vivo 服务端监控体系建设实践
作者:vivo 互联网服务器团队- Chen Ningning
本文根据“2022 vivo开发者大会"现场演讲内容整理而成。
经过几年的平台建设,vivo监控平台产品矩阵日趋完善,在vivo终端庞大的用户群体下,承载业务运行的服务数量众多,监控服务体系是业务可用性保障的重要一环,监控产品全场景覆盖生产环境各个环节。从事前发现,事中告警、定位、恢复,事后复盘总结,监控服务平台都提供了丰富的工具包。从以前的水平拆分,按场景建设,到后来的垂直划分,整合统一,降低平台割裂感。同时从可观测性、AIOps、云原生等方向,监控平台也进行了建设实践。未来vivo监控平台将会向着全场景、一站式、全链路、智能化方向不断探索前行。
监控服务平台是自研的、覆盖全场景的可用性保障系统。经过多年深耕,vivo监控团队已经成体系构筑起一整套稳定性保障系统,随着云原生可观测技术变革不断深化,监控团队如何掌舵前行?下面就平台的建设历程、思考、探索,做一下简单介绍。
一、监控体系建设之道
1.1 监控建设历程
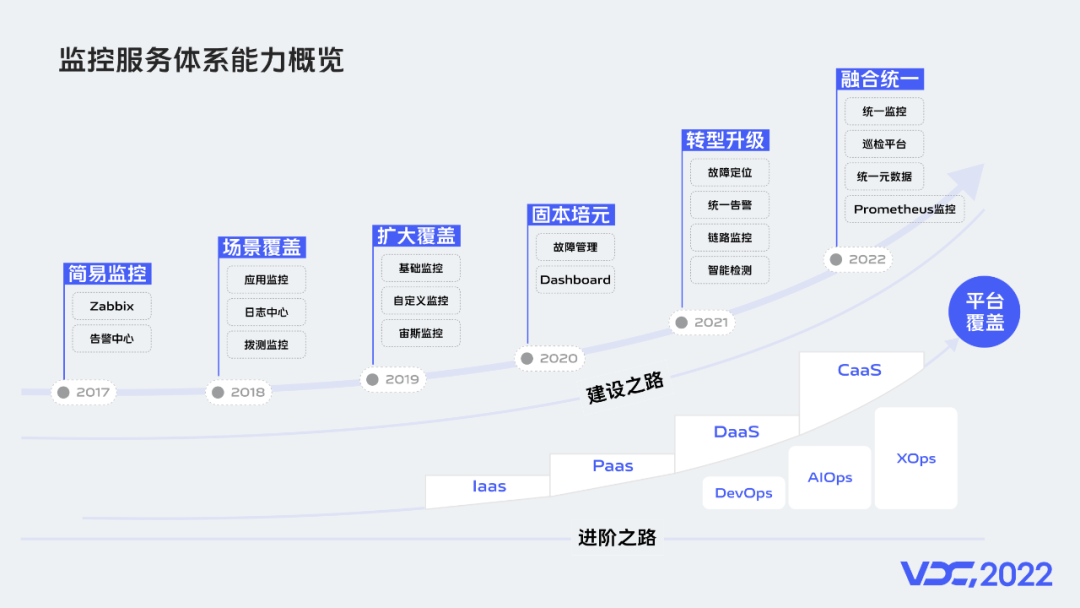
回顾监控建设历程,最初采用Zabbix,与告警中心的组合实现简易监控。随着业务的发展在复杂监控场景和数据量不断增长的情况下,这种简易的组合就显的捉襟见肘。所以从2018年开始我们开启了自研之路,最开始我们建设了应用监控、日志监控、拨测监控解决了很大一部分监控场景没有覆盖的问题;2019年我们建设了基础监控、自定义监控等,完成了主要监控场景的基本覆盖;2020年我们在完善前期监控产品的同时,进一步对周边产品进行了建设;随着AI技术的不断成熟,我们从2021年开始也进行了转型升级,先后建设了故障定位平台、统一告警平台有了这些平台后我们发现,要想进一步提升平台价值,数据和平台的统一至关重要;所以从2022年开始建设了统一监控平台,也就是将基础监控、应用监控和自定义监控进行了统一,统一监控包含了统一配置服务和统一检测服务。从监控的建设历程来看,我们一路覆盖了IaaS、PaaS、DaaS、CaaS等平台。我们的职能也从DevOps向AIOps迈进。
1.2 监控能力矩阵
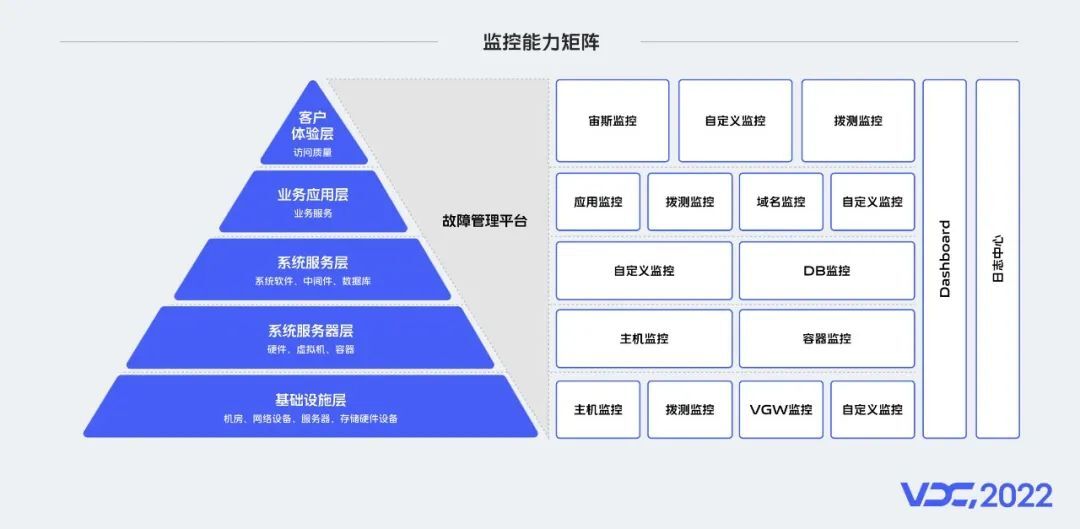
讲了监控的发展历程,那么这些监控产品在我们的生产环境中是如何分布的呢?要想支撑数以万计的业务运行,需要庞杂的系统支撑,服务器、网络环境、基础组件等,都需要监控系统保障它的稳定性。