elasticsearch relevance score相关性评分的计算
一、多shard场景下relevance score不准确问题
1、问题描述:
多个shard下,如果每个shard包含指定搜索条件的document数量不均匀的情况下,会导致在某个shard上document数量少的时候,计算该指定搜索条件的document的相关性评分要虚高。导致该document比实际真正想要返回的document的评分要高。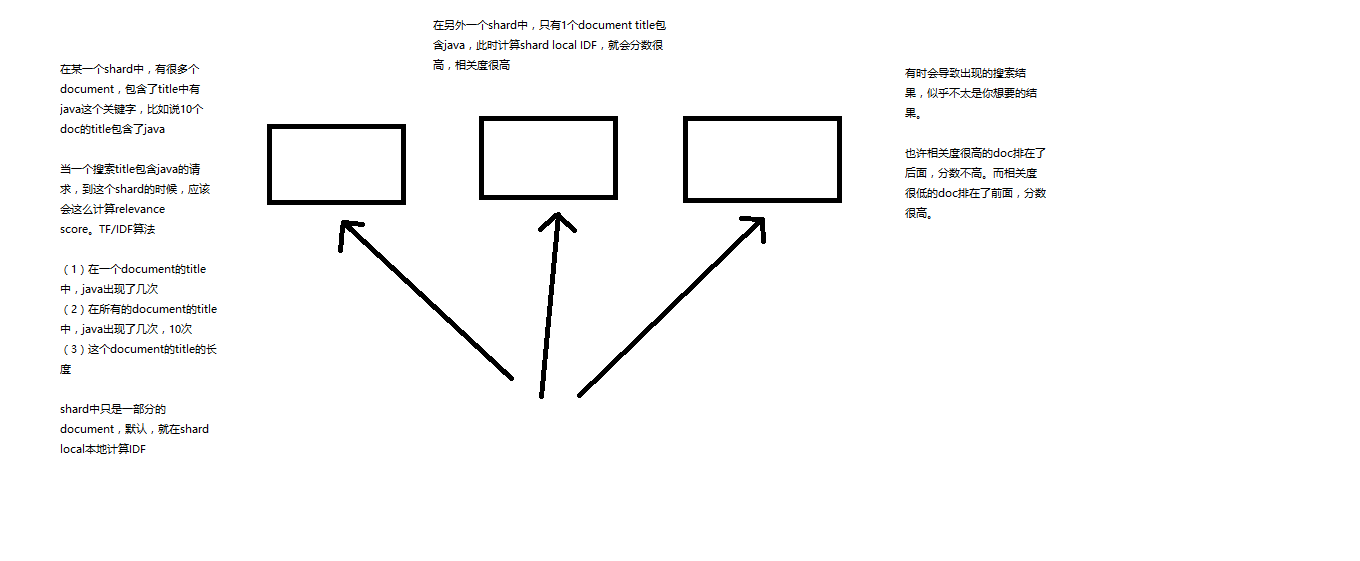
2、解决
(1)生产环境下,数据量大,尽可能实现均匀分配
数据量很大的话,其实一般情况下,在概率学的背景下,es都是在多个shard中均匀路由数据的,路由的时候根据_id,负载均衡
比如说有10个document,title都包含java,一共有5个shard,那么在概率学的背景下,如果负载均衡的话,其实每个shard都应该有2个doc,title包含java
如果说数据分布均匀的话,其实就没有刚才说的那个问题了
(2)测试环境下,将索引的primary shard设置为1个,number_of_shards=1,index settings
如果说只有一个shard,那么当然,所有的document都在这个shard里面,就没有这个问题了
(3)测试环境下,搜索附带search_type=dfs_query_then_fetch参数,会将local IDF取出来计算global IDF
计算一个doc的相关度分数的时候,就会将所有shard对的local IDF计算一下,获取出来,在本地进行global IDF分数的计算,会将所有shard的doc作为上下文来进行计算,也能确保准确性。但是production生产环境下,不推荐这个参数,因为性能很差。
二、多字段搜索相关性评分计算(best fields策略,most_field策略)
1、测试数据
POST /forum/article/_bulk
{ "index": { "_id": "1"} }
{"title" : "this is java and elasticsearch blog"}
{ "index": { "_id": "2"} }
{"title" : "this is java blog"}
{ "index": { "_id": "3"} }
{"title" : "this is elasticsearch blog"}
{ "index": { "_id": "4"} }
{"title" : "this is java, elasticsearch, hadoop blog"}
{ "index": { "_id": "5"} }
{"title" : "this is spark blog"}
POST /forum/article/_bulk
{ "update": { "_id": "1"} }
{ "doc" : {"content" : "i like to write best elasticsearch article"} }
{ "update": { "_id": "2"} }
{ "doc" : {"content" : "i think java is the best programming language"} }
{ "update": { "_id": "3"} }
{ "doc" : {"content" : "i am only an elasticsearch beginner"} }
{ "update": { "_id": "4"} }
{ "doc" : {"content" : "elasticsearch and hadoop are all very good solution, i am a beginner"} }
{ "update": { "_id": "5"} }
{ "doc" : {"content" : "spark is best big data solution based on scala ,an programming language similar to java"} }
POST /forum/_mapping/article
{
"properties": {
"sub_title": {
"type": "text",
"analyzer": "english",
"fields": {
"std": {
"type": "text",
"analyzer": "standard"
}
}
}
}
}
