kubernetes集成GPU原理
这里以Nvidia GPU设备如何在Kubernetes中管理调度为例研究, 工作流程分为以下两个方面:
- 如何在容器中使用GPU
- Kubernetes 如何调度GPU
容器中使用GPU
想要在容器中的应用可以操作GPU, 需要实两个目标:
- 容器中可以查看GPU设备
- 容器中运行的应用,可以通过Nvidia驱动操作GPU显卡
在应用程序中使用 GPU,由于需要安装 nvidia driver, Docker 引擎并没有原生支持。因此也就无法直接在容器中访问 GPU 资源。
为了解决容器中无法访问 GPU 资源的问题,有以下方案:
1、无nvidia-docker
在早期的时候,没有nvidia-docker,可以通过在容器内再部署一遍nvidia GPU驱动解决。同理,其他设备如果想在容器里使用,也可以采用在容器里重新安装一遍驱动解决。
2、nvidia-docker1.0
nvidia-docker是英伟达公司专门用来为docker容器使用nvidia GPU而设计的,设计方案就是把宿主机的GPU驱动文件映射到容器内部使用,可以通过tensorflow生成GPU驱动文件夹。
3、nvidia-docker2.0
nvidia-docker2.0对nvidia-docker1.0进行了很大的优化,不用再映射宿主机GPU驱动了,直接把宿主机的GPU运行时映射到容器即可。启动方式示例:
nvidia-docker run -d -e NVIDIA_VISIBLE_DEVICES=all --name nvidia_docker_test nvidia/cuda:10.0-base /bin/sh -c "while true; do echo hello world; sleep 1; done"
4、安装docker19.03及以上版本,已经内置了nvidia-docker,无需再单独部署nvidia-docker了。安装方式如下:
安装docker:
yum install -y yum-utils
yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo
yum-config-manager --enable docker-ce-nightly
yum-config-manager --enable docker-ce-test
yum install docker-ce docker-ce-cli containerd.io
systemctl start docker
安装nvidia-container-toolkit
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.repo | sudo tee /etc/yum.repos.d/nvidia-docker.repo
sudo yum install -y nvidia-container-toolkit
sudo systemctl restart docker
启动容器:
docker run --gpus all nvidia/cuda:10.0-base /bin/sh -c "while true; do echo hello world; sleep 1; done"
进入容器并输入nvidia-smi验证。
在容器中重新安装 nvidia driver,容器启动的时候将 nvidia gpu 作为符号设备传递进来。这种方案的问题在于宿主机和容器内安装的 nvidia driver 版本可能不一致,因此 docker image 无法在多机间共享。这就丧失了 docker 的主要优势。
因此,为了在保持 docker image 迁移性的同时可以方便的使用 gpu,nvidia 提出了 nvidia docker 的方案。
参考文献:https://developer.nvidia.com/blog/gpu-containers-runtime/
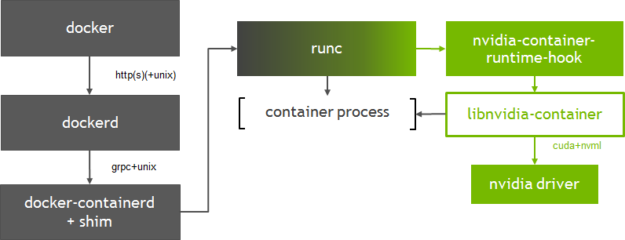
容器启动流程大致为:docker --> dockerd --> docker-containerd-shim --> nvidia-container-runtime-hook --> libnvidia-container--> nvidia-driver。
docker客户端将创建容器的请求发送给dockerd, 当dockerd收到请求任务之后将请求发送给docker-containerd-shim,nvidia-container-runtime创建容器时,先执行nvidia-container-runtime-hook这个hook去检查容器是否需要使用GPU(通过环境变量NVIDIA_VISIBLE_DEVICES来判断)。如果需要则调用libnvidia-container来暴露GPU给容器使用。否则则走默认的runc逻辑。
Nvidia-docker
项目地址:https://github.com/NVIDIA/nvidia-docker
Nvidia提供Nvidia-docker项目,它是通过修改Docker的Runtime为nvidia runtime工作,当我们执行 nvidia-docker create 或者 nvidia-docker run 时,它会默认加上 --runtime=nvidia 参数。将runtime指定为nvidia。
