Cpython解释器支持的线程
因为Python解释器帮你自动定期进行内存回收,你可以理解为python解释器里有一个独立的线程,每过一段时间它起wake up做一次全局轮询看看哪些内存数据是可以被清空的,此时你自己的程序 里的线程和 py解释器自己的线程是并发运行的,假设你的线程删除了一个变量,py解释器的垃圾回收线程在清空这个变量的过程中的clearing时刻,可能一个其它线程正好又重新给这个还没来及得清空的内存空间赋值了,结果就有可能新赋值的数据被删除了,为了解决类似的问题,python解释器简单粗暴的加了锁,即当一个线程运行时,其它人都不能动,这样就解决了上述的问题, 这可以说是Python早期版本的遗留问题。
一 理论部分
一 什么是线程
在传统操作系统中,每个进程有一个地址空间,而且默认就有一个控制线程
线程顾名思义,就是一条流水线工作的过程,一条流水线必须属于一个车间,一个车间的工作过程是一个进程
车间负责把资源整合到一起,是一个资源单位,而一个车间内至少有一个流水线
流水线的工作需要电源,电源就相当于cpu
所以,进程只是用来把资源集中到一起(进程只是一个资源单位,或者说资源集合),而线程才是cpu上的执行单位。
多线程(即多个控制线程)的概念是,在一个进程中存在多个控制线程,多个控制线程共享该进程的地址空间,相当于一个车间内有多条流水线,都共用一个车间的资源。
例如,北京地铁与上海地铁是不同的进程,而北京地铁里的13号线是一个线程,北京地铁所有的线路共享北京地铁所有的资源,比如所有的乘客可以被所有线路拉。
二 线程的创建开销小
创建进程的开销要远大于线程?
如果我们的软件是一个工厂,该工厂有多条流水线,流水线工作需要电源,电源只有一个即cpu(单核cpu)
一个车间就是一个进程,一个车间至少一条流水线(一个进程至少一个线程)
创建一个进程,就是创建一个车间(申请空间,在该空间内建至少一条流水线)
而建线程,就只是在一个车间内造一条流水线,无需申请空间,所以创建开销小
进程之间是竞争关系,线程之间是协作关系?
车间直接是竞争/抢电源的关系,竞争(不同的进程直接是竞争关系,是不同的程序员写的程序运行的,迅雷抢占其他进程的网速,360把其他进程当做病毒干死)
一个车间的不同流水线式协同工作的关系(同一个进程的线程之间是合作关系,是同一个程序写的程序内开启动,迅雷内的线程是合作关系,不会自己干自己)
三 线程与进程的区别
- Threads share the address space of the process that created it; processes have their own address space 线程共享创建它的进程的地址空间; 进程有自己的地址空间。
- Threads have direct access to the data segment of its process; processes have their own copy of the data segment of the parent process.线程可以直接访问其进程的数据段; 进程具有自己的父进程的数据段副本。
- Threads can directly communicate with other threads of its process; processes must use interprocess communication to communicate with sibling processes.线程可以直接与其进程的其他线程通信; 进程必须使用进程间通信来与兄弟进程进行通信。
- New threads are easily created; new processes require duplication of the parent process.新线程很容易创建; 新进程需要父进程的副本。线程创建开销小
- Threads can exercise considerable control over threads of the same process; processes can only exercise control over child processes.线程可以对相同进程的线程进行相当的控制; 进程只能控制子进程。
- Changes to the main thread (cancellation, priority change, etc.) may affect the behavior of the other threads of the process; changes to the parent process does not affect child processes.对主线程的更改(取消,优先级更改等)可能会影响进程的其他线程的行为; 对父进程的更改不会影响子进程。
1. 线程共享创建它的进程的地址空间; 进程有自己的地址空间。
2.线程可以直接访问其进程的数据; 进程具有自己的父进程的数据的副本。
3.线程可以直接与其进程的其他线程通信; 进程必须使用进程间通信来与兄弟进程进行通信。
4.新线程很容易创建; 新进程需要父进程的副本。线程创建开销小
5.线程可以对相同进程的线程进行相当的控制; 进程只能控制子进程。
6.对主线程的更改(取消,优先级更改等)可能会影响进程的其他线程的行为; 对父进程的更改不会影响子进程。
四 为何要用多线程
多线程指的是,在一个进程中开启多个线程,简单的讲:如果多个任务共用一块地址空间,那么必须在一个进程内开启多个线程。详细的讲分为4点:
1. 多线程共享一个进程的地址空间
2. 线程比进程更轻量级,线程比进程更容易创建可撤销,在许多操作系统中,创建一个线程比创建一个进程要快10-100倍,在有大量线程需要动态和快速修改时,这一特性很有用
3. 若多个线程都是cpu密集型的,那么并不能获得性能上的增强,但是如果存在大量的计算和大量的I/O处理,拥有多个线程允许这些活动彼此重叠运行,从而会加快程序执行的速度。
4. 在多cpu系统中,为了最大限度的利用多核,可以开启多个线程,比开进程开销要小的多。(这一条并不适用于python)
五 多线程的应用举例

开启一个字处理软件进程,该进程肯定需要办不止一件事情,比如监听键盘输入,处理文字,定时自动将文字保存到硬盘,这三个任务操作的都是同一块数据,因而不能用多进程。只能在一个进程里并发地开启三个线程,如果是单线程,那就只能是,键盘输入时,不能处理文字和自动保存,自动保存时又不能输入和处理文字。
六 经典的线程模型(了解)
多个线程共享同一个进程的地址空间中的资源,是对一台计算机上多个进程的模拟,有时也称线程为轻量级的进程
而对一台计算机上多个进程,则共享物理内存、磁盘、打印机等其他物理资源。
多线程的运行也多进程的运行类似,是cpu在多个线程之间的快速切换。
不同的进程之间是充满敌意的,彼此是抢占、竞争cpu的关系,如果迅雷会和QQ抢资源。而同一个进程是由一个程序员的程序创建,所以同一进程内的线程是合作关系,一个线程可以访问另外一个线程的内存地址,大家都是共享的,一个线程干死了另外一个线程的内存,那纯属程序员脑子有问题。
类似于进程,每个线程也有自己的堆栈

不同于进程,线程库无法利用时钟中断强制线程让出CPU,可以调用thread_yield运行线程自动放弃cpu,让另外一个线程运行。
线程通常是有益的,但是带来了不小程序设计难度,线程的问题是:
1. 父进程有多个线程,那么开启的子线程是否需要同样多的线程
如果是,那么附近中某个线程被阻塞,那么copy到子进程后,copy版的线程也要被阻塞吗,想一想nginx的多线程模式接收用户连接。
2. 在同一个进程中,如果一个线程关闭了问题,而另外一个线程正准备往该文件内写内容呢?