POST /forum/article/_bulk
{ "update": { "_id": "1"} }
{ "doc" : {"sub_title" : "learning more courses"} }
{ "update": { "_id": "2"} }
{ "doc" : {"sub_title" : "learned a lot of course"} }
{ "update": { "_id": "3"} }
{ "doc" : {"sub_title" : "we have a lot of fun"} }
{ "update": { "_id": "4"} }
{ "doc" : {"sub_title" : "both of them are good"} }
{ "update": { "_id": "5"} }
{ "doc" : {"sub_title" : "haha, hello world"} }
POST /forum/article/_bulk
{ "update": { "_id": "1"} }
{ "doc" : {"author_first_name" : "Peter", "author_last_name" : "Smith"} }
{ "update": { "_id": "2"} }
{ "doc" : {"author_first_name" : "Smith", "author_last_name" : "Williams"} }
{ "update": { "_id": "3"} }
{ "doc" : {"author_first_name" : "Jack", "author_last_name" : "Ma"} }
{ "update": { "_id": "4"} }
{ "doc" : {"author_first_name" : "Robbin", "author_last_name" : "Li"} }
{ "update": { "_id": "5"} }
{ "doc" : {"author_first_name" : "Tonny", "author_last_name" : "Peter Smith"} }完整数据结果
{
"took": 0,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 5,
"max_score": 1,
"hits": [
{
"_index": "forum",
"_type": "article",
"_id": "5",
"_score": 1,
"_source": {
"title": "this is spark blog",
"content": "spark is best big data solution based on scala ,an programming language similar to java",
"sub_title": "haha, hello world",
"author_first_name": "Tonny",
"author_last_name": "Peter Smith"
}
},
{
"_index": "forum",
"_type": "article",
"_id": "2",
"_score": 1,
"_source": {
"title": "this is java blog",
"content": "i think java is the best programming language",
"sub_title": "learned a lot of course",
"author_first_name": "Smith",
"author_last_name": "Williams"
}
},
{
"_index": "forum",
"_type": "article",
"_id": "4",
"_score": 1,
"_source": {
"title": "this is java, elasticsearch, hadoop blog",
"content": "elasticsearch and hadoop are all very good solution, i am a beginner",
"sub_title": "both of them are good",
"author_first_name": "Robbin",
"author_last_name": "Li"
}
},
{
