Kibana探索数据(Discover)详解
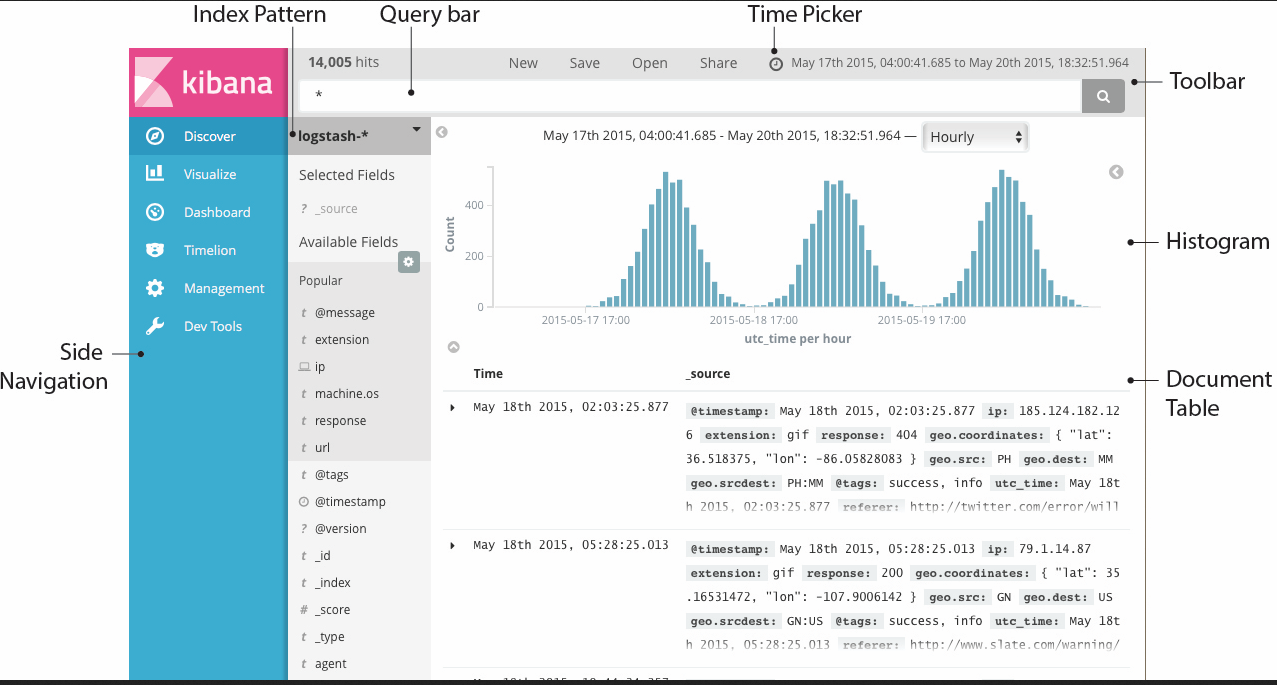
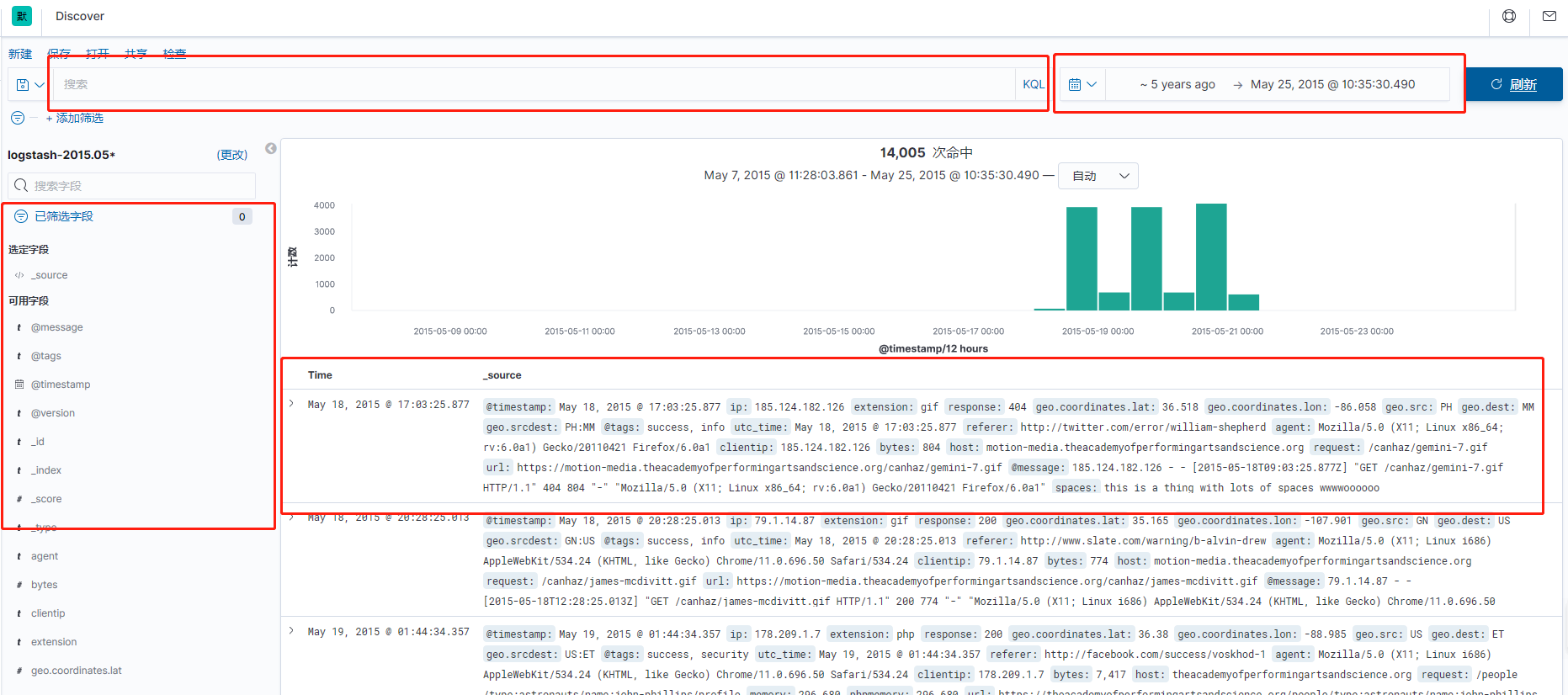
设置时间过滤器
时间过滤器按照指定的时间段展示搜索结果。设置了 index contains time-based events 和 time-field 的索引模式可以使用时间过滤器。
时间过滤器默认的时间段为最近15分钟。您可以使用页面顶部的 Time Picker 来调整时间段和刷新频率。
通过 Time Picker 设置时间过滤器:
1.点击 Kibana 工具栏中的 Time Picker time picker 。
2.可以通过点击一个时间段设置快速过滤。
3.可以基于当前时间来设置相对时间过滤器,点击 Relative 后选择数字和时间单位(秒、分、时、天、月、年)来指定当前时间多久之前是开始时间。也可以用同样的方式指定当前多久之后为结束时间。相对时间既可以是过往也可以是将来。
4.可以点击 Absolute ,通过修改 To 和 From 字段直接指定开始时间和结束时间。
5.点击工具条下方最右侧的脱字符图标来关闭 Time Picker 。
用如下两种方式可以通过直方图来设置时间过滤器:
- 直接点击直方图上的一根柱子来放大对应的时间段。
- 通过拖拽的方式指定时间段。当光标在图表的背景上变成一个加号时,代表这是可以选取的时间段。
可以点击 Time Picker 左边和右边的箭头来选择上一个或下一个时间段:
您可以通过浏览器的返回按钮进行撤销操作。
时间段和刷新周期会在直方图上展示。默认情况下,刷新周期会根据时间段来自动设置。也可以可以通过页面上的链接手动设置刷新周期。
搜索数据
通过在搜索栏输入搜索条件,您可以在匹配当前索引模式的索引中进行搜索。您可以进行简单的文本查询,或使用 Lucene 语法,或使用基于 JSON 的 Elasticsearch 查询 DSL 。
提交一次搜索请求后,直方图、文档列表、字段列表会按新的搜索结果来展示。工具栏上会展示命中的文档数量。文档列表会展示前5条命中的文档。默认情况下,文档列表会按时间倒序进行排列,最新的文档显示在最上面。您可以点击时间字段的表头来调整顺序。您可以基于任何索引字段来指定列表的顺序。可以参考 Sorting the Documents Table 获取更多信息。
搜索栏输入您的搜索条件,然后回车或点击 Search search button 来向 Elasticsearch 提交搜索请求。
- 直接输入文本字符串来进行简单文本搜索。例如,查询 Web 服务器日志的时候输入 safari 来搜索所有字段中包含词条 safari 的文档。
- 可以用字段名作为前缀来根据指定字段进行搜索。例如,输入 status:200 来搜索字段 status 中包含词条 200 的文档。
