爬虫五之Selenium
Selenium
自动化测试工具,支持多种浏览器;
爬虫中主要用来解决JavaScript渲染问题。
用法详解
基本使用

声明浏览器对象
from selenium import webdriver
browser = webdriver.Chrome()
browser = webdriver.Firefox()
browser = webdriver.Edge()
browser = webdriver.PhantomJS()
browser = webdriver.Safari()
访问页面
browser = webdriver.Chrome()
browser.get('https://www.taobao.com')
print(browser.page_source)
browser.close()
查找元素
单个元素
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.taobao.com')
input_first = browser.find_element_by_id('q')
input_second = browser.find_element_by_css_selector('#q')
input_third = browser.find_element_by_xpath('//*[@id="q"]')
print(input_first, input_second, input_third)#这些方法效果是同样的
browser.close()
一样的方法
from selenium import webdriver
from selenium.webdriver.common.by import By
browser = webdriver.Chrome()
browser.get('https://www.taobao.com')
input_first = browser.find_element(By.ID,'q')
print(input_first)
browser.close()
多个元素
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.taobao.com')
lis = browser.find_elements_by_css_selector('.service-bd Ii')
print(lis)
browser.close()
from selenium import webdriver
from selenium.webdriver.common.by import By
browser = webdriver.Chrome()
browser.get('https://www.taobao.com')
lis = browser.find_elements(By.CSS_SELECTOR,'.service-bd li')
print(lis)
browser.close()
元素交互操作
对获取的元素调用交互方法