"_index": "forum",
"_type": "article",
"_id": "1",
"_score": 1,
"_source": {
"title": "this is java and elasticsearch blog",
"content": "i like to write best elasticsearch article",
"sub_title": "learning more courses",
"author_first_name": "Peter",
"author_last_name": "Smith"
}
},
{
"_index": "forum",
"_type": "article",
"_id": "3",
"_score": 1,
"_source": {
"title": "this is elasticsearch blog",
"content": "i am only an elasticsearch beginner",
"sub_title": "we have a lot of fun",
"author_first_name": "Jack",
"author_last_name": "Ma"
}
}
]
}
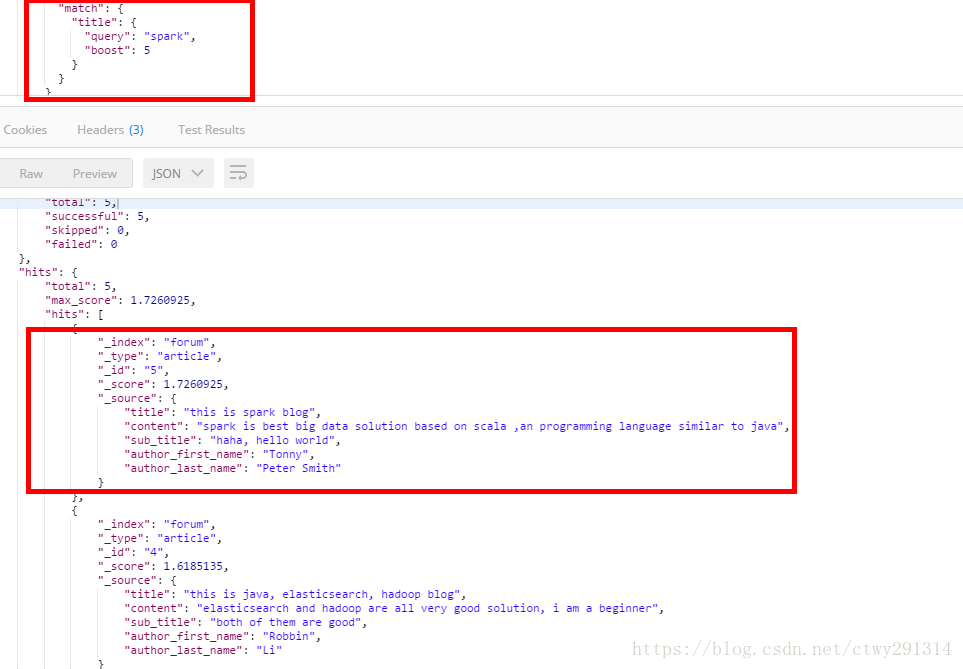
}2、搜索title中包含blog,同时java、elasticsearch、hadoop、spark只要包含都将搜索出来,但是我们希望拥有spark的评分最高,优先返回。我们可以使用boost,当匹配这个搜索条件计算relevance score时,将会有有更高的score
POST /forum/article/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"title": "blog"
}
}
],
"should": [
{
"match": {
"title": {
"query": "java"
}
}
},
{
"match": {
"title": {
"query": "hadoop"
}
}
},
{
"match": {
"title": {
"query": "elasticsearch"
}
}
},
{
"match": {
"title": {
"query": "spark",
"boost": 5
}
}
}
]
}
}
}
3、搜索title或content中包含java或solution的帖子
下面这个就是multi-field搜索,多字段搜索
POST /forum/article/_search
{
"query": {
"bool": {
"should": [
{ "match": { "title": "java solution" }},
{ "match": { "content": "java solution" }}
]
}
}
}
结果分析
返回doc的score顺序是_id=2 > _id=4 > _id=5,期望的是doc5,结果是doc2,doc4排在了前面
计算每个document的relevance score:每个query的分数(每一个query对应每个document,如果满足则会算出一个score,否则没有score)乘以matched query数量,除以总query数量。我们举例来说明doc4和doc5的大致评分过程。(具体的score为一个estimate time)
算一下"match": { "title": "java solution" }的分数
{
"query": {
"match": { "title": "java solution" }
}
}
算一下"match": { "content": "java solution" }的分数
{
"query": {
"match": { "content": "java solution" }
}
}
分数汇总
id match: { "title": "java solution" } match: { "content": "java solution" } "should": [
{ "match": { "title": "java solution" }},
{ "match": { "content": "java solution" }}
]1 0.2876821 0 0.2876821 2 0.19856805 0.7549128 0.95348084 3 0 0 0 4 0.16853254 0.64072424 0.8092568 5 0 0.5753642 0.5753642 算一下doc4的分数
