带你了解CANN的目标检测与识别一站式方案
摘要: 了解通用目标检测与识别一站式方案的功能与特性,还有实现流程,以及可定制点。
本文分享自华为云社区《玩转CANN目标检测与识别一站式方案》,作者: Tianyi_Li。
背景介绍
目标检测与识别是计算机视觉领域中的关键技术,随着深度学习技术的发展,目标检测与识别的应用场景也越来越广泛。当前, 主要有以下几个应用场景:
安全领域:指纹识别、物体识别等。
交通领域:车牌号识别、无人驾驶、交通标志识别等。
医疗领域:心电图、B超、健康管理、营养学等。
生活领域:智能家居、智能购物、智能测肤等。
但当前人工智能应用开发面临着开发周期长、AI软件栈理解成本高、算法模型与业务结合难度高、对开发人员技能要求高等门槛。为了降低AI应用开发的门槛,昇腾CANN开源了高性能的通用目标检测与识别一站式方案,通过其强大的可定制、可扩展性,旨在为AI开发者们提供更好的编程选择。
特别提示,如果您具有以下知识储备,将有助于学习:
- 具有C&C++编程经验。
- 了解异构计算架构CANN在昇腾AI全栈中的位置和作用。
- 了解应用编程框架AscendCL的关键特性,并能够基于AscendCL接口开发简单的AI应用。
目标
- 了解通用目标检测与识别一站式方案的功能与特性
- 了解ACLlite的背景及接口使用方法
- 深入了解通用目标检测与识别一站式方案的实现流程
- 能够基于此方案定制自己的AI应用
目标检测与识别一站式方案介绍
方案特性
点此detect_and_classify,可查看方案源代码。
方案整体特性概括如下:

1.支持多格式输入和输出
通用目标检测和识别一站式方案支持图片、离线视频、RTSP视频流等多输入格式,开发者可基于此方案实现对图片和视频等不同格式的目标进行识别。另外在结果展示方面,支持图片、离线视频、Web前端等多形式展现,开发者可根据业务场景灵活呈现识别结果。
2.支持轻松替换和串接模型
该方案当前选用的是YoloV3图片检测模型与CNN颜色分类模型的串接,可实现基本的车辆检测和车辆颜色识别,开发者可轻松修改程序代码,自行替换/增加/删除AI模型,实现更多AI功能。
3.支持高效数据预处理
图片、视频等各类数据是进行目标检测和识别的原料,在把数据投入AI算法或模型前,我们需要对数据进行预加工,才能达到更加高效和准确的计算。该样例采用独立数据预处理模块,支持开发者按需定制,高效实现解码、抠图、缩放、色域转换等各种常见数据处理功能。
