C++ 不知树系列之初识树(树的邻接矩阵、双亲孩子表示法……)
1. 前言
树是一种很重要的数据结构,最初对数据结构的定义就是指对树和图的研究,后来才广义化了数据结构这个概念。从而可看出树和图在数结构这一研究领域的重要性。
树和图重要的原因是,它让计算机能建模出现实世界中更多领域里错综复杂的信息关系,让计算机服务这些领域成为可能。
本文将和大家聊聊树的基本概念,以及树的物理存储结构以及实现。
2. 基本概念
数据结构的研究主要是从 2 点出发:
- 洞悉数据与数据之间的逻辑关系。
- 设计一种物理存储方案。除了存储数据本身还要存储数据之间的逻辑关系,并且能让基于此数据上的算法利用这种存储结构达到事半功倍的效果。
当数据之间存在一对多关系时,可以使用树来描述。如公司组织结构、家庭成员关系……
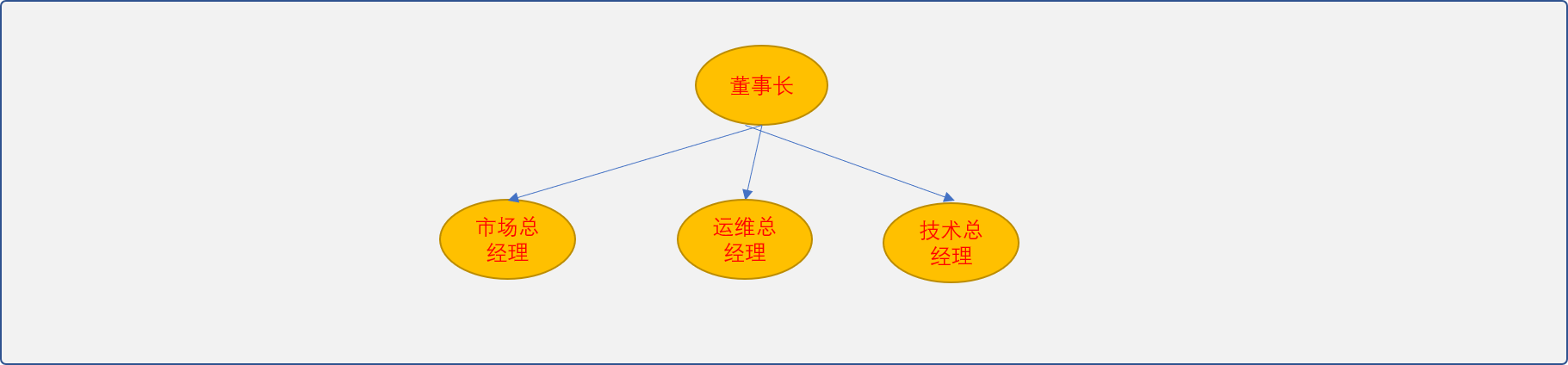
完整的树结构除了需要描述出数据信息,还需要描述数据与数据之间的关系。树结构中,以节点作为数据的具体形态,边作为数据之间关系的具体形态。
也可以说树是由很多节点以及边组成的集合。
如果一棵树没有任何节点,则称此树为空树。如果树不为空,则此树存在唯一的根节点(root),根节点是整棵树的起点,其特殊之处在于没有前驱节点。如上图值为董事长的节点。
除此之外,树中的节点与节点之间会存在如下关系:
- 父子关系:节点的前驱节点称其为父节点,且只能有一个或没有(如根节点)。节点的后驱节点称其为子节点,子节点可以有多个。如上图的
董事长节点是市场总经理节点的父节点,反之,市场总经理节点是董事长节点的子节点。 - 兄弟关系: 如果节点之间有一个共同的前驱(父)节点,则称这些节点为兄弟节点。如上图的
市场总经理节点和运维总经理节点为兄弟关系。 - 叶节点: 叶节点是没有后驱(子)节点的节点。
- 子树:一棵树也可以理解是由子节点为根节点的子树组成,子树又可以理解为多个子子树组成…… 所以树可以描述成是树中之树式的递归关系。
如下图所示的 T 树 。
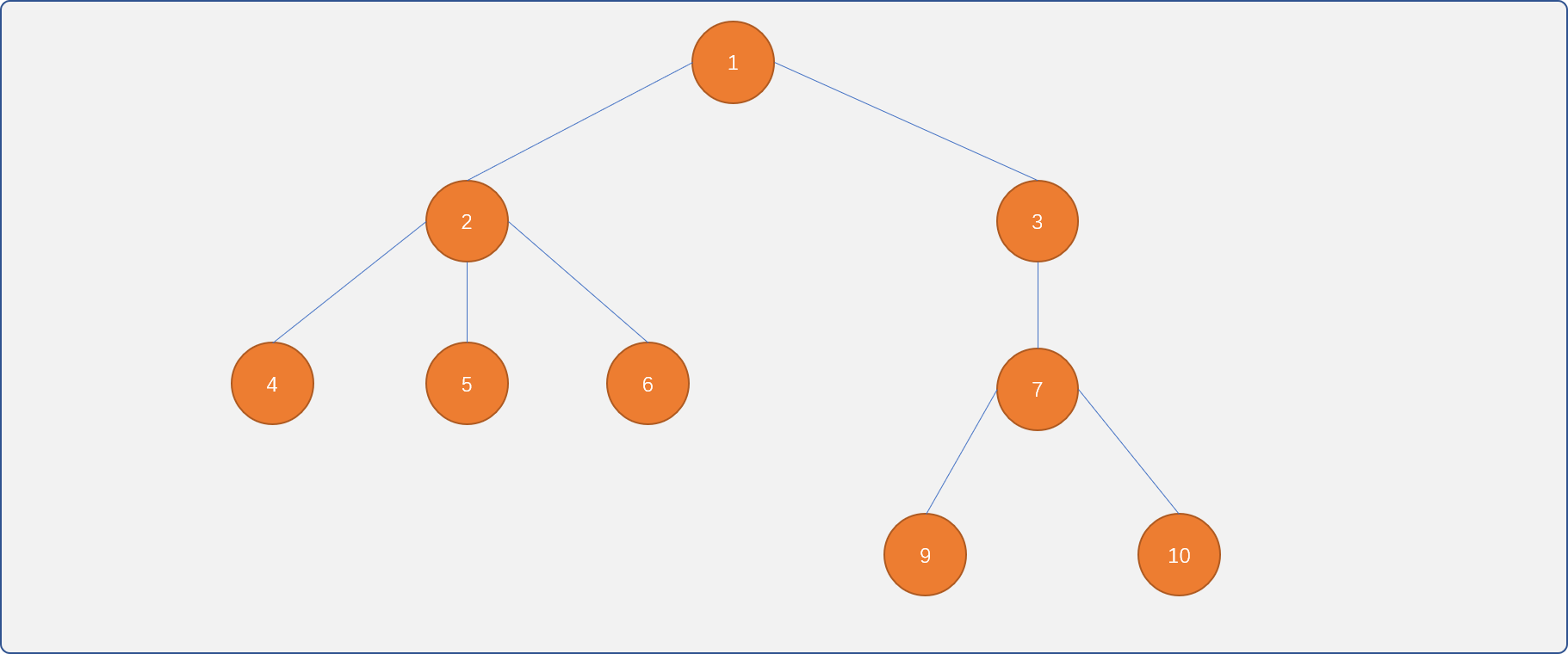
可以理解为T1和T2子树组成。
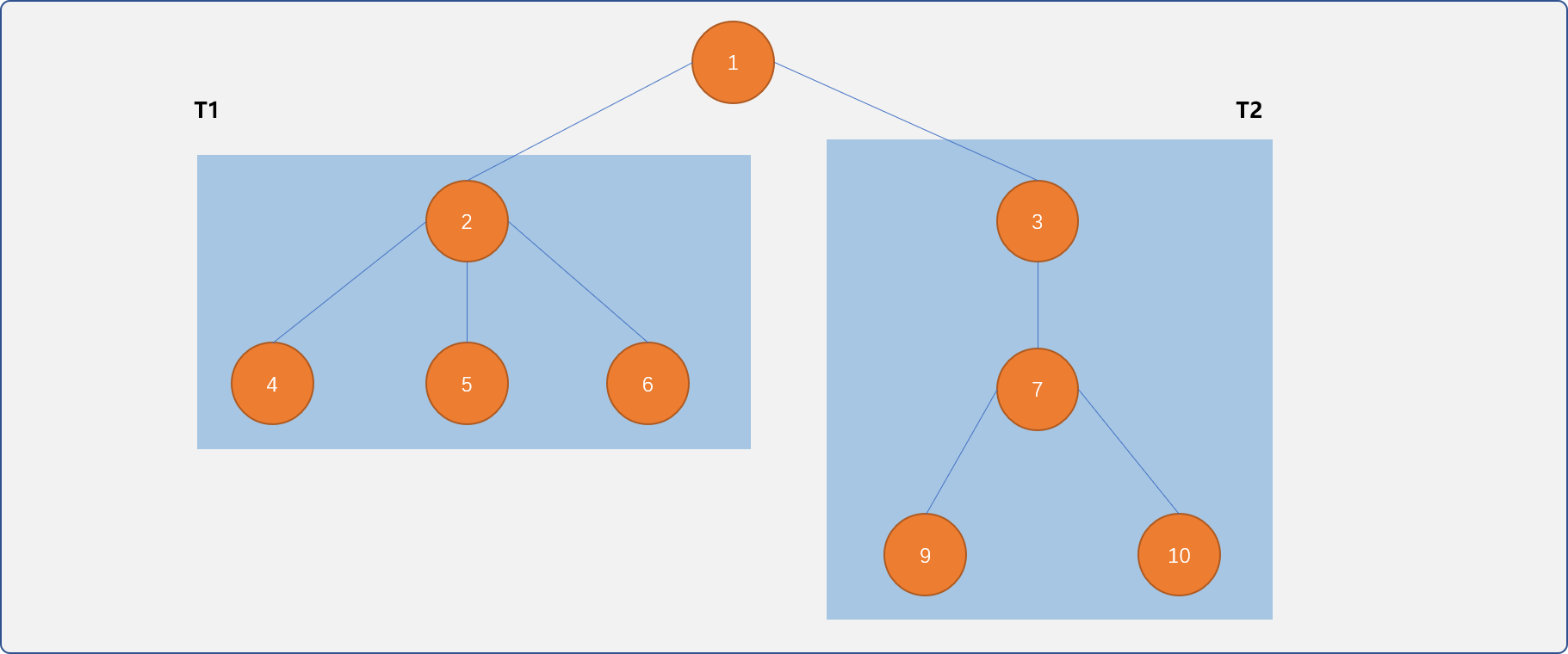
T1、T2又可以认为是由它的子节点为根节点的子子树组成,以此类推,一直到叶节点为止。
