Step-by-step from Markov Process to Markov Decision Process
In this post, I will illustrate Markov Property, Markov Reward Process and finally Markov Decision Process, which are fundamental concepts in Reinforcement Learning.
Markov Property
'The state is independent of the past given the present'
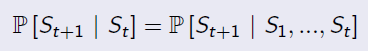
Markov Process (Markov Chain)
Keywords: state, transition matrix
A Markov Process is defined by a Tuple(S,P), in which S is the state space, and P is the transition matrix. The following chart is an example.
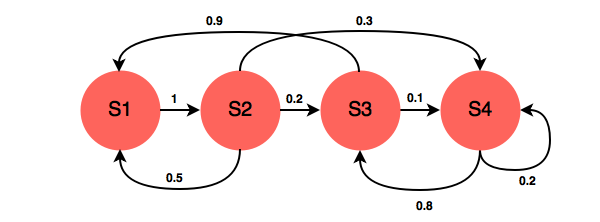
A transition matrix demonstrates the probabilities of transitioning from one state to another.


In the example above, the transition matrix is:

Markov Reward Process: Markov Process with Value Judgement
Keywords: Reward, Return, Discount Factor, Value Function
MRP add two additional properties into Markov Chain: one is Reward, who represents the immediate feedback an agent can receive at time t+1 if he is in state s at time t; another property is Discount Factor γ∈[0,1]. So the representation tuple is [S,P,R,γ].
Formally, Reward is the immediate feedback, which means when agent gets to state s at time t, it can definetly receive this reward at time t+1. It is defined by:

Given reward and discount factor, we can calculate the Return for a given senario by this equation:
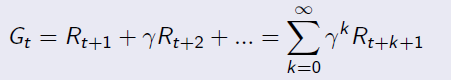
Example for Return calculation:
Senario: Class1->Class2->Class3->Pass->Sleep, and the agent is at state=Class1.
Case 1: when gamma=0, g=-2+(-2)*0+(-2)*0+10*0=-2
Case 2: when gamma=1, g=-2+(-2)*1+(-2)*1+10*1=4
Case 3: when gamma=0.8, g=-2+(-2)*0.8+(-2)*0.64+10*=-4-1.6+5.12=-0.48
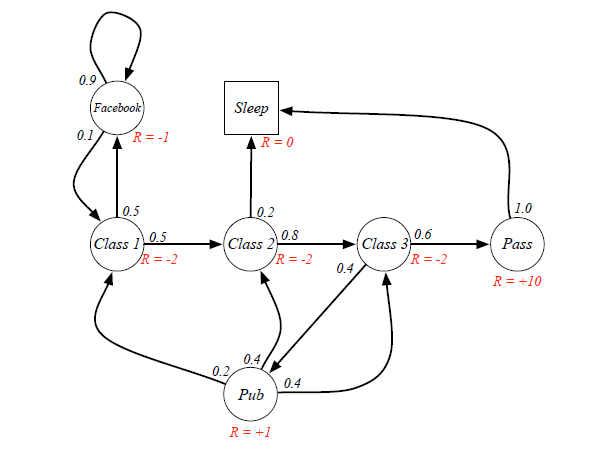
From different γ, we know our agent can be exetremely short-sighted (far-sighted) only for immediate reward, or trying to seek balance between short and long term reward.
When an agent is in a certain state, the way to measure the total reward from this state over time is calculating expected Returns for all possible senarios. The function to calculate it is called Value Function:
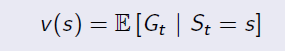
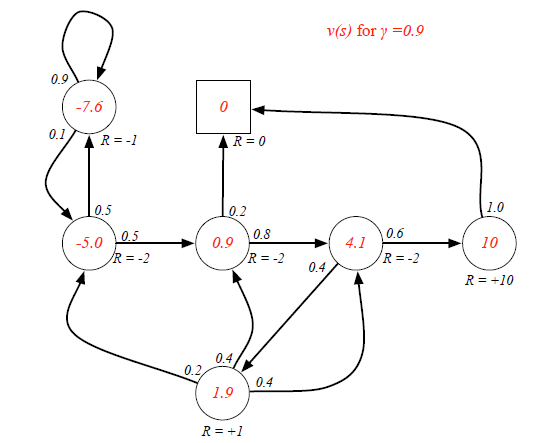
Ex. If the agent is at Class3 state, it has 0.6 and 0.4 probabilities to transite to Pass and Pub respectively. Because there are loops inside the graph, it's difficult to directly derive expected return from value function. (Forget the red labeled value, they are result...)
