Linux多线程服务器端编程
Linux多线程服务器端编程
- 源码链接。
- muduo的编译安装.
- 陈硕的编译教程。
- bazel编译文件不能有中文路径。
- 安装到指定目录:
- /usrdata/usingdata/studying-coding/server-development/server-muduo/build/release-install-cpp11/lib/libmuduo_base.a.
- 这本书前前后后看了三四遍,写得非常有深度,值得推荐。
- 编译和安装.
线程安全的对象生命期管理
利用shared_ptr和weak_ptr避免对象析构时存在的竞争条件(race conditon).
当一个对象被多个线程同时看到,那么对象的销毁时机就会变得模糊不清,可能出现多种竞争条件(race condition).
用RAII(Resource Acquire Is Initialization, 资源申请即初始化)封装互斥量的创建和销毁, MutexLock封装临界区(critical section), 资源管理类。
MutexLockGuard封装临界区的进入和退出,即加锁和解锁,MutexLockGuard一般是个栈上对象,它的作用域刚好等于临界区域。
-
- 把copy构造函数和复制操作符声明为私有函数并不声明。
- 在C++11中使用delete关键字,muduo采用了这种方式。
namespace muduo
{ class noncopyable
{
public:
noncopyable(const noncopyable&) = delete;
void operator=(const noncopyable&) = delete; protected:
noncopyable() = default;
~noncopyable() = default;
}; } // namespace muduo
对象构造要做到线程安全,唯一的要求是在构兆期间不要泄漏this指针。
- 不要在构造函数中注册任何回调;(利用二段式构造(构造函数+initialization()),或直接调用register_函数)
- 不要把在构造函数中把this传给跨线程的对象;
- 即便在构造函数的最后一行也不行。(构造函数执行期间对象还没有完成初始化。)
对象的销毁线程比较难
- 单线程对象析构要注意避免空悬指针和野指针。多线线程每个成员函数的临界区域不得重叠,而且成员函数用来保护临界区的互斥器本身必须是有效的。
- 在析构函数中直接调用互斥器进行多线程的同步是不可取的,没有完全达到线程安全的效果。
- 作为数据成员的mutex不能保护析构, 因为成员的生命周期最多与对象一样长,而析构动作可以发生在对象死亡之后。(调用基类析构函数时,派生类的析构函数已经被调用)
- 析构函数本身不需要保护,因为只有别的线程都访问不到这个对象时,析构才是安全的。
- 如果要锁住相同类型的多个对象,为了保证始终按相同的顺序加锁,可以比较mutex对象的地址,始终先加锁地址较小的mutex.(防止死锁)
- 判断一个指针是不是合法指针没有高效的办法,这是C/C++指针问题的根源。
- 调用正在析构对象的任何非静态成员函数都是不安全的,更何况是虚函数。
- 指向对象的原始指针(raw pointer)最好不要暴露给别的线程。--- 一般用智能指针
- 解决空悬指针的办法是,引入一层间接性。(handle/body惯用技法)
- shared_ptr指针源码分析.
- shared_ptr控制对象的生命期,是强引用,只要有一个指向x对象的shared_ptr存在,该x对象就不会析构,当指向对象x的最后一个shared_ptr析构或reset()调用时,x保证会被销毁。
- weak_ptr不控制对象的生命期,但它知道对象是否还或者;
- 如果对象还活着,weak_ptr可以提升为有效的shared_ptr;
- 如果对象已经死了,提升失败,返回一个空的shared_ptr;
- 提升函数lock()行为是线程安全的。
- shared_ptr/weak_ptr的计数在主流平台上是原子操作,没有用锁,性能不俗。
- 资源(包括复杂对象本省)都是通过对象(只能指针或容器)来管理,不要直接调用delete来删除资源。
- shared_ptr本身的引用计数本身是线程安全的,但是读写操作不是原子化的。
- shared_ptr技术与陷阱:
- 如果不小心多进行了拷贝或赋值就会意外延长对象的生命周期。
- 析构动作在创建时被捕获;
- shared_ptr可以持有任何对象,而且能安全地释放。(析构动作可以定制)
- 为了不影响关键线程的速度,可以用一个单独的线程来做shared_ptr对象的析构。
- 要避免shared_ptr管理共享资源时引起的循环引用,通常做法是owner持有指向child的shared_ptr,child持有指向owner的weak_ptr.
- shared_ptr的析构函数可以有一个额外的模板类参数,传入一个函数指针或反函数d,在析构对象时执行d(ptr),其中ptr是shared_ptr保存的对象指针。
- 弱回调技术会在事件通知中会非常有用。
线程同步精要
- 线程同步的四原则:
- 首要原则是尽量最低限度地共享对象,减少需要同步的场合。
- 其次使用高级的并发编程构建(TaskQueue, Producer-Consumer Queue, CountDownLatch(倒计时)).
- 最后不得已必须使用底层同步原语(promitives)时,只用非递归的互斥器和条件变量,慎用读写锁,不要用信号量。
- 使用非递归(non-recursive)互斥量可以把程序错误尽早地暴露出来。
- 除了使用atomic整数之外,不自己编写lock-free代码,也不要用内核级的同步原语。
- 如果坚持Scoped Locking,那么出现死锁的时候就很容易定位。
gdb ./self_deadlock core--- 调试定位死锁。- __attribute__可以用来防止函数inline内联展开。
- 条件变量(condition variable): 一个或多个线程等待某个布尔表达式为真,即等待别的线程唤醒它。
- 条件变量的学名叫作管程(monitor);
- 必须和mutex一起使用, 该布尔表达式的读写受此mutex保护。
- 在mutex已上锁的时候才能调用wait().
- 把判断布尔条件和wait()放到while循环中。
- 虚假唤醒(spurious wakeup):
- 为什么条件锁会产生虚假唤醒现象, spurious wakeup.
- 虚假唤醒的一个可能性是条件变量的等待被信号中断.
- 倒计时(CountDownLatch)是一种常用且易用的同步手段,主要用途:
- 主线程等待多个子线程完成初始化;
- 多个子线程等待主线程发起起跑命令。
- 使用CountDownLatch使程序逻辑更清楚。
- pthread_onece保证函数只执行一次。
- sleep并不是同步原语。
- 如果需要等待一段已知的时间,应该往event loop里注册一个timer,然后在timer的回调函数里接着干活,因为线程是个珍贵的资源,不能轻易浪费(阻塞也是浪费)。
借shared_ptr实现写时拷贝(copy-on-write)
- 写时如果引用计数大于1,该如何处理?
- 用普通的mutex替换读写锁。
- 大多数情况下更新都是在原来数据上进行的,拷贝的比例还不到1%.
多线程服务器的适用场合与常用编程模型
- 进程(process)是操作系统里最重要的两个概念之一(另一个是文件),一个进程就是内存中正在运行的程序。
- 每个进程有自己独立的地址空间(adress space), 在同一个进程还是不在同一个进程是系统功能划分的重要决策。
- 把一个进程比喻成一个人,周期性的心跳判断对方是否还活着。
- 容错 --- 万一有人突然死了。
- 扩容 --- 新人中途加进来。
- 负载均衡 --- 把甲的活挪给乙做。
- 退休 --- 甲要修复Bug, 先别派新任务,等他做完手上的活就把他重启。
- 线程的特点是共享地址空间,从而可以高效地共享数据。
- 多进程可以高效地共享代码段,但是不能共享数据。
- 多线程可以高效地发挥多核的效能。(单核,按照状态机编程思想比较高效)
单线程服务器的常用编程模型
- “nonblocking IO + IO multiplexing(非阻塞IO + IO 多路复用)”, 即Reactor模式(反应堆模式)。
- lighttpd, 单线程服务器(Nginx与之类似,每个工作进程有一个事件循环(event loop)).
- libevent, libev.
- ACE, Poco C++ Libaries.
- Java NIO, 包括Aache Mina 和 Netty.
- POE(Perl).
- Twisted(Python).
- “nonblocking IO + IO multiplexing(非阻塞IO + IO 多路复用)”, 即Reactor模式(反应堆模式)的基本结构是一个事件循环:
- 以事件驱动和事件回调的方式实现业务逻辑。
- Reactor模式(Linux采用epoll机制)对于IO密集的应用是一个不错的选择。
- 巧妙地使用fdevent结构。
- 基于事件驱动的编程模式的本质缺点是: 要求事件回调函数必须是非阻塞的,容易割裂业务逻辑,将其散布于各个回调函数中。
多线程服务器的常用编程模型
每个请求创建一个线程,使用阻塞式IO操作(可伸展性不佳)。
使用线程池。
- 阻塞的任务队列(blocking queue TaskQueue)。
- Intel Threading Building Blocks的concurrent_queue性能比较好。
- 线程池(thread pool)用来做计算, 可以用任务队列或者是生产者消费者队列实现。
使用nonblocking IO + IO multiplexing(非阻塞IO + IO 多路复用)。
- 每个IO线程有一个event loop(或者叫Reactor)用于处理读写和定时事件。
- 对实时性要求高的连接(connection)可以单独使用一个线程。
- 数据量大的连接可以独占一个线程,并把数据处理任务分摊到另几个计算线程中(用线程池)。
- 其他辅助性的连接可以共享一个线程。
Leader/Follower等高级模式。
进程间通信:
- 匿名管道(pipe);
- 用来异步唤醒select(或等价的poll或epoll_wait)调用。
- 具名管道(FIFO);
- POSIX消息队列;
- 共享内存;
- 共享内存是消息协议,a进行填好一块内存让b进程来读,基本上是停等方式(stop wait).
- 信号(signals);
- 套接字(socket),一般用TCP, 不考虑domain协议和UDP(可以跨主机,具有伸缩性)。
- TCP是双向的,管道pipe是单向的(进程间双向通信需要打开两个文件描述符,父子进程才能用pipe).
- 套接字由一个进程独占,且操作系统会自动回收(关闭文件描述符时)。
- 套接字是端口是独占的,可以防止程序重复启动。
- 可以用tcpcopy工具进行压力测试。
- TCP是字节流协议,只能顺序读取,有写缓冲区;
- RPC/HTTP/SOAP上层通信协议都是用的TCP网络层协议。
- 匿名管道(pipe);
同步原语(synchronization primitives):
- 互斥器(mutex);
- 条件变量(condition variable);
- 读写锁(reader-writer lock);
- 文件锁(recode locking);
- 信号量(semaphore)
分布式系统中使用TCP长连接通信
分布式系统是由运行在多台机器上的多个进程组成的,进程间采用TCP长连接通信(建立连接后不会立即关闭)。
在实现每一类服务器进程时,在必要时可以通过多线程提高性能。
对整个分布式系统,要做到能scale out, 即享受增加机器带来的好处。
TCP长连接的好处:
- 容易定位分布式系统中服务之间的依赖关系。 ---
netstat -tpna | grep :port- 客户端用netstat或lsof找到那个进程发起的连接。
- 通过接收和发送队列的长度也较容易定位网络或程序故障。 ---
netstat -tn观察Recv-Q和Send-Q的变化情况。
- 容易定位分布式系统中服务之间的依赖关系。 ---
Event Loop(事件循环): 事件循环的最明显的缺点是非抢占的(non-preemptive), 可能会发生优先级发转(通过多线程克服)。
多线程的使用适用场合:
- 提高响应速度,让IO和计算相互重叠,降低latency.
多线程不能提高并发度(并发连接数)。
多线程也不能提高吞吐量,但多线程能够降低响应时间。
线程池的经验公式 T=C/P(一个有C个CPU, 密集计算所占的时间比重为P( 0 < P <= 1)).
如果一次请求响应中要和别的进程打多次交道,那么Proactor模型往往能做到更高的并发度。
Proactor模式依赖操作系统或库来高效地调度这些子任务,每个子任务都不会阻塞,因此能用比较少的线程达到很高的IO并发度。
Proactor能提高吞吐量,但不能降低延迟。
C++多线程系统编程精要
- 多线程编程面临的最大思维方式的转变有两点:
- 当前线程可能随时会被切换出去,或者说被抢占(preempt)了。
- 多线程程序中,事件的发生顺序不再有全局同喜的先后关系。
- 多线程程序的正确性不能依赖于任何一个线程的执行速度,不能通过原地等待(sleep())来假定其他线程的时间已经发生,而必须通过适当的同步来让当前线程能看到其他线程的时间的结果。
- 线程(thread),互斥量(mutex),条件变量(condition)这三个线程原语可以完成任何多线程任务。
- 内存序(memory ordering),内存模型(memory model),内存能见度(memory visibility)。
- Linux系统本身是可以被抢占的(preemptive).
- errno是一个全局变量。
- 不用担心系统调用的线程安全性,因为系统调用对用户态程序来说是原子的。
- 但系统调用对于内核态的改变可能影响其他线程
- C++中的泛型函数一般都是线程安全的。C++ iostream不是线程安全的。
- pthreads只能保证同一进程内,同一时刻的各个线程的id不同;不能保证同一进程先后过个线程具有不同的id.
- 如果程序中不止一个线程,就很难安全地fork()了。
- 在main()函数之前不应该启动线程,因为这会影响全局对象的安全构造。
- 全局对象不能创建线程。
- kill一个进程比杀死本地进程内的线程要安全得多。
- 不要用共享内存和跨进程的互斥器等IPC, 因为这样仍然有死锁的可能。
- Thread的析构不会等待线程结束。
- 如果Thread对象的生命期短于线程,那么析构时会自动detach线程(僵死线程的感觉),避免资源泄漏。
- 程序中的线程创建最好能在初始化阶段全部完成,则程序是不必销毁的。
- 最好不要通过外部杀死线程。
- exit()可能导致析构对象时造成死锁。
- 善用__thread关键字,但只能用于内置类型。
- __thread变量是每个线程有一份独立实体,各个线程的变量值都互不干扰。
- 多线程磁盘IO的一个思路是每个磁盘配一个线程,把所有针对此磁盘的IO挪到同一个线程,可以避免或者减少内核中的锁竞争。
- 每个文件描述符只由一个线程操作。
- Linux/Unix中, 信号(signal)与多线程可谓是水火不相容,信号打断了正在运行的线程控制权。
- fork()之后, 子进程几乎继承父进程的所有状态,但子进程不会继承:
- 父进程的内存锁: mlock,mlockall.
- 父进程的文件锁: fcntl.
- 父进程的某些定时器,setitimer,alarm,timer_create等(man 2 fork).
- 多线程和fork协作很差,fork一般不能在多线程程序中调用,因为Linux中的fork只会克隆当前线程的线程控制权,不克隆其他线程。
- fork之后,除了当前线程之外,其他线程都消失了。
- 调用fork后,立即调用exec()执行另一个程序,彻底隔断子进程与父进程的联系。
高效的多线程日志
- 日志可以分为两类:
- 诊断日志(diagnostic log), 用于故障诊断和追踪(trace), 也可用于性能分析。
- 每条日志都要有对应的时间戳。
- 生产者-消费者模型: 对生产者(前端)而言,要尽量做到低延迟、低CPU开销、无阻塞;对消费者(后端)而言,要做到足够大的吞吐量,并占用较少的资源。
- 整个程序最好使用相同的日志库(库程序和主程序)。 --- 日志库最好是一个单例(singleton).