树的相关概念:
- 节点的度: 一个节点含有子树的个数称为该节点的度。
- 树的度:一棵树中,最大的节点的度称为树的度。
- 节点的层次:同级的节点为一个层次。根节点为第
1层,根的子节点为第2层,以此类推。 - 树的高(深)度: 树中节点最大的层次。如上图中的树的最大层次为
4。
树的类型:
- 无序树:树中的结点之间没有顺序关系,这种树称为无序树。
- 有序树:树中任意节点的子节点之间有左右顺序关系。如下图,任一节点的左子节点值小于右子节点值。
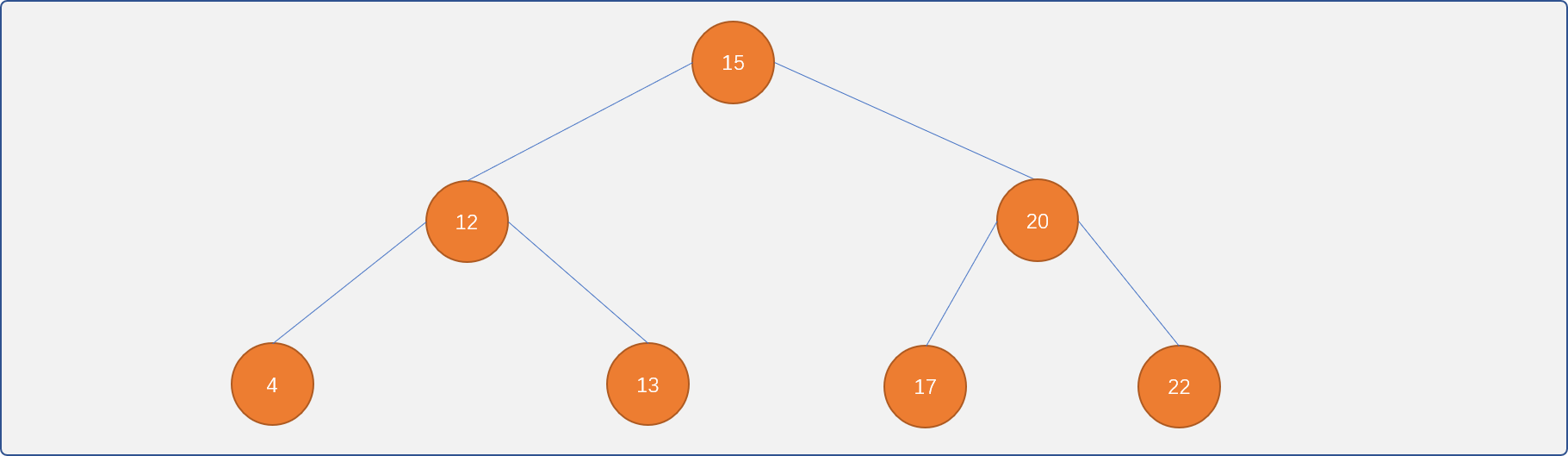
二叉树:如果任一节点最多只有
2个子节点,则称此树结构为二叉树。上图的有序树也是一棵二叉树。完全二叉树:一棵二叉树至多只有最下面两层的节点的子结点可以小于
2。并且最下面一层的节点都集中在该层最左边的若干位置上。满二叉树:除了叶节点,其它节点的子结点都有
2个。如上图中的树也是满二叉树。
3. 物理存储
可以使用邻接矩阵和邻接表的形式存储树。
3.1 邻接矩阵存储
邻接矩阵是顺序表存储方案。
3.1.1 思路流程
- 给树中的每一个节点从小到大进行编号。如下图,树共有
11个节点。

- 创建一个
11X11的名为arrTree的矩阵 ,行和列的编号对应节点的编号,并初始矩阵的值都为0。
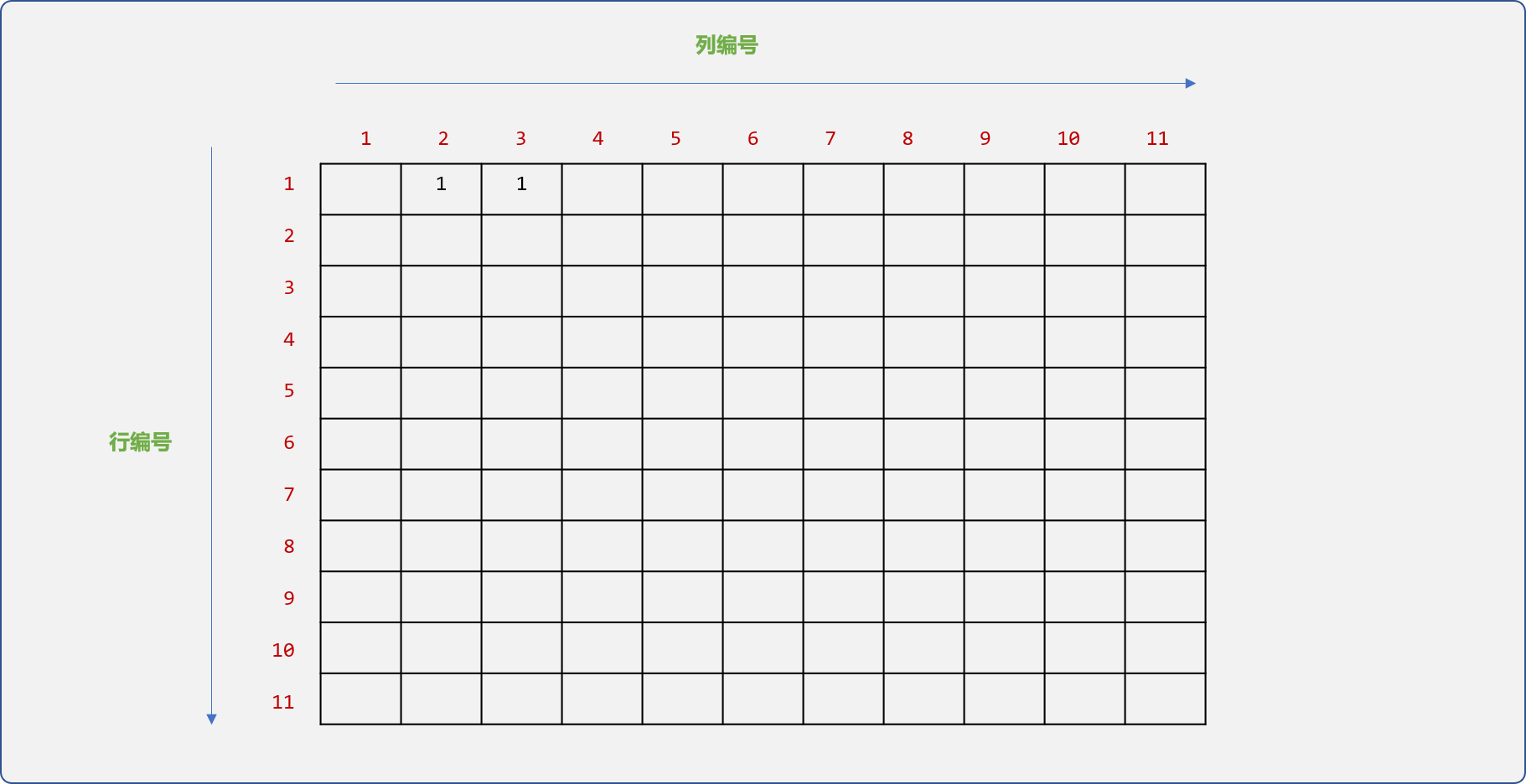
- 在树结构中,编号为
1的节点和编号为2、3的节点存在父子关系,则把矩阵的arrTree[1][2]和arrTree[1][3]的位置设置为1。也就是说,行号和列号交叉位置的值如果是1,则标志着编号和行号、列号相同的节点之间有关系。
- 找到树中所有结点之间的关系,最后矩阵中的信息如下图所示。
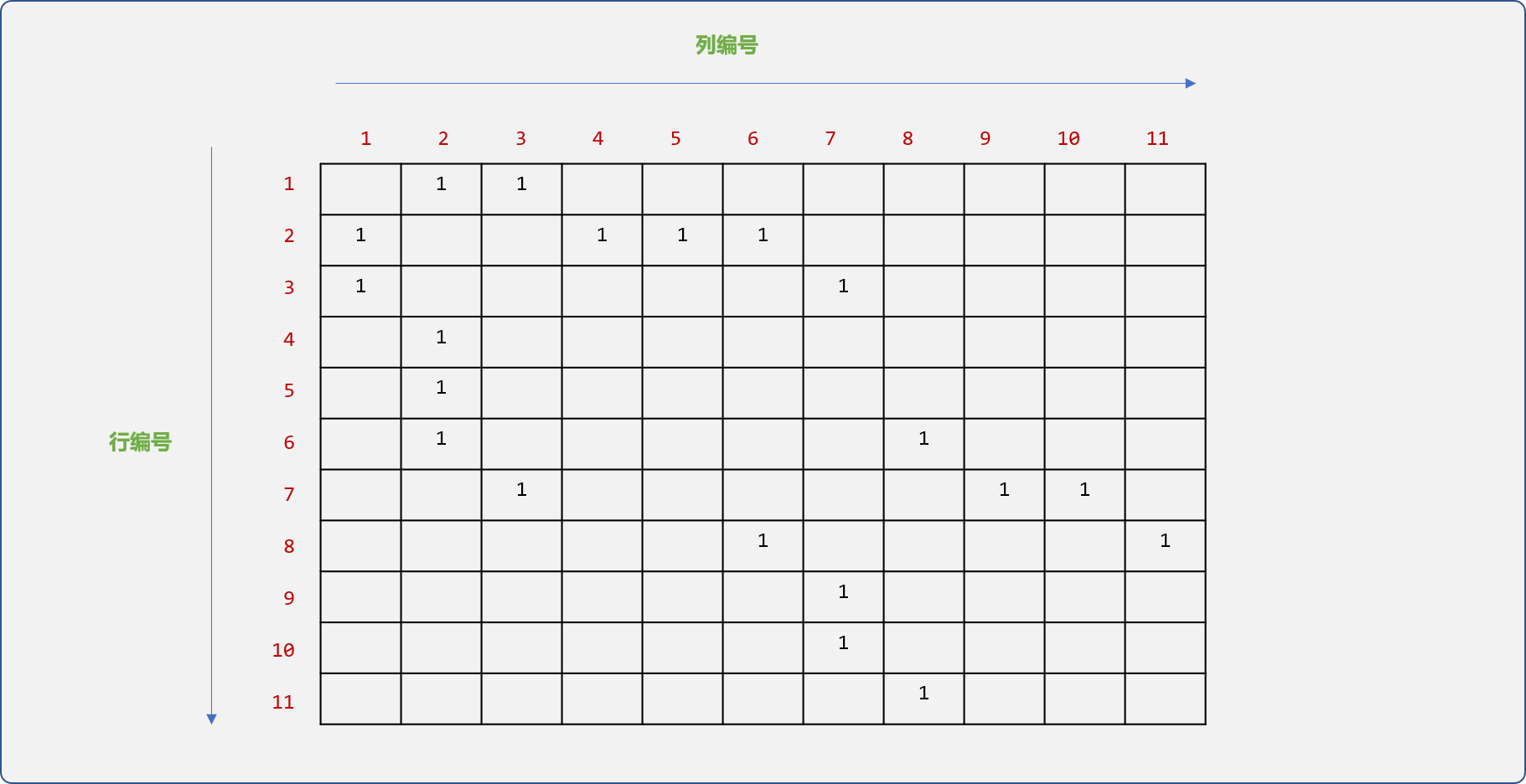
矩阵记录了结点之间的双向(父到子,子到父)关系,最终看到是一个对称的稀疏矩阵。可以只存储上三角或下三角区域的信息,并可以对矩阵进行压缩存储。
邻接矩阵存储优点是实现简单、查询方便。但是,如果不使用压缩算法,空间浪费较大。
3.1.2 编码实现
现采用邻接矩阵方案实现对如下树的具体存储:
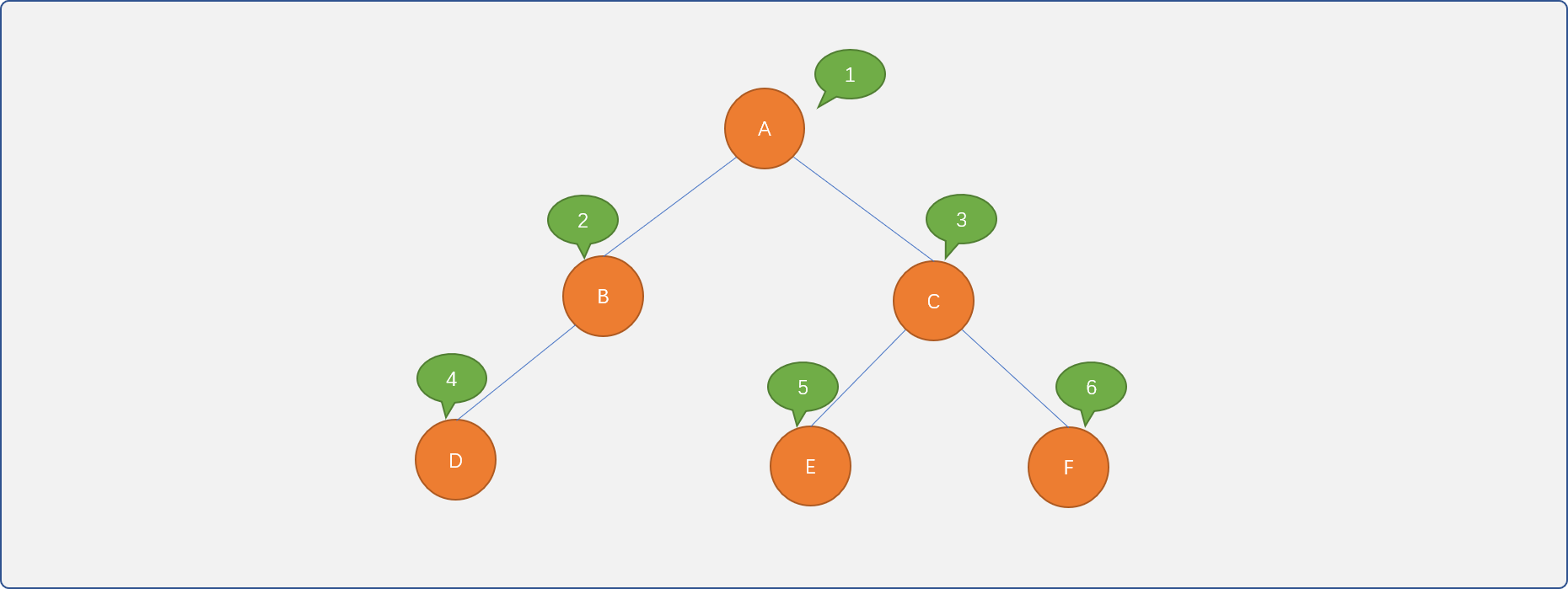
- 节点类型: 用来描述数据的信息。