Bellman Equation helps to solve this complexity:
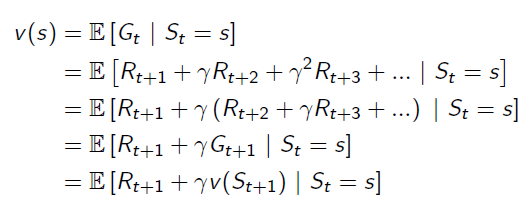
It breaks the value function into two parts: Immediate Reward and Future Reward: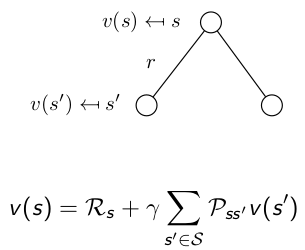 The future reward is discounted by γ, and it has probabilities on different states, so actually the future reward is an expectation.
The future reward is discounted by γ, and it has probabilities on different states, so actually the future reward is an expectation.
Now we can use Bellman Equation to solve value function: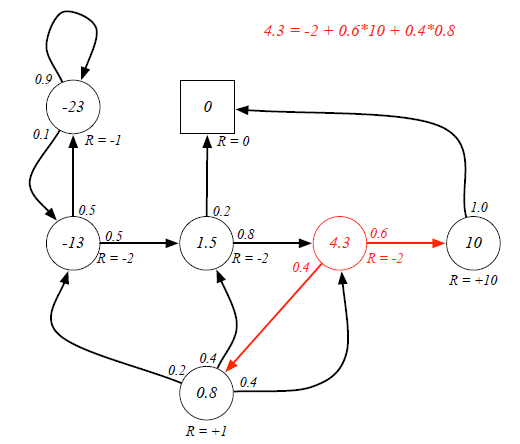
Markov Decision Process: MRP with Actions
Keywords: Action
Markov Decision Process adds more complexity onto MRP, it is defined by a tuple(S,A,P,R,γ), in which:
S is state space, and γ is discount factor, they are same as MRP.
A is a finite set of Actions, which is new. Then because of the existense of Action, Transition Matrix and Reward Function are all conditional on both State and Action.
P is State Transition Matrix: it is conditional on state and action at time t, which means different actions would result in different distribution of state at time t+1.
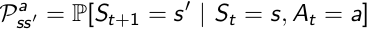
R is Reward Function conditional upon state and action: also, different actions lead to different reward, despite of the same state s.
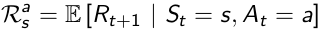
A graph(from Wikipedia) helps understanding the role of actions:
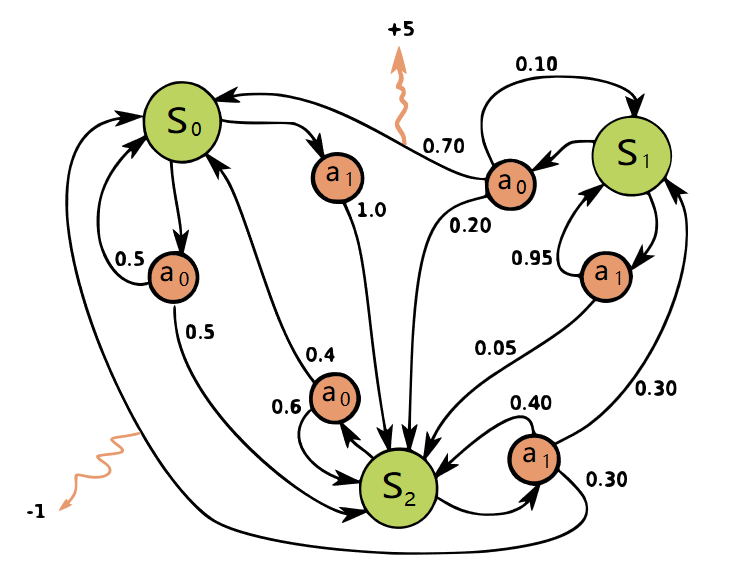
So by now, we have already had the model of the environment: all states, all possible actions and transition matrix conditional on state and actions.
Step-by-step from Markov Process to Markov Decision Process的更多相关文章
- Step by step Process of creating APD
Step by step Process of creating APD: Business Scenario: Here we are going to create an APD on top o ...