- 可以通过中括号指定范围搜索, [START_VALUE TO END_VALUE] 。例如,搜索状态为 4xx 的条目,您可以输入 status:[400 TO 499] 。
- 您可以通过布尔操作符 AND 、 OR 和 NOT 来指定更多的搜索条件。例如,搜索状态为 4xx 而且扩展名为 php 或 html 的条目,您可以输入 status:[400 TO 499] AND (extension:php OR extension:html) 。
保存搜索
搜索保存后可以在下次使用数据探索的时候被重新载入并作为可视化的基础条件。保存搜索的时候既保存了查询字符串,也保存了当前选择的索引模式。
保存当前的搜索:
- 点击 Kibana 工具栏的 Save 。
- 输入搜索的名称然后点击 Save 。
您可以在 Management/Kibana/Saved Objects 导入、导出或删除已经保存的搜索。
打开已经保存的搜索
在搜索栏载入已经保存的搜索:
- 在 Kibana 工具栏点击 Open 。
- 选择您要打开的搜索。
如果打开的搜索是关联到非当前索引模式的,打开这个搜索的同时会同时改变选择的索引模式。
更改要搜索的索引
提交一个搜索请求后,会在匹配当前索引模式的索引中进行搜索。当前的模式会展示在工具栏上。如果要改变需要搜索的索引模式,请点击这个索引模式然后选择另外一个。
刷新搜索结果
随着越来越多的文档被加入您要搜索的索引中,视图中展示的搜索结果会变得越陈旧。您可以设置刷新频率来周期性的提交搜索请求,以获取最新的结果。
开启自动刷新:
- 点击 Kibana 工具栏中的 Time Picker Time Picker 。
- 点击 Auto refresh 。
自动刷新开启后,刷新频率会和一个 Pause 按钮一起展示在 Time Picker 旁边。点击 Pause 可以临时性的暂停自动刷新。
如果自动刷新没有打开,您可以手动点击 Refresh 来刷新视图。
根据字段过滤
可以对搜索结果进行过滤,只显示包含特定字段值的文档。也可以创建否定过滤器,排除包含特定字段值的文档。
从 Fields 表或 Documents 表中选择要添加的字段过滤器。除了可以创建积极字段和消极过滤器外,Documents 表还可以过滤某一字段是否存在。使用过的过滤器会在 Query 栏下方显示。消极过滤器用红色显示。
从 Fields 列表中添加一个过滤器:
1.点击想要过滤的字段名。这里显示了该领域最常用的五个字段值。
2.添加积极过滤器,请点击 Positive Filter 按钮。这会只显示包含该字段值的文档。
3.添加消极过滤器,请点击 Negative Filter 按钮。这会排除包含该字段值的文档。
从 Documents 表中添加一个过滤器:
1.通过点击文档表条目左侧的 Expand 按钮 Expand Button 展开 Documents 表中的一个文档。