4.支持图片数、分辨率可变场景定制
在目标检测和识别领域,开发者们除了需要应对输入数据格式等方面差异,还会经常遇到图片数量、分辨率不确定的场景,这也是格外头疼的问题之一。比如,在目标检测和识别过程中,由于检测出的目标个数不固定,导致程序要等到图片攒到固定数量再进行AI计算,浪费了大量宝贵的AI计算资源。该样例开放了便捷的定制入口,支持设置多种数据量Batch档位、多种分辨率档位,在推理时根据实际输入情况灵活匹配,不仅扩宽了业务场景,更有效节省计算资源,大大提升AI计算效率。
5.支持多路多线程高性能编程
为了进一步提高编程的灵活性,满足开发者实现高性能AI应用,该样例支持通过极为友好和便捷的方式调整线程数和设备路数,极大降低学习成本,提升设备资源利用率。
6.高效后处理计算
除此之外,该样例后续还会将原本需要在CPU上进行处理的功能推送到昇腾AI处理器上执行,利用昇腾AI处理器强大的算力实现后处理的加速,进一步提升整个AI应用的计算效率。
实现流程
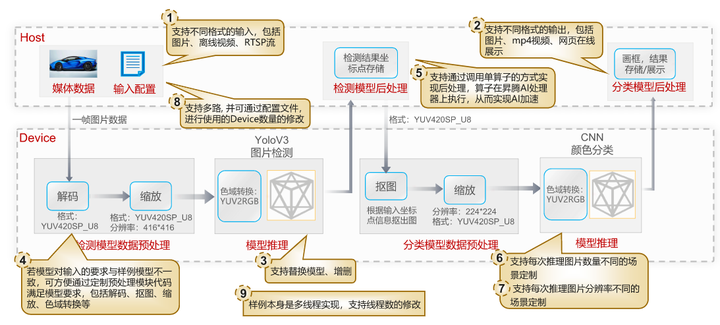
该样例使用了图片检测模型与颜色分类模型,基于CANN AI应用编程接口,对数据预处理、模型推理、模型后处理等AI核心计算逻辑进行模块化组装,实现了车辆检测和车身颜色识别基础功能,以输入图片是JPEG压缩图片为例,该样例功能流程如下所示:
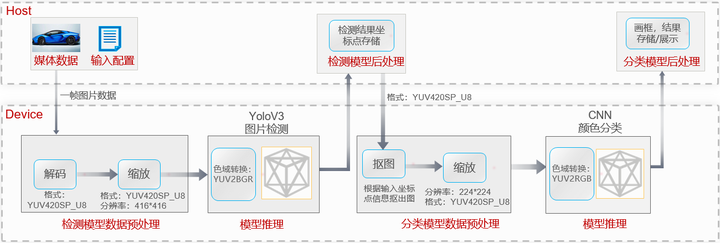
- 首先输入图片送入Device的DVPP进行数据预处理,因为模型的输入要求是非压缩的、指定编码格式的图片,所以首先使用DVPP进行图片的解码操作,解码后格式为YUV420SP_U8。
- 由于图片的大小与模型要求的大小不一致,解码后我们使用DVPP的VPC功能进行大小的调整。
- 经过前面的一系列处理后,输入到模型的编码格式YUV420SP_U8仍与模型要求不一致,此时我们可以在模型转换时通过AIPP的色域转换功能实现格式转换,将YUV420SP_U8格式转换为模型要求的BGR格式,这里的色域转换功能其实就相当于在模型中添加了一个色域转换算子,直接在模型推理前实现了编码格式的转换,而无需代码层面的修改。
- 检测模型推理后的结果就可以送入模型后处理模块,后处理模块根据业务流程需要,进行检测坐标点的存储。
- 下一步,就是将检测坐标点以及前面预处理后的YUV图片,一起送入分类模型的预处理模块,首先根据检测结果的坐标点信息对输入的图片进行抠图,然后再将其缩放为分类模型要求的大小。