- Step by Step Process of Migrating non-CDBs and PDBs Using ASM for File Storage (Doc ID 1576755.1)
Step by Step Process of Migrating non-CDBs and PDBs Using ASM for File Storage (Doc ID 1576755.1) AP ...
- Tomcat Clustering - A Step By Step Guide --转载
Tomcat Clustering - A Step By Step Guide Apache Tomcat is a great performer on its own, but if you'r ...
- [ZZ] Understanding 3D rendering step by step with 3DMark11 - BeHardware >> Graphics cards
http://www.behardware.com/art/lire/845/ --> Understanding 3D rendering step by step with 3DMark11 ...
- e2e 自动化集成测试 架构 实例 WebStorm Node.js Mocha WebDriverIO Selenium Step by step (二) 图片验证码的识别
上一篇文章讲了“e2e 自动化集成测试 架构 京东 商品搜索 实例 WebStorm Node.js Mocha WebDriverIO Selenium Step by step 一 京东 商品搜索 ...
- Code Understanding Step by Step - We Need a Task
Code understanding is a task we are always doing, though we are not even aware that we're doing it ...
- enode框架step by step之saga的思想与实现
enode框架step by step之saga的思想与实现 enode框架系列step by step文章系列索引: 分享一个基于DDD以及事件驱动架构(EDA)的应用开发框架enode enode ...
- 课程五(Sequence Models),第一 周(Recurrent Neural Networks) —— 1.Programming assignments:Building a recurrent neural network - step by step
Building your Recurrent Neural Network - Step by Step Welcome to Course 5's first assignment! In thi ...
- 精通initramfs构建step by step
(一)hello world 一.initramfs是什么 在2.6版本的linux内核中,都包含一个压缩过的cpio格式 的打包文件.当内核启动时,会从这个打包文件中导出文件到内核的rootfs ...
随机推荐
- Codeforces 833B 题解(DP+线段树)
题面 传送门:http://codeforces.com/problemset/problem/833/B B. The Bakery time limit per test2.5 seconds m ...
- Codeforces 1159D The minimal unique substring(构造)
首先我们先观察三个串 10,1110,11101110,答案都是红色部分,我们可以下一个结论,形如 1,1101,111101,那么答案为红色部分.我们可以发现,通过我们末尾添加的1,导致之前红色部分 ...
- AtCoder Beginner Contest 133 B - Good Distance
地址:https://atcoder.jp/contests/abc133/tasks/abc133_b 核心问题:判断一个浮点数开方是否为整数 ; double ans1=sqrt(ans); if ...
- NancyFx 2.0的开源框架的使用-ConstraintRouting
新建一个空的Web项目 然后在Nuget库中安装下面两个包 Nancy Nancy.Hosting.Aspnet 然后在根目录添加三个文件夹,分别是models,Module,Views 然后往Mod ...
- CA认证机制的简明解释
公钥机制面临的问题: 假冒身份发布公钥! 可以用CA来认证公钥的身份.CA有点像公安局,公钥就像身份证.公安局可以向任何合法用户颁发身份证以证明其合法身份.第三方只要识别身份证的真伪就能判断身份证持有 ...
- console.log 不起作用
devtool console.log 突然不起作用了
- java.util.Date 与 java.sql.Date 相关知识点解析
问:java.sql.Date 和 java.util.Date 有什么区别? 答:这两个类的区别是 java.sql.Date是针对 SQL 语句使用的,它只包含日期而没有时间部分,一般在读写数 ...
- JavaWeb(九):上传和下载
表单 进行文件上传时, 表单需要做的准备: 1). 请求方式为 POST: <form action="uploadServlet" method="post&qu ...
- django数据库迁移相关【sqlite3迁移到MySQL】(django2.0.3测试通过)
前言 项目部署到服务器之后,用的数据库还是sqlite3. 发现一些问题,sqlite3是小巧,但是服务器上查看数据库比较费劲,不能直观看到数据.可是我们经常需要即时.直观查看数据,这就用到MySQL ...
- Vue的思考扩展
1.Vue是如何实现数据双向绑定的 1.1.实现双向绑定的基本原理 数据驱动:Vue会通过Dircetives指令,对DOM做一层封装,当数据发生改变会通知指令去修改对应的DOM,数据驱动DOM变化, ...