struct TreeNode{
//节点的编号
int code;
//节点上的值
int data;
};
- 树类型:树类型中除了存储节点(数据)信息以及节点之间的关系,还需要提供相应的数据维护算法。本文仅考虑如何对树进行存储。
class Tree {
private:
int size=7;
vector<TreeNode> treeNodes;
//使用矩阵存储节点之间的关系,矩阵第一行第一列不存储信息
int matrix[7][7];
//节点编号,为了方便,从 1 开始
int idx=1;
public:
Tree() {
}
//初始根节点
Tree(char root) {
cout<<3<<endl;
for(int r=1; r<this->size; r++) {
for(int c=1; c<this->size; c++) {
this->matrix[r][c]=0;
}
}
TreeNode node= {this->idx,root};
this->treeNodes.push_back(node);
//节点的编号由内部指定
this->idx++;
}
//获取到根节点
TreeNode getRoot() {
return this->treeNodes[0];
}
//添加新节点
int addVertex(char val) {
if (this->idx>=this->size)
return 0;
TreeNode node= {this->idx,val};
this->treeNodes.push_back(node);
//返回节点编号
return this->idx++;;
}
/*
* 添加节点之间的关系
*/
bool addEdge(int from,int to) {
char val;
//查找编号对应节点是否存在
if (isExist(from,val) && isExist(to,val)) {
//建立关系
this->matrix[from][to]=1;
//如果需要,可以打开双向关系
//this->matrix[to][from]=1;
}
}
//根据节点编号查询节点
bool isExist(int code,char & val) {
