模块/collections/random/time/datetime
内容概要
- 模块——包的具体使用
- 编程思想介绍
- 软件开发——目录规范
- 常用模块介绍——collections模块
- 常用模块介绍——time、datetime
- 常用模块介绍——random
1.包的具体使用
'''
虽然python3中对包的要求降低了,不需要__init__.py也可以识别,但是为了兼容性考虑最好还是加上__init__.py文件
'''
1.我们如果只想使用包中的某几个模块,那么还是按照之前的导入方式即可
from 路径 import 模块名
2.或者直接导入包名
import 包名
只不过我们在导入包名的时候只是导入包里面的__init__.py文件,此文件中的名字可以通过包+.的方式调出来供我们使用
2.编程思想的转变
1.
小白阶段:
我们在写代码阶中总是所有的代码堆叠在一起
大多是if else 等等的判断堆叠
2.
初级阶段
根据功能或需求的不同我们可以把一段代码给封装成函数模式
我们通过调用函数的方法可以让我们避免写冗长重复的代码
3.
模块阶段
我们根据不同的需求封装不同的函数到不同的py文件中
我们在编写代码的过程中可以直接通过模块方式调用我们写好的功能
3.软件开发——目录规范(重要)
1.我们在编写软件的时候,目录规范的指定主要是在开发程序过程中针对不同的文件功能需要做出不同的分类
文件名字并不绝对,但是总体思想是不变的 为了分类管理的便利性我们需要规范的目录
项目my_project文件夹中应包含
1.bin 文件夹 # 主要存放启动文件
strat.py # 启动文件一般存放在bin文件夹中或者my_project根目录下
2.conf 文件夹 # 主要存放项目配置文件 一般都是全大写
settings.py # 一般都是全大写(默认) 相当于常量
3.core 文件夹 # 主要存放项目的核心文件
src.py # 主要存放项目核心功能
4.interface # 里面主要存放项目接口文件
user.py
goods.py # 根据具体业务逻辑划分对应的文件
order.py
5.db文件夹 # 主要存放项目相关数据
db_handler.py # 主要是存放数据库相关操作的代码
userinfo.txt
6.log 文件夹 # 主要存放项目日志文件
log.log
7.lib 文件夹 # 主要存放项目公共功能的文件
common.py
8.readme 文件夹 # 主要存放项目使用说明书
9.requierments.txt 主要存放项目所需模块及版本
4.常用内置模块——collections模块
1.具名元组:nametuple
# namedtuple() 返回一个新的元组子类,且规定了元组的元素的个数,同时除了使用下标获取元素之外,还可以通过属性直接获取。
from collections import named tuple
此功能参数:
collections.namedtuple(typename, field_names, verbose=False, rename=False)
typename:字符串,元组名称
field_names:由元组中元素的名称,可选类型为:字符串列表或空格分隔开字符串或逗号分隔开字符串
verbose:默认就好
rename:如果元素名称中含有python的关键字,则必须设置为rename=True
from collections import namedtuple
point = namedtuple('点', ['x', 'y'])
p1 = point(1, 2)
print(p1) # 点(x=1, y=2)
print(p1.x) # 1
print(p1.y) # 2
________________________________________________________________
from collections import namedtuple
poke_list = namedtuple('扑克牌', ['num', 'color'])
poke = poke_list(1, '红桃')
poke1 = poke_list(1, '黑桃')
print(poke) # 扑克牌(num=1, color='红桃')
print(poke.num) # 1
print(poke.color) # 红桃
2.队列与堆栈
队列:先进先出
栈堆:先进后出
队列和堆栈都是一边只能进一边只能出
3.Counter
