Maximum Entropy Population-Based Training for Zero-Shot Human-AI Coordination
原文:https://www.cnblogs.com/Twobox/p/16791412.html
熵
熵:表述一个概率分布的不确定性。例如一个不倒翁和一个魔方抛到地上,看他们平稳后状态。很明显,魔方可能有6种状态,而不倒翁很大可能就一个状态,那么我们说在这种情况下,不倒翁的确定性高于魔方。也就是魔方的熵大于另外一个。那么我看表达式:
\(H(p)=-\sum_i^n P_i logP_i\)

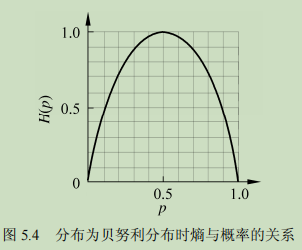
很明显,当p的概率是0或1时,没有不确定性,熵值为0。当为0.5时,熵最大,最不确定。
相对熵
https://zhuanlan.zhihu.com/p/372835186zui
两个分布相似度的一种度量
定义:
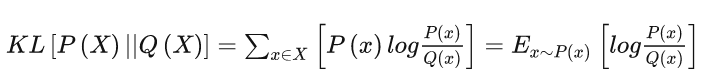
性质:
D(P||Q) >= 0,当 P=Q时,D(P||Q)=0;
Maximum Entropy RL
https://zhuanlan.zhihu.com/p/444441890
名字很长,但是实际很简单。

1、加上这个实际体现是什么?2、有什么好处?
一般来说,我们将state输入神经网络后,输出的action是分布,即每个动作的概率值。例如 向左0.8 向右0.1 开火0.1。我们具体执行那个动作是通过抽样来选择的。
刚才我们说到,熵是衡量一个概率分布的不确定性,各变量概率越相近,熵值越大。例如上述例子,当p为0.5时候,熵最大。也就是说,所谓最大熵目标,也就是希望各动作的概率尽可能的小。换句话说,希望获得高奖励的同时,动作的可选择性尽可能多。
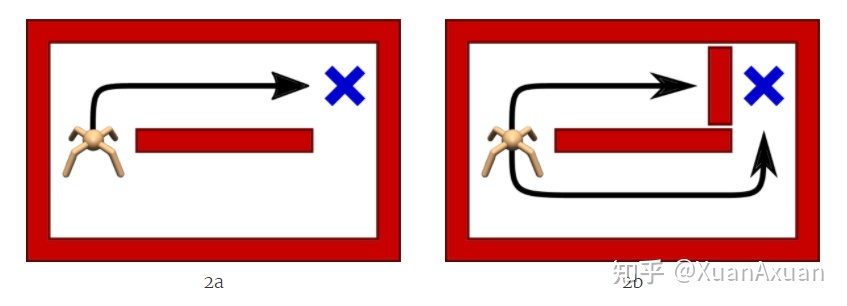
如图,上面的路线更短,传统RL方法会学习到向上,而最大熵RL则都能够学习到。说白了就是增加应对不同情况的鲁棒性!
MEP背景
强化学习在对抗人类方面取得了很多成功,例如 、刀塔、星际争霸等。但是在合作协作方面都有待进展。一般Agent是通过自博弈,例如,来进行训练。那么造成了这么一个问题:只对特定的对手策略起作用,当换成人的时候时候,因为没见过,很大可能就傻了,啥也不是。
论文中有个形象的例子,我们来看下:
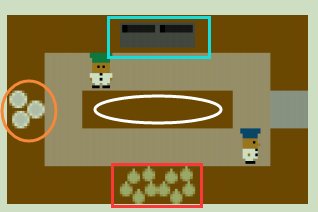
一个相互协作的烹饪游戏,2玩家,下面红色框里是洋葱、左边橙色框里是盘子、上面蓝色框里是烹饪台,中间一条和周围一圈是褐色的是桌面。游戏目标很见到那,首先将下面3个洋葱放到上面烹饪台上,等烹饪时间结束后,再用左边的盘子装盘,送到最右边的出口。
那么传统自博弈将出现下面这种情况:一个人在下面不停的送,上面不停的接,并且他只送一个台面。因为这样整体奖励是最高的。但是这时候下面那个换成一个人,并且就不放洋葱到那个台面,这时候上面那个Agent就蒙了。显然,最直接的原因,就是之前训练的机器人没有学习到伙伴的其他情况。
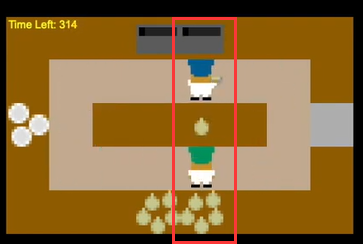
MEP
那么本文的思想很简单,那不是见识少吗,那我就先训练一大堆不同的策略的伙伴,然后让我们的Agent和这些伙伴协作训练就行了。梳理下就是 1、先训练一大堆不同策略的伙伴 2、Agent和这些伙伴协作训练
PD目标
那么我们要先训练出来的这个群里,我们真对其2个部分进行优化。首先是当中的每个个体,使用最大熵奖励,鼓励每个个体自身有exploratory and multi-modal。也说就是其自身尽可能有不同的操作。其次是对于整个群里而言,互相之间尽可能差别大。那么可以用KL散度作为目标的另一部分。数学形式如下:
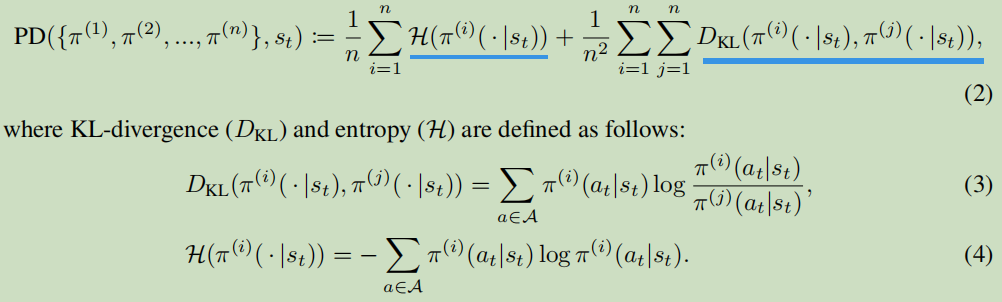
细看很简单,就是每个个体的熵值求平均、每俩之间的相对熵求平均。看公式很明显,这个算法的时间复杂度为\(O(n^2)\),\(n\)为种群的个体数。对此,提出另一个替代目标PE,该文章通过数学证明,证明PE为PD的下界,即PD>=PE。
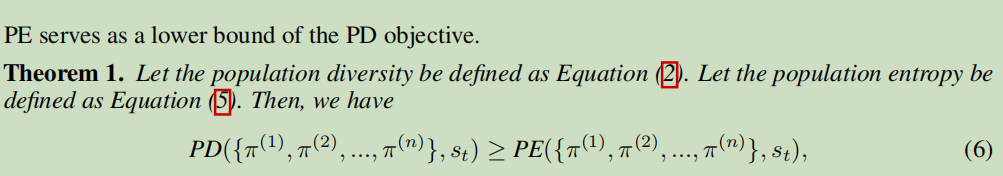
PE目标