我们将监控的对象分为五层,在基础设施层,包含了网络设备、服务器、存储硬件等,这一层我们通过VGW监控对网络设备进行监控,VGW是Vivo Gateway的缩写,类似于LVS;通过自定义监控,对机房进行监控;系统服务器层,我们定义的监控对象是服务运行依赖的环境,通过主机监控对物理机、虚拟机等监控,当前容器在云原生技术体系中,已然成为微服务运行的最佳载体,所以对容器的监控必不可少;系统服务层,包含了各种数据库产品、大数据组件等,在这一层主要通过自定义监控检测、告警;业务应用层,主要有应用服务,我们通过应用监控对业务链路信息进行监控;客户体验层,我们定义了端上的访问质量,由宙斯平台实现监控。前面我们讲了监控能力矩阵,下面我们具体介绍一下监控的范围和整个平台的能力。
1.3 监控对象范围

监控对象涉及网络、主机、基础服务等。面对各地机房我们做到了监控全覆盖,为满足各类环境部署诉求,我们可以做到针对不同环境的监控。我们支持多种采集方式,SDK和API采集主要应用在自定义监控场景,Agent主要采集主机类指标,采集上来的时序数据经过预聚合、统一的数据清洗,然后存储在TSDB数据库。针对海量数据存储我们采用了数据降精,宽表多维多指标等方案。我们常用的检测算法有恒值检测、突变检测、同比检测等,同时还支持了无数据检测、多指标组合检测,检测出现的异常我们会形成一个问题,问题在经过一系列的收敛后发出告警,我们有多种告警通道,支持告警合并、认领、升级等,需要展示的指标数据我们提供了丰富的自定义指标看板,对使用频率高 固化场景,我们提供了模板化配置方案。有了完备的监控体系,那么系统的关键指标和监控对象体量如何?
1.4 监控系统体量

当前监控服务体系保障着x万+的主机实例,x万+的DB实例,每天处理x千亿条各类指标和日志,对x千+的域名做到秒级监控,对x万+的容器实例监控,每天从统一告警发出的各类告警达到x十万+ ,对主机实例的监控覆盖率达到x %,监控平台通过不断的探索实践,实现了对海量数据计算存储,当前对核心业务的告警延迟在x秒以内,告警召回率大于x %。
1.5 监控系统面临挑战
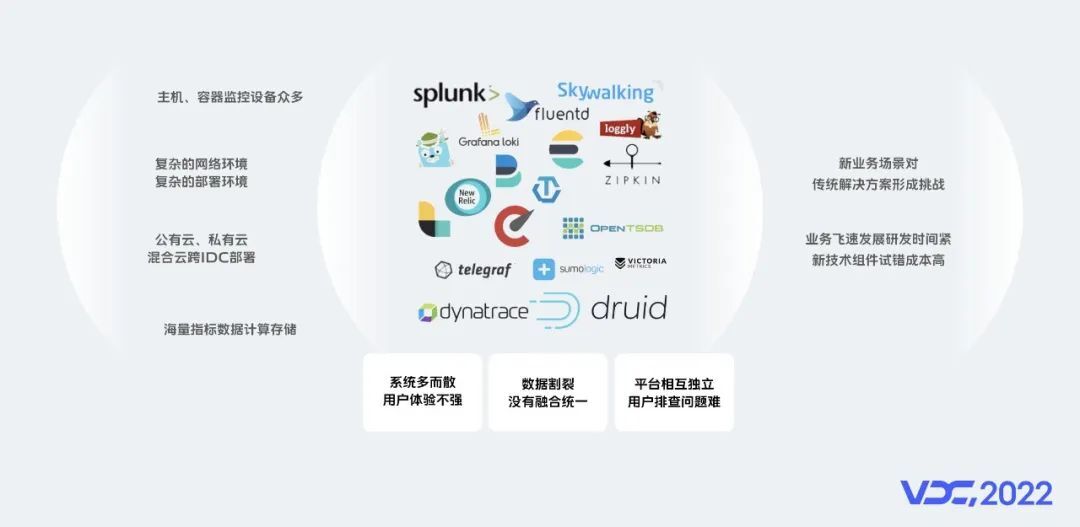
虽然现阶段取得了一些成果,但是目前仍然面临很多挑战,主要分为三大类:
部署环境复杂
对数以万计的主机和容器,实时采集 计算是一项困难的事情;面对各地机房监控,部署过程中依赖项多,维护工作复杂;对海量数据计算存储,保障监控服务稳定性、可用性难度大。
平台系统繁多
当前系统还存在割裂,用户体验不强;数据割裂,没有从底层融合在一起,对于数据组合使用形成挑战。
新技术挑战
首先基于容器的监控方案,对传统监控方案形成挑战,当前对Prometheus指标存储处在探索阶段,暂时没有标准的解决方案,但是面对快速增长的数据量,新组件的探索试错成本相对较高。
二、监控服务体系架构
2.1 产品架构

产品架构的能力服务层,我们定义了采集能力、检测能力、告警能力等;功能层我们对这些能力做了具体实现,我们将监控分为主机、容器、DB等9类场景,展示层主要由Dashboard提供灵活的图表配置能力,日志中心负责日志查询,移动端可以对告警信息进行认领、屏蔽。
