利用Kafka的Assign模式实现超大群组(10万+)消息推送
引言
问题背景

问题分解
1)长连接网关要支持10万+用户在线
2)群ID到成员列表的转换
3)长连接网关之间的路由通信问题
解决方案
1)连接池
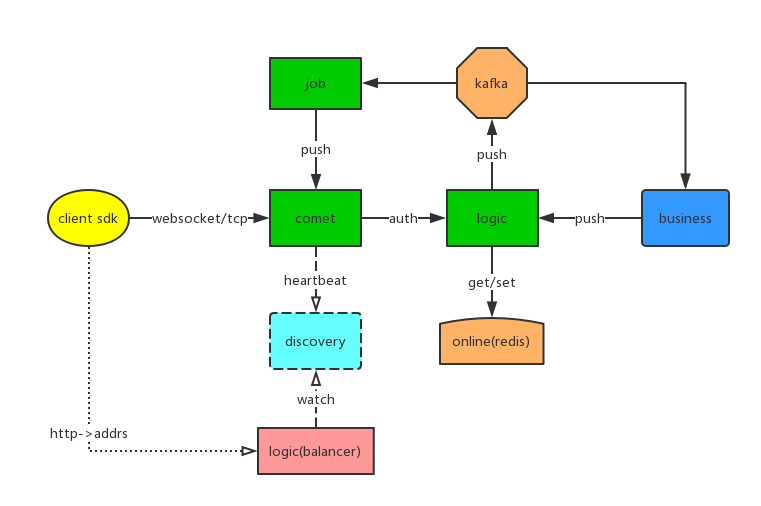
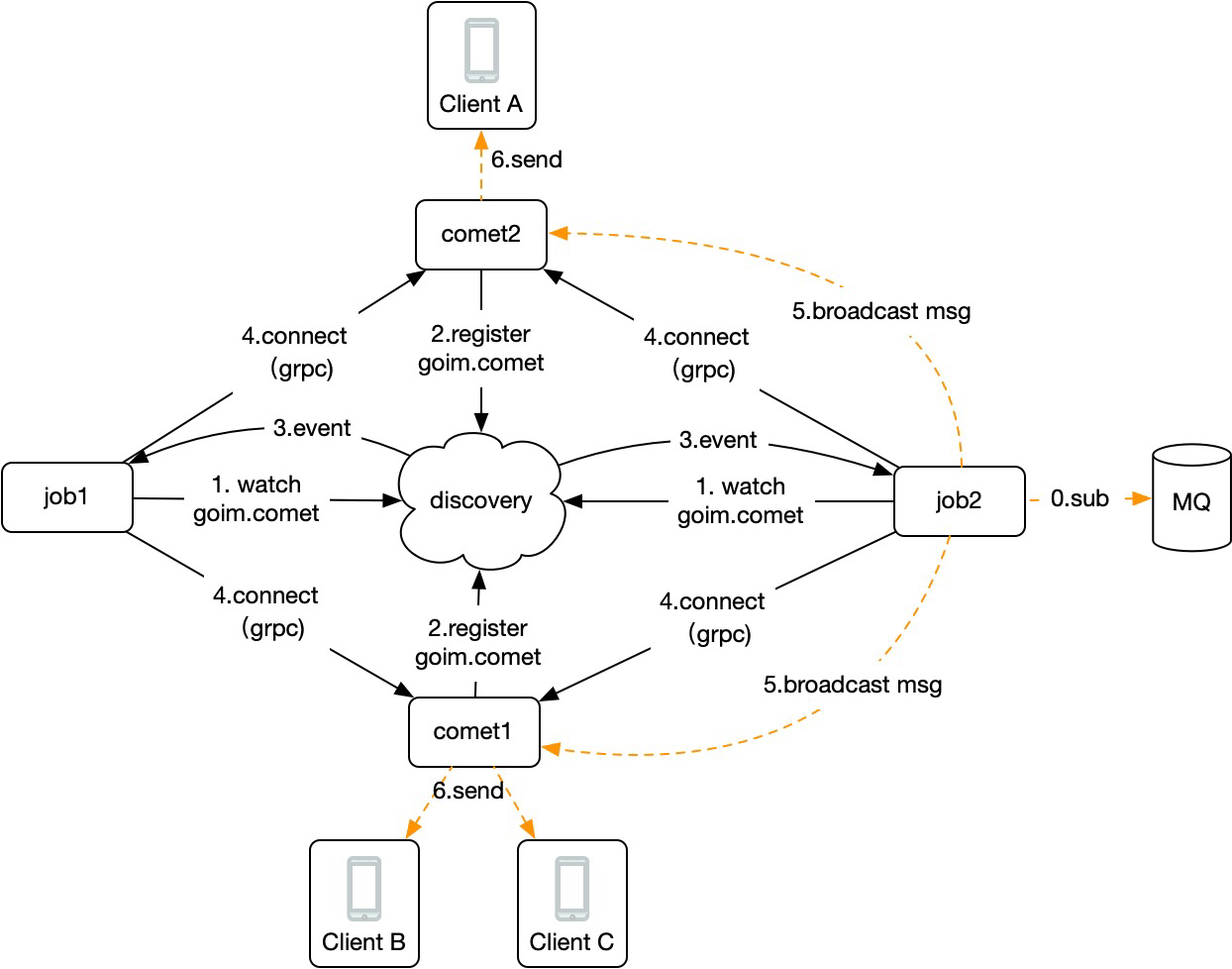
2)kafka实现
方式一:使用consumer group
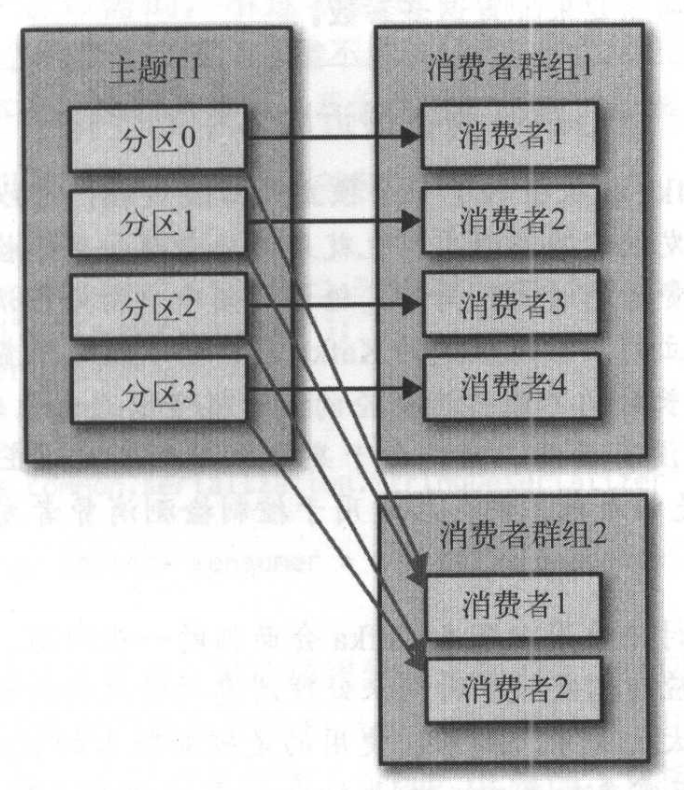
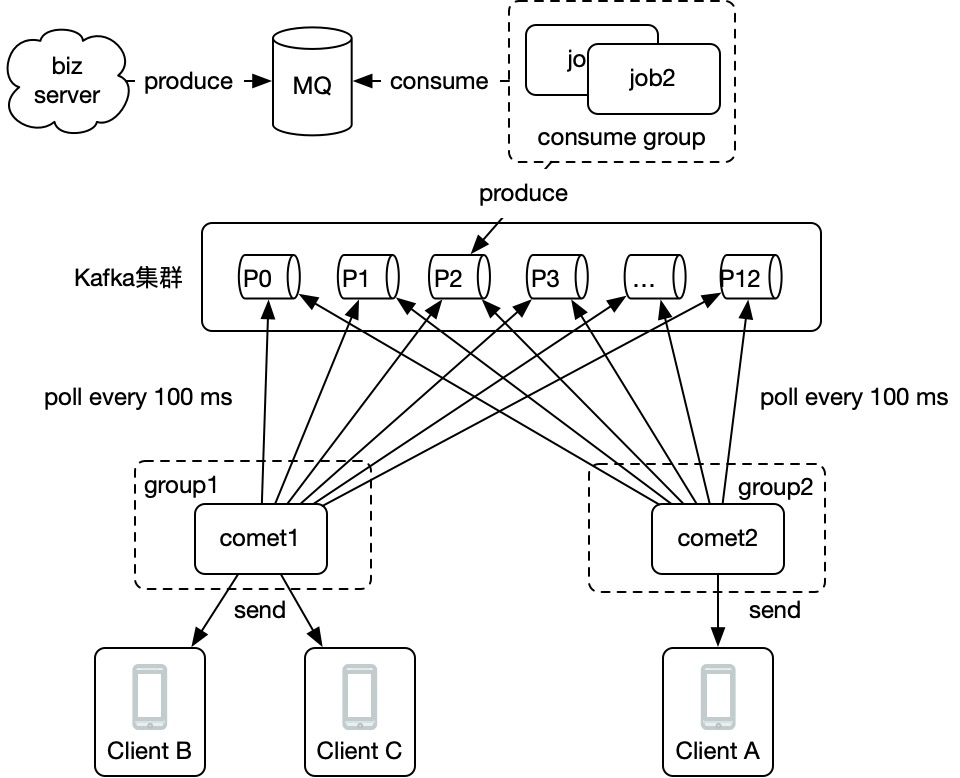

方式二:使用assign,手动订阅所有分区,不使用consumer group
consumer group vs assign模式
- 优点:分区的管理通过group自动实现,不用考虑新分区创建、新消费者加入等等情况。在kafka中还能很方便的看到每一个消费者的消费情况。
- 缺点:受限于云产品的group数量限制,再加上k8s动态启动容器,故需要开发额外的group name分配服务来动态分配提前创建好的group name。
- 优点:不需要创建consumer group,简单方便。
- 缺点:由于是程序自己管理分区,故 kafka tools 等工具上看不到消费情况,消息堆积情况等等。另外如果新增分区,要么重启程序,要么程序中定时拉取,kafka需要预先就估算创建好分区数量,有一定难度。
Assign模式代码实现