{ "match": { "title": "java solution" }},针对doc4,是有一个分数的,0.16853254
{ "match": { "content": "java solution" }},针对doc4,也是有一个分数的,0.64072424
所以是两个分数加起来,0.16853254 + 0.64072424 = 0.8092568
matched query数量 = 2
总query数量 = 2
0.8092568 * 2 / 2 = 0.8092568


算一下doc5的分数
{ "match": { "title": "java solution" }},针对doc5,是没有分数的,0
{ "match": { "content": "java solution" }},针对doc5,是有一个分数的,0.5753642
所以说,只有一个query是有分数的,0.5753642
matched query数量 = 2
总query数量 = 2
0.5753642 * 2 / 2 = 0.5753642
doc5的分数 = 0.5753642 < doc4的分数 = 0.8092568
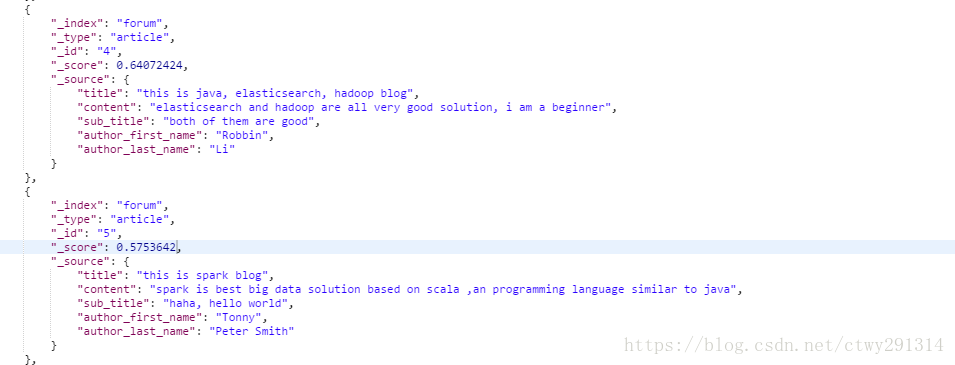
4、best fields策略,dis_max
best fields策略,就是说,搜索到的结果,应该是某一个field中匹配到了尽可能多的关键词,被排在前面;而不是尽可能多的field匹配到了少数的关键词,排在了前面
dis_max语法,直接取多个query中,分数最高的那一个query的分数即可
{ "match": { "title": "java solution" }},针对doc4,是有一个分数的,0.16853254
{ "match": { "content": "java solution" }},针对doc4,也是有一个分数的,0.64072424
取最大分数,0.64072424
{ "match": { "title": "java solution" }},针对doc5,是没有分数的,0
{ "match": { "content": "java solution" }},针对doc5,是有一个分数的,0.5753642
取最大分数,0.5753642
然后doc4的分数 = 0.64072424 > doc5的分数 = 0.5753642,所以doc5就可以排在更前面的地方,符合我们的需要
POST /forum/article/_search
{
"query": {
"dis_max": {
"queries": [
{ "match": { "title": "java solution" }},
{ "match": { "content": "java solution" }}
]
}
}
}
5、dis_max的优化、改进
dis_max只取某一个query最大的分数,完全不考虑其他query的分数。这样存在返回的document不是预期的情况
tie_breaker参数的意义,在于说,将其他query的分数,乘以tie_breaker,然后综合与最高分数的那个query的分数,综合在一起进行计算
除了取最高分以外,还会考虑其他的query的分数
tie_breaker的值,在0~1之间,是个小数,就ok
GET /forum/article/_search
{
"query": {
"dis_max": {
"queries": [
{ "match": { "title": "java solution" }},
{ "match": { "content": "java solution" }}
],
"tie_breaker": 0.3
}
}
}
6.基于multi_match语法实现dis_max+tie_breaker

GET /forum/article/_search
{
"query": {
"multi_match": {
"query": "java solution",
"type": "best_fields",
"fields": [ "title^2", "content" ], //title^2表示 boost设置为2
"tie_breaker": 0.3,
"minimum_should_match": "50%"
}
}
}
(1)minimum_should_match,主要是用来干嘛的?