2.2 技术架构
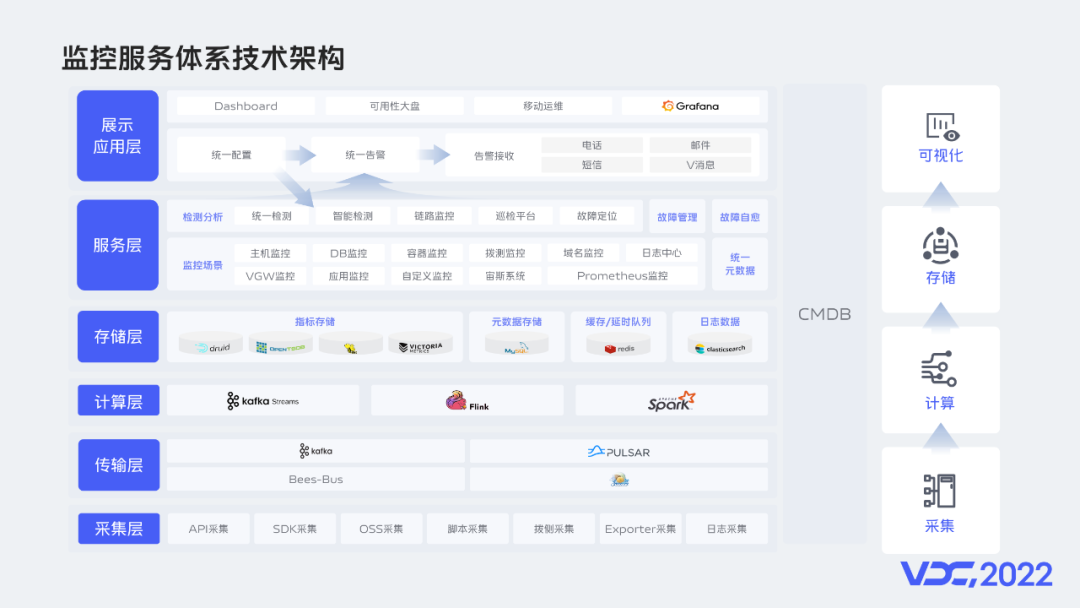
技术架构层分为采集、计算、存储、可视化几大块,首先在采集层我们通过各种采集方式进行指标采集;上报的数据主要通过Bees-Bus进行传输,Bees-Bus是一款公司自研的分布式、高可用的数据收集系统,指标经过Bees-Bus之后写入Kafka,随着Pulsar的受关注度与使用量的显著增加,我们也在这方面进行了一定的探索;计算层我们经历了Spark、Flink、KafkaStream几个阶段的探索,基本实现了计算层技术栈收归到KafkaStream;数据主要存储在Druid,当前有190+节点的Druid集群。Opentsdb和Hive早期应用在主机监控场景,随着业务发展其性能已经不能胜任当前的写入和查询需求,所以逐步被舍弃。
当前我们选用了VictoriaMetrics作为Prometheus的远端存储,日志信息存储在ES中,目前我们有250+的ES节点。服务层中各类监控场景的元数据,都由统一元数据服务提供;各类检测规则、告警规则都由统一配置服务维护,统一告警服务则负责告警的收敛、合并、发送等。Grafana则主要用作自监控告警。
2.3 交互流程
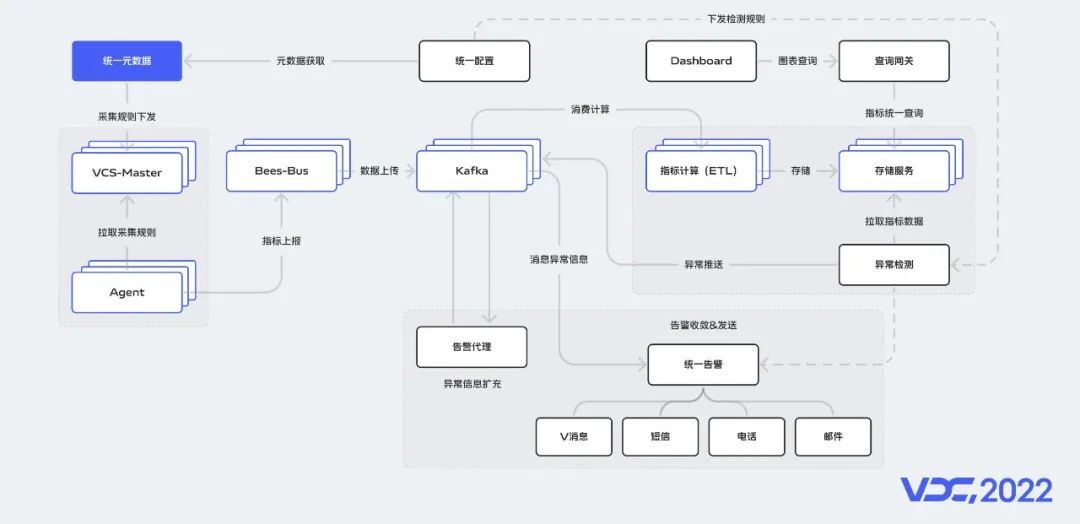
在监控架构的基础上,我们介绍一下整体交互流程,采集规则由统一元数据服务管理,并主动下发到VCS-Master,VCS-Master主要用来任务下发,Agent执行结果数据接收,任务查询和配置管理等,Agent会定期从VCS-Master拉取缓存的采集规则,指标经过Bees-Bus双写到Kafka,由ETL程序对指标数据消费,然后做清洗和计算,最后统一写入到存储服务中,统一配置服务下发检测规则到异常检测服务,检测出的异常信息推送到Kafka,由告警代理服务对异常信息进行富化,处理好的数据推到Kafka,然后由统一告警服务消费处理。在存储服务之上,我们做了一层查询网关,所有的查询会经过网关代理。
三、可用性体系构建与保障
3.1 可用性体系构建
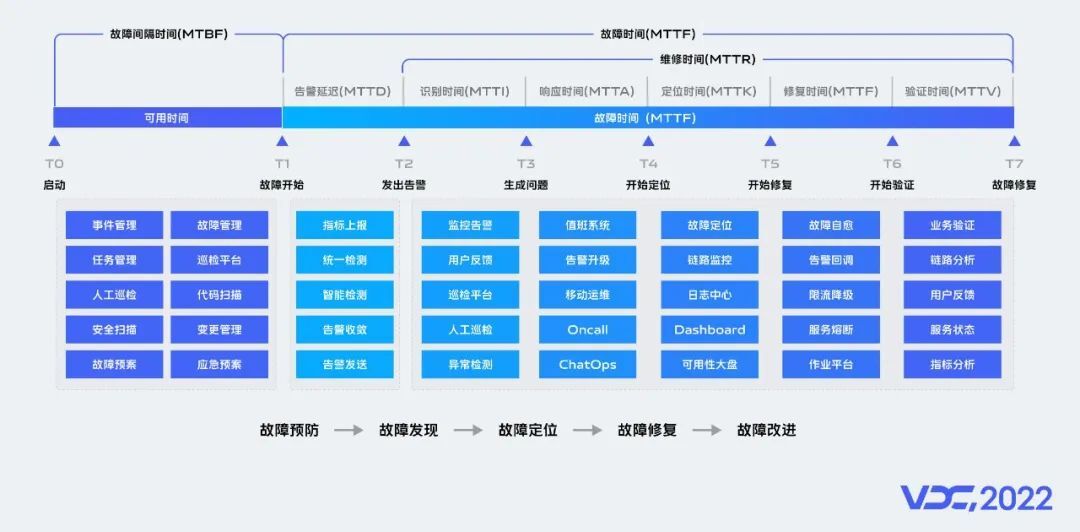
前面说了监控服务体系整体架构,那么监控产品如何服务于业务可用性。我们将业务稳定性在时间轴上进行分割,不同的时段有不同的系统保障业务可用性,当前我们主要关注MTTD和MTTR,告警延迟越小发现故障的速度也就越快,系统维修时间越短说明系统恢复速度越快,我们将MTTR指标拆解细化然后各个击破,最终达成可用性保障要求。vivo监控服务体系提供了,涵盖在稳定性建设中需要的故障预防、故障发现等全场景工具包,监控平台提供了产品工具,那么与运维人员,研发人员是怎样协作配合的?