如果一个线程注意到没有内存了,并开始分配更多的内存,在工作一半时,发生线程切换,新的线程也发现内存不够用了,又开始分配更多的内存,这样内存就被分配了多次,这些问题都是多线程编程的典型问题,需要仔细思考和设计。
七 POSIX线程(了解)
为了实现可移植的线程程序,IEEE在IEEE标准1003.1c中定义了线程标准,它定义的线程包叫Pthread。大部分UNIX系统都支持该标准,简单介绍如下

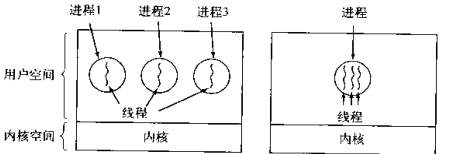
八 在用户空间实现的线程(了解)
线程的实现可以分为两类:用户级线程(User-Level Thread)和内核线线程(Kernel-Level Thread),后者又称为内核支持的线程或轻量级进程。在多线程操作系统中,各个系统的实现方式并不相同,在有的系统中实现了用户级线程,有的系统中实现了内核级线程。
用户级线程内核的切换由用户态程序自己控制内核切换,不需要内核干涉,少了进出内核态的消耗,但不能很好的利用多核Cpu,目前Linux pthread大体是这么做的。

在用户空间模拟操作系统对进程的调度,来调用一个进程中的线程,每个进程中都会有一个运行时系统,用来调度线程。此时当该进程获取cpu时,进程内再调度出一个线程去执行,同一时刻只有一个线程执行。
九 在内核空间实现的线程(了解)
内核级线程:切换由内核控制,当线程进行切换的时候,由用户态转化为内核态。切换完毕要从内核态返回用户态;可以很好的利用smp,即利用多核cpu。windows线程就是这样的。

十 用户级与内核级线程的对比(了解)
一: 以下是用户级线程和内核级线程的区别:
- 内核支持线程是OS内核可感知的,而用户级线程是OS内核不可感知的。
- 用户级线程的创建、撤消和调度不需要OS内核的支持,是在语言(如Java)这一级处理的;而内核支持线程的创建、撤消和调度都需OS内核提供支持,而且与进程的创建、撤消和调度大体是相同的。
- 用户级线程执行系统调用指令时将导致其所属进程被中断,而内核支持线程执行系统调用指令时,只导致该线程被中断。
- 在只有用户级线程的系统内,CPU调度还是以进程为单位,处于运行状态的进程中的多个线程,由用户程序控制线程的轮换运行;在有内核支持线程的系统内,CPU调度则以线程为单位,由OS的线程调度程序负责线程的调度。
- 用户级线程的程序实体是运行在用户态下的程序,而内核支持线程的程序实体则是可以运行在任何状态下的程序。
二: 内核线程的优缺点
优点:
- 当有多个处理机时,一个进程的多个线程可以同时执行。
缺点:
- 由内核进行调度。
三: 用户进程的优缺点
优点:
- 线程的调度不需要内核直接参与,控制简单。
- 可以在不支持线程的操作系统中实现。
- 创建和销毁线程、线程切换代价等线程管理的代价比内核线程少得多。
- 允许每个进程定制自己的调度算法,线程管理比较灵活。
- 线程能够利用的表空间和堆栈空间比内核级线程多。
- 同一进程中只能同时有一个线程在运行,如果有一个线程使用了系统调用而阻塞,那么整个进程都会被挂起。另外,页面失效也会产生同样的问题。
缺点:
- 资源调度按照进程进行,多个处理机下,同一个进程中的线程只能在同一个处理机下分时复用
十一 混合实现(了解)
用户级与内核级的多路复用,内核同一调度内核线程,每个内核线程对应n个用户线程

二、代码部分
一 threading模块介绍
multiprocess模块的完全模仿了threading模块的接口,二者在使用层面,有很大的相似性,因而不再详细介绍
官网链接:https://docs.python.org/3/library/threading.html?highlight=threading#
二 开启线程的两种方式
#方式一
from threading import Thread
import time
def sayhi(name):
time.sleep(2)
print('%s say hello' %name) if __name__ == '__main__':
t=Thread(target=sayhi,args=('egon',))
t.start()
print('主线程')
#方式二
from threading import Thread
import time
class Sayhi(Thread):
def __init__(self,name):
super().__init__()
self.name=name
def run(self):
time.sleep(2)
print('%s say hello' % self.name) if __name__ == '__main__':
t = Sayhi('egon')
t.start()
print('主线程')
三 在一个进程下开启多个线程与在一个进程下开启多个子进程的区别
1.谁的开启速度快
from threading import Thread
from multiprocessing import Process
import os def work():
print('hello') if __name__ == '__main__':
#在主进程下开启线程
t=Thread(target=work)
t.start()
print('主线程/主进程')
'''
打印结果:
hello
主线程/主进程
''' #在主进程下开启子进程
t=Process(target=work)
t.start()
print('主线程/主进程')
'''
打印结果:
主线程/主进程
hello
'''
2.瞅一瞅pid
from threading import Thread
from multiprocessing import Process
import os def work():
print('hello',os.getpid()) if __name__ == '__main__':
#part1:在主进程下开启多个线程,每个线程都跟主进程的pid一样
t1=Thread(target=work)
t2=Thread(target=work)
t1.start()
t2.start()
print('主线程/主进程pid',os.getpid()) #part2:开多个进程,每个进程都有不同的pid
p1=Process(target=work)
p2=Process(target=work)
p1.start()
p2.start()
print('主线程/主进程pid',os.getpid())
3.同一进程内的线程共享该进程的数据?