去长尾,long tail
长尾,比如你搜索5个关键词,但是很多结果是只匹配1个关键词的,其实跟你想要的结果相差甚远,这些结果就是长尾
minimum_should_match,控制搜索结果的精准度,只有匹配一定数量的关键词的数据,才能返回
(2)title^2表示 boost设置为2
GET /forum/article/_search
{
"query": {
"dis_max": {
"queries": [
{
"match": {
"title": {
"query": "java beginner",
"minimum_should_match": "50%",
"boost": 2
}
}
},
{
"match": {
"content": {
"query": "java beginner",
"minimum_should_match": "50%"
}
}
}
],
"tie_breaker": 0.3
}
}
}7、most_fields策略
best-fields策略,主要是说将某一个field匹配尽可能多的关键词的doc优先返回回来
most-fields策略,主要是说尽可能返回更多field匹配到某个关键词的doc,优先返回回来
不同字段使用不同的分词器,对应不同的查询行为。
POST /forum/_mapping/article
{
"properties": {
"sub_title": {
"type": "string",
"analyzer": "english", // sub_title 使用english分词器
"fields": {
"std": {
"type": "string",
"analyzer": "standard" //sub_title字段的子字段std使用standard分词器
}
}
}
}
}sub_title字段english分词器:
会将单词还原为其最基本的形态,stemmer
learning --> learn
learned --> learn
courses --> course
subtitle.std子字段standard分词器: 保留当前字段值得原始值得时态信息等
POST /forum/article/_search
{
"query": {
"match": {
"sub_title": "learning courses"
}
}
}
当我们使用most_fields来查询sub_title和sub_title.std分词和不分词的field的时候可以看出most_fields的作用:
POST /forum/article/_search
{
"query": {
"multi_match": {
"query": "learning courses",
"type": "most_fields",
"fields": [ "sub_title", "sub_title.std" ]
}
}
}
管顺序没有变化(因为有其他因素的评分影响),但是匹配更多字段的doc的评分大幅度提升了
9、跨多个fields搜索同一个标识,例如搜索一个人名,可能会去first-name和last-name两个field中进行搜索,此时most_fields或者best_fields将不能够满足我们的最佳需求
对于搜索:
POST /forum/article/_search
{
"query": {
"multi_match": {
"query": "Petre Smith",
"fields": ["author_first_name","author_last_name"],
"type": "most_fields"
}
}
}
返回的结果score最高的是
“author_first_name”: “Smith”,
“author_last_name”: “Williams”
而我们希望得到的结果是
“author_first_name”: “Tonny”,
“author_last_name”: “Peter Smith”
针对多个field一些细微的relevence score算法会影响,多方面的影响是很复杂的,但是我们可以通过结果明确知道我们的结果却是被影响了
我们的解决方法是,将一个标识在跨fields的情况下,让多个field能够合并成一个field就能够解决我们的问题,比如说,一个人名会出现在first_name,last_name,现在能够合并成一个full_name就能够解决我们面临的问题
我们定义mapping来使用copy_to将多个field拷贝到一个field中去,并建立倒排索引供搜索:
POST /forum/_mapping/article
{
"properties": {
"new_author_first_name": {
"type": "text",
"copy_to": "new_author_full_name"
},
"new_author_last_name": {
"type": "text",
"copy_to": "new_author_full_name"
},
"new_author_full_name": {
"type": "text"
}
}
}
POST /forum/article/_bulk
{"update":{"_id":"1"}}
{"doc":{"new_author_first_name":"Peter","new_author_last_name":"Smith"}}
{"update":{"_id":"2"}}
{"doc":{"new_author_first_name":"Smith","new_author_last_name":"Williams"}}