3.2 系统可用性保障
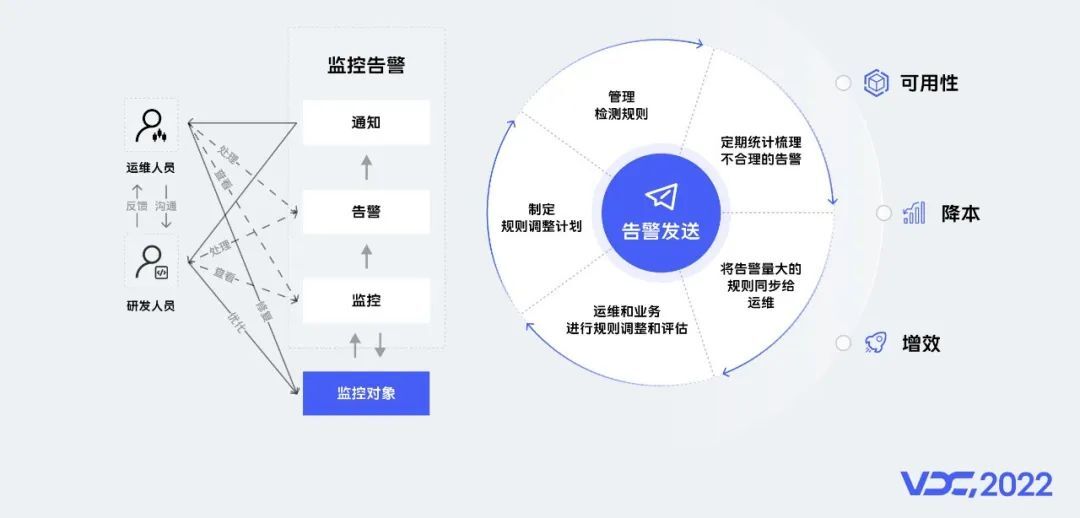
当监控对象有问题时,监控系统就会发送告警给运维人员或业务开发,他们通过查看相关指标修复问题。使用过程中运维人员的诉求和疑问,由监控平台产品和开发协同配合解决,我们通过运营指标,定期梳理出不合理的告警,将对应的检测规则同步给运维同学,然后制定调整计划,后期我们计划结合智能检测,做到零配置就能检测出异常指标。通过监控开发、运维人员和业务开发一起协同配合,保障业务的可用性。
3.3 监控系统可用性
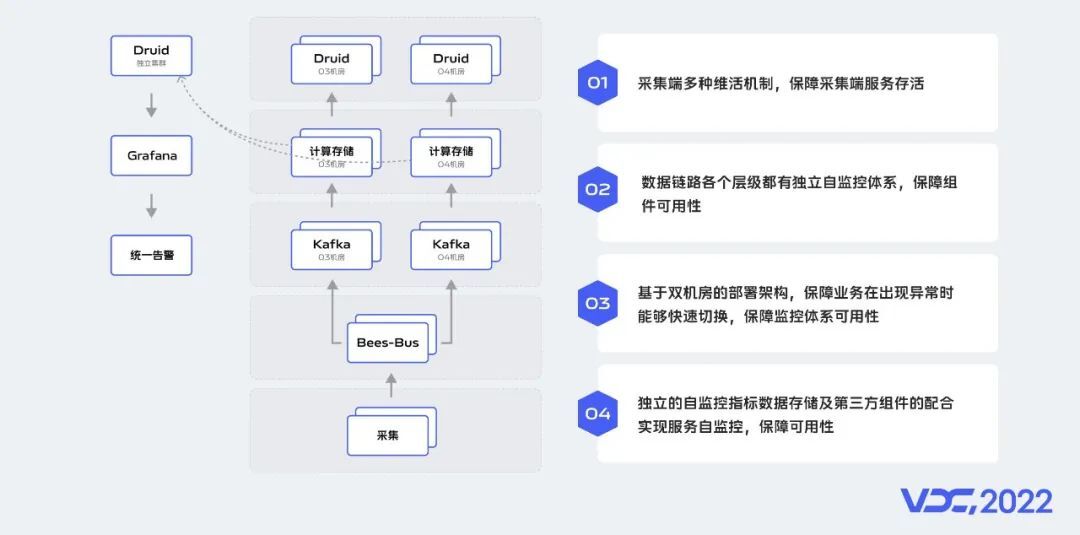
除了保障业务可用性外,监控系统自身的可用性保障也是一个重要的课题。为了保障Agent存活,我们构建了多种维活机制,保障端上指标采集正常。数据经过Bees-Bus之后,会双写到两个机房,当有一个机房出现故障,会快速切到另一个机房,保障核心业务不受损。数据链路的每一层都有自监控。监控平台通过Grafana监控告警。
3.4 复杂场景下依托监控解决问题手段 监控能力矩阵
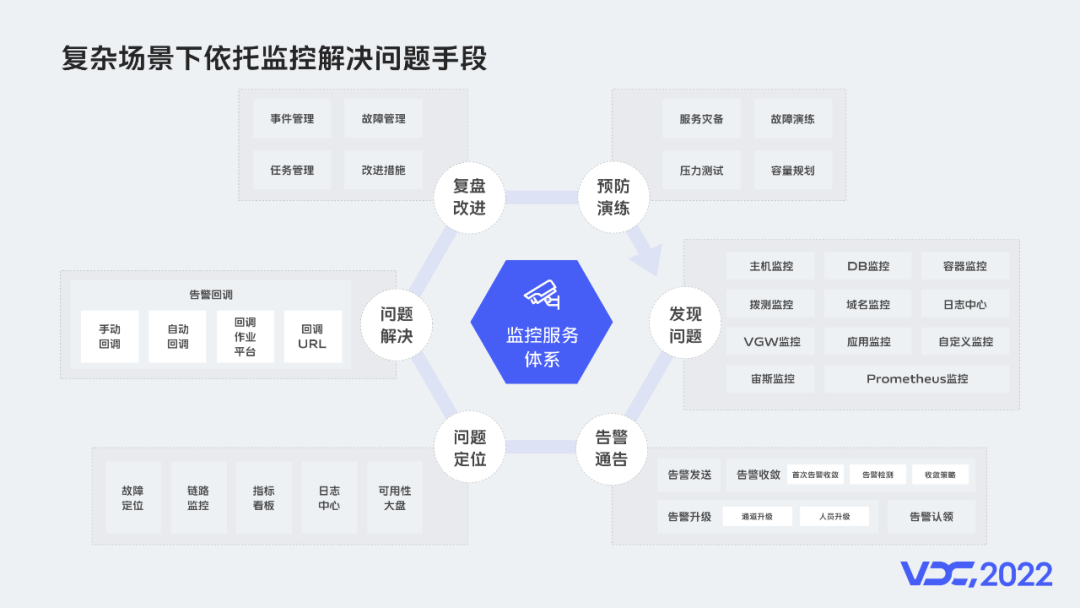
随着公司业务发展,业务模型、部署架构越来越复杂,让故障定位很困难,定位问题成本高。而监控系统在面对复杂、异构、调用关系冗长的系统时就起到了重要作用。在问题发现阶段,例如多服务串联调用,如果某个阶段,出现耗时比较大的情况,可以通过应用监控,降低问题排查难度。在告警通知阶段,可以通过统一告警对异常统一收敛,然后根据告警策略,通知给运维或者开发。问题定位时,可以利用故障定位服务找到最可能出现问题的服务。