from threading import Thread
from multiprocessing import Process
import os
def work():
global n
n=0 if __name__ == '__main__':
# n=100
# p=Process(target=work)
# p.start()
# p.join()
# print('主',n) #毫无疑问子进程p已经将自己的全局的n改成了0,但改的仅仅是它自己的,查看父进程的n仍然为100 n=1
t=Thread(target=work)
t.start()
t.join()
print('主',n) #查看结果为0,因为同一进程内的线程之间共享进程内的数据
四 练习
练习1
多线程并发的socket服务端
#_*_coding:utf-8_*_
#!/usr/bin/env python
import multiprocessing
import threading import socket
s=socket.socket(socket.AF_INET,socket.SOCK_STREAM)
s.bind(('127.0.0.1',8080))
s.listen(5) def action(conn):
while True:
data=conn.recv(1024)
print(data)
conn.send(data.upper()) if __name__ == '__main__': while True:
conn,addr=s.accept() p=threading.Thread(target=action,args=(conn,))
p.start()
客户端
#_*_coding:utf-8_*_
#!/usr/bin/env python import socket s=socket.socket(socket.AF_INET,socket.SOCK_STREAM)
s.connect(('127.0.0.1',8080)) while True:
msg=input('>>: ').strip()
if not msg:continue s.send(msg.encode('utf-8'))
data=s.recv(1024)
print(data)
练习二:三个任务,一个接收用户输入,一个将用户输入的内容格式化成大写,一个将格式化后的结果存入文件
from threading import Thread
msg_l=[]
format_l=[]
def talk():
while True:
msg=input('>>: ').strip()
if not msg:continue
msg_l.append(msg) def format_msg():
while True:
if msg_l:
res=msg_l.pop()
format_l.append(res.upper()) def save():
while True:
if format_l:
with open('db.txt','a',encoding='utf-8') as f:
res=format_l.pop()
f.write('%s\n' %res) if __name__ == '__main__':
t1=Thread(target=talk)
t2=Thread(target=format_msg)
t3=Thread(target=save)
t1.start()
t2.start()
t3.start()
五 线程相关的其他方法
Thread实例对象的方法
# isAlive(): 返回线程是否活动的。
# getName(): 返回线程名。
# setName(): 设置线程名。 threading模块提供的一些方法:
# threading.currentThread(): 返回当前的线程变量。
# threading.enumerate(): 返回一个包含正在运行的线程的list。正在运行指线程启动后、结束前,不包括启动前和终止后的线程。
# threading.activeCount(): 返回正在运行的线程数量,与len(threading.enumerate())有相同的结果。
from threading import Thread
import threading
from multiprocessing import Process
import os def work():
import time
time.sleep(3)
print(threading.current_thread().getName()) if __name__ == '__main__':
#在主进程下开启线程
t=Thread(target=work)
t.start() print(threading.current_thread().getName())
print(threading.current_thread()) #主线程
print(threading.enumerate()) #连同主线程在内有两个运行的线程
print(threading.active_count())
print('主线程/主进程') '''
打印结果:
MainThread
<_MainThread(MainThread, started 140735268892672)>
[<_MainThread(MainThread, started 140735268892672)>, <Thread(Thread-1, started 123145307557888)>]
主线程/主进程
Thread-1
'''
主线程等待子线程结束
from threading import Thread
import time
def sayhi(name):
time.sleep(2)
print('%s say hello' %name) if __name__ == '__main__':
t=Thread(target=sayhi,args=('egon',))
t.start()
t.join()
print('主线程')
print(t.is_alive())
'''
egon say hello
主线程
False
'''
六 守护线程
无论是进程还是线程,都遵循:守护xxx会等待主xxx运行完毕后被销毁
需要强调的是:运行完毕并非终止运行
#1.对主进程来说,运行完毕指的是主进程代码运行完毕 #2.对主线程来说,运行完毕指的是主线程所在的进程内所有非守护线程统统运行完毕,主线程才算运行完毕
详细解释:
#1 主进程在其代码结束后就已经算运行完毕了(守护进程在此时就被回收),然后主进程会一直等非守护的子进程都运行完毕后回收子进程的资源(否则会产生僵尸进程),才会结束, #2 主线程在其他非守护线程运行完毕后才算运行完毕(守护线程在此时就被回收)。因为主线程的结束意味着进程的结束,进程整体的资源都将被回收,而进程必须保证非守护线程都运行完毕后才能结束。
from threading import Thread
import time
def sayhi(name):
time.sleep(2)
print('%s say hello' %name) if __name__ == '__main__':
t=Thread(target=sayhi,args=('egon',))
t.setDaemon(True) #必须在t.start()之前设置
t.start() print('主线程')
print(t.is_alive())
'''
主线程
True
'''
迷惑人的例子
from threading import Thread
import time
def foo():
print(123)
time.sleep(1)
print("end123") def bar():
print(456)
time.sleep(3)
print("end456") t1=Thread(target=foo)
t2=Thread(target=bar) t1.daemon=True
t1.start()
t2.start()
print("main-------")
七 Python GIL(Global Interpreter Lock)
http://www.cnblogs.com/ctztake/p/7454988.html
八 同步锁
三个需要注意的点:
#1.线程抢的是GIL锁,GIL锁相当于执行权限,拿到执行权限后才能拿到互斥锁Lock,其他线程也可以抢到GIL,但如果发现Lock仍然没有被释放则阻塞,即便是拿到执行权限GIL也要立刻交出来 #2.join是等待所有,即整体串行,而锁只是锁住修改共享数据的部分,即部分串行,要想保证数据安全的根本原理在于让并发变成串行,join与互斥锁都可以实现,毫无疑问,互斥锁的部分串行效率要更高 #3. 一定要看本小节最后的GIL与互斥锁的经典分析
GIL VS Lock
机智的同学可能会问到这个问题,就是既然你之前说过了,Python已经有一个GIL来保证同一时间只能有一个线程来执行了,为什么这里还需要lock?
首先我们需要达成共识:锁的目的是为了保护共享的数据,同一时间只能有一个线程来修改共享的数据
然后,我们可以得出结论:保护不同的数据就应该加不同的锁。
最后,问题就很明朗了,GIL 与Lock是两把锁,保护的数据不一样,前者是解释器级别的(当然保护的就是解释器级别的数据,比如垃圾回收的数据),后者是保护用户自己开发的应用程序的数据,很明显GIL不负责这件事,只能用户自定义加锁处理,即Lock
过程分析:所有线程抢的是GIL锁,或者说所有线程抢的是执行权限
线程1抢到GIL锁,拿到执行权限,开始执行,然后加了一把Lock,还没有执行完毕,即线程1还未释放Lock,有可能线程2抢到GIL锁,开始执行,执行过程中发现Lock还没有被线程1释放,于是线程2进入阻塞,被夺走执行权限,有可能线程1拿到GIL,然后正常执行到释放Lock。。。这就导致了串行运行的效果
既然是串行,那我们执行
t1.start()
t1.join
t2.start()
t2.join()
这也是串行执行啊,为何还要加Lock呢,需知join是等待t1所有的代码执行完,相当于锁住了t1的所有代码,而Lock只是锁住一部分操作共享数据的代码。
因为Python解释器帮你自动定期进行内存回收,你可以理解为python解释器里有一个独立的线程,每过一段时间它起wake up做一次全局轮询看看哪些内存数据是可以被清空的,此时你自己的程序 里的线程和 py解释器自己的线程是并发运行的,假设你的线程删除了一个变量,py解释器的垃圾回收线程在清空这个变量的过程中的clearing时刻,可能一个其它线程正好又重新给这个还没来及得清空的内存空间赋值了,结果就有可能新赋值的数据被删除了,为了解决类似的问题,python解释器简单粗暴的加了锁,即当一个线程运行时,其它人都不能动,这样就解决了上述的问题, 这可以说是Python早期版本的遗留问题。
from threading import Thread
import os,time
def work():
global n
temp=n
time.sleep(0.1)
n=temp-1
if __name__ == '__main__':
n=100
l=[]
for i in range(100):
p=Thread(target=work)
l.append(p)
p.start()
for p in l:
p.join() print(n) #结果可能为99
锁通常被用来实现对共享资源的同步访问。为每一个共享资源创建一个Lock对象,当你需要访问该资源时,调用acquire方法来获取锁对象(如果其它线程已经获得了该锁,则当前线程需等待其被释放),待资源访问完后,再调用release方法释放锁:
import threading R=threading.Lock() R.acquire()
'''
对公共数据的操作
'''
R.release()
from threading import Thread,Lock
import os,time
def work():
global n
lock.acquire()
temp=n
time.sleep(0.1)
n=temp-1
lock.release()
if __name__ == '__main__':
lock=Lock()
n=100
l=[]
for i in range(100):
p=Thread(target=work)
l.append(p)
p.start()
for p in l:
p.join() print(n) #结果肯定为0,由原来的并发执行变成串行,牺牲了执行效率保证了数据安全
分析:
#1.100个线程去抢GIL锁,即抢执行权限
#2. 肯定有一个线程先抢到GIL(暂且称为线程1),然后开始执行,一旦执行就会拿到lock.acquire()
#3. 极有可能线程1还未运行完毕,就有另外一个线程2抢到GIL,然后开始运行,但线程2发现互斥锁lock还未被线程1释放,于是阻塞,被迫交出执行权限,即释放GIL
#4.直到线程1重新抢到GIL,开始从上次暂停的位置继续执行,直到正常释放互斥锁lock,然后其他的线程再重复2 3 4的过程 GIL锁与互斥锁综合分析(重点!!!)