- 交易日志(transaction log), 用于记录状态变更,通过回放日志可以逐步恢复每一次修改的状态。
- 诊断日志(diagnostic log), 用于故障诊断和追踪(trace), 也可用于性能分析。
日志功能的需求
- 日志消息有多种级别(level): TRACE, DEBUG, INFO, WARN, ERROR,FATAL等。
- 日志消息的格式可配置(layout)。
- 日志消息可能有多个目的地(appender),如文件、socket,SMTP等。
- 可以设置运行时过滤器(filter),控制不同组件的日志消息的级别和目的地。
- 日志的输出级别需要在运行时进行动态调整(不需要重新编译,也不要重新启动进程)。
- muduo库只要调用muduo::Logger::setLogLevel()就能即时生效。
- 分布式系统中,日志的目的地(destination)只有一个: 本地文件。
- 因为诊断日志的功能之一就是诊断网络故障:
- 链接断开(网卡或交换机故障);
- 网络暂时不通(若干秒之内没有心跳消息);
- 网络拥塞(消息延迟明显加大)等。
- 也应该避免往网络文件系统(NFS)上写日志。
- 因为诊断日志的功能之一就是诊断网络故障:
日志回滚(rolling):
- 回滚(rolling)通常具有两个条件:
- 文件大小(如写满1GB就换下一个文件);
- 时间(如每天零点新建一个日志文件,不论前一个文件有没有写满)。
- 回滚(rolling)通常具有两个条件:
日志文件压缩和归档(archive)不是日志库应有的功能,应该交给专门的脚本去做。
定期(默认3秒)将缓冲区内的日志消息flush到硬盘;
每条内存中的日志消息都带有cookie(或者叫哨兵值/sentry),其值为某个函数地址,通过core dump查找cookie就能找到尚未来得及写入磁盘的消息。
muduo库的优化措施:
- 时间戳字符串中的日期和时间两部分是缓存的,一秒内的多条日志只需要重新格式化微妙部分。
- 日志消息的前4个字段是定长的,避免在运行期求字符串长度。
- 线程id是预格式化为字符串,在输出日志消息时只需简单拷贝几个字节。
- 文件名basename采用编译期计算。
多线程异步日志
多线程写多个文件也不一定会提速,所以尽量一个进程的多线程写一个文件。
- 用一个背景线程负责收集日志消息,并写入日志文件,其他线程只管往这个日志线程发送日志消息,这称为"异步消息"("非阻塞日志")。
在正常的实时业务处理流程中应该测底避免磁盘IO。
muduo日志库采用双缓冲技术(double buffering):
- 准备两块buffer: A和B, 前端负责往A填数据(日志消息),后端负责将buffer B的数据写入文件;
- 当buffer A写满之后,交换A和B,让后端将buffer A的数据写入文件,而前端则往buffer B填入新的日志消息,如此往复。
- 这么做的好处是:
- 新建日志消息的时候不必等待磁盘文件操作,也避免每条新日志消息都触发(唤醒)后端日志线程。
- 即便buffer A未填满,日志库也会每3秒执行一次交换写入操作。
- 坏处是: 前端消息速度(前端buffer写速度)要和buffer大小做好平衡,否则会出现后端写入磁盘还没有写完,前端的buffer就已经填满。
Java的ConcurrentHashmap那样用多个筒子(bucket),前端写日志的时候再按线程id哈希到不同的bucket, 以减少竞争。
Linux默认会把core dump写到当前目录,而且文件名是固定的core。(sysctl可以进行设置core dump的一些参数)
muduo网络库简介
- 高级语言(Java, Python等)Socket库并没有对Sockets API提供更高层的封装,直接调用很容易掉入到陷阱中;网络库的价值在于能方便地处理并发连接。
- muduo使用了较新的系统调用(主要是timefd和eventfd),要求linux内核的版本大于2.6.28.
- muduo是基于Reactor模式的网络库,其核心是个时间循环EventLoop, 用于响应计时器和IO事件。
- muduo采用基于对象而非面向对象的设计风格,其事件回调接口多以boost::function+boost::bind表达。
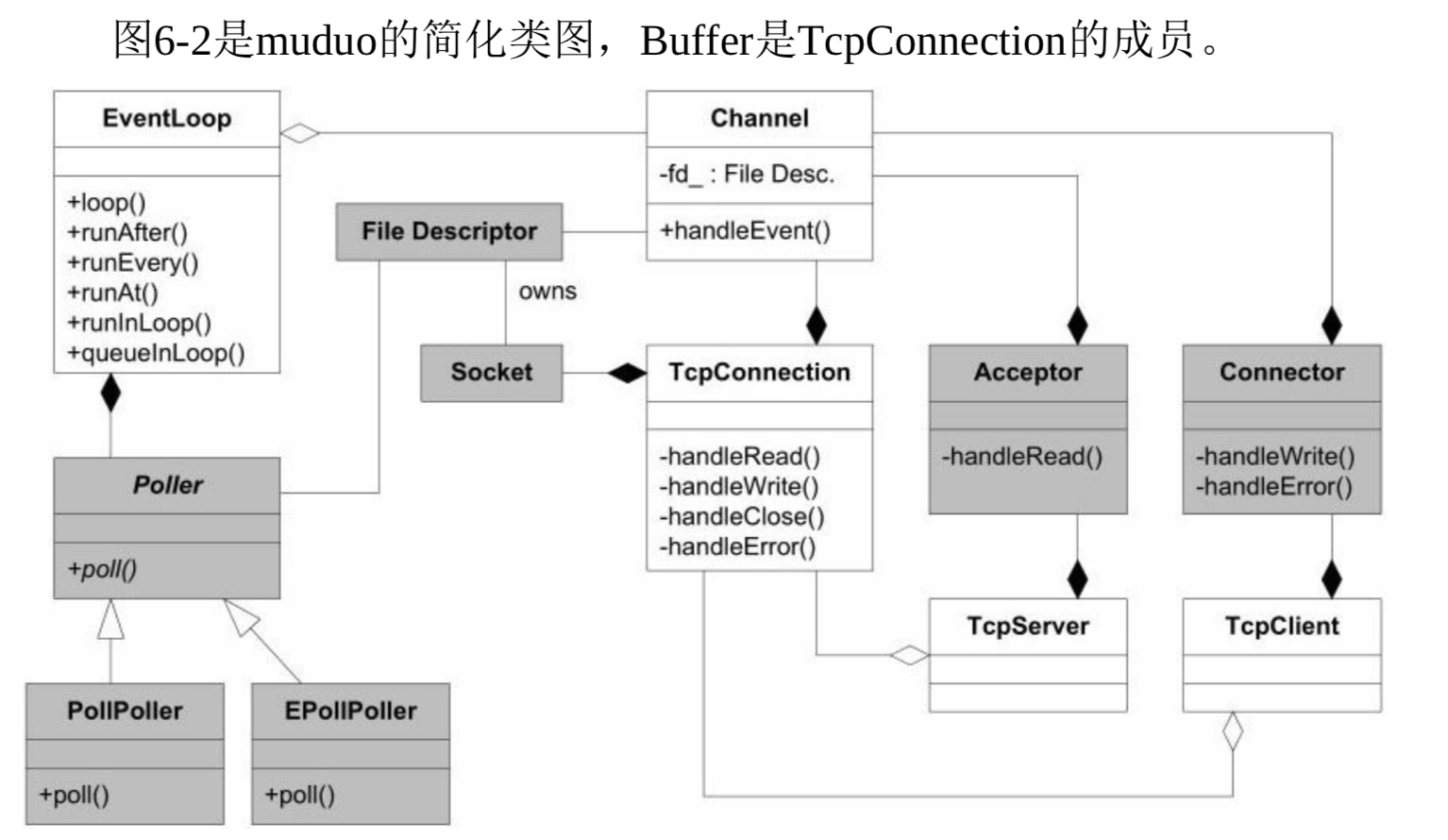
- muduo主要掌握关键的5个类: Buffer, EventLoop, TcpConnection, TcpClient, TcpSever.
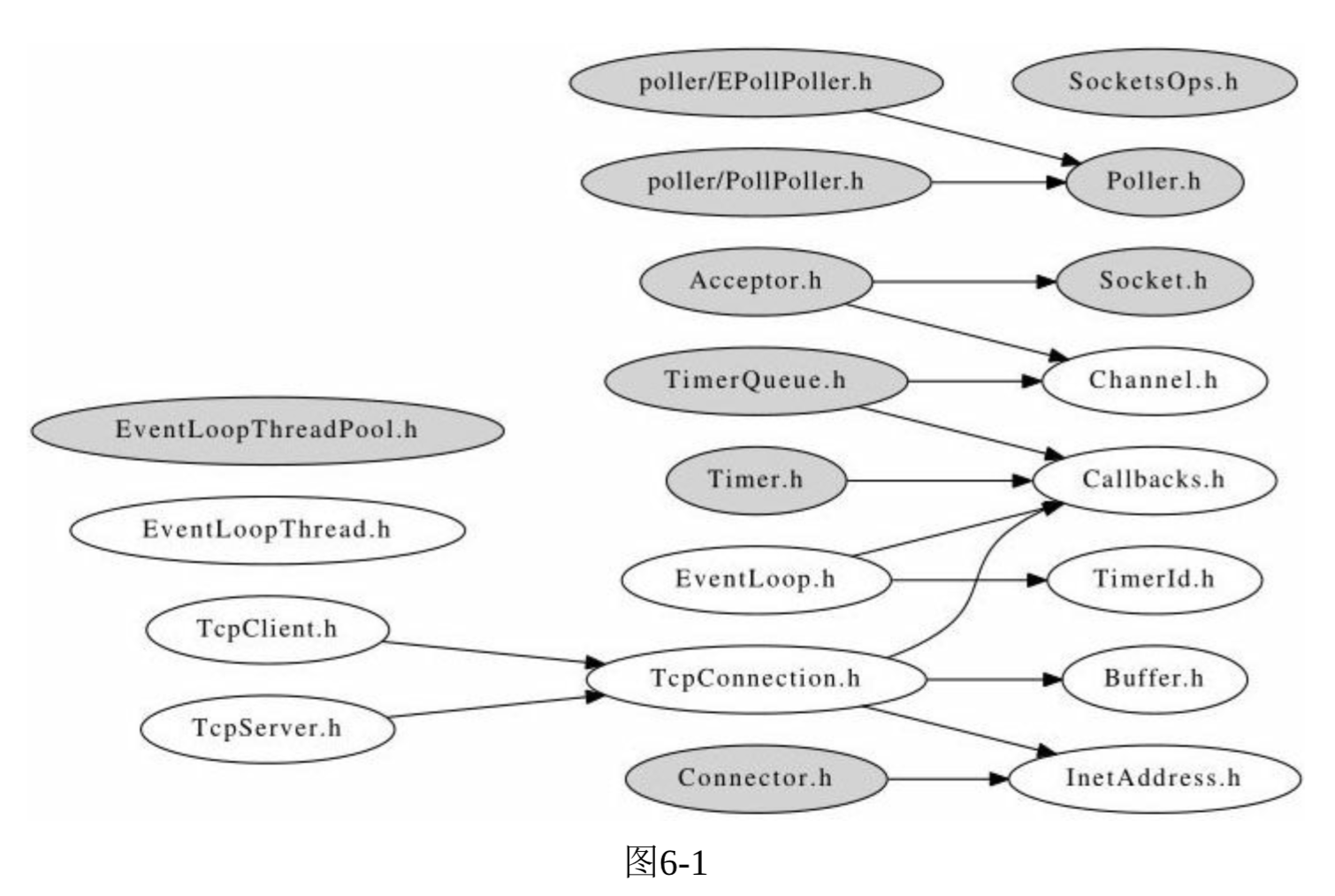 .
.
 .
. - 一个文件描述符(file descriptor)只能由一个线程读写。
- muduo支持非并发阻塞TCP网络编程,它的核心是每个IO线程一个事件循环,把IO事件分发到回调函数上。减少网络编程中的偶发复杂性(accidental complexity).