解决问题时,类似磁盘打满这种比较常见的故障,可以通过回调作业快速排障。复盘改进阶段,故障管理平台可以统一管理,全流程复盘,使解决过程可追溯。预防演练阶段,在服务上线前,可以对服务进行压力测试,根据指标设置容量。
四、行业变革下的监控探索实践及未来规划
4.1 云原生:Prometheus监控
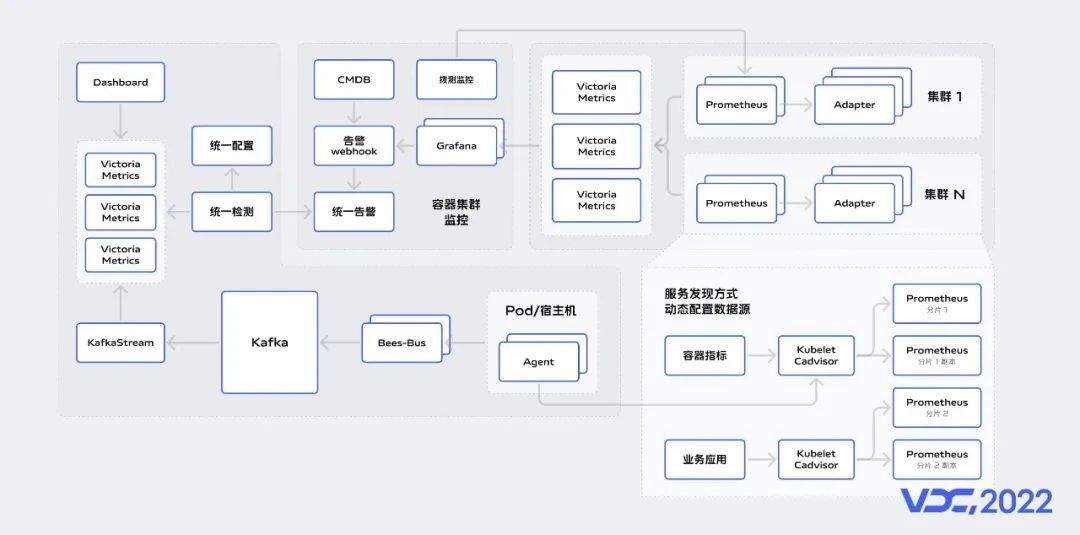
当前行业正迎来快速变革,我们在云原生、AIOps、可观性等方向均进行了探索实践。未来我们也想紧跟行业热点,继续深挖产品价值。随着Kubernetes成为容器编排领域的事实标准,Prometheus因为对容器监控良好的适配,使其成为云原生时代,容器监控的事实标准。下面我们介绍一下整体架构,我们将容器监控分为容器集群监控和容器业务监控,首先对于容器集群监控,每个生产集群都有独立的监控节点,用于部署监控组件,Prometheus按照采集目标服务划分为多组,数据存储采用VictoriaMetrics,我们简称VM,同一机房的Prometheus集群,均将监控数据Remote-Write到VM中,VM配置为多副本存储。通过拨测监控,实现对Prometheus自监控,保障Prometheus异常时能收到告警信息。容器业务监控方面,Agent部署在宿主机,并从Cadvisor拉取指标数据,上报到Bees-Bus,Bees-Bus将数据双写到两个Kafka集群,统一检测服务异步检测指标数据,业务监控指标数据采用VM做远端存储,Dashboard通过Promql语句查询展示指标数据。
4.2 AIOps:故障定位