表达式相当简单,就是把先群体中每一个策略加起来求个平均,得出一个平均策略,然后对这个平均策略求一个熵就可以了。
训练最大熵群体
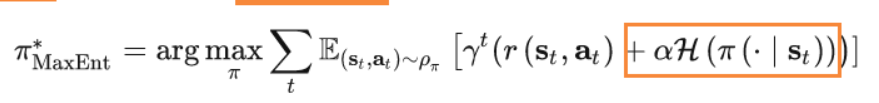
回顾下之前说的最大熵强化学习目标表达式,就是在原来奖励的基础上,加上了一个熵作为附加奖励。

相似的,本文最大熵种群的训练目标也是原来奖励的基础熵,加上我们的PE目标,也就是群平均策略的熵。

流程很简单,每次抽一个个体出来与环境交互,根据目标函数,利用交互数据进行训练。直至收敛。
训练鲁棒性Agent
想法很简单,每次选群里中配合最难的个体出来进行协作训练。\(\pi^{(A)}\)就是我训练的最终策略,他的目标就是,不断提高与最垃圾的那个人配合的分数。形象表达,在工作中最难配合的人都适应了,其他人还算啥。

那么怎么计算具体的概率呢:我们希望概率正相关难度,也就是负相关合作收益,收益越高,约靠后。
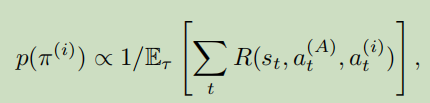
最终,我们选取了下面这个形式,将他们以难度排序。例如3个分别排 1、2、3 。那么第一个的概率就是1/(1+2+3) = 1/6、第二个就是2/6、第三个就是3/6。就是这个意思。