- muduo擅长的领域是TCP长连接(建立连接后一直收发、处理数据)。
TCP网络编程最本质的是处理三个半事件:
- 连接的建立: 服务端成功接受(accept)新连接和客户端成功发起(connect)连接。
- 连接的断开: 包括主动断开(close、shutdown)和被动断开(read(2) 返回0)。
- 消息到达,文件描述符可读: 对它的处理决定了网络编程的风格(阻塞还是非阻塞,如何处理分包,应用层的缓冲如何设计等)。
- 消息发送完毕,这算半个: 发送完毕是指数据写入操作系统的缓冲区,将由TCP协议栈负责数据的发送与重传,不代表对方已经收到了数据。
在一个端口上提供服务,并且要发挥多核处理器的计算能力
- 高性能httpd(httpd是一个开源软件,且一般用作web服务器来使用)普遍采用的是单线程Reactor方式。
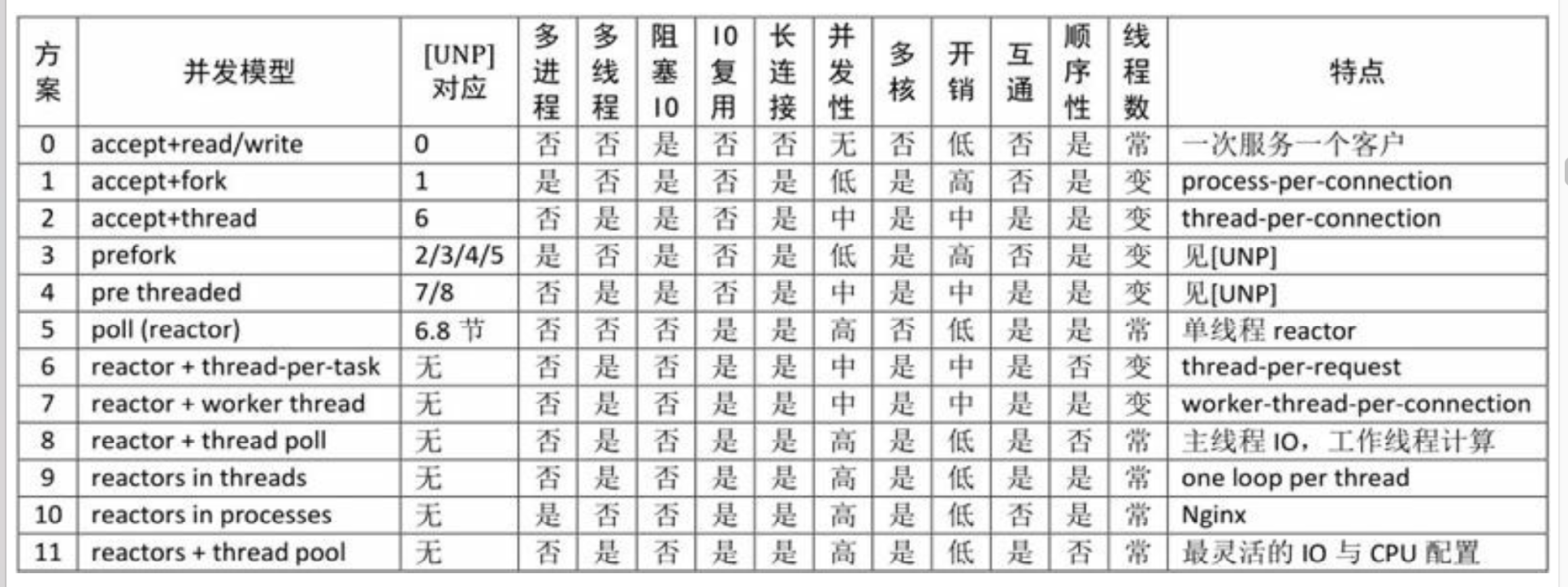
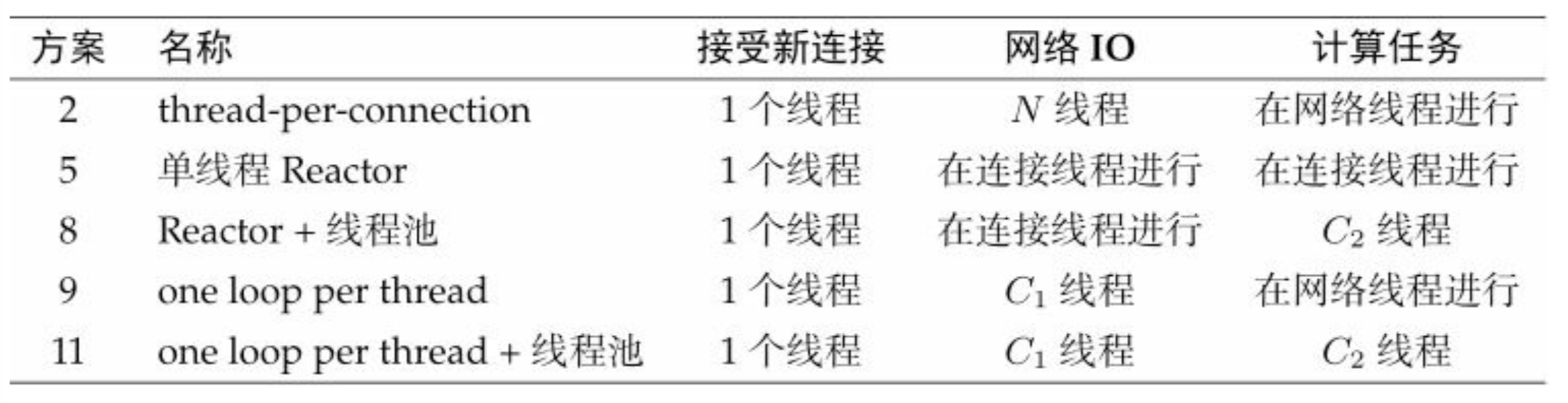
- 推荐的C++多线程服务端编程模式: one loop per thread + threadpool.
- event loop 用作non-blocking IO和定时器。
- threadpool用来做计算,具体可以是任务队列或生产者消费者队列。
- 实用的5种方案,muduo支持后4种:
muduo编程示例
- daytime是短连接协议,在发送完当前时间后,由服务端主动断开连接。
- 非阻塞网络编程必须在用户态使用接收缓冲区。
- TcpConnection对象表示一次TCP连接,连接断开后不能重建,重试后连接的会是另一个TcpConnection对象。
- Chargen协议很特殊,它只发送数据,不接收数据,而且,它发送数据的速度不能快过客户端接收的速度。
- 在非阻塞网络编程种,发送消息通常是由网络库完成,用户代码不会直接调用write或send等系统调用。
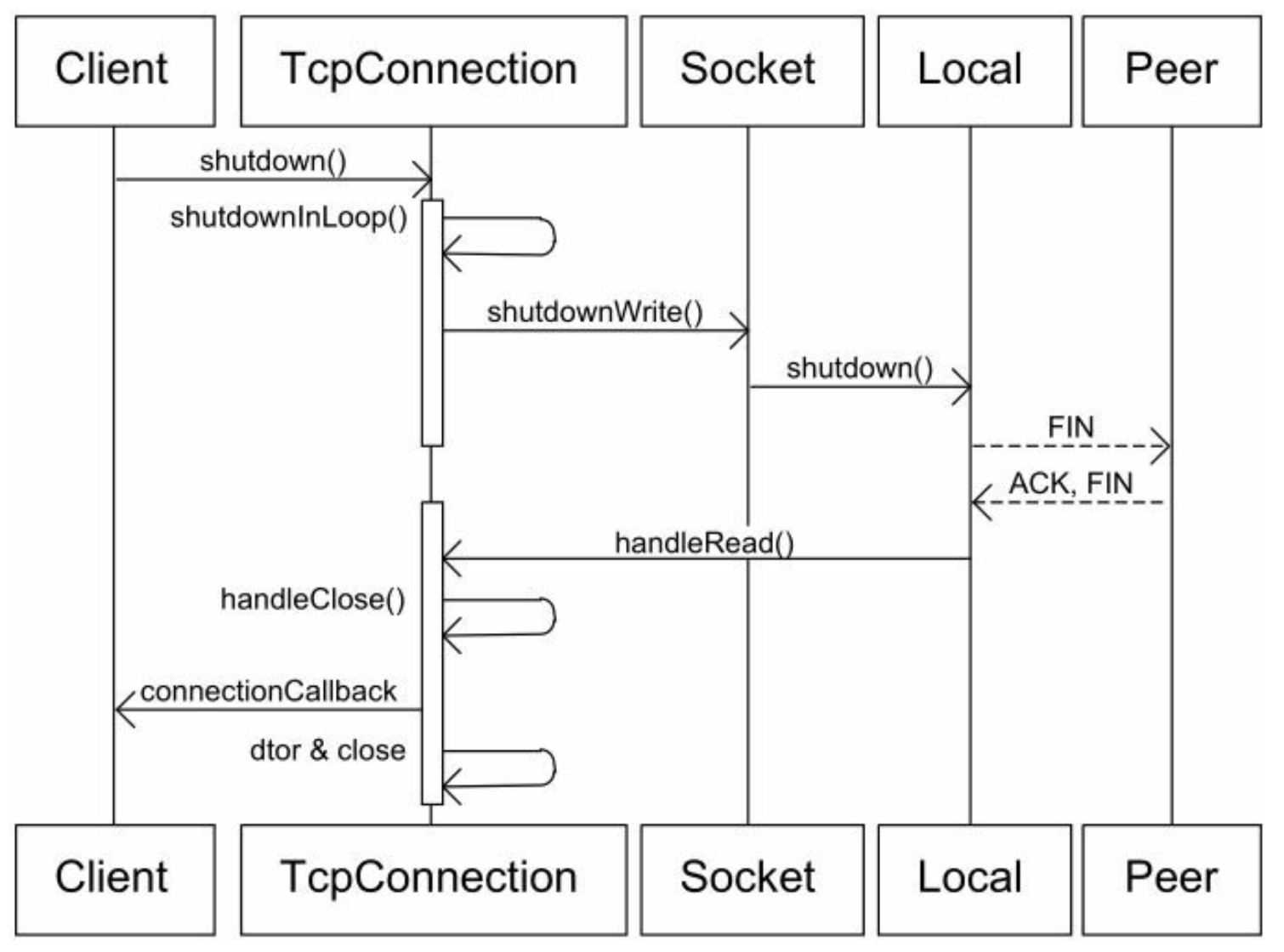
- TCP是一个全双工协议,同一个文件描述符即可读又可写,shutdownWrite()关闭了"写"方向的连接,保留了"读方向"的连接,这称为TCP半关闭(half-close).
- 如果直接close(socket_fd), 那么sock_fd就不能读或写了。
 .
.
- 如果直接close(socket_fd), 那么sock_fd就不能读或写了。
- 在TCP这种字节流协议上做应用层分包是网络编程的基本需求。
- 分包指的是在发生一个消息(message)或一帧(frame)数据时,通过一定的处理,让接收方能从字节流种识别并截取(还原)一个个消息。
- 对于短连接,只要发送方主动关闭连接,分包不是一个问题。
- 对于长连接,分包有四种方法:
- 消息长度固定。
- 使用特殊字符或者字符串作为消息的边界(如'\r\n')。
- 在每条消息的头部加一个长度字段(最常用的做法)。
- 利用消息本身的格式来分包(XML, JSON, 但歇息这种消息格式通常会用到状态机(state machine))。
- non-blocking(非阻塞)IO的核心思想是避免阻塞在read()或write()或其他IO调用上,这样可以最大限度地复用thread-of-control, 让一个线程能服务于多个socket连接。
- IO线程只阻塞在IO multiplexing(复用)函数上(如select/poll/epoll_wait等)。
- muduo库采用的是水平触发(level trigger), 而不是边沿触发(edge trigger)。
- 为了与传统的poll兼容,在文件描述符较少,活动文件描述符比例较高时,epoll不见得比poll更高效。
- 必要时可以在进程中切换Poller.
- 水平触发(level trigger)编程更加容易,不可能发生漏掉事件的bug.
- 读写的时候不必等候出现EAGAIN, 可以节省系统调用次数,降低延迟。
- muduo所有的IO都是带有缓冲的IO(buffered IO)。
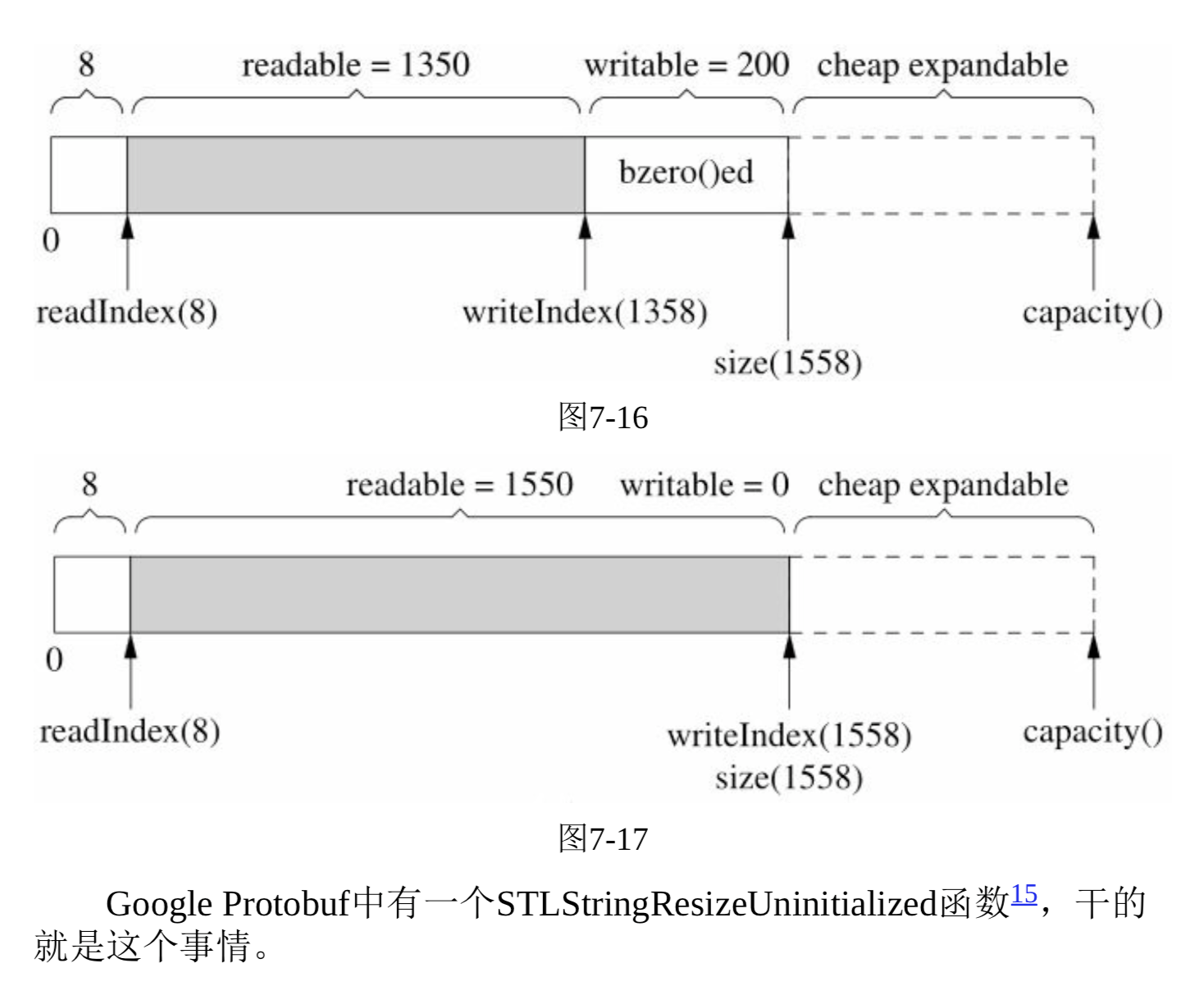
- 在栈上准备一个65536字节的额外缓存(extrabuf), 利用readv来读取数据,iovec有两块,第一块指向muduo的Buffer中的可写字节,另一块指向extrabuf。
- 数据不多,直接存到Buffer中,如果较多,剩余的放到extrabuf中进行缓存,然后再存到Buffer中。
- 在栈上准备一个65536字节的额外缓存(extrabuf), 利用readv来读取数据,iovec有两块,第一块指向muduo的Buffer中的可写字节,另一块指向extrabuf。
- send()是线程安全原子的,多个线程可以同时调用send(),消息之间不会混叠或交织。
- FILE是一个在stdio.h中预先定义的一个文件类型.