# Counter 可以简单理解为一个计数器,可以统计每个元素出现的次数,同样 Counter() 是需要接受一个可迭代的对象的。
# 统计列表中每个数据值出现的次数并组织成字典展示
from collections import Counter
l1 = ['jason','jason','kevin','oscar','kevin','tony','kevin']
l1_data = Counter(l1)
print(l1_data)
# Counter({'kevin': 3, 'jason': 2, 'oscar': 1, 'tony': 1})
我们使用Counter功能()内需要填写可迭代对象
我们可以获得一个字典,键为可迭代对象,值为出现次数
# 求列表每个数字出现的次数
l1 = [11, 2, 3, 2, 2, 1, 2, 1, 2, 3, 2, 3, 2, 3, 4, 3, 2, 3, 2, 2, 2, 2, 3, 2]
from collections import Counter
l1_count = Counter(l1)
print(l1_count)
# Counter({2: 13, 3: 7, 1: 2, 11: 1, 4: 1})
4.deque
# deque是 double-ended queue的简称 这个功能可以方便我们在数据的前后快速更改或增添新的元素 append pop leftpop leftappend
from collections import deque
q = deque([1, 2, 3, 4, 5])
a = q.pop()
print(a)
print(q)
q.append(10)
print(q)
print(q[0])
打印结果为:
5
deque([1, 2, 3, 4])
deque([1, 2, 3, 4, 10])
1
4.常用内置模块——time、datetime模块
time 模块
time模块常用函数
1.时间戳
import time
print(time.time())
# 1666168553.743125
# 格林威治时间1970年01月01日00时00分00秒 至今经历过的的秒数
2.推迟指定的时间运行
import time
time.sleep(1) # 延迟一秒在执行
print('hello world') # 延迟一秒打印
3.格式化输出时间
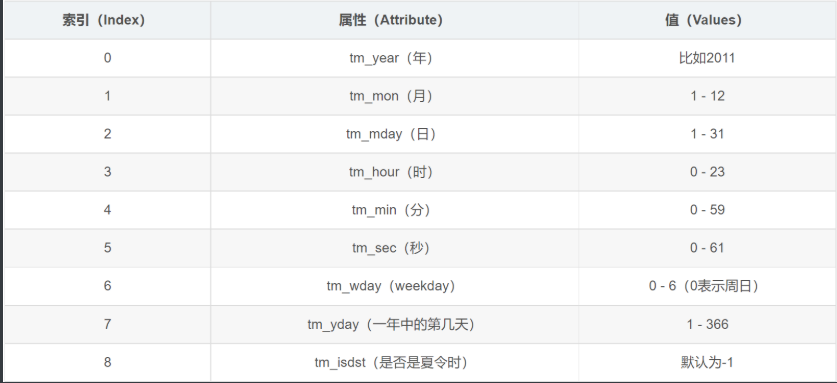
print(localtime()) # time.struct_time(tm_year=2022, tm_mon=10, tm_mday=19, tm_hour=17, tm_min=2, tm_sec=22, tm_wday=2, tm_yday=292, tm_isdst=0)
print(time.strftime('%Y-%m-%d,%H:%M:%S:%p',time.localtime()))
# 2022-10-19,17:02:22:PM %p为上午下午
print(time.strftime('%Y:%m:%d %X',time.localtime()))
# 2022:10:19 17:05:56 %X表示 时分秒
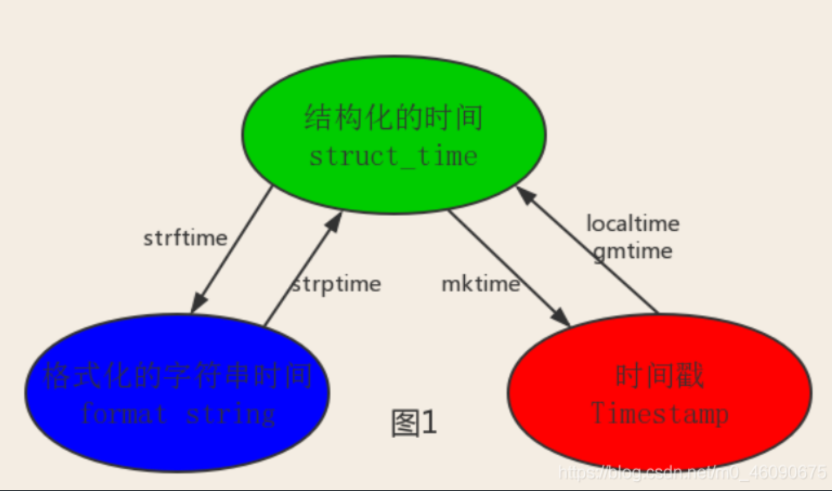
总而言之strftime() 可以把localtime() 的时间相关信息
根据自己想输出的内容格式 表现出来
而strptime() 则是根据自己输入的时间内容编程localtime()的格式
print(time.strptime('2020-10-18','%Y-%m-%d'))
# time.struct_time(tm_year=2020, tm_mon=10, tm_mday=18, tm_hour=0, tm_min=0, tm_sec=0, tm_wday=6, tm_yday=292, tm_isdst=-1)
它输出的的和结构化时间 localltime() 一样
import datatime
import time, datetime
print(datetime.datetime.now()) # 现在的时间
print(datetime.datetime.today()) # 现在的时间
print(datetime.date.today()) # 今天的日期
精简版
from datetime import datetime,date
print(date.today())
print(datetime.now())
from datetime import datetime