for(int i=0; i<this->treeNodes.size(); i++) {
if (this->treeNodes[i].code==code) {
val=this->treeNodes[i].data;
return true;
}
}
return false;
}
//输出节点信息
void showAll() {
cout<<"矩阵信息"<<endl;
for(int r=1; r<this->size; r++) {
for(int c=1; c<this->size; c++) {
cout<<this->matrix[r][c]<<" ";
}
cout<<endl;
}
cout<<"所有节点信息:"<<endl;
for(int i=0; i<this->treeNodes.size(); i++) {
TreeNode tmp=this->treeNodes[i];
cout<<"节点:"<<tmp.code<<"-"<<tmp.data<<endl;
//以节点的编号为行号,在列上扫描子节点
char val;
for(int j=1; j<this->size; j++ ) {
if(this->matrix[tmp.code][j]!=0) {
isExist(j,val);
cout<<"\t子节点:"<<j<<"-"<<val<<endl;
}
}
}
}
};
测试代码:
int main() {
//通过初始化根节点创建树
Tree tree('A');
TreeNode root=tree.getRoot();
int codeB= tree.addVertex('B');
tree.addEdge(root.code,codeB);
int codeC= tree.addVertex('C');
tree.addEdge(root.code,codeC);
int codeD= tree.addVertex('D');
tree.addEdge(codeB,codeD);
int codeE= tree.addVertex('E');
tree.addEdge(codeC,codeE);
int codeF= tree.addVertex('F');
tree.addEdge(codeC,codeF);
tree.showAll();
}