typedef struct{
short level; /*缓冲区“满/空”的程度*/
unsigned flags; /*文件状态标志字*/
char fd;
unsigned char hold;
short bsize; /*缓冲区大小*/
unsigned char *buffer; /*数据缓冲区的位置*/
unsigned char *curp; /*当前读写位置指针*/
unsigned istemp;
short token;
}FILE;
- boost::any可以表示任意类型,所以boost::any用不了多态的特性。
- pintf()函数是线程安全的,但std::cout<<不是线程安全的。
- 解析数据往往比生成数据更加复杂。
- 非阻塞读(nonblocking read)必须和input buffer一起使用,在接收方(decoder)一定要在收到完整的消息之后再retrieve(取出)整条消息。
- Buffer其实就像是一个队列(queue), 从末尾写入数据,从头部读出数据。
- Buffer内部是一个std::vector,它是一块连续的内存,参考netty的ChannelBuffer(prependable是微创新)。
- 如果readIndex太靠右,就不会重新分配内存,而是把已有数据移动到前面,腾出writable空间。
- 前方添加(prepend):提供prependable空间,让程序能够以很低的代价在数据前面添加杰哥字节。
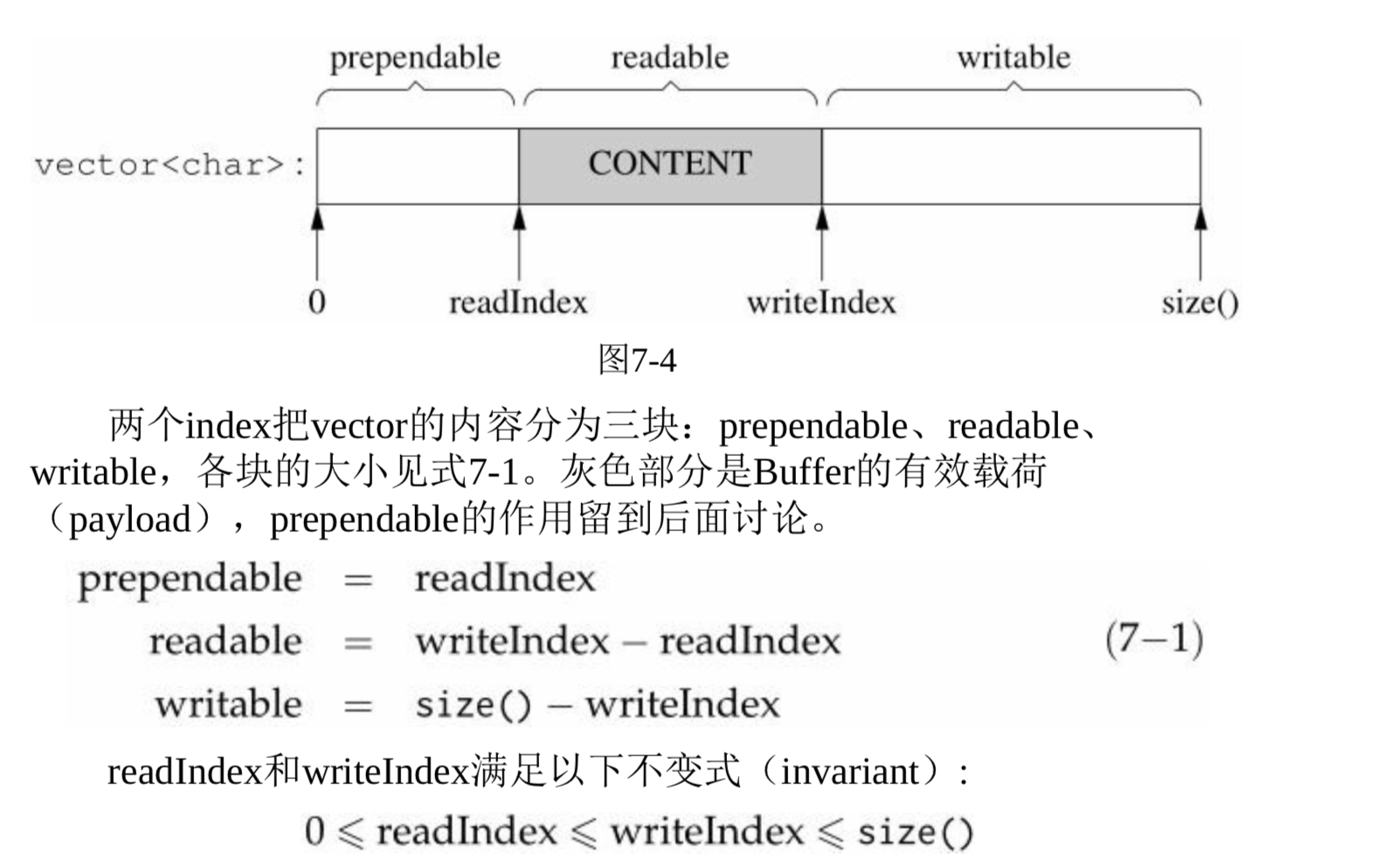
- muduo Buffer不是固定长度的,它可以自动增长(使用vector的好处)。
- readIndex和writeIndex是整数(因为指针的话,在新建数组时会失效)。
- Buffer没有自动shink, 数组只会越来越大。
- libevent 2.0.x的设计方案:
- 实现分段连续的zero copy buffer再配合gather scatter IO(mbuf方案, Linux的sk_buff方案),基本思路是不要求数据在内存中是连续的,而是用链表把数据连接到一起。
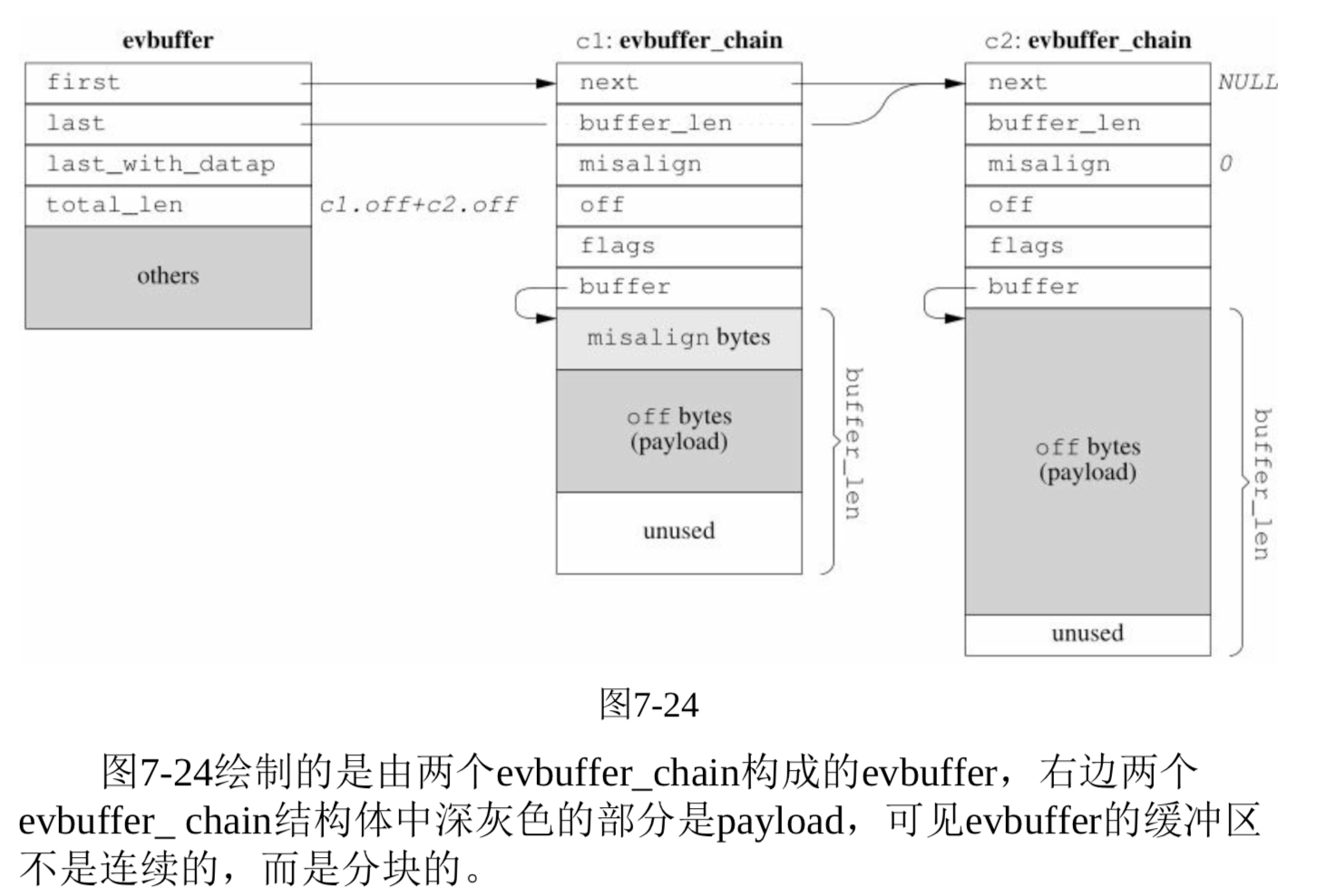
- 实现分段连续的zero copy buffer再配合gather scatter IO(mbuf方案, Linux的sk_buff方案),基本思路是不要求数据在内存中是连续的,而是用链表把数据连接到一起。
- muduo的设计目标之一是吞吐量能让千兆以太网饱和,每秒收发120MB的数据。
- Buffer内部是一个std::vector,它是一块连续的内存,参考netty的ChannelBuffer(prependable是微创新)。
一种自动反射消息类型的Google Protobuf网络传输方案
- Google Protocol Buffers(简称Protobuf)是一款非常优秀的库,它定义了一种紧凑的可扩展二进制消息格式,特别适合网络数据传输。
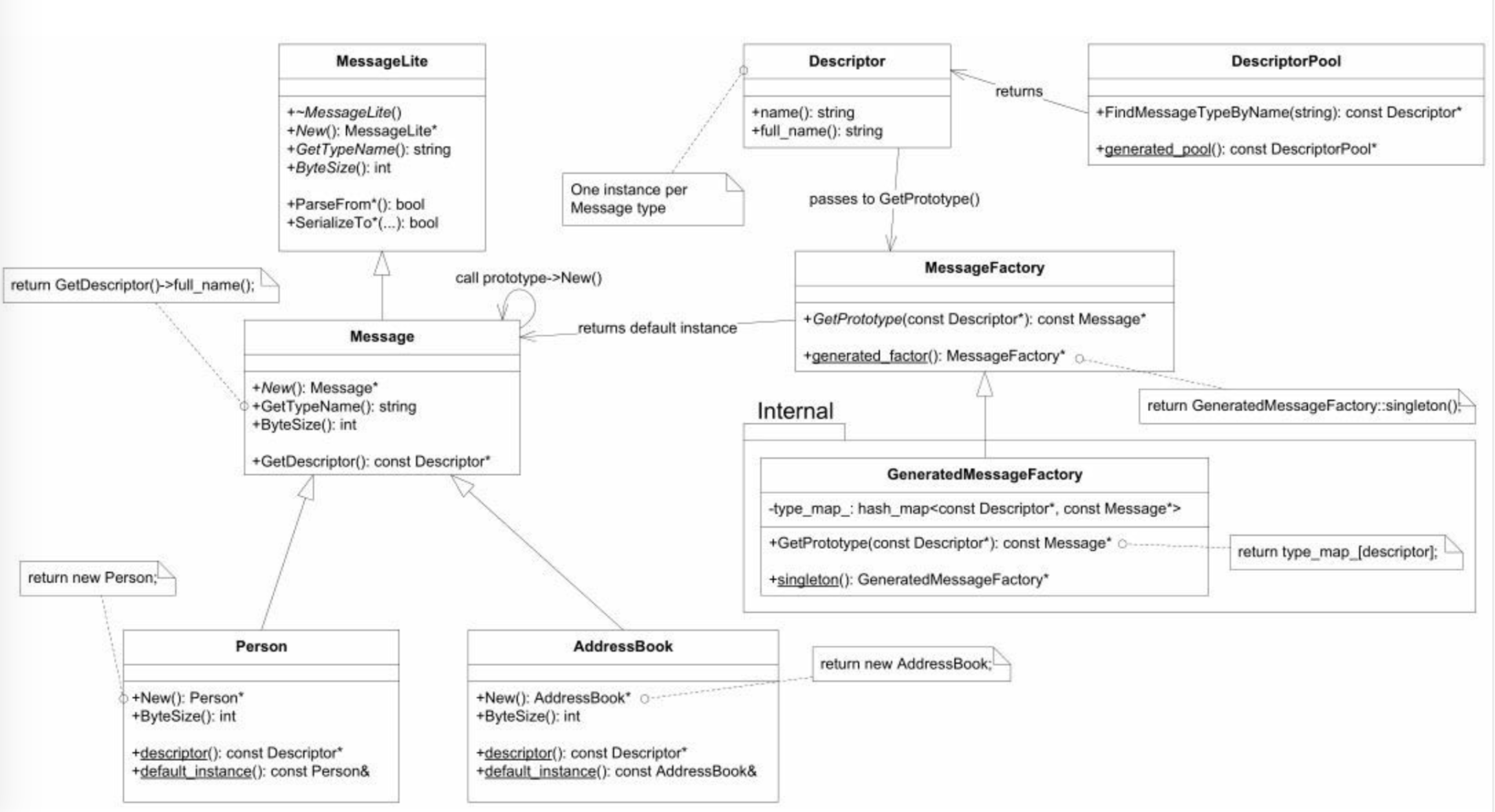
- 拿到Message*指针,不用知道它的具体类型,就能创建和其他类型一样的具体Message type的对象。
- 通过DescriptorPool可以根据type name查到Descriptor*, 再调用DescriptorPool::findMessageTypeByName(const string& type_name)即可。
- 使用步骤:
- 用DescriptorPool::generated_pool()找到一个DescriptorPool对象(它包含了编译时所连接的全部Protobuf Message types).
- 根据type name用DescriptorPool::FindMessageTypeByName()查找Descriptor.
- 再用MessageFactory::generated_factory()找到MessageFactory对象,它能创建程序编译的时候所链接的全部Protobuf Message types.