2.添加积极过滤器,请点击该字段名右侧的 Positive Filter 按钮。这会只显示包含该字段值的文档。
3.添加消极过滤器,请点击该字段名右侧的 Negative Filter 按钮。这会排除包含该字段值的文档。
4.过滤文档是否包含某一字段,请点击该字段名右侧的 Exists 按钮。这会只显示包含该字段的文档。
管理过滤器
修改一个过滤器,请将鼠标置于该过滤器,然后点击某个操作按钮。
- 启动过滤器
禁用过滤器不会删除过滤器。再次点击会重启过滤器。斜条纹表示过滤器被禁用。 - 固定过滤器
当把上下文切换为 Kibana 时,被固定的过滤器仍然有效。例如,在 Discover 中固定一个过滤器,若切换至 Visualize,该过滤器仍然存在。请注意,过滤器是基于某个特定的索引字段——如果搜索的索引不包含固定过滤器中的字段,将不会生效。 - 切换筛选器
在积极过滤器和消极过滤器之间转换。 - 移除过滤器
- 编辑过滤器
编辑过滤器定义。可用于手动更新过滤查询和为过滤器指定标签。
对所有已应用的过滤器进行一次过滤,点击 Actions 并选择过滤指令。
查看文档数据
提交一个搜索查询后,Documents 表中就会列出500个匹配查询的最新文档。您可以通过 Advanced Settings 中的 discover:sampleSize 设置表中显示的文档个数。默认情况下,该表显示的是为所选索引模式和文本 _source 配置的时间域的本地化版本。 您可以从 Fields 表中选择字段向 Documents 表中添加。您可以通过表中包含的任意索引字段对所列文档进行排序。
查看文档的字段数据,请击该文档表项目左侧的 Expand 按钮。
查看原始 JSON 文档(整齐打印),请点击 JSON 标签。
以单独页面查看文档数据,请点击 View single document 链接。可以通过收藏和分享本链接来实现对特定文档的直接访问。
显示或隐藏 Documents 表中的某一个字段所在的列,请点击 Add Column Toggle column in table 按钮。
折叠文档细节,请点击 Collapse 按钮。
整理文档列表
可以根据任意索引字段值对 Documents 表中的文档进行分类。如果为当前索引模式配置一个时间字段,文档将默认按照反向时间顺序排列。
若要改变排列顺序,鼠标放在您想分类的字段名上,然后点击分类按钮。再次点击将反向排序。
向文档表中添加字段列
默认情况下, Documents 表显示的是为所选索引模式和 _source 文档配置的时间字段的本地化版本。 您可以从 Fields 列表或文档的字段数据中选择字段向文档表中添加。
从 Fields 列表中添加字段列,请将鼠标放在该字段上,并点击该字段的 add 按钮。
从文档的字段数据中添加字段列,请展开文档并点击该字段的 Add Column Toggle column in table 按钮。