输出结果:
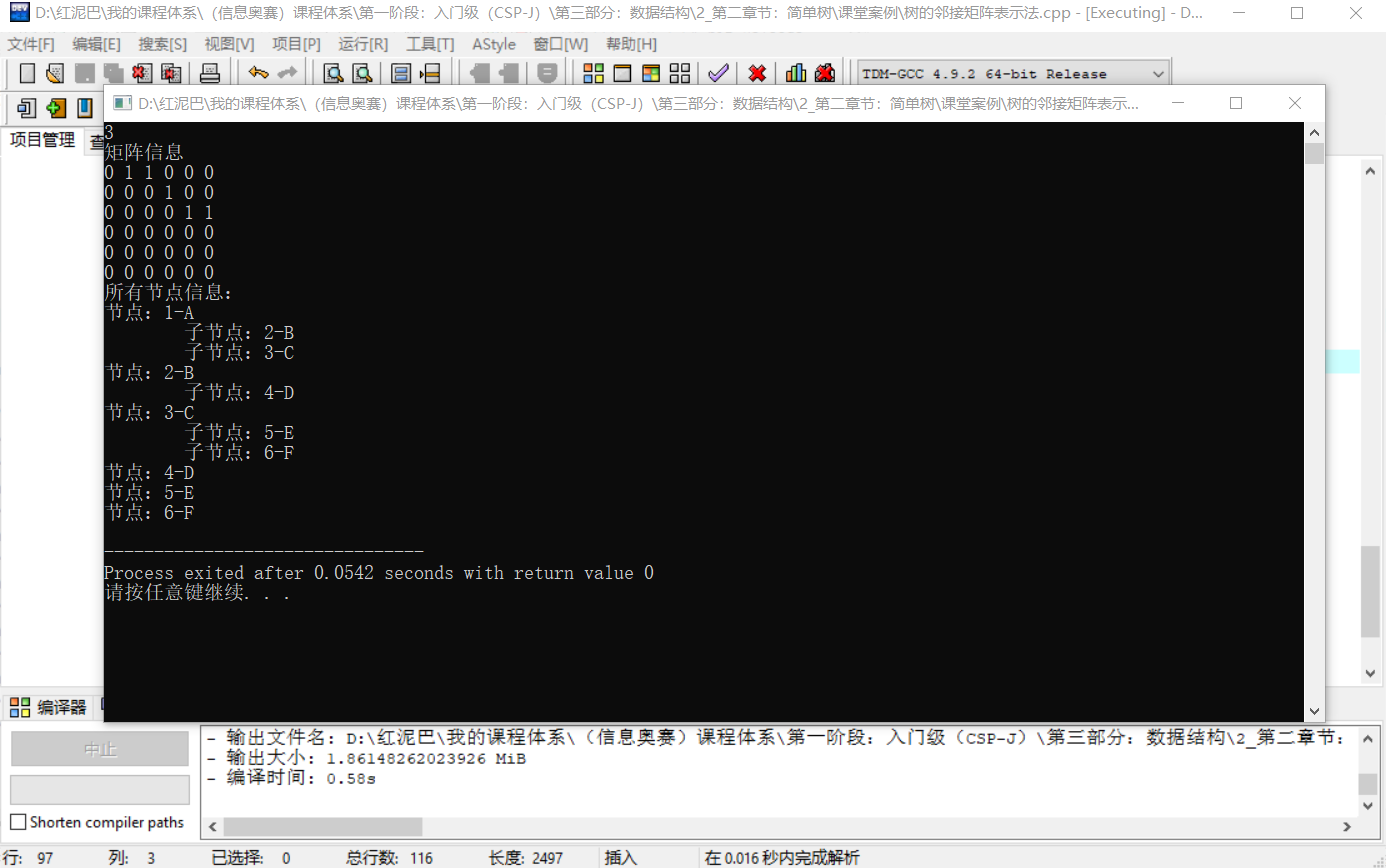
邻接矩阵存储方式的优点:
- 节点存储在线性容器中,可以很方便的遍历所有节点。
- 使用矩阵仅存储节点之间的关系,节点的存储以及其关系的存储采用分离机制,无论是查询节点还是关系(以节点的编号定位矩阵的行,然后在此行上以列扫描就能找到所以子节点)都较方便。
缺点:
- 矩阵空间浪费严重,虽然可以采用矩阵压缩,但是增加了代码维护量。
3.2 邻接表存储
邻接表存储和邻接矩阵的分离存储机制不同,邻接表的节点类型中除了存储数据信息,还会存储节点之间的关系信息。
可以根据节点类型中的信息不同分为如下几种具体存储方案:
3.2.1 双亲表示法
结点类型有 2 个存储域:
- 数据域。
- 指向父节点的指针域。

如下文所示的树结构,用双亲表示法思路存储树结构后的物理结构如下图所示。
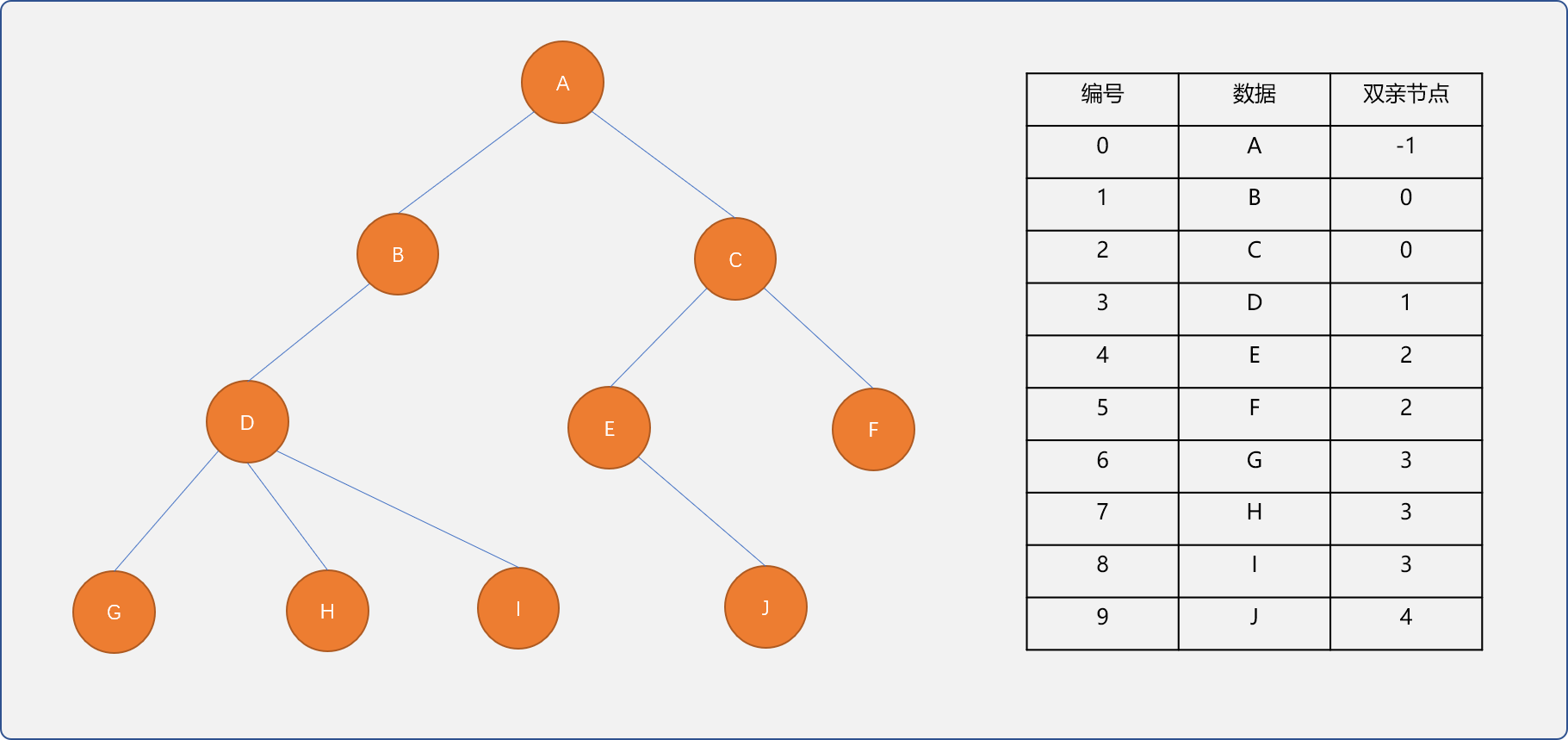
根节点没有父结点,双亲指针域中的值为 0。
双亲表示法很容易找到节点的父节点,如果要找到节点的子节点,需要对整个表进行查询,双亲表示法是一种自引用表示法。
双亲表示法无论使用顺序存储或链表存储都较容易实现。
3.2.2 孩子表示法
用顺序表存储每一个节点,然后以链表的形式为每一个节点存储其所有子结点。如下图所示,意味着每一个节点都需要维护一个链表结构,如果某个节点没有子结点,其维护的链表为空。
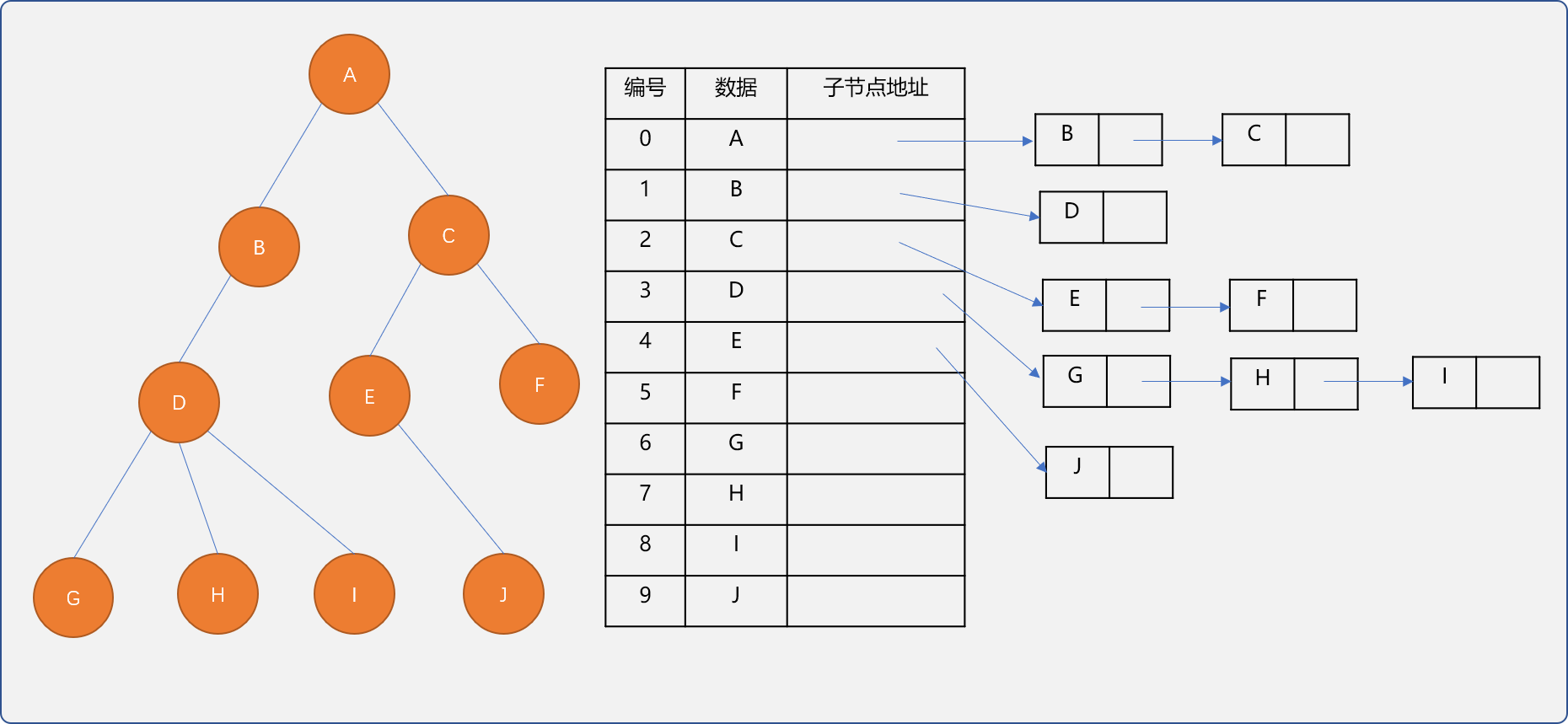
孩子表示法,查找节点的子节点或兄弟节点都很方便,但是查找父节点,就不怎方便了。可以综合双亲、孩子表示法。
3.2.3 双亲孩子表示法
双亲孩子表示法的存储结构,无论是查询父节点还是子节点都变得轻松。如下图所示。
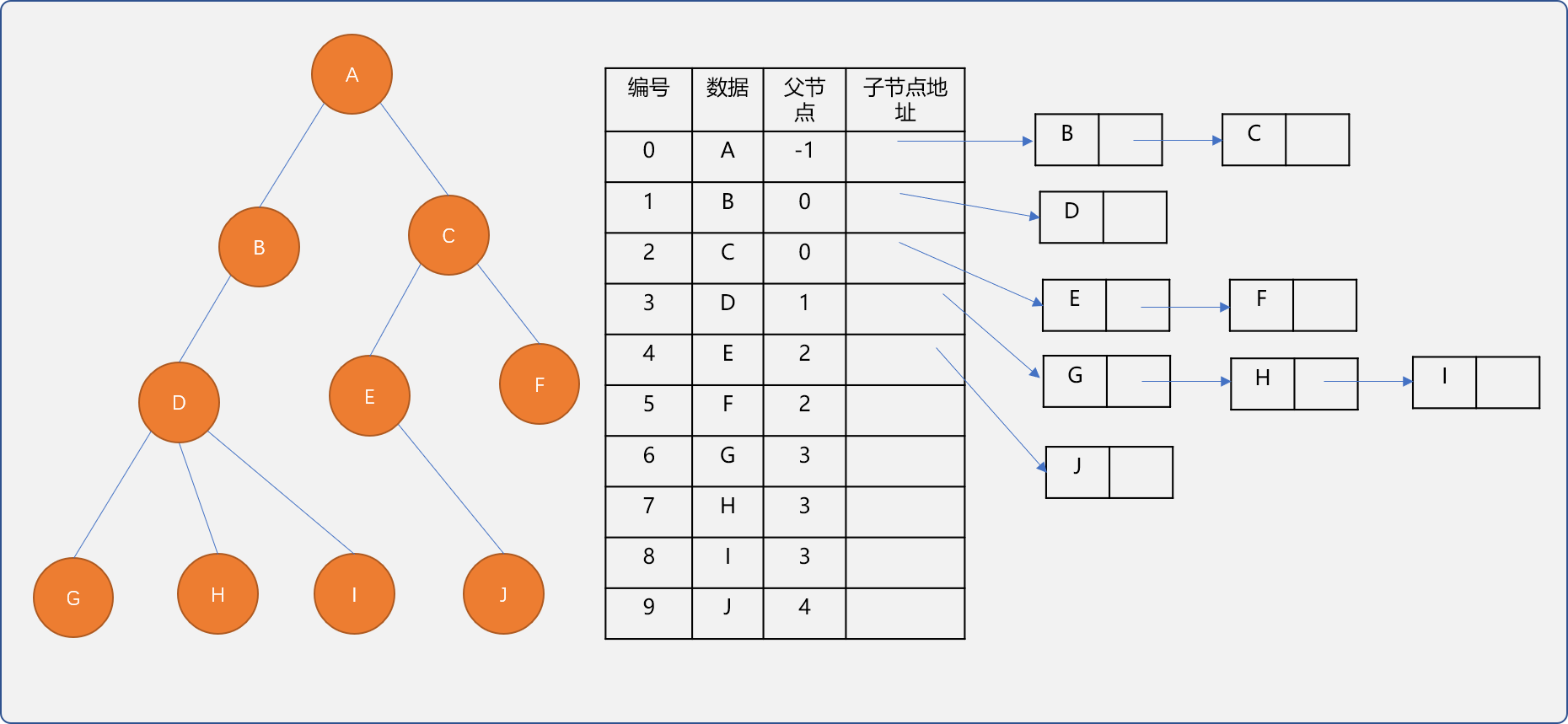
双亲孩子表示法的具体实现:
- 设计节点类型:
#include <iostream>
#include <vector>
using namespace std;
struct TreeNode {
//节点编号
int code;
//节点的值
char val;
//节点的父节点
TreeNode *parent;
//节点的子节点信息,以单链表的方式存储,head 指向第一个子节点的地址