- 由于颜色分类模型要求的图片编码格式是RGB,同前面的检测模型一样,需要使用AIPP的色域转换功能,在模型推理前将YUV转换为RGB。
- 最后对分类模型推理后的结果进行处理,在图片上进行画框,标注结果,并根据用户的输出要求进行存储或者在线展示。
快速体验
下面介绍让样例快速跑起来,了解通用目标检测与识别一站式方案的总体编译运行流程,主要是:
- 输入/输出数据都为图片,其中输入数据请选择jpeg格式的图片
- 使用1个Device运行
准备环境
这里不做过多介绍,使用的是ECS + 官方推送的镜像,很简单就能搞定了,需要注意的是环境准备好后,请以HwHiAiUser用户体验如下任务。HwHiAiUser用户下已经配置好了环境变量,安装好了应用所需基本依赖。
编译运行样例
因为镜像已经做好了配置,可以直接下载样例,模型与数据,直接编译运行即可。详细步骤如下:
步骤 1 :下载samples源码仓。
此处已将samples仓下载到$HOME路径下为例, 可以使用以下两种方式下载,请选择其中一种即可
【命令行下载】
cd ${HOME}
git clone https://gitee.com/ascend/samples.git
【压缩包下载】
a. 在samples仓右上角选择【克隆/下载】下拉框,并选择【下载ZIP】。
b. 将ZIP包以HwHiAiUser用户上传到开发环境的普通用户家目录中。
例如:${HOME}/ascend-samples-master.zip
c. 执行以下命令,解压缩zip包。
cd ${HOME}
unzip ascend-samples-master.zip
步骤 2 : 准备模型及数据。
请参见README中的模型及数据准备章节。
步骤 3 : 样例编译运行。
请参见README中的样例编译运行章节。
【说明】
- 输入/输出数据都要求为图片,其中输入数据请选择jpeg格式的图片
- 使用1个Device运行
结果输出
如下图所示,左图为运行的打印输出,右图为输出的推理结果图片:

此外,还支持多种输入输出模式:
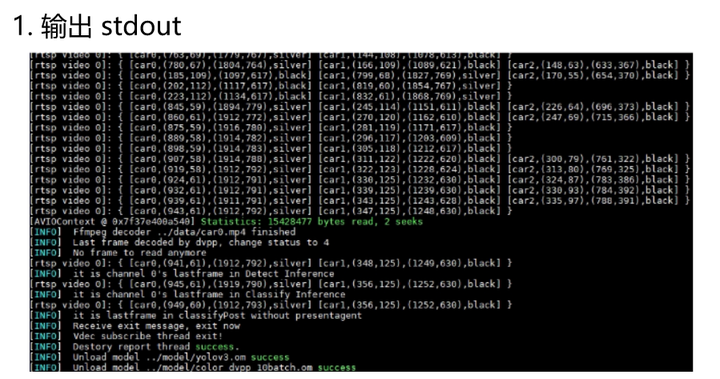
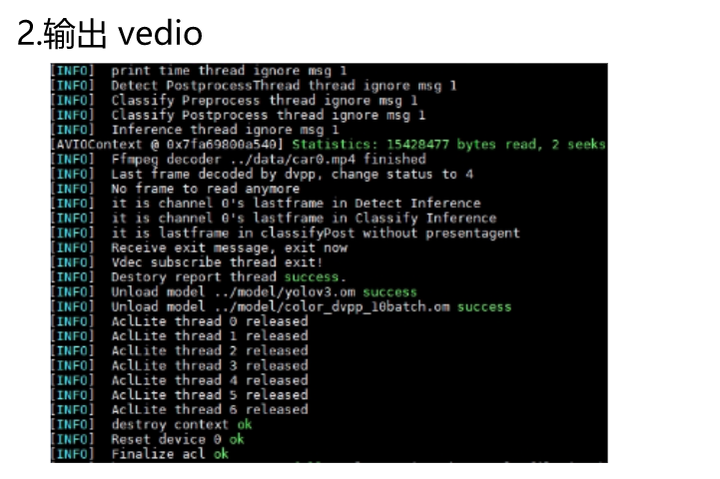
根据官方的测试,单device最多支持22路,在输入分辨率1280 * 720的视频下,单帧图像处理耗时20ms,每秒最大处理帧数为50帧。