nvidia-docker是在docker的基础上做了一层封装,通过 nvidia-docker-plugin把硬件设备在docker的启动命令上添加必要的参数。
gpu-containers-runtime
gpu-containers-runtime 是一个NVIDIA维护的容器 Runtime,它在runc的基础上,维护了一份 Patch, 在容器启动前,注入一个 prestart 的hook 到容器的Spec中(hook的定义可以查看 OCI规范 )。这个hook 的执行时机是在容器启动后(Namespace已创建完成),容器自定义命令(Entrypoint)启动前。
gpu-containers-runtime-hook
gpu-containers-runtime-hook 是一个简单的二进制包,定义在Nvidia container runtime的hook中执行。 目的是将当前容器中的信息收集并处理,转换为参数调用 nvidia-container-cli 。主要处理以下参数:
- 根据环境变量
NVIDIA_VISIBLE_DEVICES判断是否会分配GPU设备,以及挂载的设备ID。如果是未指定或者是void,则认为是非GPU容器,不做任何处理。 否则调用nvidia-container-cli, GPU设备作为--devices参数传入 - 环境环境变量
NVIDIA_DRIVER_CAPABILITIES判断容器需要被映射的 Nvidia 驱动库。 - 环境变量
NVIDIA_REQUIRE_*判断GPU的约束条件。 例如cuda>=9.0等。 作为--require=参数传入 - 传入容器进程的Pid
gpu-containers-runtime-hook 做的事情,就是将必要的信息整理为参数,传给 nvidia-container-cli configure 并执行。
nvidia-container-cli
项目地址:https://github.com/NVIDIA/libnvidia-container,基于c语言
nvidia-container-cli 是一个命令行工具,用于配置Linux容器对GPU 硬件的使用。支持
- list: 打印 nvidia 驱动库及路径
- info: 打印所有Nvidia GPU设备
- configure: 进入给定进程的命名空间,执行必要操作保证容器内可以使用被指定的GPU以及对应能力(指定 Nvidia 驱动库)。 configure是我们使用到的主要命令,它将Nvidia 驱动库的so文件 和 GPU设备信息, 通过文件挂载的方式映射到容器中。
docker 19.03之后,默认支持NVIDIA GPU。
kubernetes中使用GPU
参考资源:https://kubernetes.io/zh/docs/tasks/manage-gpus/scheduling-gpus/#deploying-amd-gpu-device-plugin
Kubernetes 提供了Device Plugin 的机制,用于异构设备的管理场景。原理是会为每个特殊节点上启动一个针对某个设备的DevicePlugin pod, 这个pod需要启动grpc服务, 给kubelet提供一系列接口。
整个 Device Plugin 的工作流程可以分成两个部分:
- 一个是启动时刻的资源上报;
- 另一个是用户使用时刻的调度和运行。
Device Plugin 的开发主要包括最关注与最核心的两个事件方法:
- 其中 ListAndWatch 对应资源的上报,同时还提供健康检查的机制。当设备不健康的时候,可以上报给 Kubernetes 不健康设备的 ID,让 Device Plugin Framework 将这个设备从可调度设备中移除;
- 而 Allocate 会被 Device Plugin 在部署容器时调用,传入的参数核心就是容器会使用的设备 ID,返回的参数是容器启动时,需要的设备、数据卷以及环境变量。
Nvidia GPU Device Plugin
为了能够在Kubernetes中管理和调度GPU, Nvidia提供了Nvidia GPU的Device Plugin。
项目地址:https://github.com/NVIDIA/k8s-device-plugin
主要功能如下:
- 支持ListAndWatch 接口,上报节点上的GPU数量。
- 支持Allocate接口, 支持分配GPU的行为。
调度流程
整个Kubernetes调度GPU的过程如下:
- GPU Device plugin 部署到GPU节点上,通过
ListAndWatch接口,上报注册节点的GPU信息和对应的DeviceID。 - 当有声明
nvidia.com/gpu的GPU Pod创建出现,调度器会综合考虑GPU设备的空闲情况,将Pod调度到有充足GPU设备的节点上。 - 节点上的kubelet 启动Pod时,根据request中的声明调用各个Device plugin 的 allocate接口, 由于容器声明了GPU。 kubelet 根据之前
ListAndWatch接口收到的Device信息,选取合适的设备,DeviceID 作为参数,调用GPU DevicePlugin的Allocate接口。 - GPU DevicePlugin ,接收到调用,将DeviceID 转换为
NVIDIA_VISIBLE_DEVICES环境变量,返回kubelet。 - kubelet将环境变量注入到Pod, 启动容器。
- 容器启动时,