总结
我们希望在没有人类数据的情况下,通过自博弈能够实现与人类的合作。因为不同的人行为不同,所以我们希望我们在训练之前,尽可能的先训练一大批行为不同的行为模型,然后再和这些模型进行训练,以提升和真人的配合的鲁棒性。如果我们训练的这个群里,行为越丰富,那么越能代表大多数真人,那么我们最终训练的Agent越能配合形形色色的真人。其中难点是群体训练,体现在两方面,个体多样性,个体之间的多样性,这个进化计算的思想是一致的!对于个体多样性,我们使用熵来进行控制。对于俩俩之间的多样性,通过相对熵,也就是KL散度来控制。这篇文章做的只是这样,更重要的是通过推到,找到了一个线性复杂度的替代目标,来代替原先\(n^2\)复杂度的目标。
Maximum Entropy Population-Based Training for Zero-Shot Human-AI Coordination的更多相关文章
- 《Population Based Training of Neural Networks》论文解读
很早之前看到这篇文章的时候,觉得这篇文章的思想很朴素,没有让人眼前一亮的东西就没有太在意.之后读到很多Multi-Agent或者并行训练的文章,都会提到这个算法,比如第一视角多人游戏(Quake ...
- 最大熵模型The Maximum Entropy
http://blog.csdn.net/pipisorry/article/details/52789149 最大熵模型相关的基础知识 [概率论:基本概念CDF.PDF] [信息论:熵与互信息] [ ...
- 最大熵模型 Maximum Entropy Model
熵的概念在统计学习与机器学习中真是很重要,熵的介绍在这里:信息熵 Information Theory .今天的主题是最大熵模型(Maximum Entropy Model,以下简称MaxEnt),M ...
- Maximum Entropy Model(最大熵模型)初理解
0,熵的描述 熵(entropy)指的是体系的混沌的程度(可也理解为一个随机变量的不确定性),它在控制论.概率论.数论.天体物理.生命科学等领域都有重要应用,在不同的学科中也有引申出的更为具体的定义, ...
- Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor
Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor 20 ...
- HDU 6047 - Maximum Sequence | 2017 Multi-University Training Contest 2
/* HDU 6047 - Maximum Sequence [ 单调队列 ] 题意: 起初给出n个元素的数列 A[N], B[N] 对于 A[]的第N+K个元素,从B[N]中找出一个元素B[i],在 ...
- Maximum Entropy Markov Models for Information Extraction and Segmentation
1.The use of state-observation transition functions rather than the separate transition and observat ...
- 逻辑斯特回归(logistic regression)与最大熵模型(maximum entropy model)
- 最大熵模型(Maximum Entropy Models)具体分析
因为本篇文章公式较多,csdn博客不同意复制公式,假设将公式一一保存为图片在上传太繁琐了,就用word排好版后整页转为图片传上来了.如有错误之处.欢迎指正.
随机推荐
- 【ASP.NET Core】选项类的依赖注入
咱们继续上一个话题.先简单复习一下,根据老周前面文章的介绍,选项类体系的基本套路是通过 IOptionsFactory 来创建选项类实例的.而我们在服务容器(IServiceCollection)上是 ...
- java-Servlet编码/异常处理
1. Servlet输出中文(1)为什么会有乱码?out.println方法在输出时或者表单提交的时候,浏览器会对表单中的中文参数值进行编码; 注:会使用表单所在的页面打开时使用的编码方式进行编码服务 ...
- 非常全的一份Python爬虫的Xpath博文
非常全的一份Python爬虫的Xpath博文 Xpath 是 python 爬虫过程中非常重要的一个用来定位的一种语法. 一.开始使用 首先我们需要得到一个 HTML 源代码,用来模拟爬取网页中的源代 ...
- 开源云真机平台-Sonic应用实践
前言 Sonic是一款开源.支持分布式部署.在线自动化测试的私有云真机平台.偶然接触到这个平台是源于虫师的一篇公众号文章<基于Linux 部署 Sonic>,于是结合文章内容和官网尝试搭建 ...
- Excelize 2.3.2 发布,Go 语言 Excel 文档基础库,2021 年首个更新
Excelize 是 Go 语言编写的用于操作 Office Excel 文档基础库,基于 ECMA-376,ISO/IEC 29500 国际标准.可以使用它来读取.写入由 Microsoft Exc ...
- iOS WebRTC 点对点实时音视频流程介绍
前言 公司某个项目需要接入音视频即时通讯, 功能类似微信的拨打视频通话,语音通话的场景.那么对于音视频通讯会用到什么技术呢?没错,它就是 WebRTC . 什么是WebRTC WebRTC,名称源自网 ...
- sql报错收集
踩坑记录: 当出现如下错误 Not enough parameters for the SQL statement 多半是因为插入时填写的字段名有误 json.decoder.JSONDecodeEr ...
- PHP8中match新语句的操作方法
PHP8 新出的一个语法很好用,就是 match 语句.match 语句跟原来的 switch 类似,不过比 switch 更加的严格和方便 原来的 switch 语句代码如下: 1 function ...
- C#/.NET/.NET Core优秀项目框架推荐
前言: 为.NET开源者提供的一个推荐自己优秀框架的地址,大家可以把自己的一些优秀的框架,或者项目链接地址存到在这里,提供给广大.NET开发者们学习(排名不分先后). Github项目仓库收集地址:h ...
- VSCODE 配置远程调试环境
以下内容为本人的著作,如需要转载,请声明原文链接微信公众号「englyf」https://www.cnblogs.com/englyf/p/16691460.html 我的需求是,在Windows桌面 ...