d = datetime.strptime('2017/9/30', '%Y/%m/%d')
print(d)
# 2017-09-30 00:00:00
e = datetime.strptime('2017年9月30日星期六', '%Y年%m月%d日星期六')
print(e)
# 2017-09-30 00:00:00
f = datetime.strptime('2017年9月30日星期六8时42分24秒', '%Y年%m月%d日星期六%H时%M分%S秒')
print(f)
# 2017-09-30 08:42:24
时间差:
import datetime
ctime = datetime.datetime.today()
print(ctime)
time_del = datetime.timedelta(minutes=20)
print(ctime + time_del)
2022-10-19 19:02:11.837217
2022-10-19 19:22:11.837217
差值20分钟
5.常用模块——random模块(随机数)
import random
print(random.random()) # 随机产生0-1之间的小数
print(random.randint(1,9)) # 随机产生1-9 之间的数字 包括9
print(random.randrange(0,100,2)) # 随机取0-100之间的偶数
print(random.choice(['一等奖', '二等奖', '三等奖', '谢谢惠顾'])) # 随机抽取一个样本
rint(random.sample(['jason', 'kevin', 'tony', 'oscar', 'jerry', 'tom'], 2)) # 随机抽指定样本数 ['tom', 'jerry']
l1 = [2, 3, 4, 5, 6, 7, 8, 9, 10, 'J', 'Q', 'K', 'A']
random.shuffle(l1) # 随机打乱数据集
print(l1)
# 产生图片验证码: 每一位都可以是大写字母 小写字母 数字 4位
def get_code(n):
code = ''
for i in range(n):
# 1.先产生随机的大写字母 小写字母 数字
random_upper = chr(random.randint(65, 90))
random_lower = chr(random.randint(97, 122))
random_int = str(random.randint(0, 9))
# 2.随机三选一
temp = random.choice([random_upper, random_lower, random_int])
code += temp
return code
res = get_code(10)
print(res)
res = get_code(4)
print(res)
模块/collections/random/time/datetime的更多相关文章
- python_模块 collections,random
collections模块 在内置数据类型(dict.list.set.tuple)的基础上,collections模块还提供了几个额外的数据类型:Counter.deque.defaultdict. ...
- python全栈开发day17-常用模块collections,random,time,os,sys,序列化(json pickle shelve)
1.昨日内容回顾 1.正则表达式 # 正则表达式 —— str # 检测字符串是否符合要求 # 从大段的文字中找到符合要求的内容 1).元字符 #. # 匹配除换行 ...
- python time模块 sys模块 collections模块 random模块 os模块 序列化 datetime模块
一 collections模块 collections模块在内置的数据类型,比如:int.str.list.dict等基础之上额外提供了几种数据类型. 参考博客 http://www.pythoner ...
- oldboy edu python full stack s22 day16 模块 random time datetime os sys hashlib collections
今日内容笔记和代码: https://github.com/libo-sober/LearnPython/tree/master/day13 昨日内容回顾 自定义模块 模块的两种执行方式 __name ...