- 然后用MessageFactory::GetPrototype()找到具体Message type的default instance(默认实例)。
- 最后用prototype->New()创建对象。
- 返回的是动态对象,调用方需要释放它,可以使用智能指针管理资源。(消息分发器dispatcher)
- 返回的是动态对象,调用方需要释放它,可以使用智能指针管理资源。(消息分发器dispatcher)
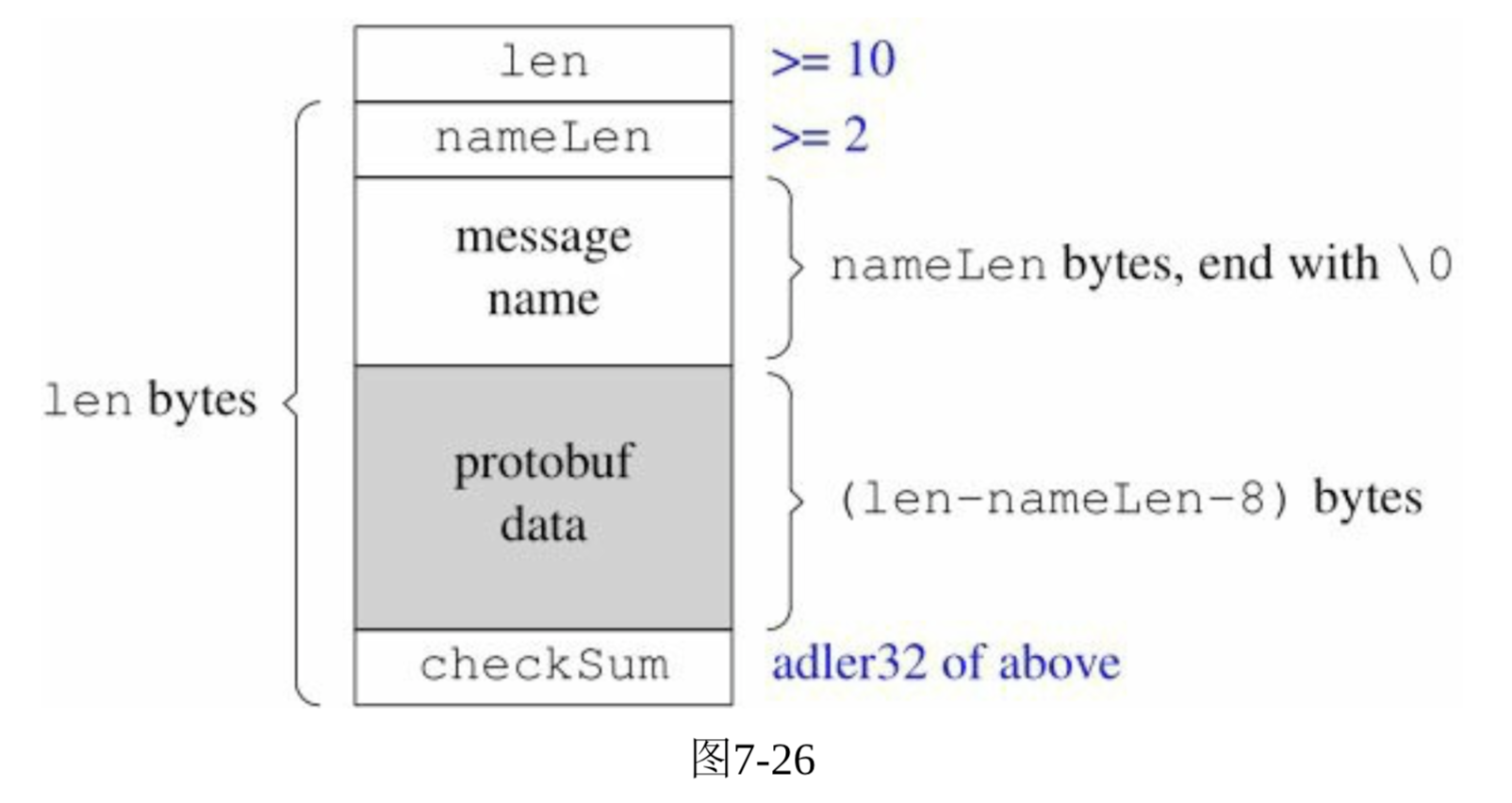
- java没有unsigned类型。protobuf一般用于打包小于1MB的数据。
- adler32校验算法,计算量小,速度比较快,强度和CRC-32差不多。
- Protobuf Message的一个突出有点是用optional fields来避免协议的版本号.
- 只有再使用TCP长连接,并且在一个连接上传递不知一种消息的情况下,才需要打包方案。(还需要一个分发器,把不同类型的消息分给各个消息小狐狸函数)。
- non-trivial的网络服务常旭通常会以消息为单位来通信,每条消息有明确的长度与界限。
- codec(编解码器)的基本功能是TCP分包: 确定每条消息的长度,为消息划分界限。
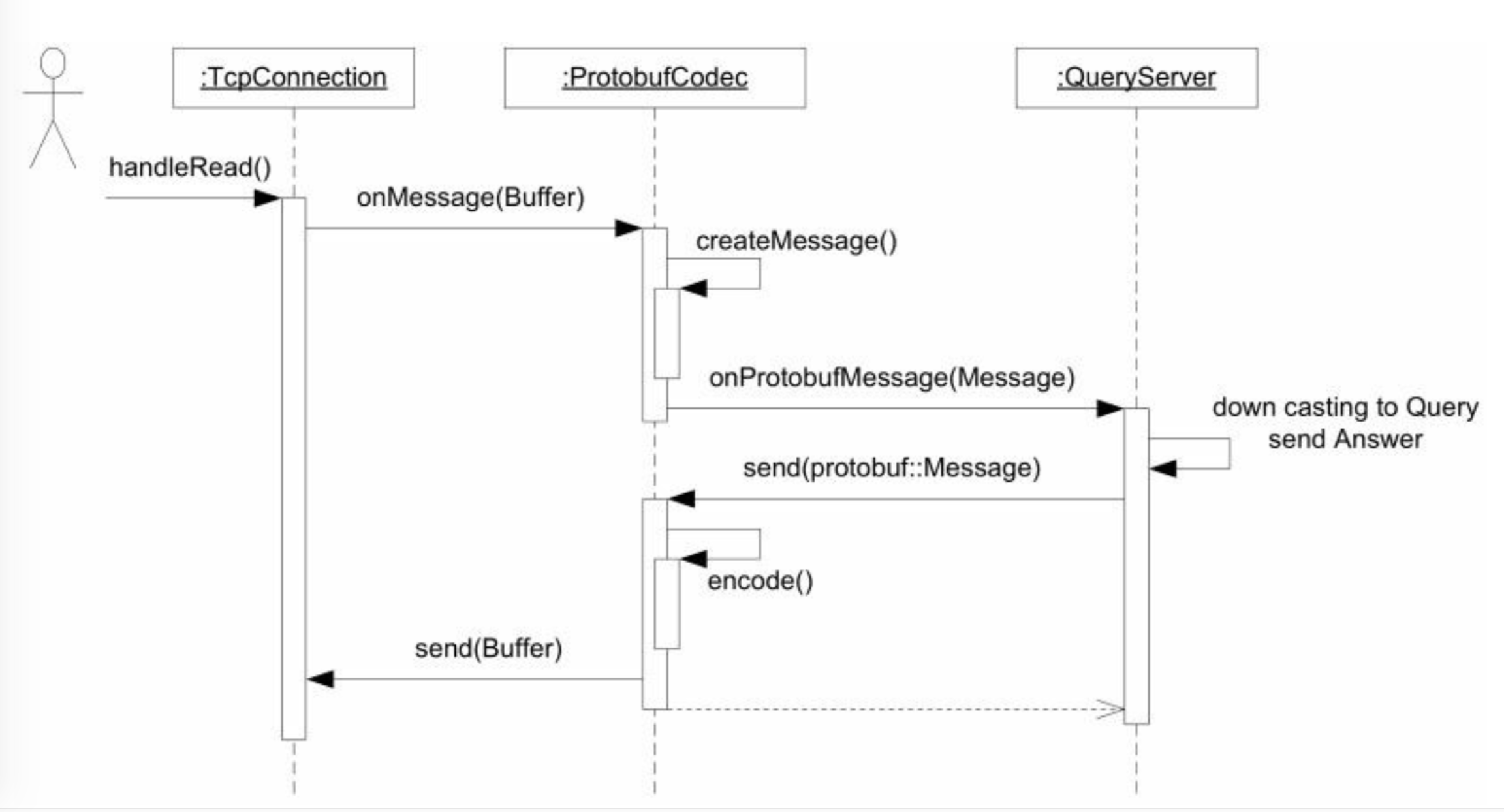
- Protobuf RPC.
- codec(编解码器)的基本功能是TCP分包: 确定每条消息的长度,为消息划分界限。
- ProtobufCodec拦截了TcpConnection的数据,把它转换为Message, ProtobufDispatcher拦截了ProtobufCodec的回调函数(callback). 按照消息具体类型把它分派给多个callbacks.
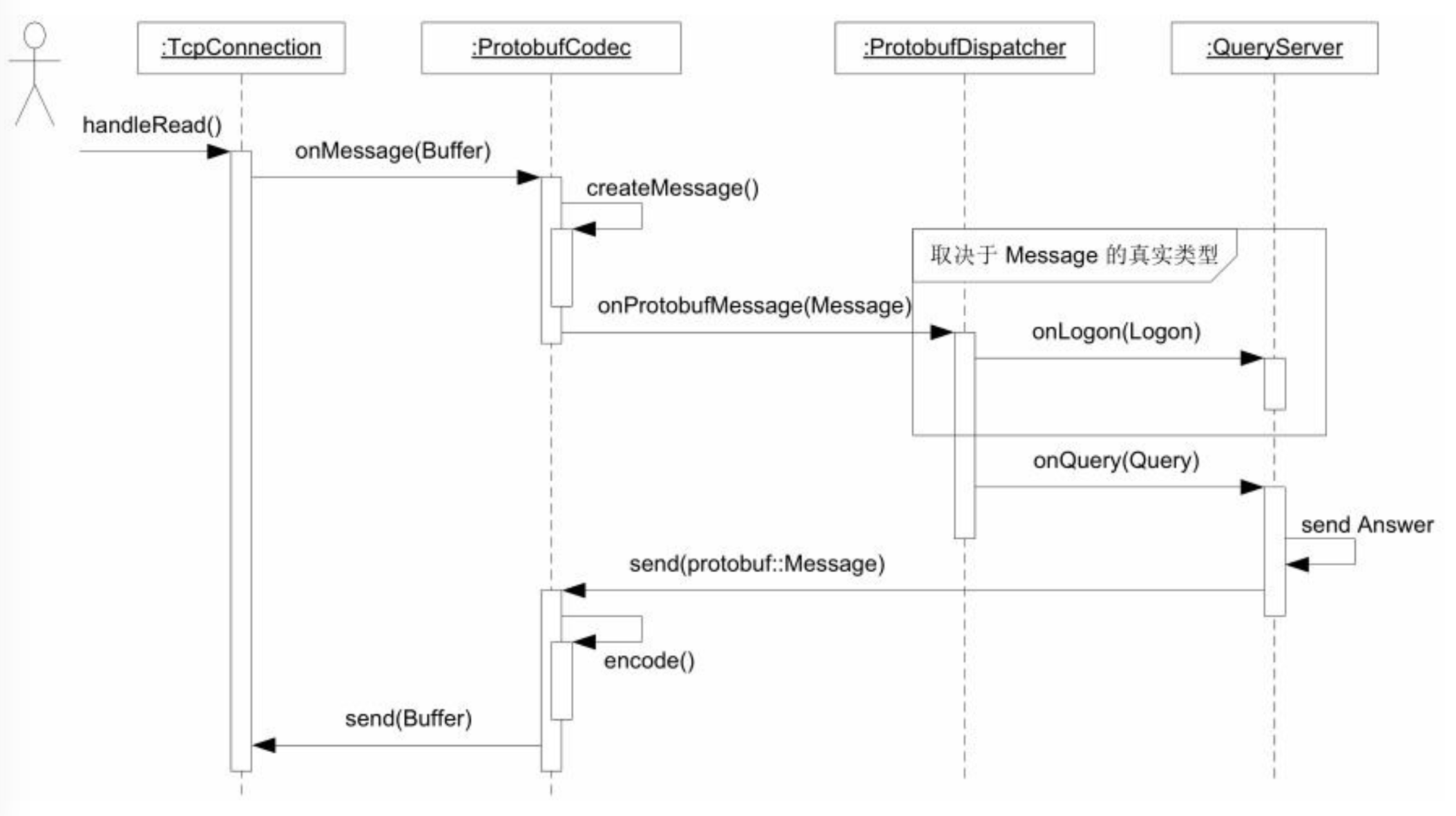
- filedescriptor是稀缺资源,如果出现文件描述符(filedescriptor)耗尽,很棘手。
- 处理空闲连接超时: 如果一个长连接长时间(若干秒)没有输入数据,就踢掉此连接。--- 用timing wheel解决。
- 定时器(时间):
- 计时只使用gettimeofday(2)来获取当前时间。 --- 精度为1微妙。
- 定时只使用timerfd_*系列函数来处理定时任务。
- Netty是一个非常好的Java NIO网络库,带有流量统计功能的echo和discard服务端。
- 两台机器的网络延迟和时间差(简单网络程序roundtrip).
- NTP协议进行时间校准。
- 应该用心跳消息来判断对方进程是否能正常工作,timing wheel(时间轮盘)避免空闲连接占用资源。
- timing wheel只用检查第一个桶中的连接。
- 层次化的timing wheel与hash timing wheel.
- timing wheel中的每个格子是hash set,可以容纳不止一个连接。
- 不会真的把一个连接从一个格子移动到另一个格子,而是采用引用计数的办法,用shared_ptr来管理Entry.
- 如果连接接收到了数据,就把对应的EntryPtr放到这个格子里,引用计数为零,那么就析构掉(断开连接)。
- 简单的消息广播服务:
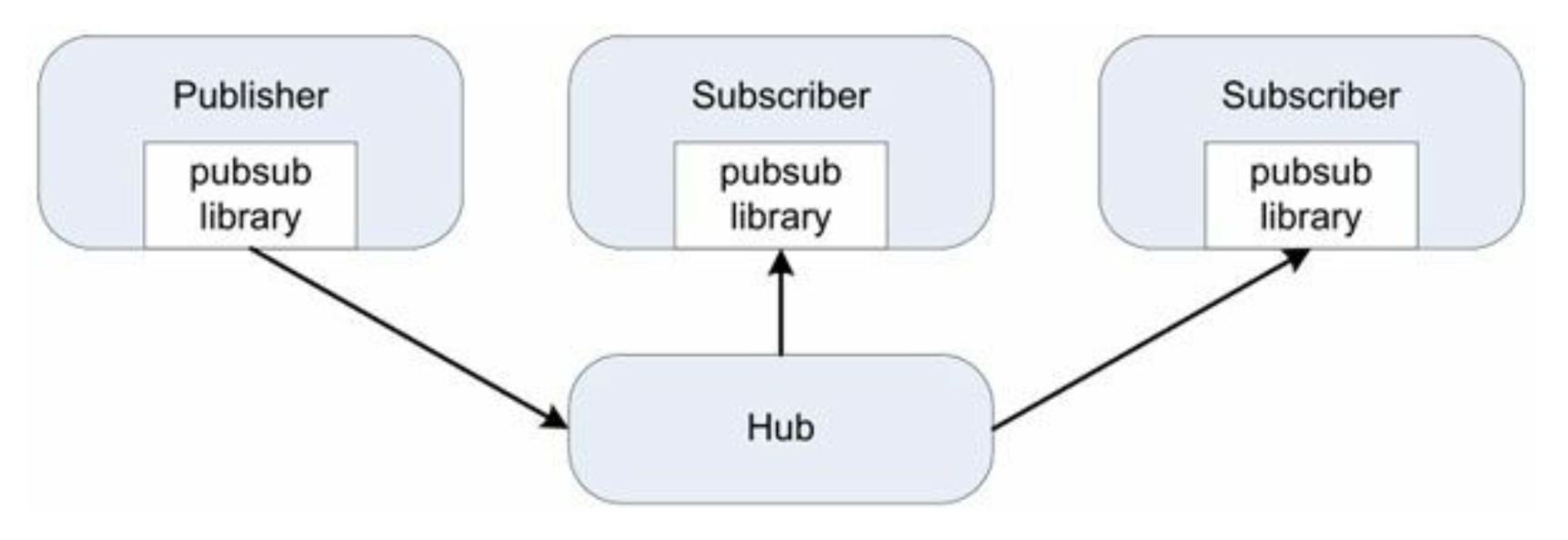
- 可以增加多个Subscriber而不用修改Subscriber(分布式的观察者模式Observer pattern).