gpu-container-runtime调用gpu-containers-runtime-hook。 gpu-containers-runtime-hook根据容器的NVIDIA_VISIBLE_DEVICES环境变量,转换为--devices参数,调用nvidia-container-cli prestart。nvidia-container-cli根据--devices,将GPU设备映射到容器中。 并且将宿主机的Nvidia Driver Lib 的so文件也映射到容器中。 此时容器可以通过这些so文件,调用宿主机的Nvidia Driver。
在k8s中启用GPU支持
必要条件:
- NVIDIA 驱动程序 ~= 384.81
- nvidia-docker 版本 > 2.0
- docker 配置为 nvidia 作为默认运行时。
- Kubernetes 版本 >= 1.10
$ kubectl create -f https://raw.githubusercontent.com/NVIDIA/k8s-device-plugin/v0.11.0/nvidia-device-plugin.yml
运行GPU作业
部署守护程序后,可以使用nvidia.com/gpu资源类型请求 NVIDIA GPU:
apiVersion: v1
kind: Pod
metadata:
name: gpu-pod
spec:
containers:
- name: cuda-container
image: nvcr.io/nvidia/cuda:9.0-devel
resources:
limits:
nvidia.com/gpu: 2 # requesting 2 GPUs
- name: digits-container
image: nvcr.io/nvidia/digits:20.12-tensorflow-py3
resources:
limits:
nvidia.com/gpu: 2 # requesting 2 GPUs
AMD GPU Device Plugin
项目地址:https://github.com/RadeonOpenCompute/k8s-device-plugin
在k8s中启用GPU支持
必要条件:
- 支持 ROCm 的机器
- ROCm 内核(安装指南)或最新的 AMD GPU Linux 驱动程序(安装指南)
--allow-privileged=true对于 kube-apiserver 和 kubelet(仅当设备插件通过 DaemonSet 部署时才需要,因为设备插件容器需要特权安全上下文才能访问/dev/kfd设备健康检查)
部署 AMD 设备插件:
kubectl create -f https://raw.githubusercontent.com/RadeonOpenCompute/k8s-device-plugin/r1.10/k8s-ds-amdgpu-dp.yaml
k8s 共享GPU方案
在kubernetes中运行GPU程序,通常都是将一个GPU卡分配给一个容器。这可以实现比较好的隔离性,确保使用GPU的应用不会被其他应用影响;对于深度学习模型训练的场景非常适合;
但是如果对于模型开发和模型预测的场景就会比较浪费。很多诉求是能够让更多的预测服务共享同一个GPU卡上,进而提高集群中Nvidia GPU的利用率。
阿里云开源了一个gpushare项目,实现多个pod共享同一块gpu卡。
核心模块:
- GPU Share Scheduler Extender: 利用Kubernetes的调度器扩展机制,负责在全局调度器Filter和Bind的时候判断节点上单个GPU卡是否能够提供足够的GPU Mem,并且在Bind的时刻将GPU的分配结果通过annotation记录到Pod Spec以供后续Filter检查分配结果。
- GPU Share Device Plugin: 利用Device Plugin机制,在节点上被Kubelet调用负责GPU卡的分配,依赖scheduler Extender分配结果执行。
工作流程(gpushare):
1)GPU Share Device Plugin利用nvml库查询到GPU卡的数量和每张GPU卡的显存, 通过ListAndWatch()将节点的GPU总显存(数量 *显存)作为另外Extended Resource汇报给Kubelet; Kubelet进一步汇报给Kubernetes API Server。
2)Kubernetes默认调度器在进行完所有过滤(filter)行为后会通过http方式调用GPU Share Scheduler Extender的filter方法,找出单卡满足调度条件的节点和卡。
3)当调度器找到满足条件的节点,就会委托GPU Share Scheduler Extender的bind方法进行节点和Pod的绑定。
4)当Pod和节点绑定的事件被Kubelet接收到后,Kubelet就会在节点上创建真正的Pod实体,在这个过程中, Kubelet会调用GPU Share Device Plugin的Allocate方法, Allocate方法的参数是Pod申请的gpu-mem。
kubernetes集成GPU原理的更多相关文章
- CRI 与 ShimV2:一种 Kubernetes 集成容器运行时的新思路
摘要: 关于 Kubernetes 接口化设计.CRI.容器运行时.shimv2.RuntimeClass 等关键技术特性的设计与实现. Kubernetes 项目目前的重点发展方向,是为开发 ...