添加的字段列会取代 Documents 表中的 _source 列。添加的字段也会被添加到 Selected Fields 列表中。
重新排列字段列,请将鼠标置于想要移动的列的标题上,然后点击 Move left 或 Move right 按钮。
从文档表中移除字段列
从文档表中移除一个字段列,请将鼠标置于想要移除的列的标题处,然后点击 Remove 按钮。
查看文档上下文
对于某些应用程序来说,窗口查看围绕特定主题的多个文档是很有用的。上下文视图能够帮助设置包含时序性事件的索引模式。
想要显示与锚文档相关的上下文,点击文档表条目左侧的 Expand 按钮 Expand Button ,然后点击 View surrounding documents 链接。
上下文视图会显示锚文档前后的多个文档。锚文档会用蓝色突出显示。该视图是根据索引模式配置的时间字段而检索出的结果,并使用 Discover 浏览上下文时打开的组列。
默认显示的文档数量可以通过 Management > Advanced Options 中的 context:defaultSize 设置。
改变上下文数量
可以单独改变锚文档前后的文档显示数量。
想要增加比锚文档更新文档的显示数量, 点击文档列表上方的Load 5 more 按钮,或者在该按钮右侧的输入框中输入所需的数量。
想要增加比锚文档更旧文档的显示数量,点击文档列表下方的 Load 5 more 按钮,或者在该按钮右侧的输入框中输入所需的数量。
每次点击按钮默认加载的文档数量能够通过 Management > Advanced Options 中的 context:step 配置。

展示字段数据统计
通过 Fields 列表, 您可以看到文档列表里面有多少文档包含特定的字段,这个字段排名前5的值是什么,包含每一个值的文档所占的百分比是多少。
在字段列表里面点击字段名称,可以展示字段数据统计。
Kibana探索数据(Discover)详解的更多相关文章
- Kibana探索数据(Discover)
总结说明: 1.先在Management/Kibana/Index Patterns 界面下添加索引模式(前提是有索引数据) 2.在Discover界面选中响应的索引模式 3.开启Kibana 查询语 ...
- Kibana可视化数据(Visualize)详解
可视化 (Visualize) 功能可以为您的 Elasticsearch 数据创建可视化控件.然后,您就可以创建仪表板将这些可视化控件整合到一起展示. Kibana 可视化控件基于 Elastics ...
- 深入浅出DOM基础——《DOM探索之基础详解篇》学习笔记
来源于:https://github.com/jawil/blog/issues/9 之前通过深入学习DOM的相关知识,看了慕课网DOM探索之基础详解篇这个视频(在最近看第三遍的时候,准备记录一点东西 ...