- 应用层广播在分布式系统中用处很大。 --- 消息应该是snapshot, 而不是delta(现在比分是几比几,而不是谁刚才又得分了)。
·sub<topic>\r\n, 表示订阅, 以后该topic有任何更新都会发给这个TCP连接。- Hub会把上最近的消息发给此Subscriber.
unsub<topic>\r\n, 表示退订.pub<topic>\r\n<content>\r\n, 表示往发送消息,内容为.- 利用thread local的办法解决多线程广播的锁竞争。
- 数据串并转换:
- 连接服务器把多个客户连接汇聚为一个内部TCP连接,起到数据串并转换的作用,后端(backend)的逻辑服务器专心处理业务。
- 分为四步:
- 当client connection到达或断开时,向backend发出通知。
- 当从client connection收到数据时,把数据连同connection id一同发给backend.
- 当从backend connection收到数据时,辨别数据是发给那个client connection,并执行相应的转发操作.
- 如果backend connection断开连接,则断开所有client connections(假设client会自动重试).
- multiplexer的功能与proxy颇为相似。
- 中继器(relay)主要把client与Server之间的通信内容记录下来(tcpdump的功能)。
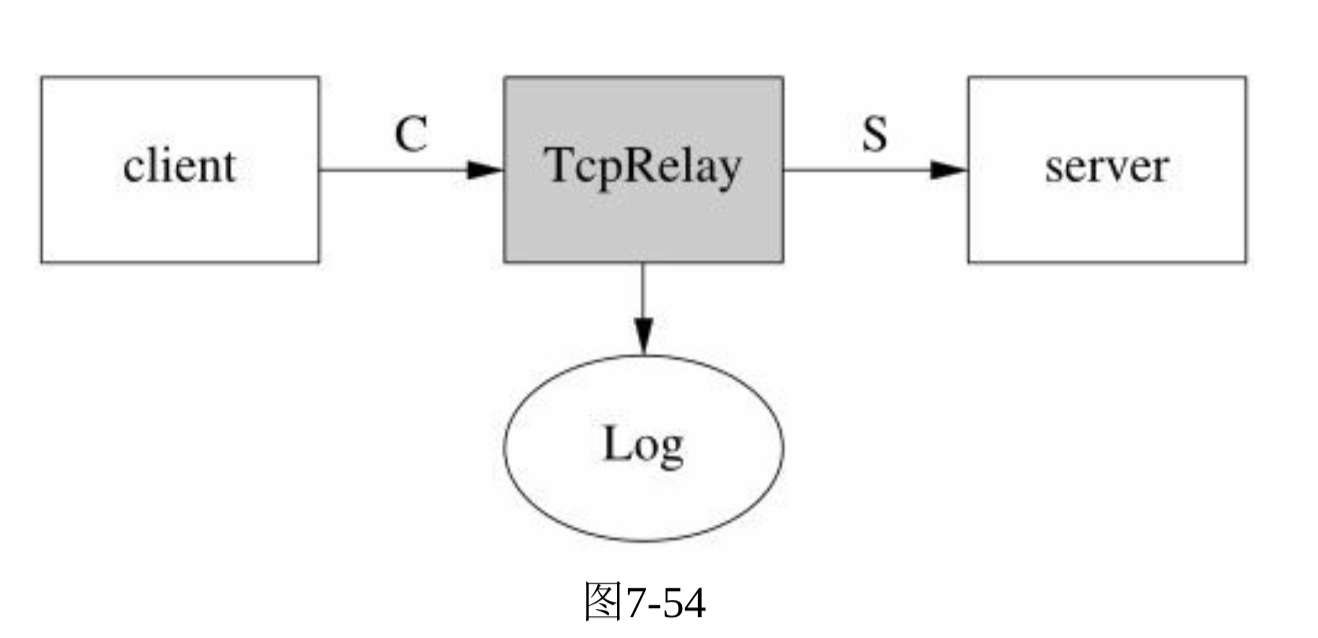
- Sockets API来实现TcpRelay,需要splice系统调用。
- 需要考虑的问题:

短址服务
muduo HTTP服务器可以处理简单的HTTP请求,也可以用来实现一个简单的短URL转发服务。
一种真正高效的优化手段是修改Linux内核,例如Google的SO_REUSEPORT内核补丁。
muduo的Channel class类,可以把其他一些现成的网络库融入muduo的event loop中。
- Channel class是IO事件回调的分发器(dispatcher), 它在handleEvent()中根据事件的具体类型分别回调ReadCallback, WriteCallback等。
- 每个Channel对象服务于一个文件描述符,但并不拥有fd, 在析构函数中也不会close(fd).
- Channel与EventLoop的内部交互有两个函数:
- EventLoop::updateChannel(Channel*);
- EventLoop::removeChannel(Channel*).
- 客户需要在Channel析构前自己调用Channel::remove().
libcurl是一个常用的HTTP客户端库,可以方便地下载HTTP和HTTPS数据。
muduo提供Channel::tie(const boost::shared_ptr&)这个函数,用于延长某些对象的生命期,使其寿命长过Channel::handleEvent()函数。
POSIX操作系统总是选用当前最小可用的文件描述符。
muduo库设计与实现
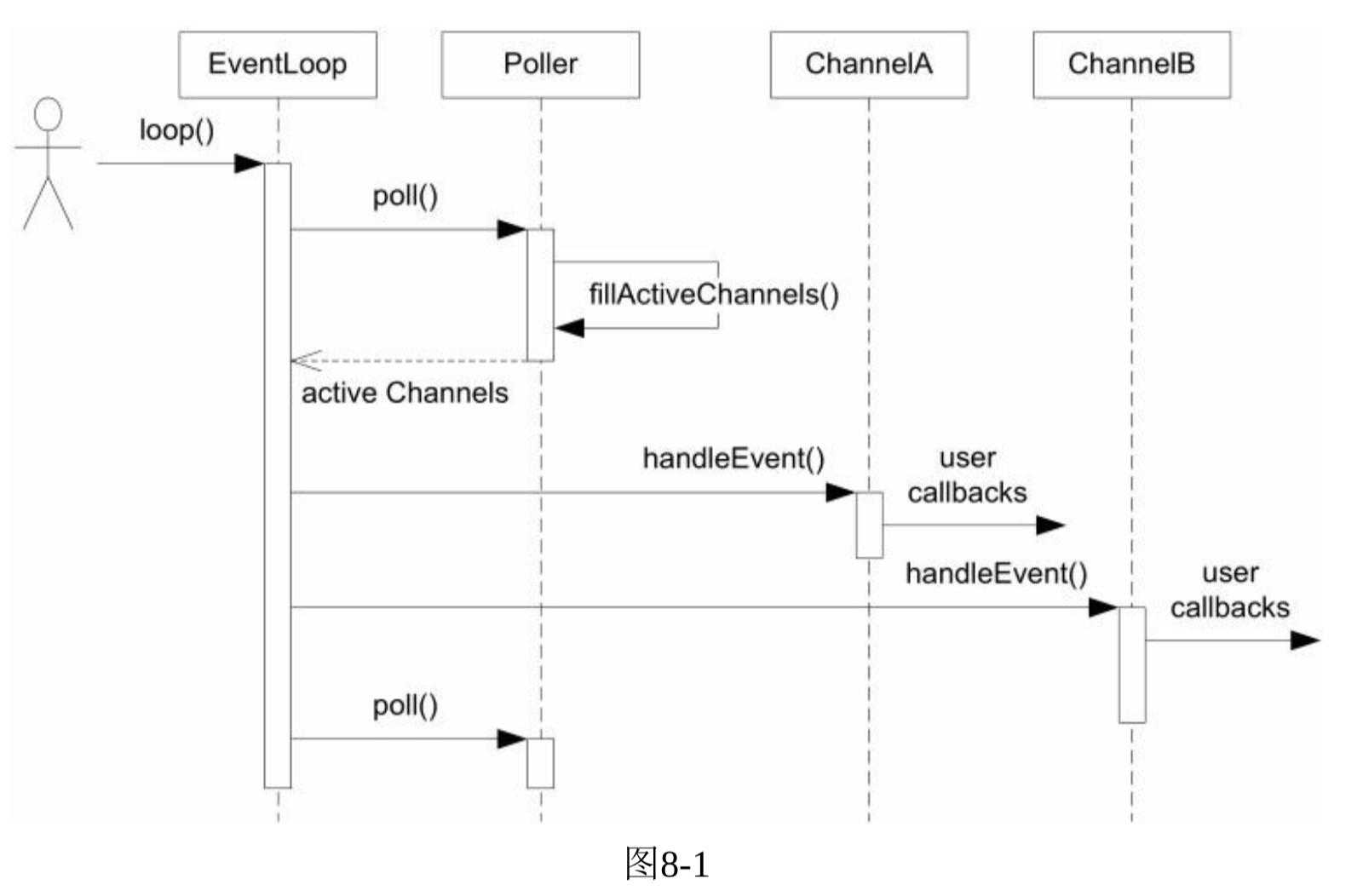
- EventLoop的析构函数会记住本对象所属的线程(threadId_), 创建了EventLoop的线程是IO线程。
- 其主要同能时运行事件循环EventLoop::loop().
- EventLoop对象的生命期通常和其所属的线程一样长,不必是heap对象。
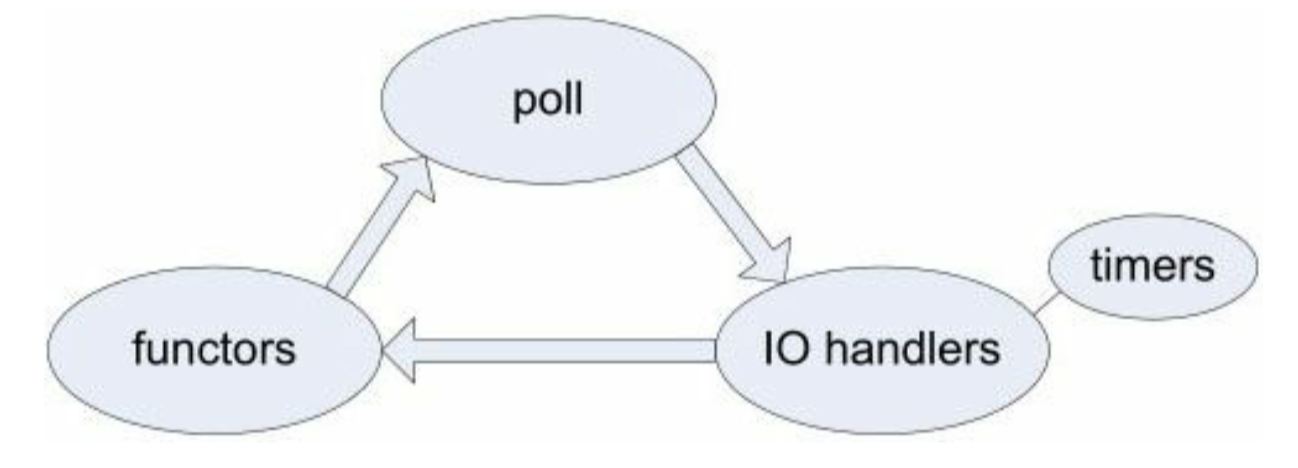
- Reactor的关键结构: Reactor 最核心的事件分发机制,即将IO multiplexing拿到的IO事件分发给各个文件描述符(fd)的事件处理函数。
- Channel的成员函数都只能在IO线程调用,因此更新数据成员都不必加锁。
- TcpConnection简单的状态图:
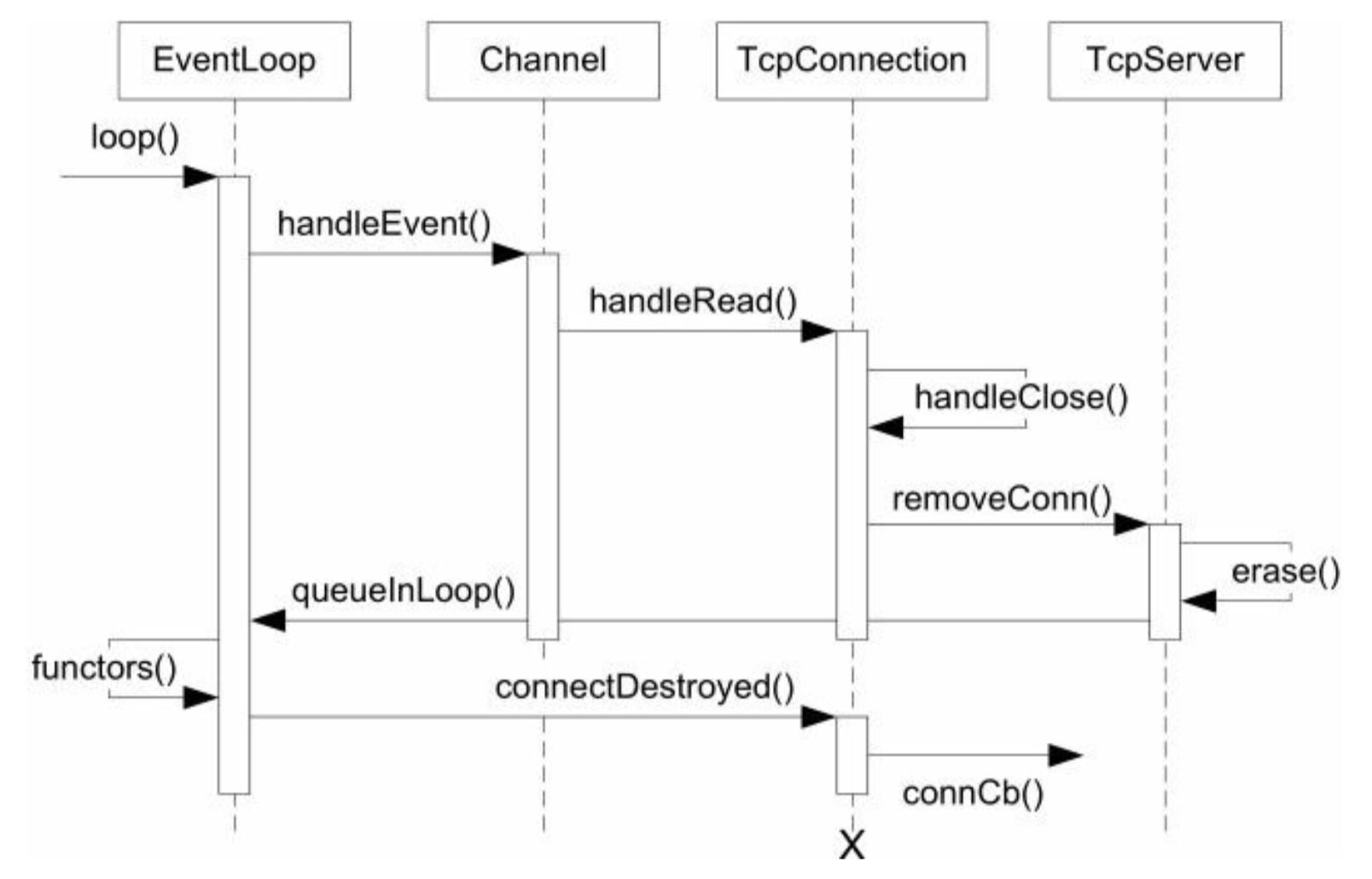
- SIGPIPE的默认行为时终止进程,在网络编程中,意味着如果对方断开连接而本地继续写入的话,会造成服务进程意外退出。
- TCPNoDelay和TCPkeepalive都是常用的TCP选项:
- TCPNoDelay的作用是禁用Nagle算法,避免连续发包出现延迟,对编写低延迟网络服务很重要。
- TCPkeepalive是定期检查TCP连接是否还存在,如果有应用层心跳,TCPkeepalive不是必须的,但一般需要暴露其接口。
- 用one loop per thread的思想多线程TcpServer的关键步骤是在新建TcpConnection时从event loop pool里挑选一个loop给TcpConnection用.