assign模式由来
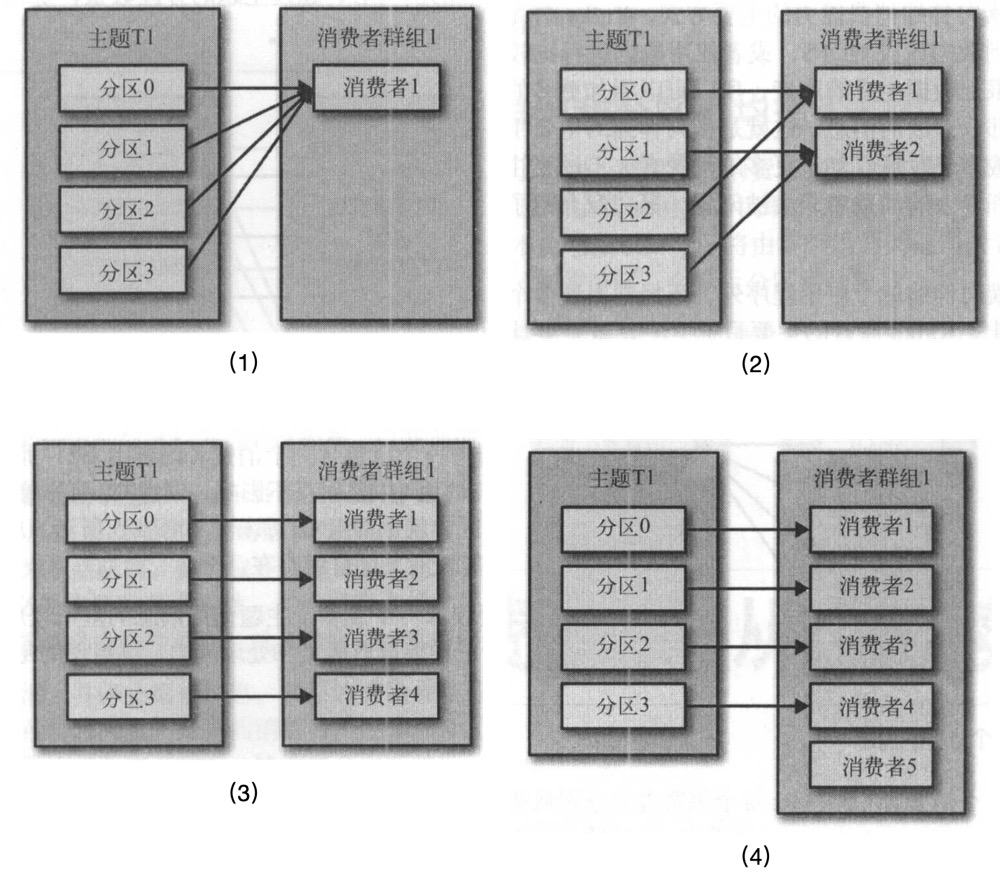
- subscribe:为consumer自动分配partition,有内部算法保证topic-partition以最优的方式均匀分配给同group下的不同consumer
// Subscribe to the given list of topics to get dynamically assigned partitions.
void subscribe(Collection<String> topics, ConsumerRebalanceListener listener)
- assign:为consumer手动、显示的指定需要消费的topic-partitions,不受group.id限制,相当于指定的group无效(this method does not use the consumer's group management)
// Manually assign a list of partitions to this consumer.
void assign(Collection<TopicPartition> partitions)
go中代码实现
package main import (
"context"
"sync"
"time" "github.com/Shopify/sarama"