- python常用模块collections os random sys
Python 模块(Module),是一个 Python 文件,以 .py 结尾,包含了 Python 对象定义和Python语句. 模块让你能够有逻辑地组织你的 Python 代码段. 把相关的代码 ...
- day19:常用模块(collections,time,random,os,sys)
1,正则复习,re.S,这个在用的最多,re.M多行模式,这个主要改变^和$的行为,每一行都是新串开头,每个回车都是结尾.re.L 在Windows和linux里面对一些特殊字符有不一样的识别,re. ...
- python----常用模块(random,string,time&datetime,os,sys,xpinyin(拼音))
一.模块.包 1.1 什么是模块 在python中,一个.py文件就构成一个模块,意思就是说把python代码写到里面,文件名就是模块的名称,test.py test就是模块名称. 1.2 什么是包 ...
- day22 模块-collections,time,random,pickle,shelve等
一.引入模块的方式: 1. 认识模块 模块可以认为是一个py文件. 模块实际上是我们的py文件运行后的名称空间 导入模块: 1. 判断sys.modules中是否已经导入过该模块 2. 开辟一个内存 ...
- python学习之老男孩python全栈第九期_day019知识点总结——collections模块、时间模块、random模块、os模块、sys模块
一. collections模块 在内置数据类型(dict.list.set.tuple)的基础上,collections模块还提供了几个额外的数据类型:namedtuple.deque.Counte ...
- 6 - 常用模块(os,sys,time&datetime,random,json&picle,shelve,hashlib)
导入模块 想使用 Python 源文件,只需在另一个源文件里执行 import 语句 import module1[, module2[,... moduleN] from语句让你从模块中导入一个指定 ...
随机推荐
- 如何使用helm优雅安装prometheus-operator,并监控k8s集群微服务
前言:随着云原生概念盛行,对于容器.服务.节点以及集群的监控变得越来越重要.Prometheus 作为 Kubernetes 监控的事实标准,有着强大的功能和良好的生态.但是它不支持分布式,不支持数据 ...
- Python-Django模板
前面将hello world输出给浏览器,将数据与 视图 混合在一起,不符合 MVC思想. 模板就是一个文本,用来分离文档的表现形式和内容. 在templates目录下创建一个html模板 然后需要向 ...
- es证书生成方式
./bin/elasticsearch-certutil ca --pem # 生成一个名字叫做elastic-stack-ca.zip的文件 unzip elastic-stack-ca.zip A ...
- Query String Query和Sumple Query String
- Node.js躬行记(23)——Worker threads
Node.js 官方提供了 Cluster 和 Child process 创建子进程,通过 Worker threads 模块创建子线程.但前者无法共享内存,通信必须使用 JSON 格式,有一定的局 ...
- 论文解读(FedGAT)《Federated Graph Attention Network for Rumor Detection》
论文信息 论文标题:Federated Graph Attention Network for Rumor Detection论文作者:Huidong Wang, Chuanzheng Bai, Ji ...
- PAT (Basic Level) Practice 1019 数字黑洞 分数 20
给定任一个各位数字不完全相同的 4 位正整数,如果我们先把 4 个数字按非递增排序,再按非递减排序,然后用第 1 个数字减第 2 个数字,将得到一个新的数字.一直重复这样做,我们很快会停在有" ...
- WSL 2 上启用微软官方支持的 systemd
以前折腾了很久的 genie 和 distrod 来实现 wsl2 上的 systemd.现在微软和Canonical联合声明发布了官方支持的systemd,之前的折腾貌似有点浪费时间了.如果微软不发 ...
- 企业运维 | MySQL关系型数据库在Docker与Kubernetes容器环境中快速搭建部署主从实践
[点击 关注「 WeiyiGeek」公众号 ] 设为「️ 星标」每天带你玩转网络安全运维.应用开发.物联网IOT学习! 希望各位看友[关注.点赞.评论.收藏.投币],助力每一个梦想. 本章目录 目录 ...
- img通过修改css等比例缩小图片
css中加上:object-fit:cover 例子: img{ width: 200px; height: 400px; object-fit: cover; }