结语
本次的CANN目标检测与识别一站式方案总体流程图如下图所示,
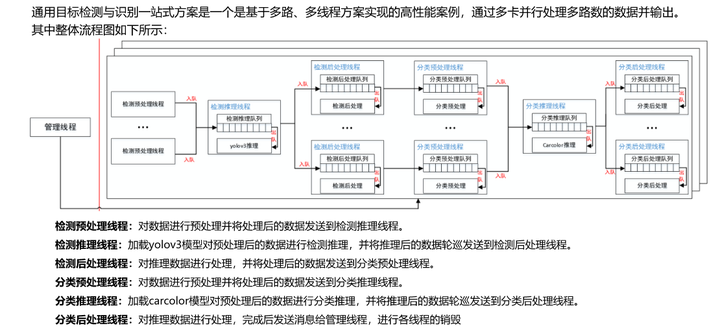
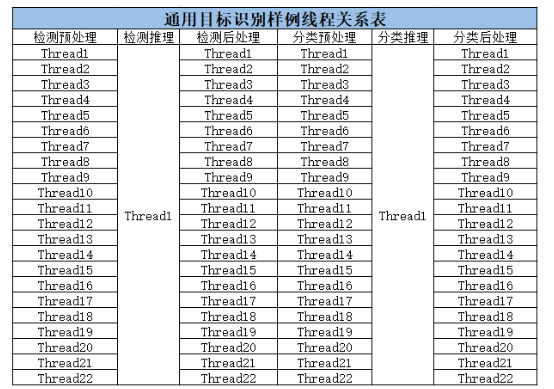
方案中大量使用了线程,多路线程分别进行数据流转和协同合作,以单device为例,线程关系如下图所示:
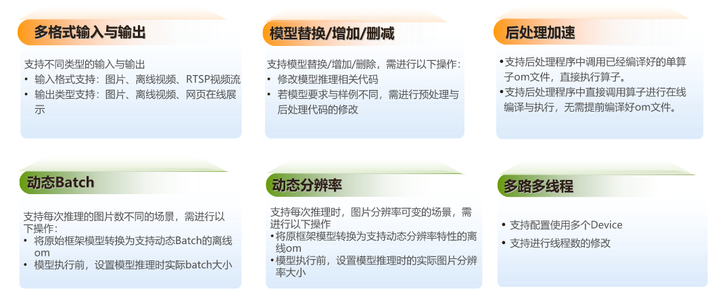
此外,还支持定制开发,开发者可根据需要,自行添加包括但不限于如下功能:
详细的操作位置如下图所示,具体可参考本方案代码库的README:
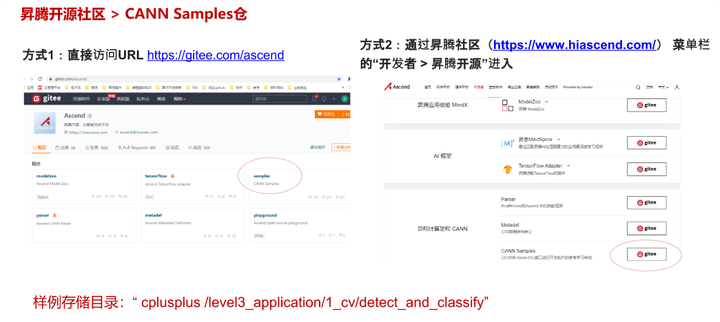
好了,最后奉上本方案代码库的获取方式,如下图所示,当然,也可以点击在前文中咱们提供的链接。
带你了解CANN的目标检测与识别一站式方案的更多相关文章
- 不带Anchors和NMS的目标检测
前言: 目标检测是计算机视觉中的一项传统任务.自2015年以来,人们倾向于使用现代深度学习技术来提高目标检测的性能.虽然模型的准确性越来越高,但模型的复杂性也增加了,主要是由于在训练和NMS后处理过 ...
- 第十八节、基于传统图像处理的目标检测与识别(HOG+SVM附代码)
其实在深度学习中我们已经介绍了目标检测和目标识别的概念.为了照顾一些没有学过深度学习的童鞋,这里我重新说明一次:目标检测是用来确定图像上某个区域是否有我们要识别的对象,目标识别是用来判断图片上这个对象 ...
- OpenCV 学习笔记 07 目标检测与识别
目标检测与识别是计算机视觉中最常见的挑战之一.属于高级主题. 本章节将扩展目标检测的概念,首先探讨人脸识别技术,然后将该技术应用到显示生活中的各种目标检测. 1 目标检测与识别技术 为了与OpenCV ...
- 第十九节、基于传统图像处理的目标检测与识别(词袋模型BOW+SVM附代码)
在上一节.我们已经介绍了使用HOG和SVM实现目标检测和识别,这一节我们将介绍使用词袋模型BOW和SVM实现目标检测和识别. 一 词袋介绍 词袋模型(Bag-Of-Word)的概念最初不是针对计算机视 ...
- 目标检测算法之YOLOv1与v2
YOLO:You Only Look Once(只需看一眼) 基于深度学习方法的一个特点就是实现端到端的检测,相对于其他目标检测与识别方法(如Fast R-CNN)将目标识别任务分成目标区域预测和类别 ...