TreeNode *head;
//兄弟结点
TreeNode *next;
//构造函数
TreeNode(int code,char val) {
this->code=code;
this->val=val;
this->parent=NULL;
this->head=NULL;
this->next=NULL;
}
//自我显示
void show() {
cout<<"结点:";
cout<<this->code<<"-"<<this->val<<endl;
if(this->parent) {
cout<<"\t父节点:";
cout<<this->parent->code<<"-"<<this->parent->val<<endl;
}
TreeNode *move=this->head;
while(move) {
cout<<"\t子节点:"<<move->code<<"-"<<move->val<<endl;
move=move->next;
}
}
};
树类型定义:
class Tree {
private:
//一维数组容器,存储所有结点
vector<TreeNode*> treeNodes;
//节点的编号生成器
int idx=0;
public:
//无参构造函数
Tree() {}
//有参构造函数,初始化根节点
Tree(char val) {
//动态创建节点
TreeNode* root=new TreeNode(this->idx,val);
this->idx++;
this->treeNodes.push_back(root);
}
//返回根节点
TreeNode* getRoot() {
return this->treeNodes[0];
}
//添加新节点
TreeNode* addTreeNode(char val,TreeNode *parent) {
//创建节点
TreeNode* newNode=new TreeNode(this->idx,val);
if(!newNode)
//创建失败
return NULL;
if(parent) {
//设置父节点
newNode->parent=parent;
//本身成为父节点的子节点
if(parent->head==NULL)