{"update":{"_id":"3"}}
{"doc":{"new_author_first_name":"Jack","new_author_last_name":"Ma"}}
{"update":{"_id":"4"}}
{"doc":{"new_author_first_name":"Robbin","new_author_last_name":"Li"}}
{"update":{"_id":"5"}}
{"doc":{"new_author_first_name":"Tonny","new_author_last_name":"Peter Smith"}}需要注意的是new_author_full_name是一个隐藏field,直接search并不会显示出来。然后对这个field直接进行搜索即可:
POST /forum/article/_search
{
"query": {
"match": {
"new_author_full_name": "Peter Smith"
}
}
}
match查询常用的参数
- operator:用来控制match查询匹配词条的逻辑条件,默认值是or,如果设置为and,表示查询满足所有条件;
- minimum_should_match:当operator参数设置为or时,该参数用来控制应该匹配的分词的最少数量;
{
"query": {
"match": {
"new_author_full_name": {
"query": "Peter Smith",
"operator": "and"
}
}
}
}
总结:
问题1:之前的cross_fields只是尽可能找到多的field匹配的doc,而不是某个field完全匹配的doc
解决:合并成一个field之后是最匹配的doc被先返回
问题2:most_fields无法使用minimum_should_match来去长尾
解决:合并成一个field之后,在搜索的时候就可以进行去长尾
问题3:relevance score被TF/IDF因为多个field所影响而最终不是我们期望的结果
解决:合并之后参与评分的field相对于搜有的doc匹配的数量是相同的,数据相对均匀,不会有极端的偏差
使用原生cross_fields来实现我们的需求(推荐):
POST /forum/article/_search
{
"query": {
"multi_match": {
"query": "Peter Smith",
"operator":"and",
"fields": ["author_first_name","author_last_name"],
"type": "cross_fields"
}
}
}
上述搜索条件为:
Peter必须在author_first_name或者author_last_name中出现且Smith必须在author_first_name或者author_last_name中出现
针对上述问题1,2的解决可以很好的理解,但是对于问题3,cross_field会取多个query针对每一个field的idf评分最小值,而不会出现极端的情况。(举例:Smith针对author_first_name出现的频率很少最后的idf分数会很小,而author_last_name却很大,最后取小的值会避免极端的情况)
10、best_fields与most_fields:
(1)best_fields,是对多个field进行搜索,挑选某个field匹配度最高的那个分数,同时在多个query最高分相同的情况下,在一定程度上考虑其他query的分数。简单来说,你对多个field进行搜索,就想搜索到某一个field尽可能包含更多关键字的数据
优点:通过best_fields策略,以及综合考虑其他field,还有minimum_should_match支持,可以尽可能精准地将匹配的结果推送到最前面
缺点:除了那些精准匹配的结果,其他差不多大的结果,排序结果不是太均匀,没有什么区分度了
实际的例子:百度之类的搜索引擎,最匹配的到最前面,但是其他的就没什么区分度了
(2)most_fields,综合多个field一起进行搜索,尽可能多地让所有field的query参与到总分数的计算中来,此时就会是个大杂烩,出现类似best_fields案例最开始的那个结果,结果不一定精准,某一个document的一个field包含更多的关键字,但是因为其他document有更多field匹配到了,所以排在了前面;所以需要建立类似sub_title.std这样的field,尽可能让某一个field精准匹配query string,贡献更高的分数,将更精准匹配的数据排到前面
优点:将尽可能匹配更多field的结果推送到最前面,整个排序结果是比较均匀的
缺点:可能那些精准匹配的结果,无法推送到最前面
实际的例子:wiki,明显的most_fields策略,搜索结果比较均匀,但是的确要翻好几页才能找到最匹配的结果
参考:控制相关度,https://www.elastic.co/guide/cn/elasticsearch/guide/cn/controlling-relevance.html
https://blog.csdn.net/molong1208/article/details/50623948
elasticsearch relevance score相关性评分的计算的更多相关文章
- Elasticsearch学习笔记(十四)relevance score相关性评分的计算(1)
一.多shard场景下relevance score不准确问题 1.问题描述: 多个shard下,如果每个shard包含指定搜索条件的document数量不均匀的情况下, ...