交互动作
将动作附加到动作链中串行执行

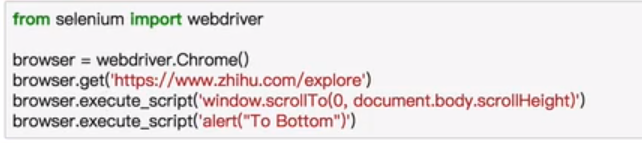
执行JavaScript
获取元素信息


Frame

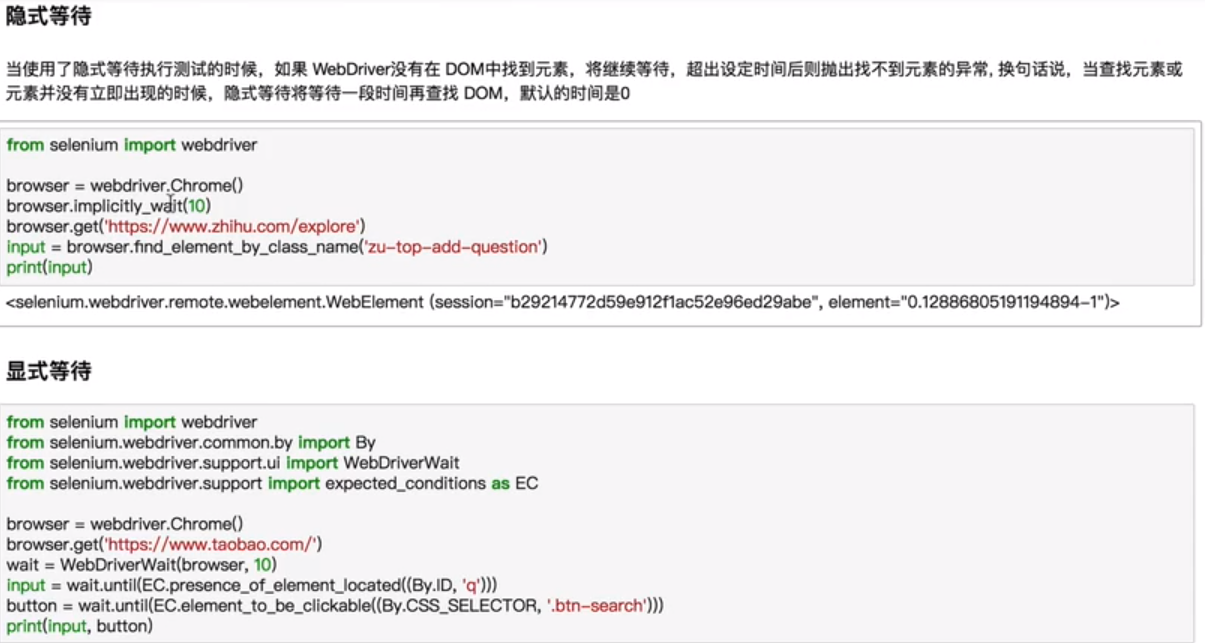
等待


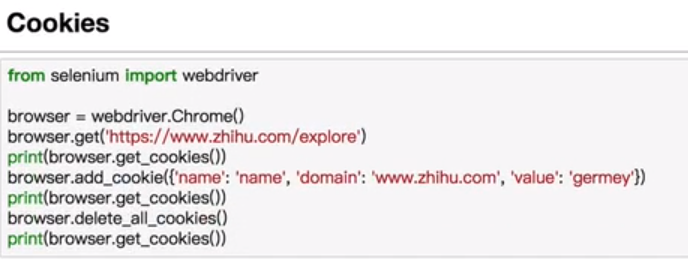
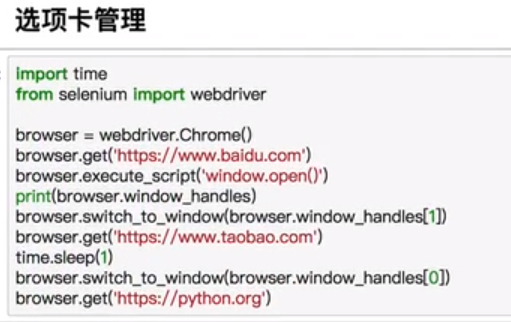
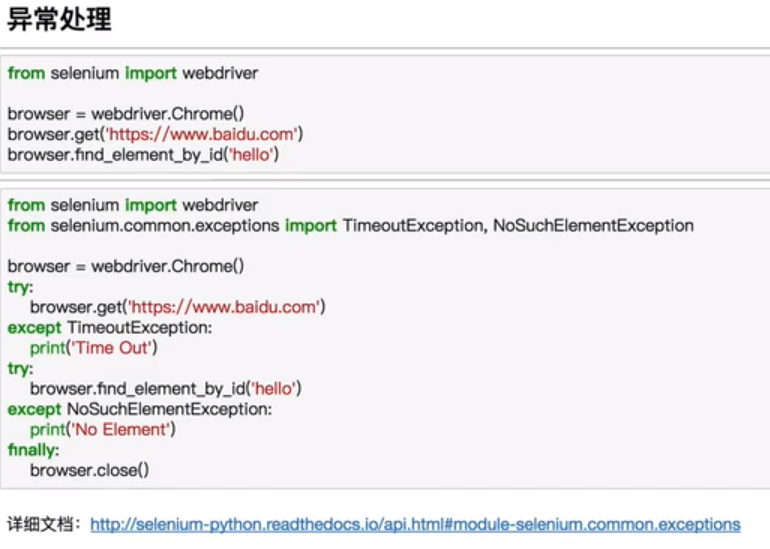
爬虫五之Selenium的更多相关文章
- Python爬虫之设置selenium webdriver等待
Python爬虫之设置selenium webdriver等待 ajax技术出现使异步加载方式呈现数据的网站越来越多,当浏览器在加载页面时,页面上的元素可能并不是同时被加载完成,这给定位元素的定位增加 ...
- python爬虫动态html selenium.webdriver
python爬虫:利用selenium.webdriver获取渲染之后的页面代码! 1 首先要下载浏览器驱动: 常用的是chromedriver 和phantomjs chromedirver下载地址 ...
- scrapy爬虫框架和selenium的配合使用
scrapy框架的请求流程 scrapy框架? Scrapy 是基于twisted框架开发而来,twisted是一个流行的事件驱动的python网络框架.因此Scrapy使用了一种非阻塞(又名异步)的 ...
- # Python3微博爬虫[requests+pyquery+selenium+mongodb]
目录 Python3微博爬虫[requests+pyquery+selenium+mongodb] 主要技术 站点分析 程序流程图 编程实现 数据库选择 代理IP测试 模拟登录 获取用户详细信息 获取 ...
- [Python爬虫] 之十五:Selenium +phantomjs根据微信公众号抓取微信文章
借助搜索微信搜索引擎进行抓取 抓取过程 1.首先在搜狗的微信搜索页面测试一下,这样能够让我们的思路更加清晰 在搜索引擎上使用微信公众号英文名进行“搜公众号”操作(因为公众号英文名是公众号唯一的,而中文 ...
- python爬虫入门(五)Selenium模拟用户操作
爬虫(Spider),反爬虫(Anti-Spider),反反爬虫(Anti-Anti-Spider) 之间恢宏壮阔的斗争... 小莫想要某站上所有的电影,写了标准的爬虫(基于HttpClient库), ...
- 爬虫(五)—— selenium模块启动浏览器自动化测试
目录 selenium模块 一.selenium介绍 二.环境搭建 三.使用selenium模块 1.使用chrome并设置为无GUI模式 2.使用chrome有GUI模式 3.查找元素 4.获取标签 ...
- Python爬虫利器五之Selenium的用法
1.简介 Selenium 是什么?一句话,自动化测试工具.它支持各种浏览器,包括 Chrome,Safari,Firefox 等主流界面式浏览器,如果你在这些浏览器里面安装一个 Selenium 的 ...