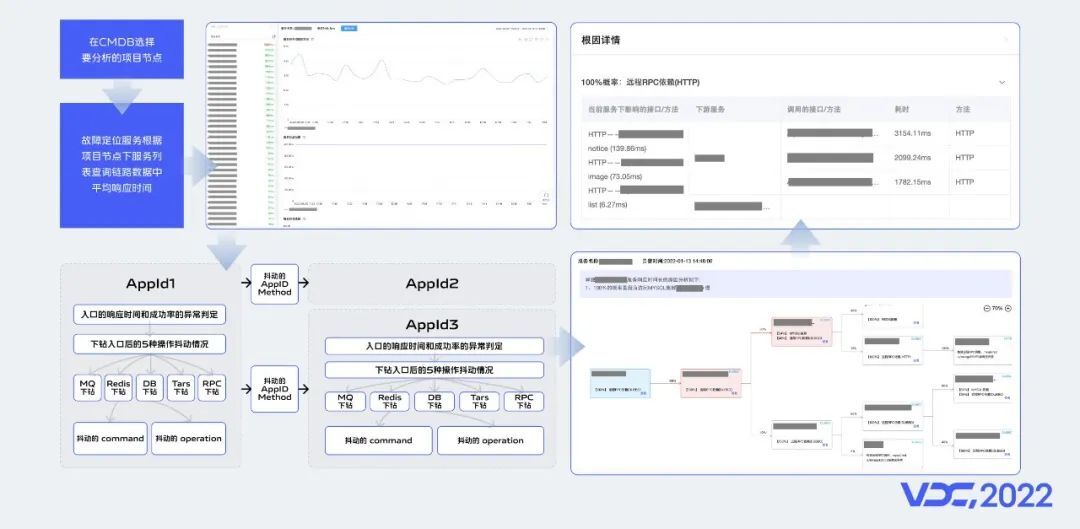
当前业界对AIOps的探索,大部分在一些细分场景,我们也在故障定位这个方向进行了探索。分析过程中首先通过CMDB节点树,选定需要分析的项目节点,然后选择需要分析的时段,就可以按组件和服务下钻分析,通过计算得出每个下游服务的波动方差,再利用K-Means聚类,过滤掉波动较小的聚类,找到可能出现异常的服务或组件。分析过程会形成一张原因链路图,方便用户快速找到异常服务,分析结果会推荐给用户,告知用户最可能出现异常的原因。详情查看功能可以看到被调用的下游服务、接口名、耗时等信息。
4.3 可观测性:可用性大盘
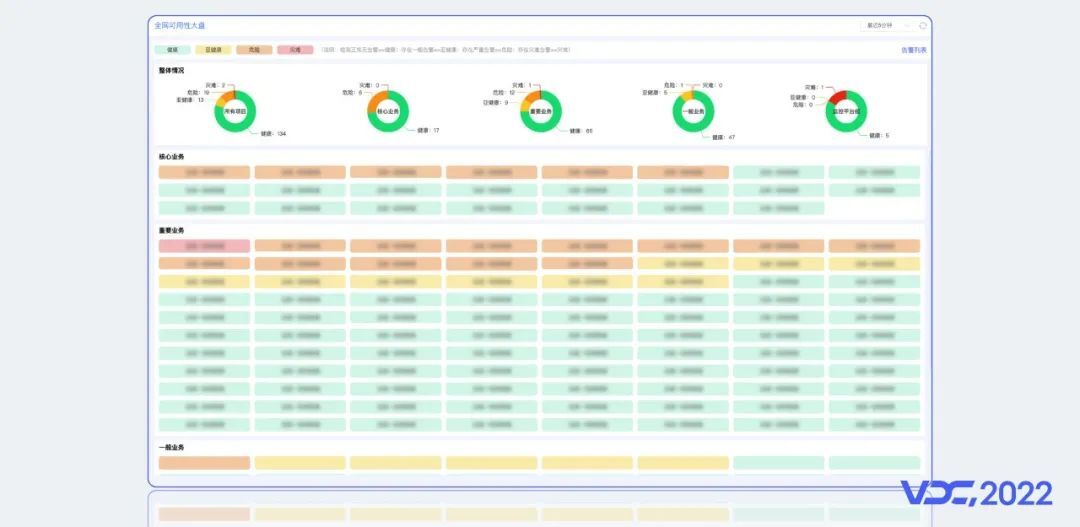
由于CNCF在云原生的定义中提到了Observerbility,所以近两年可观性,成了技术圈很火热的关键词。当前业界基于Metrics、Logs、Traces对可观测性形成了一定共识。谷歌也给出了可观测的核心价值就是快速排障。我们认为指标、日志、追踪是实现可观测性的基础,在此基础上将三者有机融合,针对不同的场景将他们串联在一起,实现方便快捷的查找故障根因,综上我们建设了可用性大盘,它能查看服务的健康状况,通过下钻,可以看到上下游服务依赖关系、域名健康状况、后端服务分布等。通过串联跳转等方式可以看到对应服务的日志和指标信息。
4.4 场景串联
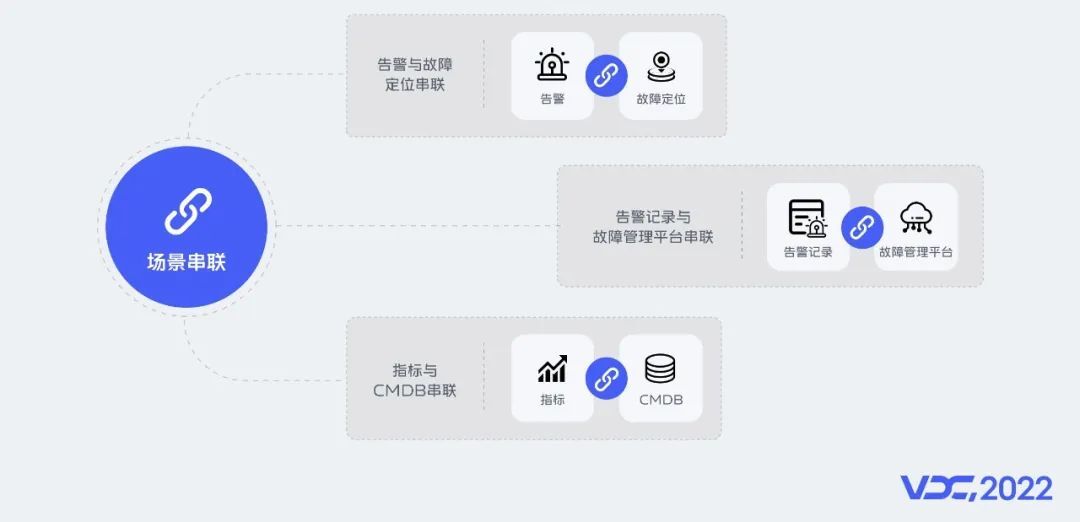
未来我们希望在场景串联、可观测性、服务能力化进一步探索,深挖产品价值。场景串联上:
首先我们希望告警能够与故障定位平台串联,帮助用户快速找到故障根因,缩短排查时间 ;