#不加锁:并发执行,速度快,数据不安全
from threading import current_thread,Thread,Lock
import os,time
def task():
global n
print('%s is running' %current_thread().getName())
temp=n
time.sleep(0.5)
n=temp-1 if __name__ == '__main__':
n=100
lock=Lock()
threads=[]
start_time=time.time()
for i in range(100):
t=Thread(target=task)
threads.append(t)
t.start()
for t in threads:
t.join() stop_time=time.time()
print('主:%s n:%s' %(stop_time-start_time,n)) '''
Thread-1 is running
Thread-2 is running
......
Thread-100 is running
主:0.5216062068939209 n:99
''' #不加锁:未加锁部分并发执行,加锁部分串行执行,速度慢,数据安全
from threading import current_thread,Thread,Lock
import os,time
def task():
#未加锁的代码并发运行
time.sleep(3)
print('%s start to run' %current_thread().getName())
global n
#加锁的代码串行运行
lock.acquire()
temp=n
time.sleep(0.5)
n=temp-1
lock.release() if __name__ == '__main__':
n=100
lock=Lock()
threads=[]
start_time=time.time()
for i in range(100):
t=Thread(target=task)
threads.append(t)
t.start()
for t in threads:
t.join()
stop_time=time.time()
print('主:%s n:%s' %(stop_time-start_time,n)) '''
Thread-1 is running
Thread-2 is running
......
Thread-100 is running
主:53.294203758239746 n:0
''' #有的同学可能有疑问:既然加锁会让运行变成串行,那么我在start之后立即使用join,就不用加锁了啊,也是串行的效果啊
#没错:在start之后立刻使用jion,肯定会将100个任务的执行变成串行,毫无疑问,最终n的结果也肯定是0,是安全的,但问题是
#start后立即join:任务内的所有代码都是串行执行的,而加锁,只是加锁的部分即修改共享数据的部分是串行的
#单从保证数据安全方面,二者都可以实现,但很明显是加锁的效率更高.
from threading import current_thread,Thread,Lock
import os,time
def task():
time.sleep(3)
print('%s start to run' %current_thread().getName())
global n
temp=n
time.sleep(0.5)
n=temp-1 if __name__ == '__main__':
n=100
lock=Lock()
start_time=time.time()
for i in range(100):
t=Thread(target=task)
t.start()
t.join()
stop_time=time.time()
print('主:%s n:%s' %(stop_time-start_time,n)) '''
Thread-1 start to run
Thread-2 start to run
......
Thread-100 start to run
主:350.6937336921692 n:0 #耗时是多么的恐怖
''' 互斥锁与join的区别(重点!!!)
九 死锁现象与递归锁
进程也有死锁与递归锁,在进程那里忘记说了,放到这里一切说了额
所谓死锁: 是指两个或两个以上的进程或线程在执行过程中,因争夺资源而造成的一种互相等待的现象,若无外力作用,它们都将无法推进下去。此时称系统处于死锁状态或系统产生了死锁,这些永远在互相等待的进程称为死锁进程,如下就是死锁
from threading import Thread,Lock
import time
mutexA=Lock()
mutexB=Lock() class MyThread(Thread):
def run(self):
self.func1()
self.func2()
def func1(self):
mutexA.acquire()
print('\033[41m%s 拿到A锁\033[0m' %self.name) mutexB.acquire()
print('\033[42m%s 拿到B锁\033[0m' %self.name)
mutexB.release() mutexA.release() def func2(self):
mutexB.acquire()
print('\033[43m%s 拿到B锁\033[0m' %self.name)
time.sleep(2) mutexA.acquire()
print('\033[44m%s 拿到A锁\033[0m' %self.name)
mutexA.release() mutexB.release() if __name__ == '__main__':
for i in range(10):
t=MyThread()
t.start() '''
Thread-1 拿到A锁
Thread-1 拿到B锁
Thread-1 拿到B锁
Thread-2 拿到A锁
然后就卡住,死锁了
'''
解决方法,递归锁,在Python中为了支持在同一线程中多次请求同一资源,python提供了可重入锁RLock。
这个RLock内部维护着一个Lock和一个counter变量,counter记录了acquire的次数,从而使得资源可以被多次require。直到一个线程所有的acquire都被release,其他的线程才能获得资源。上面的例子如果使用RLock代替Lock,则不会发生死锁:
mutexA=mutexB=threading.RLock() #一个线程拿到锁,counter加1,该线程内又碰到加锁的情况,则counter继续加1,这期间所有其他线程都只能等待,等待该线程释放所有锁,即counter递减到0为止
十 信号量Semaphore
同进程的一样
Semaphore管理一个内置的计数器,
每当调用acquire()时内置计数器-1;
调用release() 时内置计数器+1;
计数器不能小于0;当计数器为0时,acquire()将阻塞线程直到其他线程调用release()。
实例:(同时只有5个线程可以获得semaphore,即可以限制最大连接数为5):
from threading import Thread,Semaphore
import threading
import time
# def func():
# if sm.acquire():
# print (threading.currentThread().getName() + ' get semaphore')
# time.sleep(2)
# sm.release()
def func():
sm.acquire()
print('%s get sm' %threading.current_thread().getName())
time.sleep(3)
sm.release()
if __name__ == '__main__':
sm=Semaphore(5)
for i in range(23):
t=Thread(target=func)
t.start()
与进程池是完全不同的概念,进程池Pool(4),最大只能产生4个进程,而且从头到尾都只是这四个进程,不会产生新的,而信号量是产生一堆线程/进程
十一 Event
同进程的一样
线程的一个关键特性是每个线程都是独立运行且状态不可预测。如果程序中的其 他线程需要通过判断某个线程的状态来确定自己下一步的操作,这时线程同步问题就会变得非常棘手。为了解决这些问题,我们需要使用threading库中的Event对象。 对象包含一个可由线程设置的信号标志,它允许线程等待某些事件的发生。在 初始情况下,Event对象中的信号标志被设置为假。如果有线程等待一个Event对象, 而这个Event对象的标志为假,那么这个线程将会被一直阻塞直至该标志为真。一个线程如果将一个Event对象的信号标志设置为真,它将唤醒所有等待这个Event对象的线程。如果一个线程等待一个已经被设置为真的Event对象,那么它将忽略这个事件, 继续执行
event.isSet():返回event的状态值; event.wait():如果 event.isSet()==False将阻塞线程; event.set(): 设置event的状态值为True,所有阻塞池的线程激活进入就绪状态, 等待操作系统调度; event.clear():恢复event的状态值为False。

例如,有多个工作线程尝试链接MySQL,我们想要在链接前确保MySQL服务正常才让那些工作线程去连接MySQL服务器,如果连接不成功,都会去尝试重新连接。那么我们就可以采用threading.Event机制来协调各个工作线程的连接操作
from threading import Thread,Event
import threading
import time,random
def conn_mysql():
count=1
while not event.is_set():
if count > 3:
raise TimeoutError('链接超时')
print('<%s>第%s次尝试链接' % (threading.current_thread().getName(), count))
event.wait(0.5)
count+=1
print('<%s>链接成功' %threading.current_thread().getName()) def check_mysql():
print('\033[45m[%s]正在检查mysql\033[0m' % threading.current_thread().getName())
time.sleep(random.randint(2,4))
event.set()
if __name__ == '__main__':
event=Event()
conn1=Thread(target=conn_mysql)
conn2=Thread(target=conn_mysql)
check=Thread(target=check_mysql) conn1.start()
conn2.start()
check.start()
十二 条件Condition(了解)
使得线程等待,只有满足某条件时,才释放n个线程
import threading def run(n):
con.acquire()
con.wait()
print("run the thread: %s" %n)
con.release() if __name__ == '__main__': con = threading.Condition()
for i in range(10):
t = threading.Thread(target=run, args=(i,))
t.start() while True:
inp = input('>>>')
if inp == 'q':
break
con.acquire()
con.notify(int(inp))
con.release()
def condition_func():
ret = False
inp = input('>>>')
if inp == '':
ret = True
return ret
def run(n):
con.acquire()
con.wait_for(condition_func)
print("run the thread: %s" %n)
con.release()
if __name__ == '__main__':
con = threading.Condition()
for i in range(10):
t = threading.Thread(target=run, args=(i,))
t.start()
十三 定时器
定时器,指定n秒后执行某操作
from threading import Timer def hello():
print("hello, world") t = Timer(1, hello)
t.start() # after 1 seconds, "hello, world" will be printed
十四 线程queue
queue队列 :使用import queue,用法与进程Queue一样
queue is especially useful in threaded programming when information must be exchanged safely between multiple threads.
- class
queue.Queue(maxsize=0) #先进先出
import queue q=queue.Queue()
q.put('first')
q.put('second')
q.put('third') print(q.get())
print(q.get())
print(q.get())
'''
结果(先进先出):
first
second
third
'''
class queue.LifoQueue(maxsize=0) #last in fisrt out
import queue q=queue.LifoQueue()
q.put('first')
q.put('second')
q.put('third') print(q.get())
print(q.get())
print(q.get())
'''
结果(后进先出):
third
second
first
'''
class queue.PriorityQueue(maxsize=0) #存储数据时可设置优先级的队列
import queue q=queue.PriorityQueue()
#put进入一个元组,元组的第一个元素是优先级(通常是数字,也可以是非数字之间的比较),数字越小优先级越高
q.put((20,'a'))
q.put((10,'b'))
q.put((30,'c')) print(q.get())
print(q.get())
print(q.get())
'''
结果(数字越小优先级越高,优先级高的优先出队):
(10, 'b')
(20, 'a')
(30, 'c')
'''
其他
Constructor for a priority queue. maxsize is an integer that sets the upperbound limit on the number of items that can be placed in the queue. Insertion will block once this size has been reached, until queue items are consumed. If maxsize is less than or equal to zero, the queue size is infinite. The lowest valued entries are retrieved first (the lowest valued entry is the one returned by sorted(list(entries))[0]). A typical pattern for entries is a tuple in the form: (priority_number, data). exception queue.Empty
Exception raised when non-blocking get() (or get_nowait()) is called on a Queue object which is empty. exception queue.Full
Exception raised when non-blocking put() (or put_nowait()) is called on a Queue object which is full. Queue.qsize()
Queue.empty() #return True if empty
Queue.full() # return True if full
Queue.put(item, block=True, timeout=None)
Put item into the queue. If optional args block is true and timeout is None (the default), block if necessary until a free slot is available. If timeout is a positive number, it blocks at most timeout seconds and raises the Full exception if no free slot was available within that time. Otherwise (block is false), put an item on the queue if a free slot is immediately available, else raise the Full exception (timeout is ignored in that case). Queue.put_nowait(item)
Equivalent to put(item, False). Queue.get(block=True, timeout=None)
Remove and return an item from the queue. If optional args block is true and timeout is None (the default), block if necessary until an item is available. If timeout is a positive number, it blocks at most timeout seconds and raises the Empty exception if no item was available within that time. Otherwise (block is false), return an item if one is immediately available, else raise the Empty exception (timeout is ignored in that case). Queue.get_nowait()
Equivalent to get(False). Two methods are offered to support tracking whether enqueued tasks have been fully processed by daemon consumer threads. Queue.task_done()