- 在并发连接较大而活动连接比例不高时, epoll比poll更有效.
- 右值引用(rvalue reference)有助于提高性能与资源管理的便利性。
分布式系统工程实践
- 分布式系统设计以进程为基本单位.
- 不要把时间浪费在解决错误的问题,应集中精力应付更本质的业务问题。
- 只用TCP为进程间通信,因为进程一退出,连接与端口自动关闭;而且无论连接的哪一方断连,都可以重建TCP连接,恢复通信。
- 分布式系统中心跳协议的设计:
- 心跳除了说明应用程序还活着(进程还在,网络畅通), 更重要的是表明应用程序还能正常工作。
- TCP keepalive由操作系统负责探查,即便进程死锁或阻塞,操作系统也会如常收发TCP keepalive消息。对方无法得知这一异常。
- 一般是服务端向客户端发送心跳。
- Sender和Receiver的计时器是独立的。
- 心跳协议的内在矛盾: 高置信度与低反应时间不可兼得。
- timeout的选择要能容忍网络消息延时波动和定时器的波动。
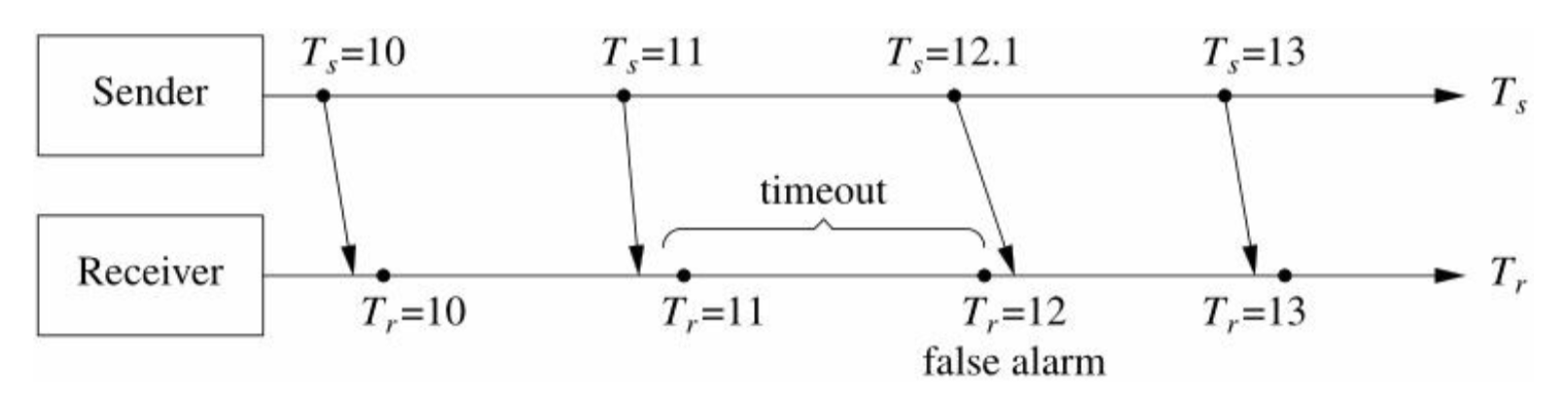
- 发送周期和检查周期均为\(T{_C}\), 通常可取\(timeout=2T{_C}\).
- 心跳应该包含发送方的标识符,也应包含当前负载,便于客户端做负载均衡。
- 考虑闰秒的影响,尤其在考虑容错协议的时候。
- 心跳协议的实现上有两个关键的点(防止伪心跳):
- 要在工作线程中发送,不要单独起一个心跳线程。
- 与业务消息用同一个连接,不要单独用心跳连接。
- 分布式系统没有全局瞬时的状态,不存在立刻判断对方故障的方法,这是分布式系统的本质困难。
- 端口只有6万多个,是稀缺资源,在公司内部也有分配完的一天,一般到高级阶段会采用动态分配端口号。
- 如果客户端与服务端之间用某种消息中间件来回转发消息,那么客户端必须通过进程标识符才能识别服务端。
- 设置SO_REUSEADDR, 为了快速重启。
- linux的pid的最大默认值是32768。
- 用四元组ip::port::tart_time::pid作为分布式系统中进程的gpid, 其中start_time是64-bit整数,表示进程的启动时刻(UTC时区)。
- 在服务程序内置监控接口的必要性;HTTP协议的便利性。
- Hadoop有四种主要services:NameNode,DataNode, JobTracker和TaskTracker.
- 每种service都内置了HTTP状态页面。
- 在自己辩词额分布式程序的时候,提供一个维修通道是很有必要的,它能帮助日常运维,而且在出现故障的时候帮助排查。
- 如果不在程序开发的时候统一预留一些维修通道,那么运维起来就抓瞎了 --- 每个进程都是黑盒子,出点什么情况都得拼命查log试图(猜想)进程的状态,工作效率不高。
- 使用跨语言的可扩展消息格式。
- 可扩展消息格式的第一条原则是避免协议的版本号。
- protobuf的可选字段(optional fields)就解决了服务端和客户端升级的难题。
- proto文件就像C/C++动态库的头文件,其中定义的消息就是库(分布式服务)的接口,一单发布就不能做有损二进制兼容性的修改。
- 分布式程序的自动化回归测试:
- 自动化测试的必要性:
- 自动化测试的作用是把程序已经事项的features以test case的形式固话下来,将来任何代码改动如果破坏了现有功能需求就会触发测试failure.
- 单元测试(unit testing): 主要测试一个函数、一个类(class)活着相关的几个class。
- 单元测试的缺点:
- 阻碍大型重构,单元测试是白盒测试,测试代码直接调用被测试代码,测试代码和被测试代码紧耦合。
- java有动态代理,还可以用cglib来操作字节码以实现注入。
- 网络连接不上,数据库超时,系统资源不足等都无法测试。
- 单元测试对多线程程序无能为力
- 单元测试的缺点:
- 分布式系统测试的要点:
- 测试进程间交互。
- 用脚本来模拟客户,自动化地测试系统的整体运作情况,作为系统的冒烟测试。
- 一个分布式系统就是一堆机器,每台机器的"屁股"上拖着两根线:电源线和网线(不考虑SAN等存储设备)。
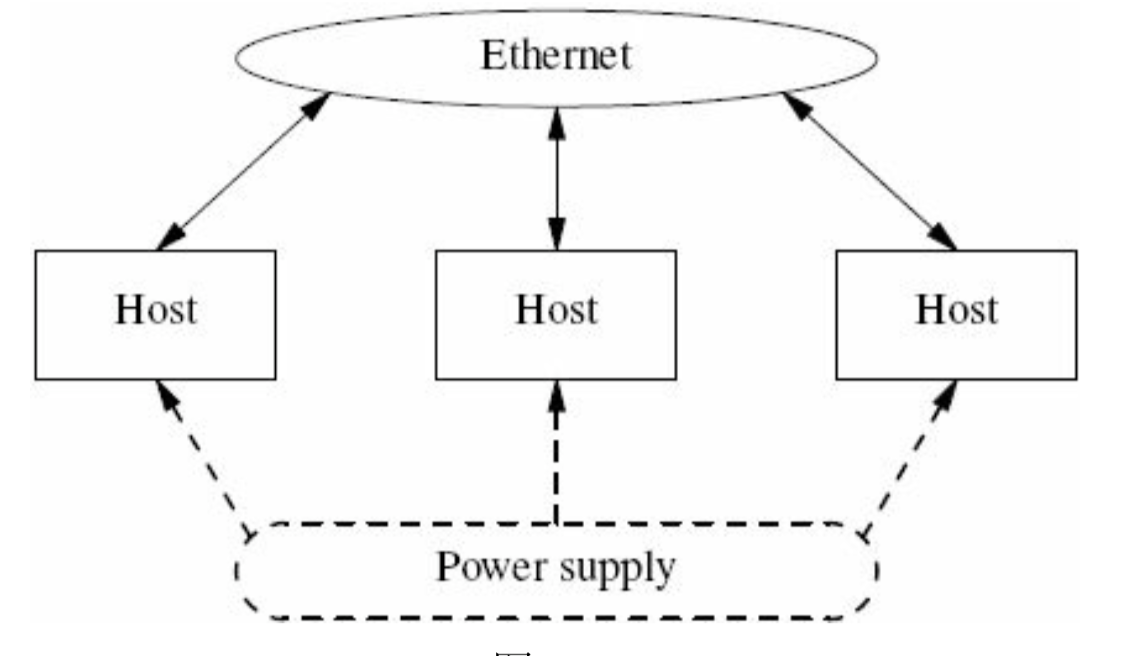
- 自动化测试的必要性:
- 千兆网的吞吐量不太于125MB/S. --- 只要能让千兆网的吞吐量饱和或接近饱和,那么编程语言就无所谓了。
- Hadoop的分布式文件系统HDFS的架构简图:
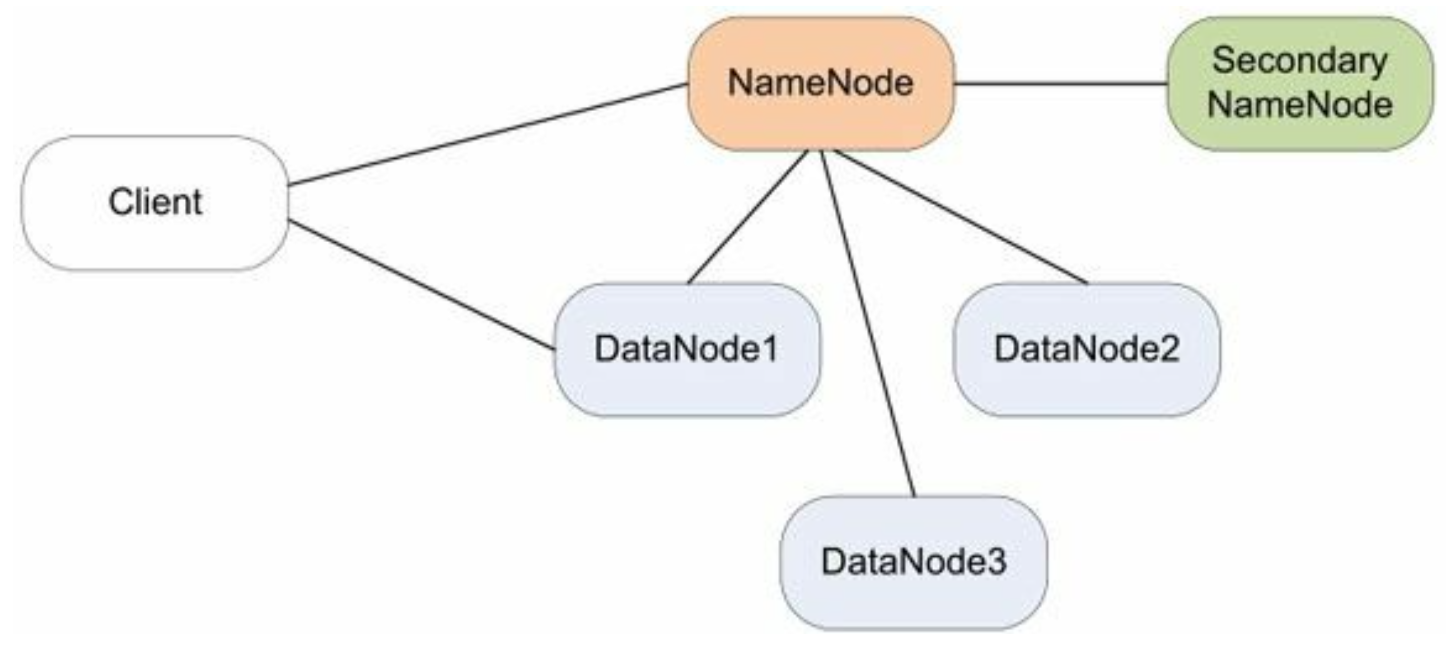
- HDFS有四个角色参与其中: NameNode(保存元数据)、DataNode(存储节点,多个)、Secondary NameNode(定期写check point)、Client(客户,系统的使用者)。
- 这些进程运行在多态机器上,之间通过TCP协议互联。但一个程序其实不知道与自己打交道的到底是什么。
- Test harness(独立的进程),模冒(mock)了与被测进程打交道的全部程序。
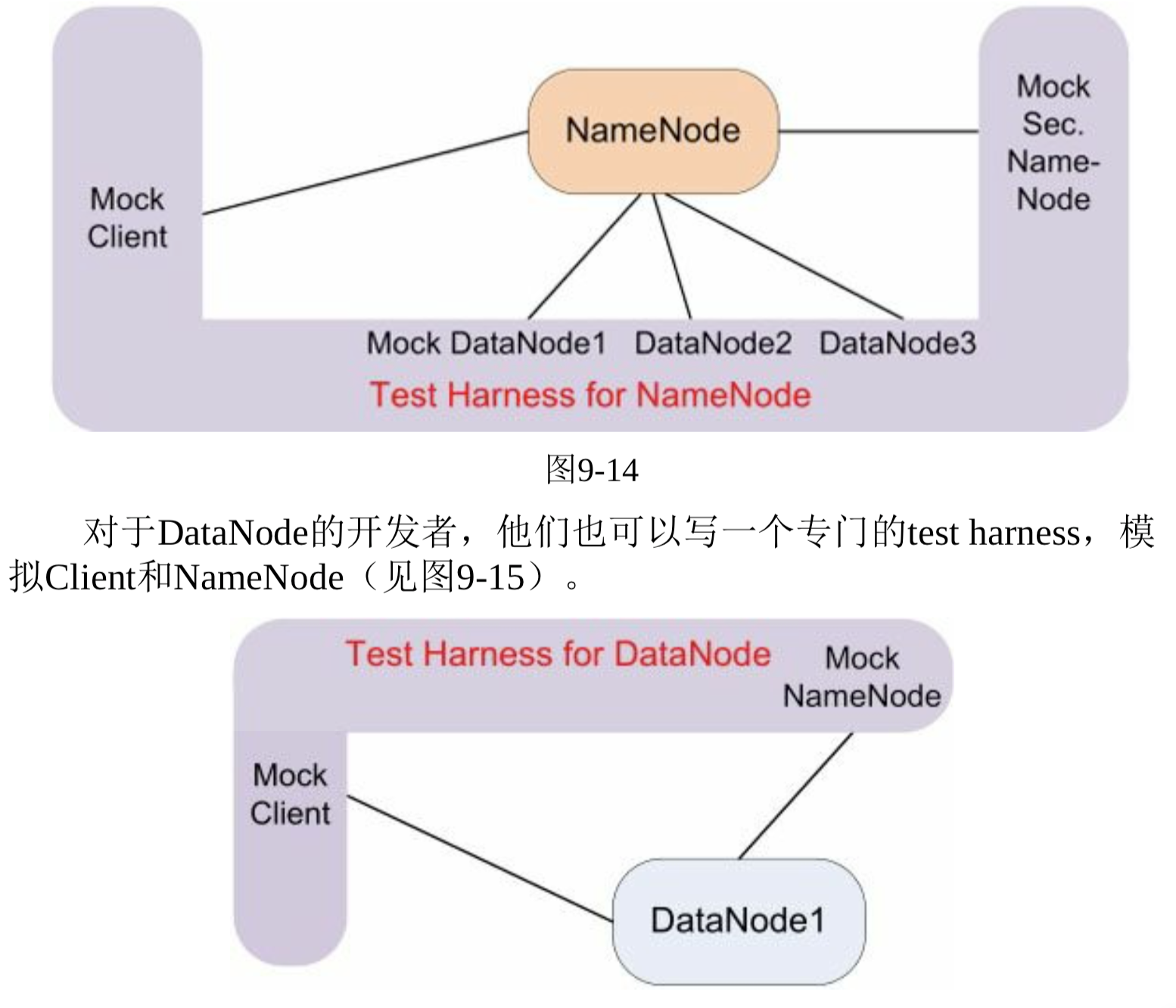
- 压力测试,test harness少加改进还可以变功能测试为压力测试, 公程序员profiling用。
- 发复不间断发送请求,向被测程序加压,用C++写一个负载生成器。
- 单独的进程作为test harness对于开发分布式程序相当有帮助,它能达到单元测试的自动化程度和细致程度,又避免了单元测试对功能代码结构的侵入与依赖。
分布式系统部署、监控与进程管理的几重境界
- 以Host指代服务器硬件。
- 境界1: 全手工操作,过家家级别,系统时灵时不灵,可以跑跑测试,发发parper.
