hadoop学习(一)概念理解
1.概念
1.1什么是hadoop?
hadoop 是大数据存储和处理的框架,主要组成为文件存储系统hdfs和分布式计算框架mapreduce。
1.2能做什么,擅长做什么,不擅长做什么?
1.2.1能做什么,如何做?
hadoop 支持处理TB,PB级别的文件。举个栗子:如100M的文件,过滤出含有helloword的行,写个java pyhton程序就很快完成了,但是1T,1P的文件能做吗?就算能做,需要多长时间,需要多大硬件资源?从传统的设计来讲,在存储和计算上都存在困难。而hdfs文件系统很好的解决了这个问题,很容易的将文件分块存储在成千上百个机器,使用的时候如同使用本地文件一样方便。
hadoop的有点很大程度上来自于hdfs。hdfs优点是:支持副本,可构建在廉价机器集群上,有自己的容错和恢复机制,支持流式访问。
顺便解释下hdfs的设计:将文件分块存储,一般一块128M,默认是64M,块太小了块的映射和维护成本大大增加;块太大了文件恢复和备份变得很困难。
分为namenode和datanode。namenode管理文件的命名空间,存放元数据文件。维护文件系统的所有文件和目录,文件和数据块的映射。同时维护着文件在各个数据节点的信息。datanode存放着具体的数据。

1.2.2 不擅长做什么?
hdfs的缺点:不适合大量小文件存储,不适合并发写入,不支持文件的随机修改,不支持随机读等低延时的访问方式。因为本就不是为了这种场景而设计,所以在选用hadoop的时候也需要根据实际的情况合理选择。
1.3 nn dn snn名词解释
1.3.1
NameNode详解
作用:
Namenode起一个统领的作用,用户通过namenode来实现对其他数据的访问和操作,类似于root根目录的感觉。
Namenode包含:目录与数据块之间的关系(靠fsimage和edits来实现),数据块和节点之间的关系
fsimage文件与edits文件是Namenode结点上的核心文件。
Namenode中仅仅存储目录树信息,而关于BLOCK的位置信息则是从各个Datanode上传到Namenode上的。
Namenode的目录树信息就是物理的存储在fsimage这个文件中的,当Namenode启动的时候会首先读取fsimage这个文件,将目录树信息装载到内存中。
而edits存储的是日志信息,在Namenode启动后所有对目录结构的增加,删除,修改等操作都会记录到edits文件中,并不会同步的记录在fsimage中。
而当Namenode结点关闭的时候,也不会将fsimage与edits文件进行合并,这个合并的过程实际上是发生在Namenode启动的过程中。
也就是说,当Namenode启动的时候,首先装载fsimage文件,然后在应用edits文件,最后还会将最新的目录树信息更新到新的fsimage文件中,然后启用新的edits文件。
整个流程是没有问题的,但是有个小瑕疵,就是如果Namenode在启动后发生的改变过多,会导致edits文件变得非常大,大得程度与Namenode的更新频率有关系。
那么在下一次Namenode启动的过程中,读取了fsimage文件后,会应用这个无比大的edits文件,导致启动时间变长,并且不可控,可能需要启动几个小时也说不定。
Namenode的edits文件过大的问题,也就是SecondeNamenode要解决的主要问题。
SecondNamenode会按照一定规则被唤醒,然后进行fsimage文件与edits文件的合并,防止edits文件过大,导致Namenode启动时间过长。
1.3.2
DataNode详解
DataNode在HDFS中真正存储数据。
首先解释块(block)的概念:
- DataNode在存储数据的时候是按照block为单位读写数据的。block是hdfs读写数据的基本单位。
- 假设文件大小是100GB,从字节位置0开始,每128MB字节划分为一个block,依此类推,可以划分出很多的block。每个block就是128MB大小。
- block本质上是一个 逻辑概念,意味着block里面不会真正的存储数据,只是划分文件的。
- block里也会存副本,副本优点是安全,缺点是占空间
1.3.3
SecondaryNode
执行过程:从NameNode上 下载元数据信息(fsimage,edits),然后把二者合并,生成新的fsimage,在本地保存,并将其推送到NameNode,同时重置NameNode的edits.