Indicate that a formerly enqueued task is complete. Used by queue consumer threads. For each get() used to fetch a task, a subsequent call to task_done() tells the queue that the processing on the task is complete. If a join() is currently blocking, it will resume when all items have been processed (meaning that a task_done() call was received for every item that had been put() into the queue). Raises a ValueError if called more times than there were items placed in the queue. Queue.join() block直到queue被消费完毕
五 Python标准模块--concurrent.futures
https://docs.python.org/dev/library/concurrent.futures.html
#1 介绍
concurrent.futures模块提供了高度封装的异步调用接口
ThreadPoolExecutor:线程池,提供异步调用
ProcessPoolExecutor: 进程池,提供异步调用
Both implement the same interface, which is defined by the abstract Executor class. #2 基本方法
#submit(fn, *args, **kwargs)
异步提交任务 #map(func, *iterables, timeout=None, chunksize=1)
取代for循环submit的操作 #shutdown(wait=True)
相当于进程池的pool.close()+pool.join()操作
wait=True,等待池内所有任务执行完毕回收完资源后才继续
wait=False,立即返回,并不会等待池内的任务执行完毕
但不管wait参数为何值,整个程序都会等到所有任务执行完毕
submit和map必须在shutdown之前 #result(timeout=None)
取得结果 #add_done_callback(fn)
回调函数
#介绍
The ProcessPoolExecutor class is an Executor subclass that uses a pool of processes to execute calls asynchronously. ProcessPoolExecutor uses the multiprocessing module, which allows it to side-step the Global Interpreter Lock but also means that only picklable objects can be executed and returned. class concurrent.futures.ProcessPoolExecutor(max_workers=None, mp_context=None)
An Executor subclass that executes calls asynchronously using a pool of at most max_workers processes. If max_workers is None or not given, it will default to the number of processors on the machine. If max_workers is lower or equal to 0, then a ValueError will be raised. #用法
from concurrent.futures import ThreadPoolExecutor,ProcessPoolExecutor import os,time,random
def task(n):
print('%s is runing' %os.getpid())
time.sleep(random.randint(1,3))
return n**2 if __name__ == '__main__': executor=ProcessPoolExecutor(max_workers=3) futures=[]
for i in range(11):
future=executor.submit(task,i)
futures.append(future)
executor.shutdown(True)
print('+++>')
for future in futures:
print(future.result())
ProcessPoolExecutor
#介绍
ThreadPoolExecutor is an Executor subclass that uses a pool of threads to execute calls asynchronously.
class concurrent.futures.ThreadPoolExecutor(max_workers=None, thread_name_prefix='')
An Executor subclass that uses a pool of at most max_workers threads to execute calls asynchronously. Changed in version 3.5: If max_workers is None or not given, it will default to the number of processors on the machine, multiplied by 5, assuming that ThreadPoolExecutor is often used to overlap I/O instead of CPU work and the number of workers should be higher than the number of workers for ProcessPoolExecutor. New in version 3.6: The thread_name_prefix argument was added to allow users to control the threading.Thread names for worker threads created by the pool for easier debugging. #用法
与ProcessPoolExecutor相同
ThreadPoolExecutor
from concurrent.futures import ThreadPoolExecutor,ProcessPoolExecutor import os,time,random
def task(n):
print('%s is runing' %os.getpid())
time.sleep(random.randint(1,3))
return n**2 if __name__ == '__main__': executor=ThreadPoolExecutor(max_workers=3) # for i in range(11):
# future=executor.submit(task,i) executor.map(task,range(1,12)) #map取代了for+submit
map的用法
from concurrent.futures import ThreadPoolExecutor,ProcessPoolExecutor
from multiprocessing import Pool
import requests
import json
import os def get_page(url):
print('<进程%s> get %s' %(os.getpid(),url))
respone=requests.get(url)
if respone.status_code == 200:
return {'url':url,'text':respone.text} def parse_page(res):
res=res.result()
print('<进程%s> parse %s' %(os.getpid(),res['url']))
parse_res='url:<%s> size:[%s]\n' %(res['url'],len(res['text']))
with open('db.txt','a') as f:
f.write(parse_res) if __name__ == '__main__':
urls=[
'https://www.baidu.com',
'https://www.python.org',
'https://www.openstack.org',
'https://help.github.com/',
'http://www.sina.com.cn/'
] # p=Pool(3)
# for url in urls:
# p.apply_async(get_page,args=(url,),callback=pasrse_page)
# p.close()
# p.join() p=ProcessPoolExecutor(3)
for url in urls:
p.submit(get_page,url).add_done_callback(parse_page) #parse_page拿到的是一个future对象obj,需要用obj.result()拿到结果
回调函数
Cpython解释器支持的线程的更多相关文章
- Cpython解释器支持的进程与线程
一.理论部分 一 什么是进程 进程:正在进行的一个过程或者说一个任务.而负责执行任务则是cpu. 举例(单核+多道,实现多个进程的并发执行): egon在一个时间段内有很多任务要做:python备课的 ...