parent->head=newNode;
else {
//原来头节点成为尾节点
newNode->next=parent->head;
//新子节结点成为头结点
parent->head=newNode;
}
}
//编号自增
this->idx++;
//添加到节点容器中
this->treeNodes.push_back(newNode);
return newNode;
}
//显示树上的所有结点,以及结点之间的关系
void showAll() {
for(int i=0; i<this->treeNodes.size(); i++) {
TreeNode *tmp=this->treeNodes[i];
tmp->show();
}
}
};
测试代码:
int main(int argc, char** argv) {
Tree tree('A');
//返回根节点
TreeNode * root =tree.getRoot();
//根节点下添加 B、C 两个子节点
TreeNode * rootB= tree.addTreeNode('B',root);
TreeNode * rootC= tree.addTreeNode('C',root);
//B下添加D子节点
TreeNode * rootD= tree.addTreeNode('D',rootB);
//C下添加E、F子节点
TreeNode * rootE= tree.addTreeNode('E',rootC);
TreeNode * rootF= tree.addTreeNode('F',rootC);
tree.showAll();
return 0;
}
输出结果:
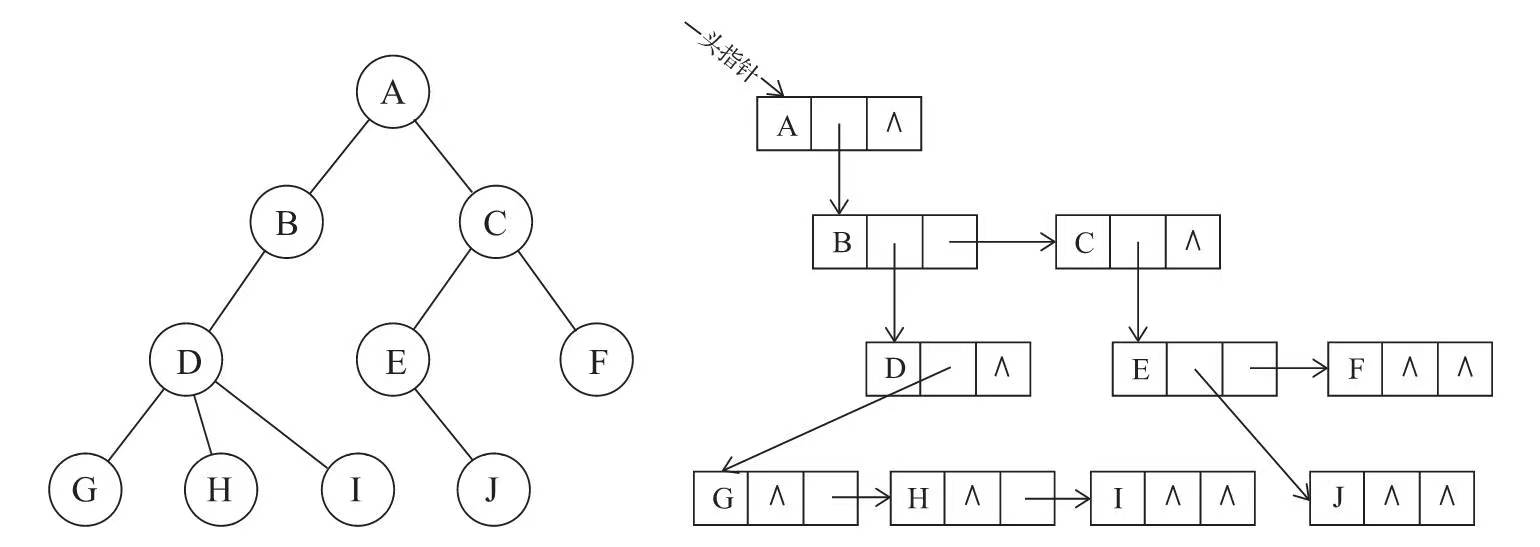
3.2.4 孩子兄弟表示法
指针域中存储子节点和兄弟节点。节点类型中有 3 个信息域:
- 数据域。
- 指向子节点的地址域。
- 指向兄弟节点的地址域。

孩子兄弟表示法的具体实现过程有兴趣者可以自行试一试,应该还是较简单的。
如上几种实现存储方式,可以根据实际情况进行合理选择。
4. 总结
本文先讲解了树的基本概念,然后讲解了树的几种存储方案。本文提供了邻接矩阵和双亲孩子表示法的具体实现。
本文同时也收录至"编程驿站"公众号!