- Faster-rcnn实现目标检测
Faster-rcnn实现目标检测 前言:本文浅谈目标检测的概念,发展过程以及RCNN系列的发展.为了实现基于Faster-RCNN算法的目标检测,初步了解了RCNN和Fast-RCNN实现目标检 ...
- 目标检测之行人检测(Pedestrian Detection)---行人检测之简介0
一.论文 综述类的文章 [1]P.Dollar, C. Wojek,B. Schiele, et al. Pedestrian detection: an evaluation of the stat ...
- 小白也能弄懂的目标检测之YOLO系列 - 第一期
大家好,上期分享了电脑端几个免费无广告且实用的录屏软件,这期想给大家来讲解YOLO这个算法,从零基础学起,并最终学会YOLOV3的Pytorch实现,并学会自己制作数据集进行模型训练,然后用自己训练好 ...
- 经典论文系列 | 目标检测--CornerNet & 又名 anchor boxes的缺陷
前言: 目标检测的预测框经过了滑动窗口.selective search.RPN.anchor based等一系列生成方法的发展,到18年开始,开始流行anchor free系列,CornerNe ...
随机推荐
- 「笔记」折半搜索(Meet in the Middle)
思想 先搜索前一半的状态,再搜索后一半的状态,再记录两边状态相结合的答案. 暴力搜索的时间复杂度通常是 \(O(2^{n})\) 级别的.但折半搜索可以将时间复杂度降到 \(O(2 \times 2^ ...
- git的工作原理和git项目创建及克隆
Git基本理论(重要)三个区域Git本地有三个工作区域:工作目录(Working Directory).暂存区(Stage/Index).资源库(Repository或Git Directory).如 ...
- thymeleaf实现前后端数据交换
1.前端传数据后端接收: 用户在登录界面输入用户名和密码传给后端controller,由后端判断是否正确! 在html界面中要传递的数据name命名,通过表单的提交按钮会传递给响应的controlle ...
- go-zero微服务实战系列(十一、大结局)
本篇是整个系列的最后一篇了,本来打算在系列的最后一两篇写一下关于k8s部署相关的内容,在构思的过程中觉得自己对k8s知识的掌握还很不足,在自己没有理解掌握的前提下我觉得也很难写出自己满意的文章,大家看 ...
- Solution -「线段树」题目集合
T1 无聊的数列 来自:Link flag 帖先从水题入手. 首先分析题目,它是以等差数列为原型进行的修改.等差数列一大性质就是其差分数列的值除第一项以外均相等. 于是不难想到使用差分数列进行维护. ...
- javaweb 03: jsp
JSP 我的第一个JSP程序: 在WEB-INF目录之外创建一个index.jsp文件,然后这个文件中没有任何内容. 将上面的项目部署之后,启动服务器,打开浏览器,访问以下地址: http://loc ...
- java的访问权限protected和default
protected和default的区别 第一点:在同一个包中,protected和default表现一致,即,当main方法所在的类和使用了protected与default修饰属性.方法的类在同一 ...
- python打开文件、文件夹窗口、终端窗口
简介 在一些项目中,我们会需要在生成完文件后打开某些文件或者文件夹窗口,这就需要使用到内置的文件打开方式了. 打开文件或文件夹 Windows import os import subprocess ...
- 《吐血整理》进阶系列教程-拿捏Fiddler抓包教程(9)-Fiddler如何设置捕获Https会话
1.简介 由于近几年来各大网站越来越注重安全性都改成了https协议,不像前十几年前直接是http协议直接裸奔在互联网.还有的小伙伴或者童鞋们按照上一篇宏哥的配置都配置好了,想大展身手抓一下百度的包, ...
- 内网渗透之Windows认证(二)
title: 内网渗透之Windows认证(二) categories: 内网渗透 id: 6 key: 域渗透基础 description: Windows认证协议 abbrlink: d6b7 d ...