) type ConsumerHandler func(partition int32, partitionConsumer sarama.PartitionConsumer, message *sarama.ConsumerMessage) func NewConsumer(addrs []string, config *sarama.Config) (sarama.Consumer, error) {
if config == nil {
config = sarama.NewConfig()
// Aliyun kafka version 2.2.0
config.Version = sarama.V2_0_0_0
}
return sarama.NewConsumer(addrs, config)
} // Consume start consume, will block until exit, call in `goroutine`
// note: `handle` called in `goroutine`
func Consume(ctx context.Context, consumer sarama.Consumer, topic string, handle ConsumerHandler) error {
defer consumer.Close() // 获取所有分区
partitions, err := consumer.Partitions(topic)
if err != nil {
return err
} // 消费所有分区
waitGroup := sync.WaitGroup{}
for k, part := range partitions {
p, err := consumer.ConsumePartition(topic, part, sarama.OffsetNewest)
if err != nil {
return err
} waitGroup.Add(1)
go func(partition int32, partitionConsumer sarama.PartitionConsumer) {
defer waitGroup.Done()
defer partitionConsumer.AsyncClose() for {
select {
case <-ctx.Done():
return
case m := <-partitionConsumer.Messages():
handle(partition, partitionConsumer, m)
default:
time.Sleep(time.Millisecond)
}
}
}(int32(k), p)
}
waitGroup.Wait()
return nil
}
main.go中使用:
func main() {
// create and start consumer
consumer, err := NewConsumer(kafkaAddr, nil)
if err != nil {
panic(err)
}
for {
log.Println("consumer is running...")