2.读、写的工作原理。
2.1写的工作原理。

看图之前需要理解几个点:
1.采用了默认的文件块大小划分。
2.文件大小划分是在client端完成的。
3.nn节点只负责返回给client端文件块可以存储的位置,client端负责将数据发送给具体的dn节点。
4.数据传输过程中是再继续划分64m文件到64k分多次传输。
5.client发送一次数据到其中一个dn,dn之间的复制由dn自己完成。
6.一个块写完成后 dn发送消息给client 由client向nn发送文件目录创建命令,此事会记录在edits文件中,特定时间由secondaryNameNode进行合并到fsimage并同步给nn。这也是snn的主要设计目的。
有一个文件FileA,100M大小。Client将FileA写入到HDFS上。
HDFS按默认配置。
HDFS分布在三个机架上Rack1,Rack2,Rack3。
a. Client将FileA按64M分块。分成两块,block1和Block2;
b. Client向nameNode发送写数据请求,如图蓝色虚线①------>。
c. NameNode节点,记录block信息。并返回可用的DataNode,如粉色虚线②--------->。
Block1: host2,host1,host3
Block2: host7,host8,host4
原理:
NameNode具有RackAware机架感知功能,这个可以配置。
若client为DataNode节点,那存储block时,规则为:副本1,同client的节点上;副本2,不同机架节点上;副本3,同第二个副本机架的另一个节点上;其他副本随机挑选。
若client不为DataNode节点,那存储block时,规则为:副本1,随机选择一个节点上;副本2,不同副本1,机架上;副本3,同副本2相同的另一个节点上;其他副本随机挑选。
d. client向DataNode发送block1;发送过程是以流式写入。
流式写入过程,
1>将64M的block1按64k的package划分;
2>然后将第一个package发送给host2;
3>host2接收完后,将第一个package发送给host1,同时client想host2发送第二个package;
4>host1接收完第一个package后,发送给host3,同时接收host2发来的第二个package。
5>以此类推,如图红线实线所示,直到将block1发送完毕。
6>host2,host1,host3向NameNode,host2向Client发送通知,说“消息发送完了”。如图粉红颜色实线所示。
7>client收到host2发来的消息后,向namenode发送消息,说我写完了。这样就真完成了。如图黄色粗实线
8>发送完block1后,再向host7,host8,host4发送block2,如图蓝色实线所示。
9>发送完block2后,host7,host8,host4向NameNode,host7向Client发送通知,如图浅绿色实线所示。
10>client向NameNode发送消息,说我写完了,如图黄色粗实线。。。这样就完毕了。
分析,通过写过程,我们可以了解到:
①写1T文件,我们需要3T的存储,3T的网络流量贷款。
②在执行读或写的过程中,NameNode和DataNode通过HeartBeat进行保存通信,确定DataNode活着。如果发现DataNode死掉了,就将死掉的DataNode上的数据,放到其他节点去。读取时,要读其他节点去。
③挂掉一个节点,没关系,还有其他节点可以备份;甚至,挂掉某一个机架,也没关系;其他机架上,也有备份。
2.2 读操作工作原理。
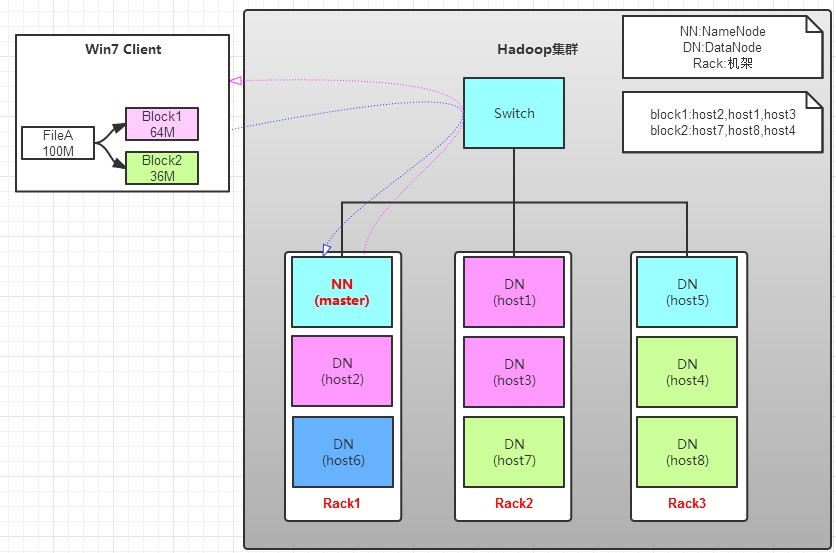
读操作 相对简单。
client 告诉nn要读取文件。nn告诉client文件的块位置和块大小,块顺序。如block1,block2,然后client请求对应host读取文件,最后进行组装。
那么,读操作流程为:
a. client向namenode发送读请求。
b. namenode查看Metadata信息,返回fileA的block的位置。
block1:host2,host1,host3
block2:host7,host8,host4
c. block的位置是有先后顺序的,先读block1,再读block2。而且block1去host2上读取;然后block2,去host7上读取;
上面例子中,client位于机架外,那么如果client位于机架内某个DataNode上,例如,client是host6。那么读取的时候,遵循的规律是:
优选读取本机架上的数据。
运算和存储在同一个服务器中,每一个服务器都可以是本地服务器。
hadoop学习(一)概念理解的更多相关文章
- hadoop学习(一)----概念和整体架构
程序员就得不停地学习啊,故步自封不能满足公司的业务发展啊!所以我们要有搞事情的精神.都说现在是大数据的时代,可以我们这些码农还在java的业务世界里面转悠呢.好不容易碰到一个可能会用到大数据技术的场景 ...
