Temporal-Difference Learning for Prediction
In Monte Carlo Learning, we've got the estimation of value function:
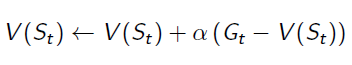
Gt is the episode return from time t, which can be calculated by:
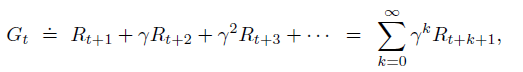
Please recall, Gt can be only calculated at the end of a given episode. This reveals a disadvantage of Monte Carlo Learning: have to wait until the end of episodes.
TD(0) algorithm replace Gt of the equation to the immediate reward and estimated value function of the next state:
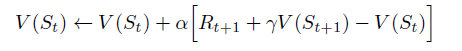
The algorithm updates the Estimated State-Value Function at time t+1, because everything in the equation is determined. This means we will wait until the agent reaching the next state, so that the agent can get the immediate reward Rt+1 and know which state the system will transition to at time t+1.
The equations below are State-Value Function for Dynamic Programming, in which the whole environment is known. Compare to these equations:
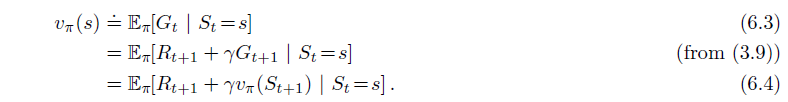
TD algorithm is quite like 6.4 Bellman Equation, but it does not take expectation. Instead, it uses the knowledge till now to estimate how much reward I am going to get from this state. The whole algorithm can be demonstrated as:

TD Target, TD Error
Bias/ Viriance trade-off
Bootstraping
Temporal-Difference Learning for Prediction的更多相关文章
- 【PPT】 Least squares temporal difference learning
最小二次方时序差分学习 原文地址: https://www.google.com/url?sa=t&rct=j&q=&esrc=s&source=web&cd= ...
- PP: Multi-Horizon Time Series Forecasting with Temporal Attention Learning
Problem: multi-horizon probabilistic forecasting tasks; Propose an end-to-end framework for multi-ho ...
- [Reinforcement Learning] Model-Free Prediction
上篇文章介绍了 Model-based 的通用方法--动态规划,本文内容介绍 Model-Free 情况下 Prediction 问题,即 "Estimate the value funct ...
- [Machine Learning] 机器学习常见算法分类汇总
声明:本篇博文根据http://www.ctocio.com/hotnews/15919.html整理,原作者张萌,尊重原创. 机器学习无疑是当前数据分析领域的一个热点内容.很多人在平时的工作中都或多 ...
- (转) Deep Learning Research Review Week 2: Reinforcement Learning
Deep Learning Research Review Week 2: Reinforcement Learning 转载自: https://adeshpande3.github.io/ad ...
- Awesome Reinforcement Learning
Awesome Reinforcement Learning A curated list of resources dedicated to reinforcement learning. We h ...
- Machine Learning 学习笔记1 - 基本概念以及各分类
What is machine learning? 并没有广泛认可的定义来准确定义机器学习.以下定义均为译文,若以后有时间,将补充原英文...... 定义1.来自Arthur Samuel(上世纪50 ...
- Distributional Reinforcement Learning with Quantile Regression
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布! arXiv:1710.10044v1 [cs.AI] 27 Oct 2017 In AAAI Conference on Artifici ...
- 3. Distributional Reinforcement Learning with Quantile Regression
C51算法理论上用Wasserstein度量衡量两个累积分布函数间的距离证明了价值分布的可行性,但在实际算法中用KL散度对离散支持的概率进行拟合,不能作用于累积分布函数,不能保证Bellman更新收敛 ...
随机推荐
- Eclipse从远程仓库的工程克隆到本地仓库
在Eclipse中,File→Import→Git→Projects from Git 点击Next→Clone URI Next,将工厂地址复制过来 Next,再点击Next, 点击Browse,选 ...
- 认识一下Qt用到的开发工具
http://c.biancheng.net/view/3868.html Qt 不是凭空产生的,它是基于现有工具链打造而成的,它所使用的编译器.链接器.调试器等都不是自己的,Qt 官方只是开发了上层 ...
- C# 中定义扩展方法
1.编写扩展方法类 using System; using System.Collections.Generic; using System.Linq; using System.Text; name ...
- Educational Codeforces Round 55 (Rated for Div. 2) B. Vova and Trophies (贪心+字符串)
B. Vova and Trophies time limit per test2 seconds memory limit per test256 megabytes inputstandard i ...
- 计蒜客 蓝桥模拟 I. 天上的星星
计算二维前缀和,节省时间.容斥定理. 代码: #include <cstdio> #include <cstdlib> #include <cstring> #in ...
- DUBBO原理、应用与面经总结
研读dubbo源码已经有一段时间了,dubbo中有非常多优秀的设计模式和示例代码值得学习,但是dubbo的调用层级和方法链都较为繁杂,如果不对源码思路进行梳理则很容易忘却,因此总结一篇研读心得,从阅读 ...
- ubuntu16.04 安装mysql
安装mysql 1.sudo apt-get install mysql-server 2.sudo apt install mysql-client 3.sudo apt install libmy ...
- handy源码阅读(六):udp类
分为UdpServer类和UdpConn类. struct UdpServer : public std::enable_shared_from_this<UdpServer>, priv ...
- handy源码阅读(四):Channel类
通道,封装了可以进行epoll的一个fd. struct Channel: private noncopyable { Channel(EventBase* base, int fd, int eve ...
- CSS3制作太极图以及用JS实现旋转太极图
太极图可以理解为一个一半黑一半白的半圆,上面放置着两个圆形,一个黑色边框白色芯,一个白色边框黑色芯. 1.实现黑白各半的圆形. .box{ width:200px;height:200px; bor ...