- Python-Cpython解释器支持的进程与线程-Day9
Cpython解释器支持的进程与线程 阅读目录 一 python并发编程之多进程 1.1 multiprocessing模块介绍 1.2 Process类的介绍 1.3 Process类的使用 1.4 ...
- Cpython 支持的线程
因为Python解释器帮你自动定期进行内存回收,你可以理解为python解释器里有一个独立的线程,每过一段时间它起wake up做一次全局轮询看看哪些内存数据是可以被清空的,此时你自己的程序 里的线程 ...
- 全局解释器锁GIL & 线程锁
1.GIL锁(Global Interpreter Lock) Python代码的执行由Python虚拟机(也叫解释器主循环)来控制.Python在设计之初就考虑到要在主循环中,同时只有一个线程在执行 ...
- Cpython解释器下实现并发编程——多进程、多线程、协程、IO模型
一.背景知识 进程即正在执行的一个过程.进程是对正在运行的程序的一个抽象. 进程的概念起源于操作系统,是操作系统最核心的概念,也是操作系统提供的最古老也是最重要的抽象概念之一.操作系统的其他所有内容都 ...
- GIL全局解释器锁,线程池与进程池 同步异步,阻塞与非阻塞,异步回调
GIL全局解释器锁 1.什么是GIL 官方解释:'''In CPython, the global interpreter lock, or GIL, is a mutex that prevents ...
- 基于 CPython 解释器,为你深度解析为什么Python中整型不会溢出
前言 本次分析基于 CPython 解释器,python3.x版本 在python2时代,整型有 int 类型和 long 长整型,长整型不存在溢出问题,即可以存放任意大小的整数.在python3后, ...
- cpython解释器内存机制
java虚拟机内存 笼统分为两部分:堆区,栈区 其中,引用在栈区,对象在堆区 详细分为五部分:堆区,虚拟机栈区,本地方法栈区,方法区,程序计数器 cpython解释器内存 笼统分为两部分:堆区,栈区 ...
- 支持JDK19虚拟线程的web框架,之二:完整开发一个支持虚拟线程的quarkus应用
欢迎访问我的GitHub 这里分类和汇总了欣宸的全部原创(含配套源码):https://github.com/zq2599/blog_demos 本篇概览 本篇是<支持JDK19虚拟线程的web ...
随机推荐
- C++学习004-Go To 语句使用
C++中,goto语句主要负责语句的跳转,可以用在循环中跳出循环 注意gotu语句是无条件跳转,用的时候一定要谨慎,一定要少 编写环境 Qt 5.7 for(int i = 0;i<100;i+ ...
- Linux系统安装jdk后出现无法执行binary 文件的错误解决
这是由于jdk版本的问题,针对Linux系统,Oracle提供了 ARM 的32jdk和64位jdk , 但是也提供了类似这样jdk-8u191-linux-i586.tar.gz32或64位的jdk ...
- nopcommerce商城系统--文档整理
原址:http://www.nopcommerce.com/documentation.aspx nopCommerce文档可以帮助您一步一步的搭建属于您自己的在线商城.根据该文档说明,您可以选择您想 ...
- JavaScript中注册时间处理程序的方式
基本的方式有两种: 一.第一种方式,出现在Web初期,给时间目标对象或文档元素设置属性. 1.设置JavaScript对象属性为事件处理程序. 示例: 缺点,这种设计都是围绕着假设每个事件目标对于每种 ...
- 使用window.getSelection()获取div中选中文字内容及位置
div添加一个弹出事件: $(document).ready(function () { $("#marked-area").mouseup(function (e) { $sco ...
- ui-grid表格怎么实现内容居中
这次是思想落后了,只关注怎么使用原生的ui-grid样式来实现这一需求,后来发现可以通过此列的cellTemplate来为列指定内容,从而可以使用css调整样式. ps:其实有时候换种思路,豁然开朗. ...
- maven打包遇到的问题
1.javax.servlet.jsp.tagext不存在 maven打包报程序包javax.servlet.jsp.tagext不存在或者maven打包报程序包javax.servlet.jsp不存 ...
- 颜色采集器colpick Color Picker
简单 RGB.HSB.十六进制颜色选取器 jQuery 插件. 非常直观类似 Photoshop 的界面. 光明和黑暗很容易自定义 CSS3 外观. 28 KB 总由浏览器加载看起来不错甚至在 IE7 ...
- PowerShell收发TCP消息包
PowerShell收发TCP消息包 https://www.cnblogs.com/fuhj02/archive/2012/10/16/2725609.html 在上篇文章中,我们在PSNet包中创 ...
- Win10间歇性卡顿
Win10间歇性卡顿 1.关闭不必要的服务:Windows Update.Windows Search.SuperFetch.Background Intelligent Transfer Servi ...