- Elasticsearch学习之相关度评分TF&IDF
relevance score算法,简单来说,就是计算出,一个索引中的文本,与搜索文本,他们之间的关联匹配程度 Elasticsearch使用的是 term frequency/inverse doc ...
- Elasticsearch 相同内容文档,不同score(评分)的奇怪问题
原文:http://stackoverflow.com/questions/14580752/elasticsearch-gives-different-scores-for-same-documen ...
- Elasticsearch搜索之explain评分分析
Lucene的IndexSearcher提供一个explain方法,能够解释Document的Score是怎么得来的,具体每一部分的得分都可以详细地打印出来.这里用一个中文实例来纯手工验算一遍Luce ...
- Elasticsearch 分页坑之---评分一致导致数错乱
面试:你懂什么是分布式系统吗?Redis分布式锁都不会?>>> 1.背景介绍 最近搞es搜索,match查询默认按照评分排序,发现有一部分数据评分一致,一开始也没注意,客户端调用 ...
- 【原创】xgboost 特征评分的计算原理
xgboost是基于GBDT原理进行改进的算法,效率高,并且可以进行并行化运算: 而且可以在训练的过程中给出各个特征的评分,从而表明每个特征对模型训练的重要性, 调用的源码就不准备详述,本文主要侧重的 ...
- XGBboost 特征评分的计算原理
xgboost是基于GBDT原理进行改进的算法,效率高,并且可以进行并行化运算,而且可以在训练的过程中给出各个特征的评分,从而表明每个特征对模型训练的重要性, 调用的源码就不准备详述,本文主要侧重的是 ...
- python数据相关性分析 (计算相关系数)
#-*- coding: utf-8 -*- #餐饮销量数据相关性分析 计算相关系数 from __future__ import print_function import pandas as pd ...
- 读《深入理解Elasticsearch》点滴-查询评分
计算文档得分的因子: 文档权重(document boost):索引期赋予某个文档的权重值 字段权重(field boost):查询期赋予某个文档的权重值 协调因子(coord):基于文档中词项个数的 ...
随机推荐
- This program cannot be run in DOS mode.
问题:通过ftp上传的exe执行时提示“This program cannot be run in DOS mode.” 解决方法:检查ftp传输模式,设置成binary模式上传即可 参考:https ...
- mysql小知识
char(10): 换行符 char(13): 回车符 UPDATE tablename SET field = REPLACE(REPLACE(field, CHAR(10), ”), CHAR(1 ...
- SYSAUX表空间满,
step1. 确认到底是哪个段占用了sysaux空间: select segment_name,sum(bytes)/1024/1024 from dba_segments where tables ...
- 利用 Redis 锁解决高并发问题
这里我们主要利用 Redis 的 setnx 的命令来处理高并发. setnx 有两个参数.第一个参数表示键.第二个参数表示值.如果当前键不存在,那么会插入当前键,将第二个参数做为值.返回 1.如果当 ...
- Java二级练习试题一
为保护本地主机,对Applet安全限制中正确的是() A. Applet可加载本地库或方法 B. Applet可读.写本地计算机的文件系统 C. Applet可向Applet之外的任何主机建立网络连接 ...
- noteone
- vagrant(二)配置文件vagrantfile详解 以及安装php、nginx、mysql
上一篇文章完整的讲叙了如何安装一个vagrant的环境.这里主要说一说vagrant的配置文件Vagrantfile. 一 配置详解 在我们的开发目录下有一个文件Vagrantfile,里面包含有大量 ...
- 第一周作业—N42-虚怀若谷
一.Linux发行版描述. Linux发行版主要有三个分支:Slackware.Debian.Redhat: (1) Slackware: SUSE:基于Slackware二次开发的一款Linux,主 ...
- python使用qq邮箱向163邮箱发送邮件、附件
在生成html测试报告后 import smtplib,time from email.mime.text import MIMEText from email.mime.multipart impo ...
- 4412 SPI驱动
1.Linux主机驱动和外设驱动分离思想(I2C驱动里有) SPI驱动总线架构:SPI核心层(x),SPI控制器驱动层(x),SPI设备驱动层(√).前面两个设备驱动搞明白了可以去看 2.教程中介绍: ...