C++ 不知树系列之初识树(树的邻接矩阵、双亲孩子表示法……)的更多相关文章
- 后缀树系列一:概念以及实现原理( the Ukkonen algorithm)
首先说明一下后缀树系列一共会有三篇文章,本文先介绍基本概念以及如何线性时间内构件后缀树,第二篇文章会详细介绍怎么实现后缀树(包含实现代码),第三篇会着重谈一谈后缀树的应用. 本文分为三个部分, 首先介 ...
- 大白话5分钟带你走进人工智能-第二十六节决策树系列之Cart回归树及其参数(5)
第二十六节决策树系列之Cart回归树及其参数(5) 上一节我们讲了不同的决策树对应的计算纯度的计算方法, ...
- 17-看图理解数据结构与算法系列(NoSQL存储-LSM树)
关于LSM树 LSM树,即日志结构合并树(Log-Structured Merge-Tree).其实它并不属于一个具体的数据结构,它更多是一种数据结构的设计思想.大多NoSQL数据库核心思想都是基于L ...
- 看图轻松理解数据结构与算法系列(NoSQL存储-LSM树) - 全文
<看图轻松理解数据结构和算法>,主要使用图片来描述常见的数据结构和算法,轻松阅读并理解掌握.本系列包括各种堆.各种队列.各种列表.各种树.各种图.各种排序等等几十篇的样子. 关于LSM树 ...
- 初识主席树_Prefix XOR
主席树刚接触觉得超强,根本看不懂,看了几位dalao的代码后终于理解了主席树. 先看一道例题:传送门 题目大意: 假设我们预处理出了每个数满足条件的最右边界. 先考虑暴力做法,直接对x~y区间暴枚,求 ...
- NOIp 数据结构专题总结 (2):分块、树状数组、线段树
系列索引: NOIp 数据结构专题总结 (1) NOIp 数据结构专题总结 (2) 分块 阅:<「分块」数列分块入门 1-9 by hzwer> 树状数组 Binary Indexed T ...
- 区块链学习1:Merkle树(默克尔树)和Merkle根
☞ ░ 前往老猿Python博文目录 ░ 一.简介 默克尔树(Merkle tree,MT)又翻译为梅克尔树,是一种哈希二叉树,树的根就是Merkle根. 关于Merkle树老猿推荐大家阅读<M ...
- BZOJ 3196 Tyvj 1730 二逼平衡树 ——树状数组套主席树
[题目分析] 听说是树套树.(雾) 怒写树状数组套主席树,然后就Rank1了.23333 单点修改,区间查询+k大数查询=树状数组套主席树. [代码] #include <cstdio> ...
- BZOJ 1901 Zju2112 Dynamic Rankings ——树状数组套主席树
[题目分析] BZOJ这个题目抄的挺霸气. 主席树是第一时间想到的,但是修改又很麻烦. 看了别人的题解,原来还是可以用均摊的思想,用树状数组套主席树. 学到了新的姿势,2333o(* ̄▽ ̄*)ブ [代 ...
随机推荐
- Taurus.MVC WebAPI 入门开发教程5:控制器安全校验属性【HttpGet、HttpPost】【Ack】【Token】【MicroService】。
系列目录 1.Taurus.MVC WebAPI 入门开发教程1:框架下载环境配置与运行. 2.Taurus.MVC WebAPI 入门开发教程2:添加控制器输出Hello World. 3.Tau ...
- MyBatis ognl.NoSuchPropertyException 或者 Invalid bound statement (not found)
描述 SpringBoot + Mybatis-plus 项目,运行时出现如下错误: ognl.NoSuchPropertyException:没有对应属性异常 Invalid bound state ...
- 209. 长度最小的子数组--LeetCode
来源:力扣(LeetCode) 链接:https://leetcode.cn/problems/minimum-size-subarray-sum 著作权归领扣网络所有.商业转载请联系官方授权,非商业 ...
- WebMvcConfigurerAdapter过时替换接口或类
(注意!)WebMvcConfigurerAdapter 在spring 5.0中已经弃用了. 原来的使用方式 @Deprecated public abstract class WebMvcConf ...
- MySQL入门笔记一
MySQL应用笔记 一MySQL关系型数据库.开源,中小型公司常用类型的数据库Oracle 大型公司常用数据库 MySQL基本的命令一. 创建.删除.查看数据库(database)创建库creat ...
- linux 旁路掉协议栈的处理点
对于协议栈的发展,目前有三种处理趋势,一种是类似于使用dpdk的方式,然后将协议栈放到用户态来做,做得比较好的一般都是以bsd的协议栈为底子,可以参考的是腾讯开源的的方案,另外一种是,继续放在内核,但 ...
- rh358 001 Linux网络与systemd设置
358 rhel7 ce ansible 部署服务 dhcp nginx vanish haproxy 打印机服务 服务管理自动化 systemd与systemctl systemctl 来管理sys ...
- ASP.NET Core 6框架揭秘实例演示[34]:缓存整个响应内容
我们利用ASP.NET开发的大部分API都是为了对外提供资源,对于不易变化的资源内容,针对某个维度对其实施缓存可以很好地提供应用的性能.<内存缓存与分布式缓存的使用>介绍的两种缓存框架(本 ...
- 第七十二篇:Vue组件的props
好家伙, 1.组件的props props是组件的自定义属性,在封装通用组件的时候,合理的使用props可以极大的提高组件的复用性 来假设一下,如果我们需要两个组件分别显示不同的值 目录结构如下: H ...
- C语言小游戏: 推箱子 支线(一)--1
好家伙,考完试了 回顾一下2021 回顾一下某次的作业 妙啊 所以, 做一个推箱子小游戏 1.先去4399找一下关卡灵感 就它了 2.在百度上搜几篇推箱子, 参考其中的"■ ☆"图 ...