- Dom探索之基础详解
认识DOM DOM级别 注::DOM 0级标准实际并不存在,只是历史坐标系的一个参照点而已,具体的说,它指IE4.0和Netscape Navigator4.0最初支持的DHTML. 节点类型 注:1 ...
- ContentProvider数据访问详解
ContentProvider数据访问详解 Android官方指出的数据存储方式总共有五种:Shared Preferences.网络存储.文件存储.外储存储.SQLite,这些存储方式一般都只是在一 ...
- 【HANA系列】SAP HANA XS使用JavaScript数据交互详解
公众号:SAP Technical 本文作者:matinal 原文出处:http://www.cnblogs.com/SAPmatinal/ 原文链接:[HANA系列]SAP HANA XS使用Jav ...
- JVM 运行时数据区详解
一.运行时数据区 Java虚拟机在执行Java程序的过程中会把它所管理的内存划分为若干个不同数据区域. 1.有一些是随虚拟机的启动而创建,随虚拟机的退出而销毁,所有的线程共享这些数据区. 2.第二种则 ...
- 学习《深度学习与计算机视觉算法原理框架应用》《大数据架构详解从数据获取到深度学习》PDF代码
<深度学习与计算机视觉 算法原理.框架应用>全书共13章,分为2篇,第1篇基础知识,第2篇实例精讲.用通俗易懂的文字表达公式背后的原理,实例部分提供了一些工具,很实用. <大数据架构 ...
- 【HANA系列】【第一篇】SAP HANA XS使用JavaScript数据交互详解
公众号:SAP Technical 本文作者:matinal 原文出处:http://www.cnblogs.com/SAPmatinal/ 原文链接:[HANA系列][第一篇]SAP HANA XS ...
随机推荐
- shell查询prometheus数据
#shell查询prometheus数据 shell使用curl调用HTTP API执行PromQL /api/v1/query查询某一时刻的数据 查询条件PromSQL复杂时, 传入接口/api/v ...
- Tampermonkey究竟有什么用?
以具体应用实例加以说明. 目标:在youtube页面上观看视频,发现喜欢的视频,单击按钮就可以下载视频. 但是,youtube页面并未提供这样的按钮及其功能. 实现思路:在浏览器下载youtube页面 ...
- 基于WPF重复造轮子,写一款数据库文档管理工具(一)
项目背景 公司业务历史悠久且复杂,数据库的表更是多而繁杂,每次基于老业务做功能开发都需要去翻以前的表和业务代码.需要理解旧的表的用途以及包含的字段的含义,表少还好说,但是表一多这就很浪费时间,而且留下 ...
- Nmap 操作手册 - 完整版
目录 Nmap - 基础篇 Nmap 安装 RedHat Windows Debina & Ubuntu Others Linux Nmap 参数(简单版) 目标说明 主机发现 扫描技术 端口 ...
- 关于javascript中this
------------恢复内容开始------------ 1 var number = 5; 2 var obj = { 3 number: 3, 4 fn1: (function () { 5 ...
- Java版的防抖(debounce)和节流(throttle)
概念 防抖(debounce) 当持续触发事件时,一定时间段内没有再触发事件,事件处理函数才会执行一次,如果设定时间到来之前,又触发了事件,就重新开始延时. 防抖,即如果短时间内大量触发同一事件,都会 ...
- benchmark性能测试
目录 benchmark介绍 benchmark运行 benchmark运行参数 benchmark性能测试案例 benchmark介绍 基准测试主要是通过测试CPU和内存的效率问题,来评估被测试代码 ...
- 【达人专栏】还不会用Apache Dolphinscheduler吗,大佬用时一个月写出的最全入门教学【二】
02 Master启动流程 2.1 MasterServer的启动 在正式开始前,笔者想先鼓励一下大家.我们知道启动Master其实就是启动MasterServer,本质上与其他SpringBoot项 ...
- Spring源码 13 IOC refresh方法8
本文章基于 Spring 5.3.15 Spring IOC 的核心是 AbstractApplicationContext 的 refresh 方法. 其中一共有 13 个主要方法,这里分析第 8 ...
- CSO视角:Sigstore如何保障软件供应链安全?
本文作者 Chris Hughes,Aquia的联合创始人及CISO,拥有近20年的网络安全经验. SolarWinds 和 Log4j 等影响广泛的软件供应链攻击事件引起了业界对软件供应链安全的关注 ...