告警记录能够一键转为事件,减少数据链路中人为操作的环节,保障数据的真实性;
我们希望能与CMDB等平台打通,将数据价值最大化。
4.5 统一可观测
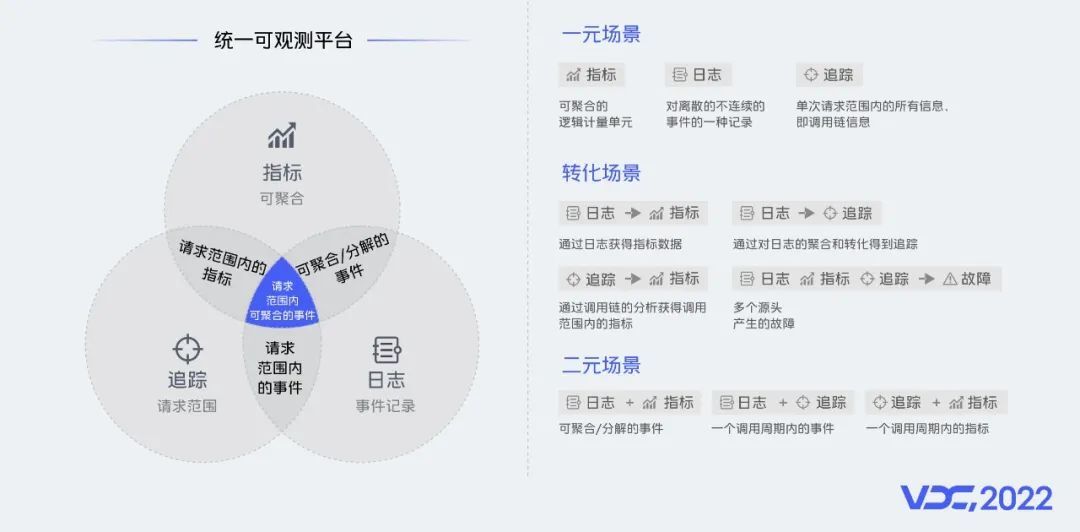
现在,vivo监控服务体系的可观测产品没有完全融合在一起,所以后续我们希望构建统一可观测平台:
在一元场景中,可以单独查看指标、日志、追踪信息;
在转化场景中,能够通过日志获得指标数据,对日志的聚合和转化得到追踪,利用调用链的分析,获得调用范围内的指标。通过指标、日志、追踪多个维度找到故障的源头;
在二元场景,我们希望日志和指标、日志和追踪、追踪和指标能够相互结合,聚合分析。
4.6 能力服务化
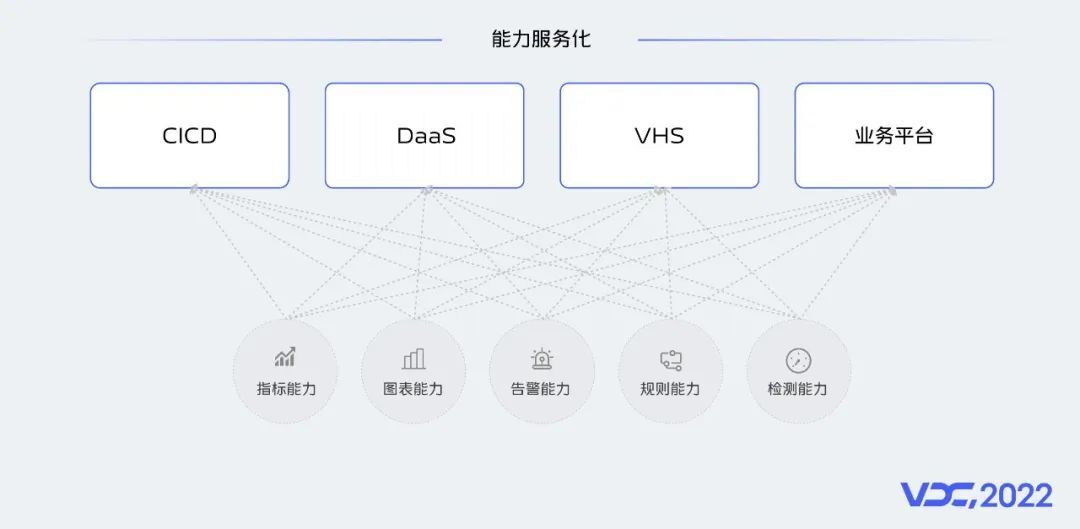
目前监控有很多服务,在公司构建混合云平台的大背景下,监控系统的服务应该具备以能力化的方式提供出去。未来我们希望指标、图表、告警等,以API或者独立服务的方式提供能力,例如在CICD服务部署过程中,就可以通过监控提供的图表能力,看到服务部署时关键指标变化情况,而不需要跳转到监控服务查看指标信息。
最后,我们希望监控能更好的保障业务可用性,在此基础上,我们也希望通过监控系统提升业务服务质量。
vivo 服务端监控体系建设实践的更多相关文章
- vivo 服务端监控架构设计与实践
一.业务背景 当今时代处在信息大爆发的时代,信息借助互联网的潮流在全球自由的流动,产生了各式各样的平台系统和软件系统,越来越多的业务也会导致系统的复杂性. 当核心业务出现了问题影响用户体验,开发人员没 ...
