalSettingsPreparer.prepareEnvironment(InternalSettingsPreparer.java:69)
at org.elasticsearch.cli.EnvironmentAwareCommand.createEnv(EnvironmentAwareCommand.java:95)
at org.elasticsearch.cli.EnvironmentAwareCommand.execute(EnvironmentAwareCommand.java:86)
at org.elasticsearch.cli.Command.mainWithoutErrorHandling(Command.java:125)
at org.elasticsearch.cli.Command.main(Command.java:90)
at org.elasticsearch.bootstrap.Elasticsearch.main(Elasticsearch.java:115)
at org.elasticsearch.bootstrap.Elasticsearch.main(Elasticsearch.java:92)同样的,在vm参数中设定home地址即可,-Des.path.home=/Users/xxx/IdeaProjects/elasticsearch-my/home
问题3:
no log4j2.properties found; tried [/Users/xxx/IdeaProjects/elasticsearch-my/config] and its subdirectories同问题1,没有复制log4j2.properties引起的问题
问题4:
java.lang.NoClassDefFoundError: org/elasticsearch/plugins/ExtendedPluginsClassLoader找到
compileOnly project(':libs:elasticsearch-plugin-classloader')修改为
compile project(':libs:elasticsearch-plugin-classloader')问题5:
Caused by: org.elasticsearch.ElasticsearchException: Failure running machine learning native code. This could be due to running on an unsupported OS or distribution, missing OS libraries, or a problem with the temp directory. To bypass this problem by running Elasticsearch without machine learning functionality set [xpack.ml.enabled: false].意思是我的机器不支持机器学习,把modules中的插件 x-pack-ml 去掉就行
最后启动完成如下
[2022-12-22T11:19:36,704][INFO ][o.e.p.PluginsService ] [tiger] loaded module [x-pack-sql]
[2022-12-22T11:19:36,705][INFO ][o.e.p.PluginsService ] [tiger] loaded module [x-pack-voting-only-node]
[2022-12-22T11:19:36,705][INFO ][o.e.p.PluginsService ] [tiger] loaded module [x-pack-watcher]
[2022-12-22T11:19:36,706][INFO ][o.e.p.PluginsService ] [tiger] no plugins loaded
[2022-12-22T11:19:37,238][INFO ][i.n.u.i.PlatformDependent] [tiger] Your platform does not provide complete low-level API for accessing direct buffers reliably. Unless explicitly requested, heap buffer will always be preferred to avoid potential system instability.
[2022-12-22T11:19:43,453][DEBUG][o.e.a.ActionModule ] [tiger] Using REST wrapper from plugin org.elasticsearch.xpack.security.Security
[2022-12-22T11:19:43,530][INFO ][i.n.u.i.PlatformDependent] [tiger] Your platform does not provide complete low-level API for accessing direct buffers reliably. Unless explicitly requested, heap buffer will always be preferred to avoid potential system instability.
[2022-12-22T11:19:43,914][INFO ][o.e.d.DiscoveryModule ] [tiger] using discovery type [zen] and seed hosts providers [settings]
[2022-12-22T11:19:45,141][INFO ][o.e.n.Node ] [tiger] initialized
[2022-12-22T11:19:45,142][INFO ][o.e.n.Node ] [tiger] starting ...
[2022-12-22T11:19:45,383][INFO ][o.e.t.TransportService ] [tiger] publish_address {127.0.0.1:9300}, bound_addresses {[::1]:9300}, {127.0.0.1:9300}
[2022-12-22T11:19:45,417][WARN ][o.e.b.BootstrapChecks ] [tiger] initial heap size [268435456] not equal to maximum heap size [4294967296]; this can cause resize pauses and prevents mlockall from locking the entire heap
[2022-12-22T11:19:45,418][WARN ][o.e.b.BootstrapChecks ] [tiger] the default discovery settings are unsuitable for production use; at least one of [discovery.seed_hosts, discovery.seed_providers, cluster.initial_master_nodes] must be configured
[2022-12-22T11:19:45,425][INFO ][o.e.c.c.Coordinator ] [tiger] cluster UUID [hhUOjQTPTxC11orp9ptAoQ]
[2022-12-22T11:19:45,450][INFO ][o.e.c.c.ClusterBootstrapService] [tiger] no discovery configuration found, will perform best-effort cluster bootstrapping after [3s] unless existing master is discovered
[2022-12-22T11:19:45,588][INFO ][o.e.c.s.MasterService ] [tiger] elected-as-master ([1] nodes joined)[{tiger}{alQTCfqOStya2j1epxaskQ}{qDAgKIDeTmCbif0-EDJ0FA}{127.0.0.1}{127.0.0.1:9300}{dim}{xpack.installed=true} elect leader, _BECOME_MASTER_TASK_, _FINISH_ELECTION_], term: 2, version: 18, reason: master node changed {previous [], current [{tiger}{alQTCfqOStya2j1epxaskQ}{qDAgKIDeTmCbif0-EDJ0FA}{127.0.0.1}{127.0.0.1:9300}{dim}{xpack.installed=true}]}
[2022-12-22T11:19:45,733][INFO ][o.e.c.s.ClusterApplierService] [tiger] master node changed {previous [], current [{tiger}{alQTCfqOStya2j1epxaskQ}{qDAgKIDeTmCbif0-EDJ0FA}{127.0.0.1}{127.0.0.1:9300}{dim}{xpack.installed=true}]}, term: 2, version: 18, reason: Publication{term=2, version=18}
[2022-12-22T11:19:45,796][INFO ][o.e.h.AbstractHttpServerTransport] [tiger] publish_address {127.0.0.1:9200}, bound_addresses {[::1]:9200}, {127.0.0.1:9200}
[2022-12-22T11:19:45,797][INFO ][o.e.n.Node ] [tiger] started
[2022-12-22T11:19:46,175][INFO ][o.e.l.LicenseService ] [tiger] license [003ac67e-0dd0-42ee-8b76-59e2c21c444a] mode [basic] - valid
[2022-12-22T11:19:46,175][INFO ][o.e.x.s.s.SecurityStatusChangeListener] [tiger] Active license is now [BASIC]; Security is disabled
[2022-12-22T11:19:46,184][INFO ][o.e.g.GatewayService ] [tiger] recovered [0] indices into cluster_state这里推荐一个chrome下的小插件elaticsearch-head,可视化当前集群的状态
4.参考列表
https://www.cnblogs.com/Jackeyzhe/p/13352543.html
(一)elasticsearch 编译和启动的更多相关文章
- (转)redis 学习笔记(1)-编译、启动、停止
redis 学习笔记(1)-编译.启动.停止 一.下载.编译 redis是以源码方式发行的,先下载源码,然后在linux下编译 1.1 http://www.redis.io/download 先 ...