- [Python爬虫] 之二十五:Selenium +phantomjs 利用 pyquery抓取今日头条网数据
一.介绍 本例子用Selenium +phantomjs爬取今日头条(http://www.toutiao.com/search/?keyword=电视)的资讯信息,输入给定关键字抓取资讯信息. 给定 ...
随机推荐
- 2017 CVTE Windows开发二面 3.8 (offer)
中午1点左右,广州的号码打过来了,是CVTE的hr,然后问我下午4点半有没有时间,帮我约视频的二面. 当然有时间了啦,然后hr给我邮箱发了个链接,让我4点半登陆进去. 因为1面没问任何网络和操作系统的 ...
- mysql数据库之 存储引擎、事务、视图、触发器、存储过程、函数、流程控制、数据库备份
目录 一.存储引擎 1.什么是存储引擎? 2.mysql支持的存储引擎 3. 使用存储引擎 二.事务 三.视图 1.什么是视图 2.为什么要用视图 3.如何用视图 四.触发器 为何要用触发器 创建触发 ...
- QT:QSS ID选择器无效
我正在学习使用Qt样式表给我的应用程序添加不同的样式.我上网看了看Qt文档,上面说你可以使用一种ID选择器,它可以把主题应用到某些对象上.我就是这样实现这个特性的: QPushButton#butto ...
- iview响应式布局
我想说,我要被逼成前端了. 之前没接触过响应式,这两天和另一位前端程序媛小小的研究了下.做了一个小例子,记录一下,方便以后使用. <template> <div> <Ro ...
- JAVA学长
https://www.cnblogs.com/chenmingjun/p/9697371.html
- 微信支付(公众号)爬坑记,包含 total_fee 失败和 JSAPI 签名验证失败等等
做商城类网站不免会需要做支付功能,目前在中国大陆通用的做法就是使用支付宝支付和微信支付,上一篇博文已经讲个支付宝支付. 这篇文章来讲一讲微信支付,微信支付的方式有很多种,本文主要讲 JSAPI 支付的 ...
- 分享几个免费IP地址查询接口(API)
淘宝IP地址库 提供的服务包括:1. 根据用户提供的IP地址,快速查询出该IP地址所在的地理信息和地理相关的信息,包括国家.省.市和运营商.2. 用户可以根据自己所在的位置和使用的IP地址更新我们的服 ...
- Linux环境下TomCat使用指定JDK的版本
服务器是web服务器,在上面安装了jdk1.7和jdk1.8.及多个tomcat应用,默认/etc/profile 配置的jdk1.7,大部分tomcat应用使用的也是jdk1.7, 但目前有一个新项 ...
- C++入门经典-例5.20-右值引用传递参数
1:使用字面值(如1.3.15f.true),或者表达式等临时变量作为函数实参传递时,按左值引用传递参数会被编译器阻止.而进行值传递时,将产生一个和参数同等大小的副本.C++11提供了右值引用传递参数 ...
- maven的依赖传递及冲突
A->B(compile) 第一关系: a依赖b compile B->C(compile) 第二关系: b依赖c compile 当在A中配置 <dep ...