// will block
err := Consume(context.Background(), consumer, topic, func(partition int32, partitionConsumer sarama.PartitionConsumer, message *sarama.ConsumerMessage) {
log.Println("consumer new mq, paritition=", partition, ",topic:", message.Topic, ",offset:", message.Offset)
})
if err != nil {
log.Println(err)
} else {
log.Println("consume exit")
}
time.Sleep(time.Second * 3)
}
}
producer代码:
func startProducer(addrs []string, topic string) {
config := sarama.NewConfig()
config.Producer.RequiredAcks = sarama.WaitForAll
config.Producer.Partitioner = sarama.NewRandomPartitioner
config.Producer.Return.Successes = true
producer, err := sarama.NewSyncProducer(addrs, config)
if err != nil {
panic(err)
}
for i := 0; i < 1000; i++ {
p, offset, err := producer.SendMessage(&sarama.ProducerMessage{
Key: sarama.StringEncoder(strconv.Itoa(i)),
Value: sarama.StringEncoder("hello" + strconv.Itoa(i)),
Topic: topic,
})
if err != nil {
log.Println(err)
} else {
log.Println("produce success, partition:", p, ",offset:", offset)
}
time.Sleep(time.Second)
}
log.Println("exit producer.")
}
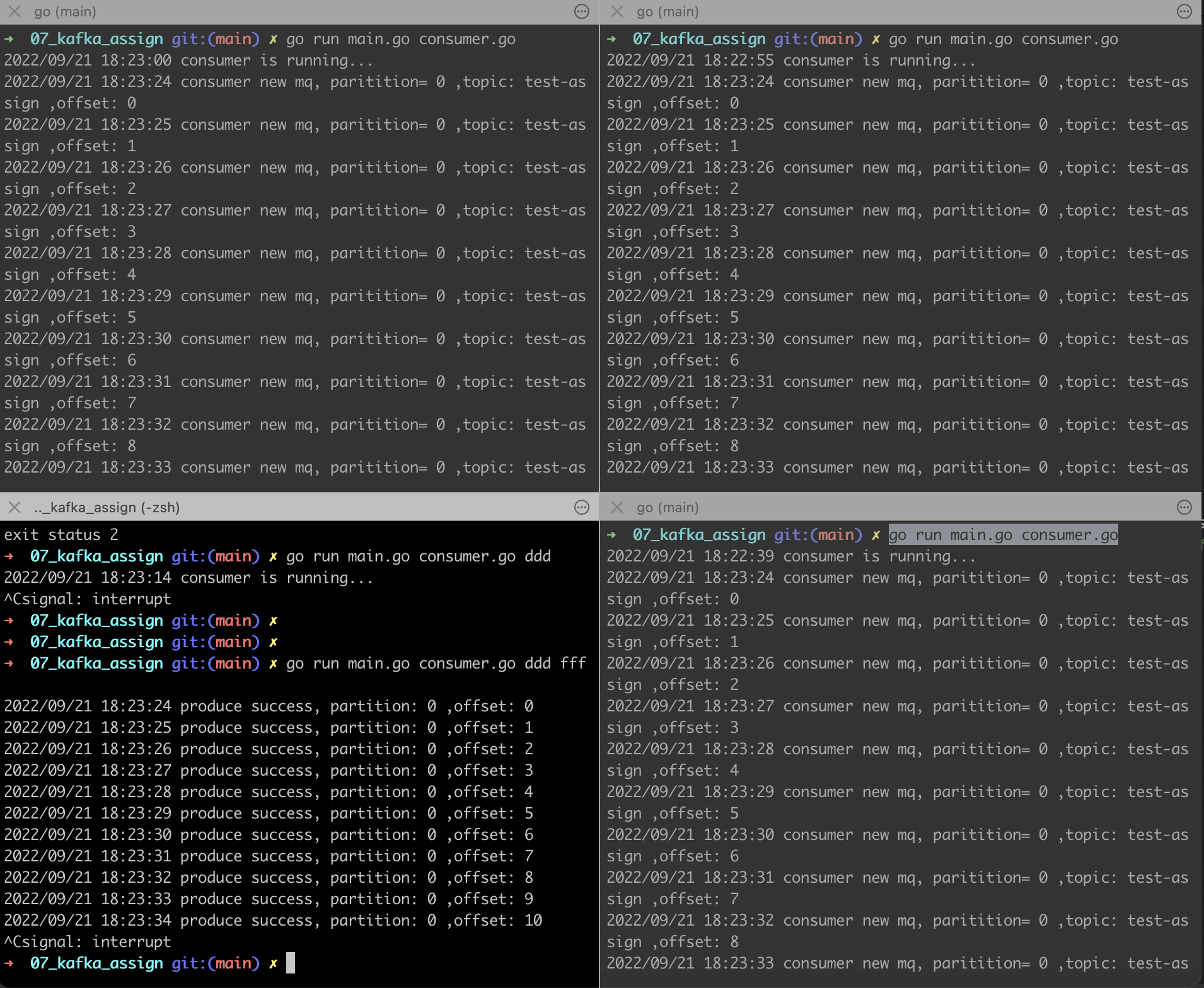
效果如下:
加餐:epoll和连接池的应用以及其局限
1)单体性能
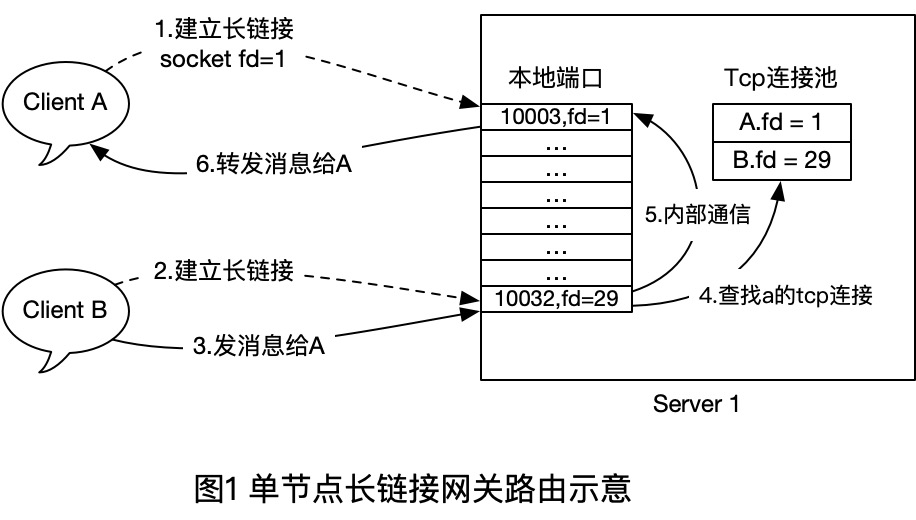
- 首先客户端A和B都和Server1建立TCP长连接,建立时,Server1在内存中插入一条 `User - TcpConn` 的关系,断开时,移除一个对应的关系。
- 当B 给 A发消息时,服务端直接使用本地维护的路由表(连接池)来查找对方的soket句柄,然后Send()到对方的Tcp连接即可。
map[int64]tcp.Conn
2)水平扩展和信息孤岛