- Docker Kubernetes 服务发现原理详解
Docker Kubernetes 服务发现原理详解 服务发现支持Service环境变量和DNS两种模式: 一.环境变量 (默认) 当一个Pod运行到Node,kubelet会为每个容器添加一组环境 ...
- jenkins持续集成工作原理、功能、部署方式等介绍
超详细的jenkins持续集成工作原理.功能.部署方式等介绍 原创 波波说运维 2019-08-29 00:01:00 概述 今天简单整理了一下jenkins的一些概念性内容,归纳如下: 1.概念 j ...
- Kubernetes Job Controller 原理和源码分析(一)
概述什么是 JobJob 入门示例Job 的 specPod Template并发问题其他属性 概述 Job 是主要的 Kubernetes 原生 Workload 资源之一,是在 Kubernete ...
- Kubernetes Job Controller 原理和源码分析(二)
概述程序入口Job controller 的创建Controller 对象NewController()podControlEventHandlerJob AddFunc DeleteFuncJob ...
- Kubernetes Job Controller 原理和源码分析(三)
概述Job controller 的启动processNextWorkItem()核心调谐逻辑入口 - syncJob()Pod 数量管理 - manageJob()小结 概述 源码版本:kubern ...
- kubernetes应用部署原理
Kubernetes应用部署模型解析(原理篇) 十多年来Google一直在生产环境中使用容器运行业务,负责管理其容器集群的系统就是Kubernetes的前身Borg.其实现在很多工作在Kubernet ...
- jenkins持续集成工作原理
转载https://www.cnblogs.com/liyuanhong/p/6548925.html 片段 这里是选择Gitlab作为git server.Gitlab的功能和Github差不多,但 ...
- 【爬坑系列】之解读kubernetes的认证原理&实践
对于访问kube-apiserver模块的请求来说,如果是使用http协议,则会顺利进入模块内部得到自己想要的:但是如果是用的是https,则能否进入模块内部获得想要的资源,他会首先要进行https自 ...
- containerd与kubernetes集成
kubernetes集群三步安装 概念介绍 cri (Container runtime interface) cri is a containerd plugin implementation of ...
随机推荐
- go 死锁示例
以下代码不会有任何打印.原因是:channel ch 在make 时是无缓冲区的channel.无缓冲区的channel 发送一个数据进入后需要等待这个数据被消耗才能继续发送下一个数据.然而getFr ...
- mybatis动态生成sql示例
- SSH的密钥登录配置
1.ssh的登录方法. 两种方法: (1)linux系统connect to linux ssh -l root 192.168.2.191 #直接登录. 语法:$ssh -p 22 user@hos ...
- js-禁止鼠标右键/禁止选中文字
1 <p>使用contextmenu禁止鼠标右键</p> 2 <script> 3 document.addEventListener('contextmenu', ...
- git log 查看分支图
操作: 在git config文件里面设置别名. git config --global alias.lg "log --graph --all --pretty=format:'%Cred ...
- 【pytest】pytest.mark.dependency用例依赖标签,并解决依赖失效的问题
pytest第三方插件,用来解决用例之间的依赖关系.如果依赖的用例执行失败后 后续的用例会被跳过执行,相当于智能执行了pytest.mark.skip, 首先要安装插件:pip install pyt ...
- 20200926--矩阵转置(奥赛一本通P95 8 多维数组)
输入一个n行m列的矩阵A,输出它的转置(看下面说明) 输入:第1行包含两个整数n和m(1<=n<=100,1<=m<=100),表示矩阵A的行数和列数.接下来n行,每行m个整数 ...
- c++项目
如题, 想搞1-2个c++项目把目前除了进程.线程管理的所有所学都用起来. 在自己设想中.
- MongoDB 相关的一些操作
一. 在 MongoDB Compass中输入条件查询数据 {"src":"小车"} // = 该值 {"src":{$ ...
- IndexError: invalid index of a 0-dim tensor. Use tensor.item() to convert a 0-dim tensor to a Python number
print('Epoch[{}/{}], loss:{:.6f}'.format(epoch+1,num_epoch,loss.data[0])) 将loss.data[0] 改为loss.item( ...