- SpringCloud的入门学习之概念理解、Eureka服务注册与发现入门
1.微服务与微服务架构.微服务概念如下所示: 答:微服务强调的是服务的大小,它关注的是某一个点,是具体解决某一个问题.提供落地对应服务的一个服务应用,狭意的看,可以看作Eclipse里面的一个个微服务 ...
- SpringCloud的入门学习之概念理解、Config配置中心
1.SpringCloud Config分布式配置中心.分布式系统面临的配置问题. 答:微服务意味着要将单体应用中的业务拆分成一个个子服务,每个服务的粒度相对较小,因此系统中会出现大量的服务.由于每个 ...
- SpringCloud的入门学习之概念理解、Zuul路由网关
1.Zuul路由网关是什么? 答:Zuul包含了对请求的路由和过滤两个最主要的功能,其中路由功能负责将外部请求转发到具体的微服务实例上,是实现外部访问统一入口的基础而过滤器功能则负责对请求的处理过程进 ...
- SpringCloud的入门学习之概念理解、Hystrix断路器
1.分布式系统面临的问题,复杂分布式体系结构中的应用程序有数十个依赖关系,每个依赖关系在某些时候将不可避免地失败. 2.什么是服务雪崩? 答:多个微服务之间调用的时候,假设微服务A调用微服务B和微服务 ...
- SpringCloud的入门学习之概念理解、Feign负载均衡入门
1.Feign是SpringCloud的一个负载均衡组件. Feign是一个声明式WebService客户端.使用Feign能让编写Web Service客户端更加简单, 它的使用方法是定义一个接口, ...
- SpringCloud的入门学习之概念理解、Ribbon负载均衡入门
1.Ribbon负载均衡,Spring Cloud Ribbon是基于Netflix Ribbon实现的一套客户端.负载均衡的工具. 答:简单的说,Ribbon是Netflix发布的开源项目,主要功能 ...
- Hadoop学习笔记(6) ——重新认识Hadoop
Hadoop学习笔记(6) ——重新认识Hadoop 之前,我们把hadoop从下载包部署到编写了helloworld,看到了结果.现是得开始稍微更深入地了解hadoop了. Hadoop包含了两大功 ...
- 大数据核心知识点:Hbase、Spark、Hive、MapReduce概念理解,特点及机制
今天,上海尚学堂大数据培训班毕业的一位学生去参加易普软件公司面试,应聘的职位是大数据开发.面试官问了他10个问题,主要集中在Hbase.Spark.Hive和MapReduce上,基础概念.特点.应用 ...
- Hadoop — HDFS的概念、原理及基本操作
1. HDFS的基本概念和特性 设计思想——分而治之:将大文件.大批量文件分布式存放在大量服务器上,以便于采取分而治之的方式对海量数据进行运算分析.在大数据系统中作用:为各类分布式运算框架(如:map ...
随机推荐
- leetCode 30.Substring with Concatenation of All Words (words中全部子串相连) 解题思路和方法
Substring with Concatenation of All Words You are given a string, s, and a list of words, words, tha ...
- java - day15 - nstInner
匿名内部类 package com.javatest.mama; public class Mama { int x = 5; public static void main(String[] arg ...
- 第一百八十九节,jQueryUI,折叠菜单 UI
jQueryUI,折叠菜单 UI 学习要点: 1.使用 accordion 2.修改 accordion 样式 3.accordion()方法的属性 4.accordion()方法的事件 5.acco ...
- linux oracle sqlplus中文乱码解决
在oracle用户的~/.bash_profile中添加 NLS_LANG="SIMPLIFIED CHINESE"_CHINA.ZHS16GBKexport NLS_LANG 然 ...
- WPF-数据转换
有时我们展现的数据,需要进行转换,比如如果一个学生的成绩过了60,我们显示一个Pass的图片. XAML: <Window x:Class="DeepXAML.MainWindow&q ...
- sscanf
#include<stdio.h> 1.sscanf和scanf的不同是输入来源,前者是一个字符串,后者则是标准输入设备 2.sscanf的使用,以解析时间字符串为例,将字符串“2009- ...
- Log4Net 笔记
Log4net框架简介: Log4net 是 Apache 下的一个开源项目,log4net框架基于Apache log4j™.Log4net用于日志记录或跟踪API,它允许开发人员控制以任意粒度输出 ...
- 利用.Net中Process类调用netstat命令来判断计算端口的使用情况
利用.Net中Process类调用netstat命令来判断计算端口的使用情况: Process p = new Process();p.StartInfo = new ProcessStartInfo ...
- log4j分级别打印和如何配置多个Logger
log4j.rootLogger=dubug,info,warn,error 最关键的是log4j.appender.[level].threshold=[level] 这个是日志分级别打印的最关 ...
- iOS学习笔记(十)——iOS真机调试
前面一直使用模拟器运行,今天使用了真机调试,这一篇介绍一下真机调试.真机调试需要99$注册,如果有注册过的账号,也可以使用注册账号邀请你加入一个账号下,注册账号可以给你分配权限,我也是使用的邀请成为开 ...