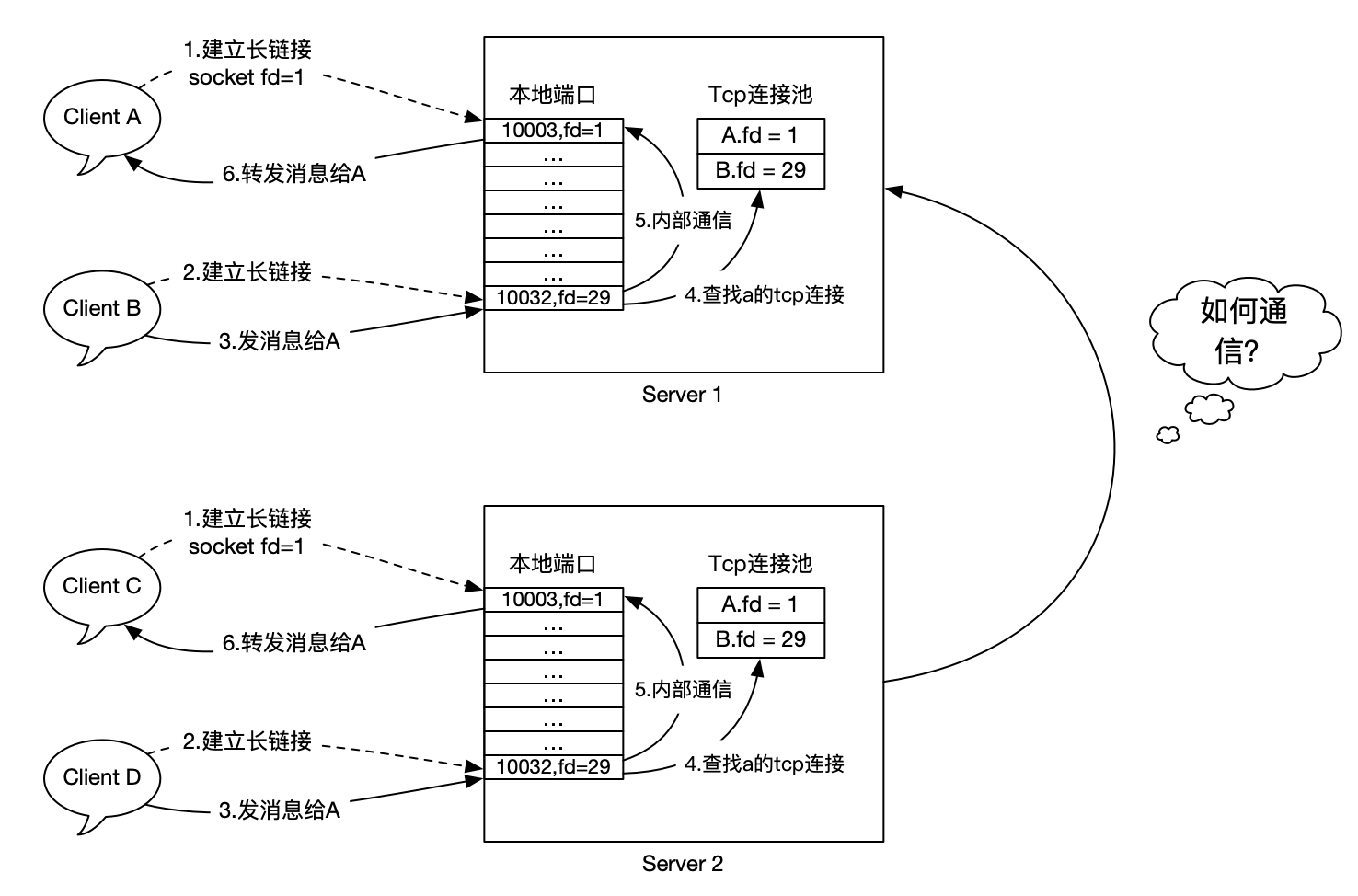
- 分布式路由表。在某个地方统一存放用户登录的节点,推送的时候倒查即可。
- 服务广播。给所有服务器广播消息,那么在该服务器上的用户自然也能收到。
总结
利用Kafka的Assign模式实现超大群组(10万+)消息推送的更多相关文章
- spring websocket 和socketjs实现单聊群聊,广播的消息推送详解
spring websocket 和socketjs实现单聊群聊,广播的消息推送详解 WebSocket简单介绍 随着互联网的发展,传统的HTTP协议已经很难满足Web应用日益复杂的需求了.近年来,随 ...
- Knative 实战:基于 Kafka 实现消息推送
作者 | 元毅 阿里云智能事业群高级开发工程师 导读:当前在 Knative 中已经提供了对 Kafka 事件源的支持,那么如何基于 Kafka 实现消息推送呢?本文作者将以阿里云 Kafka 产品为 ...
- MPush开源消息推送系统:简洁、安全、支持集群
引言由于之前自己团队需要一个消息推送系统来替换JPUSH,一直找了很久基本没有真正可用的开源系统所有就直接造了个轮子,造轮子的时候就奔着开源做打算的,只是后来创业项目失败一直没时间整理这一套代码,最近 ...
- dwr消息推送和tomcat集群
网友的提问: 项目中用到了dwr消息推送.而服务端是通过一个http请求后 触发dwr中的推送方法.而单个tomcat中.服务器发送的http请求和用户都在一个tomcat服务器中.这样就能精准推送到 ...