- 【ELK】【docker】6.Elasticsearch 集群启动多节点 + 解决ES节点集群状态为yellow
本章其实是ELK第二章的插入章节. 本章ES集群的多节点是docker启动在同一个虚拟机上 ====================================================== ...
- Elasticsearch在后台启动
Elasticsearch在linux下使用命令sh elasticsearch start,按键ctrl+c的时候程序就会stop掉,如何将程序在后台启动呢? 需要使用:./elasticsearc ...
- 在idea中编写自动拉取、编译、启动springboot项目的shell脚本
idea 开发环境搭建 idea中安装shell开发插件 服务器具备的条件 已经安装 lsof(用于检查端口占用) 已安装 git 安装 maven 有 java 环境 背景 代码提交到仓库后,需要在 ...
- 2019-8-31-dotnet-启动-JIT-多核心编译提升启动性能
title author date CreateTime categories dotnet 启动 JIT 多核心编译提升启动性能 lindexi 2019-08-31 16:55:58 +0800 ...
- dotnet 启动 JIT 多核心编译提升启动性能
用2分钟提升十分之一的启动性能,通过在桌面程序启动 JIT 多核心编译提升启动性能 在 dotnet 可以通过让 JIT 进行多核心编译提升软件的启动性能,在默认托管的 ASP.NET 程序是开启的, ...
- redis 学习笔记(1)-编译、启动、停止
一.下载.编译 redis是以源码方式发行的,先下载源码,然后在linux下编译 1.1 http://www.redis.io/download 先到这里下载Stable稳定版,目前最新版本是2.8 ...
- Unity 编译apk启动出异常
问题:unity 编译出来的apk,在android安装启动,时报以下错误: 07-06 20:52:48.282: E/linker(18229): load_library(linker.cpp: ...
- 一个简单的dos脚本, svn 获取代码 - Tomcat 备份 - Maven 编译 - 停止/启动Tomcat - Tomcat站点 发布
获取最新代码 svn update --username %SVN_USER% --password %SVN_PASSWORD% >> "../%LOG_FILE%" ...
随机推荐
- hmtl5 web SQL 和indexDB
前端缓存有cookie,localStorage,sessionStorage,webSQL,indexDB: cookie:有缺点 localStorage:功能单一 sessionStorage: ...
- Bootstrap‘s JavaScript requires jQuery
1.遇到的第一个问题:modal.js:6 Uncaught Error: Bootstrap's JavaScript requires jQuery at modal.js:6 2.遇到的第二个问 ...
- Silky微服务框架之服务引擎
构建服务引擎 在注册Silky微服务应用一节中,我们了解到在ConfigureServices阶段,通过IServiceCollection的扩展方法AddSilkyServices<T> ...
- 23.mixin类源码解析
mixin类用于提供视图的基本操作行为,注意mixin类提供动作方法,而不是直接定义处理程序方法 例如.get() .post(),这允许更灵活的定义,mixin从rest_framework.mix ...
- python dir函数解析
dir() 函数 不带参数,直接执行是返回当前环境中对象的名称列表.指定对象的名称作为参数执行,返回指定对象当中的属性(包括函数名,类名,变量名等) 下面我们具体找几个例子测试一下 dir() ...
- .NET周报【10月第3期 2022-10-25】
国内文章 聊一聊被 .NET程序员 遗忘的 COM 组件 https://www.cnblogs.com/huangxincheng/p/16799234.html 将Windows编程中经典的COM ...
- CF Round #829 题解 (Div. 2)
F 没看所以摆了 . 看拜月教教主 LHQ 在群里代打恰钱 /bx 目录 A. Technical Support (*800) B. Kevin and Permutation (*800) C. ...
- Linux系统文件与启动流程
Linux系统文件与启动流程 /etc初始化系统重要文件 /etc/sysconfig/network-scripts/ifcfg-eth0:网卡配置文件 /etc/resolv.conf:Linux ...
- 深度学习环境搭建常用网址、conda/pip命令行整理(pytorch、paddlepaddle等环境搭建)
前言:最近研究深度学习,安装了好多环境,记录一下,方便后续查阅. 1. Anaconda软件安装 1.1 Anaconda Anaconda是一个用于科学计算的Python发行版,支持Linux.Ma ...
- JS数据结构与算法-队列结构
队列结构 一.认识队列 受限的线性结构: 我们已经学习了一种受限的线性结构:栈结构. 并且已经知道这种受限的数据结构对于解决某些特定问题,会有特别的 效果. 下面,我们再来学习另外一个受限的数据结构: ...