- WCF 项目应用连载[3] - 双向通信 实例管理与服务端监控
WCF 项目应用连载[1] - 索引 - 轻量级的Log系统 - Lig Sample -序 第二节我们已经创建了Lig项目,并且能稳定工作了.现在我们来改进ILigAgent接口,实现WCF的双向通 ...
- Java 服务端监控方案(四. Java 篇)
http://jerrypeng.me/2014/08/08/server-side-java-monitoring-java/ 这个漫长的系列文章今天要迎来最后一篇了,也是真正与 Java 有关的部 ...
- JSR-303 Bean Validation 介绍及 Spring MVC 服务端参数验证最佳实践
任何时候,当要处理一个应用程序的业务逻辑,数据校验是你必须要考虑和面对的事情. 应用程序必须通过某种手段来确保输入参数在上下文来说是正确的. 分层的应用很多时候同样的数据验证逻辑会出现在不同的层,这样 ...
- 使用Jacoco统计服务端代码覆盖情况实践
一.背景 随着需求的迭代,需求增加的同时,有可能会伴随着一些功能的下线.如果不对系统已经不用的代码进行梳理并删除不需要的代码,那么就会增加系统维护成本以及理解成本.但经历比较长的迭代以及系统交接,可能 ...
- Vue.js 服务端渲染业务入门实践
作者:威威(沪江前端开发工程师) 本文原创,转载请注明作者及出处. 背景 最近, 产品同学一如往常笑嘻嘻的递来需求文档, 纵使内心万般拒绝, 身体倒是很诚实. 接过需求,好在需求不复杂, 简单构思 后 ...
- 地图POI类别标签体系建设实践
导读 POI是“Point of interest”的缩写,中文可以翻译为“兴趣点”.在地图上,一个POI可以是一栋房子.一个商铺.一个公交站.一个湖泊.一条道路等.在地图搜索场景,POI是检索对象, ...
- 【DDD/CQRS/微服务架构案例】在Ubuntu 14.04.4 LTS中运行WeText项目的服务端
在<WeText项目:一个基于.NET实现的DDD.CQRS与微服务架构的演示案例>文章中,我介绍了自己用Visual Studio 2015(C# 6.0 with .NET Frame ...
- WeText项目的服务端
WeText项目的服务端 在<WeText项目:一个基于.NET实现的DDD.CQRS与微服务架构的演示案例>文章中,我介绍了自己用Visual Studio 2015(C# 6.0 wi ...
- Nacos源码系列—服务端那些事儿
点赞再看,养成习惯,微信搜索[牧小农]关注我获取更多资讯,风里雨里,小农等你,很高兴能够成为你的朋友. 项目源码地址:公众号回复 nacos,即可免费获取源码 前言 在上节课中,我们讲解了客户端注册服 ...
随机推荐
- 自定义ListView下拉刷新上拉加载更多
自定义ListView下拉刷新上拉加载更多 自定义RecyclerView下拉刷新上拉加载更多 Listview现在用的很少了,基本都是使用Recycleview,但是不得不说Listview具有划时 ...
- Python全栈工程师之从网页搭建入门到Flask全栈项目实战(1) - ES6标准入门和Flex布局
1.简述 1.什么是ES6?ES6, 全称 ECMAScript 6.0,是 JavaScript 的下一个版本标准,2015年6月份发版.ES6的主要目的是为了解决 ES5 的先天不足. 2.了解E ...
- react.js+easyui 做一个简单的商品表
效果图: import React from 'react'; import { Form, FormField, Layout,DataList,LayoutPanel,Panel, Lab ...
- 各大厂 C/C++ 编程规范详解
来吧!各大厂知名规范体系~ 各有特点各有侧重~ Google C++ Style Guide Google C++ Style Guide,[中文版],简称 GSG,谷歌的 C++ 编程规范,在国内有 ...
- 驱动开发:内核枚举进程与线程ObCall回调
在笔者上一篇文章<驱动开发:内核枚举Registry注册表回调>中我们通过特征码定位实现了对注册表回调的枚举,本篇文章LyShark将教大家如何枚举系统中的ProcessObCall进程回 ...
- Dubbo 原理和机制详解 (非常全面)
Dubbo 是一款Java RPC框架,致力于提供高性能的 RPC 远程服务调用方案.作为主流的微服务框架之一,Dubbo 为开发人员带来了非常多的便利. 大家好,我是 mikechen,专注分享「互 ...
- pip cmd下载速度慢解决方案
cmd下载速度慢不是电脑问题,而是下载的网站有网速限制,如pip,虽然没被墙,但由于是外网,网速极差,经常是几KB一秒,所以我们可以采用镜像服务器,即在命令后加上 -i https://pypi.tu ...
- python django搭建一个简易博客的解析(按照文件顺序逐一讲解)
上次讲解了一下各py文件的内容,但比较乱,所以这次整理了一个顺序版. 源代码请在http://github/Cheng0829/mysite自行下载 mysite: db.sqlite3:数据库文件. ...
- 从源码入手探究一个因useImperativeHandle引起的Bug
今天本来正在工位上写着一段很普通的业务代码,将其简化后大致如下: function App(props: any) { // 父组件 const subRef = useRef<any>( ...
- 鹅长微服务发现与治理巨作PolarisMesh实践-上
@ 目录 概述 定义 核心功能 组件和生态 特色亮点 解决哪些问题 官方性能数据 架构原理 资源模型 服务治理 基本原理 服务注册 服务发现 安装 部署架构 集群安装 SpringCloud应用接入 ...