- Java Socket聊天室编程(一)之利用socket实现聊天之消息推送
这篇文章主要介绍了Java Socket聊天室编程(一)之利用socket实现聊天之消息推送的相关资料,非常不错,具有参考借鉴价值,需要的朋友可以参考下 网上已经有很多利用socket实现聊天的例子了 ...
- JBoss 系列十九:使用JGroups构建块RspFilter对群组通信返回消息进行过滤
内容概述 本部分说明JGroups构建块接口RspFilter,具体提供一个简单示例来说明如何使用JGroups构建块RspFilter对群组通信返回消息进行过滤. 示例描述 我们知道构建块基于通道之 ...
- (七)RabbitMQ消息队列-通过fanout模式将消息推送到多个Queue中
原文:(七)RabbitMQ消息队列-通过fanout模式将消息推送到多个Queue中 前面第六章我们使用的是direct直连模式来进行消息投递和分发.本章将介绍如何使用fanout模式将消息推送到多 ...
- SignalR快速入门 ~ 仿QQ即时聊天,消息推送,单聊,群聊,多群公聊(基础=》提升)
SignalR快速入门 ~ 仿QQ即时聊天,消息推送,单聊,群聊,多群公聊(基础=>提升,5个Demo贯彻全篇,感兴趣的玩才是真的学) 官方demo:http://www.asp.net/si ...
- APNS IOS 消息推送沙盒模式和发布模式
在做.NET向IOS设备的App进行消息推送时候,采用的是PushSharp开源类库进行消息的推送,而在开发过程中,采用的是测试版本的app,使用的是测试的p12证书采用的是ApnsConfigura ...
随机推荐
- vscode的安装、切换为中文简体、集成sass
VScode设置中文 打开vscode ,按快捷键"Ctrl+Shift+P" 输入configure language,回车 选择安装其他语言 (默认是英文的) 选择简体中安装( ...
- 数据结构-查找-二叉排序查找(平衡二叉树,B树,B+树概念)
0.为什么需要二叉排序树 1)数组存储方式: 优点:通过下标访问元素,速度快,对于有序数组,可以通过二分查找提高检索效率: 缺点:如果检索具体某个值,或者插入值(按一定顺序)会整体移动,效率较低: 2 ...
- 使用 spring-security-oauth2 体验 OAuth 2.0 的四种授权模式
目录 背景 相关代码 授权码模式 第一步 访问GET /oauth/authorize 第二步 访问POST /oauth/authorize 第三步 访问POST /oauth/token 简化模式 ...
- 基于 Rainbond 部署 DolphinScheduler 高可用集群
本文描述通过 Rainbond 云原生应用管理平台 一键部署高可用的 DolphinScheduler 集群,这种方式适合给不太了解 Kubernetes.容器化等复杂技术的用户使用,降低了在 Kub ...
- 关于ios的IDFA
了解IDFA,看我这篇文章就够了双11剁手后,我静静的限制了广告追踪 今年双11爆了,据统计,全天交易额1207亿,移动端占比82%,在马云的持续教育和移动端的爆发下,用户在移动端消费的习惯已经不可逆 ...
- 20170622日行一记之PHP函数
fread() 函数读取文件(可安全用于二进制文件) fread(file,length) 参数 描述 file 必需.规定要读取打开文件. length 必需.规定要读取的最大字节数. 该函数在读取 ...
- mysql导出bug备注
注:yiicms库和area表均存在
- 小白之Python基础(二)
一.字符串 1.字符串编码发展: 1)ASCII码: 一个字节去表示 (8个比特(bit)作为一个字节(byte),因此,一个字节能表示的最大的整数就是255(二进制11111111 = 十进制255 ...
- 使用JMeter进行MySQL的压力测试
GreatSQL社区原创内容未经授权不得随意使用,转载请联系小编并注明来源. GreatSQL是MySQL的国产分支版本,使用上与MySQL一致. 目录 前言 1. JMeter安装 2. 导入MyS ...
- idea+SpringBoot使用过程中的问题集合
1.跨域访问外部接口? 使用Nginx代理(详细参见:https://www.cnblogs.com/ZhaoHS/p/16594619.html): 合并部署,统一从后端访问第三方接口(合并部署详见 ...