- 境界2: 使用零散的自动化脚本和第三方组件
- 公司的开发中心放在实现核心业务,天健新功能方面,暂时还顾不上高效的运维。
- host的IP地址由DHCP配置,公司的软硬件配置比较统一。
- 使用cron、at、logrotate、rrdtool等标准的Linux工具来将部分运维任务自动化.
- QA签署后部署(md5), md5sum检查拷贝之后的文件是否与源文件相同。
- Monit开源工具进行监控(内存、CPU、磁盘空间、网络带宽等)。
netstart-tpn | grep port(端口号)查询哪些用到了程序。
- 境界3: 自制机制管理系统,几种化配置
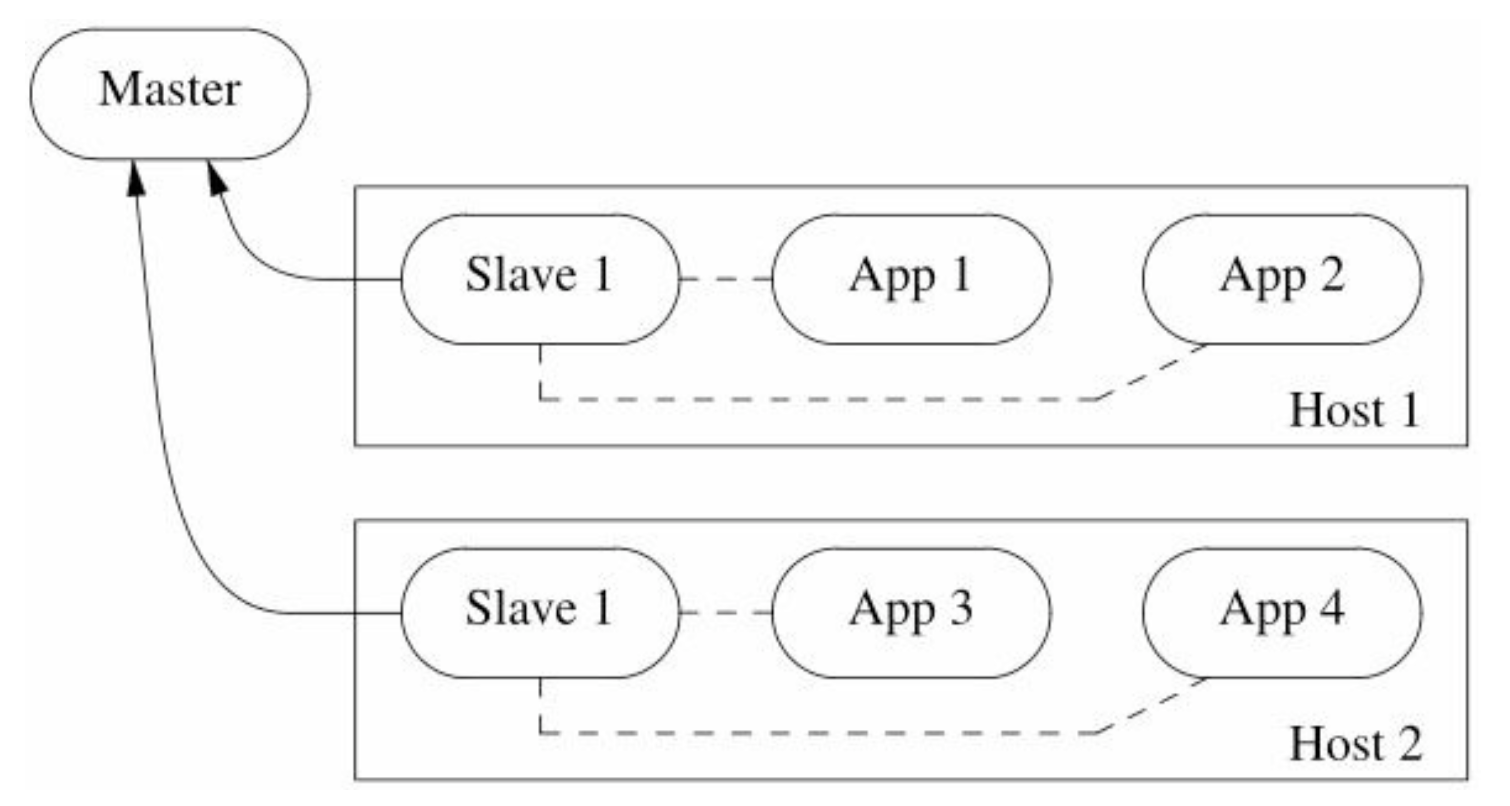
- 境界4: 机群管理与nameing service结合:
- naming service的功能是把一个service_name解析成list of ip:port,比方说,查询"sudo_solver",返回host1:9981、host2:9981、host3:9981.
- naming_servive与DNS最大的不同在于它能把新的地址信息推送给客户端。
- gethostbyname()和getaddrinfo()解析DNS是阻塞的(除非使用UDNS等异步DNS库),在大规模分布式系统中DNS的作用不大,宁愿花时间实现一个naming service,并为它编写name resolve library.
C++编译链接模型精要
- C++语言的三大约束: 与C兼容、零开销(zero overhead)原则、值语义。
- 查看编译时打开的文件命令:
strace -f -e open cpp hello.cc -o /dev/null 2>&1 |grep -v ENONT|awk {'print $3'} - C++也继承了单遍编译的约束,Java编译器不受单遍编译的约束,调整成员函数的顺序不会影响代码语义。
- 按照C++模板的局限话规则,编译期会为每一个用到的类模板成员函数具现化一份实例。
- 在现在的C++实现中,虚函数的动态调用(动态绑定、运行期决议)是通过虚函数表(vtable)进行的,每个多态class都应该有一根vtable.
- 定义或继承了虚函数的对象中会有一个隐含成员:指向vtable的指针,即vptr。
- 在构造和析构对象的时候,编译期生成的代码会修改这个vptr成员,这就要用到vtable的定义(使用其地址)。
- 源码编译才是王道。
- 实用当头,朴实为贵,好用才是王道。
- 避免使用虚函数作为库的接口。
- 以boost::function和boost::bind取代虚函数。
Linux多线程服务器端编程的更多相关文章
- [转载]赖勇浩:推荐《Linux 多线程服务器端编程》
推荐<Linux 多线程服务器端编程> 赖勇浩(http://laiyonghao.com) 最近,有一位朋友因为工作需要,需要从网游的客户端编程转向服务器端编程,找我推荐一本书.我推荐了 ...
- 推荐《Linux 多线程服务器端编程》
赖勇浩(http://laiyonghao.com) 最近,有一位朋友因为工作需要,需要从网游的客户端编程转向服务器端编程,找我推荐一本书.我推荐了<Linux 多线程服务器端编程——使用 mu ...
- 《Linux多线程服务器端编程》读书笔记第3章
<Linux多线程服务器端编程>第3章主要讲的是多线程服务器的适用场合与常用的编程模型. 1.进程和线程 一个进程是"内存中正在运行的程序“.每个进程都有自己独立的地址空间(ad ...
- linux多线程socket编程一些心得
http://hi.baidu.com/netpet/blog/item/2cc79216d9012b54f2de32b9.html 前段时间将新的web模型办到linux上来,用epoll代替了IO ...
- linux c++ 服务器端开发面试必看书籍
摘自别人博客,地址:http://blog.csdn.net/qianggezhishen/article/details/45951095 打算从这开始一本一本开始看 题外话: 推荐一个 githu ...
- 【linux草鞋应用编程系列】_4_ 应用程序多线程
一.应用程序多线程 当一个计算机上具有多个CPU核心的时候,每个CPU核心都可以执行代码,此时如果使用单线程,那么这个线程只能在一个 CPU上运行,那么其他的CPU核心就处于空闲状态,浪费了系 ...
- Linux多线程服务端编程一些总结
能接触这本书是因为上一个项目是用c++开发基于Linux的消息服务器,公司没有使用第三方的网络库,卷起袖子就开撸了.个人因为从业经验较短,主 要负责的是业务方面的编码.本着兴趣自己找了这本书.拿到书就 ...
- 《Linux 多线程服务端编程:使用 muduo C++ 网络库》电子版上市
<Linux 多线程服务端编程:使用 muduo C++ 网络库> 电子版已在京东和亚马逊上市销售. 京东购买地址:http://e.jd.com/30149978.html 亚马逊Kin ...
- 《Linux多线程服务端编程:使用muduo C++网络库》上市半年重印两次,总印数达到了9000册
<Linux多线程服务端编程:使用muduo C++网络库>这本书自今年一月上市以来,半年之内已经重印两次(加上首印,一共是三次印刷),总印数达到了9000册,这在技术书里已经算是相当不错 ...
随机推荐
- 使用 js 修饰器封装 axios
修饰器 修饰器是一个 JavaScript 函数(建议是纯函数),它用于修改类属性/方法或类本身.修饰器提案正处于第二阶段,我们可以使用 babel-plugin-transform-decorato ...
- centos安装httprunner方法
测试脚本执行的环境部署(在jenkins服务器中,要求jenkins服务器和目标的灰度环境是连通的): 一.安装python3.8 $python#看见2.6.6Python 2.6.6 (r266: ...
- python基础篇(完整版)
目录 计算机基础之编程和计算机组成 什么是编程语言 什么是编程 为什么要编程 编程语言的分类 机器语言(低级语言) 汇编语言 高级语言 计算机的五大组成 CPU(相当于人类的大脑) 多核CPU(多个大 ...
- java指定若干个网络图片,打包为zip下载
应项目要求需要将多个存在某url地址的图片,打包为zip下载下来 public void download(HttpServletRequest request, HttpServletRespons ...
- jQuery学习总结04-文档处理
1.append(content|fn) 说明:向每个匹配的元素内部追加内容. 这个操作与对指定的元素执行appendChild方法,将它们添加到文档中的情况类似. content(要追加到目标中的内 ...
- 求助:关于shell数值比较的错误提示
今天写了个脚本,过不了错误这一关,求大神路过瞟一眼. 1 #!/bin/bash 2 #disk use 3 disk_use() { 4 DISK_LOG=/tmp/disk_use.tmp 5 D ...
- 211-基于FMC的ADC-DAC子卡
基于FMC的ADC-DAC子卡 一.板卡概述 FMC-1AD-1DA-1SYNC是我司自主研发的一款1路1G AD采集.1路2.5G DA回放的FMC.1路AD同步信号子卡.板卡采用标准FMC子卡架构 ...
- OGG replicat复制进程的拆分
参考资料: 1.https://blog.csdn.net/datingting1/article/details/79583690
- glDrawArrays 和 glDrawElements
在openGL中,所有图形都是通过分解成三角形的方式进行绘制.(一个矩形分解成两个三角形进行绘制) glDrawArrays 和 glDrawElements 的作用都是从一个数据数组中提取数据渲染 ...
- Ubuntu NFS搭建过程
先简单介绍一下NFS服务器是什么? NFS server可以看作是一个FILE SERVER,它可以让你的PC通过网络将远端的NFS SERVER共享出来的档案MOUNT到自己的系统中,在CLIENT ...