kafka connect简介以及部署
https://blog.csdn.net/u011687037/article/details/57411790
1、什么是kafka connect?
根据官方介绍,Kafka Connect是一种用于在Kafka和其他系统之间可扩展的、可靠的流式传输数据的工具。它使得能够快速定义将大量数据集合移入和移出Kafka的连接器变得简单。 Kafka Connect可以获取整个数据库或从所有应用程序服务器收集指标到Kafka主题,使数据可用于低延迟的流处理。导出作业可以将数据从Kafka topic传输到二次存储和查询系统,或者传递到批处理系统以进行离线分析。 Kafka Connect功能包括:
- Kafka connector通用框架,提供统一的集成API
- 同时支持分布式模式和单机模式
- REST 接口,用来查看和管理Kafka connectors
- 自动化的offset管理,开发人员不必担心错误处理的影响
- 分布式、可扩展
- 流/批处理集成
KafkaCnnect有两个核心概念:Source和Sink。 Source负责导入数据到Kafka,Sink负责从Kafka导出数据,它们都被称为Connector。

2、kafka connect概念。
Kafka connect的几个重要的概念包括:connectors、tasks、workers和converters。
- Connectors-通过管理任务来细条数据流的高级抽象
- Tasks- 数据写入kafka和数据从kafka读出的实现
- Workers-运行connectors和tasks的进程
- Converters- kafka connect和其他存储系统直接发送或者接受数据之间转换数据
1) Connectors:在kafka connect中,connector决定了数据应该从哪里复制过来以及数据应该写入到哪里去,一个connector实例是一个需要负责在kafka和其他系统之间复制数据的逻辑作业,connector plugin是jar文件,实现了kafka定义的一些接口来完成特定的任务。
2) Tasks:task是kafka connect数据模型的主角,每一个connector都会协调一系列的task去执行任务,connector可以把一项工作分割成许多的task,然后再把task分发到各个worker中去执行(分布式模式下),task不自己保存自己的状态信息,而是交给特定的kafka 主题去保存(config.storage.topic 和status.storage.topic)。在分布式模式下有一个概念叫做任务再平衡(Task Rebalancing),当一个connector第一次提交到集群时,所有的worker都会做一个task rebalancing从而保证每一个worker都运行了差不多数量的工作,而不是所有的工作压力都集中在某个worker进程中,而当某个进程挂了之后也会执行task rebalance。
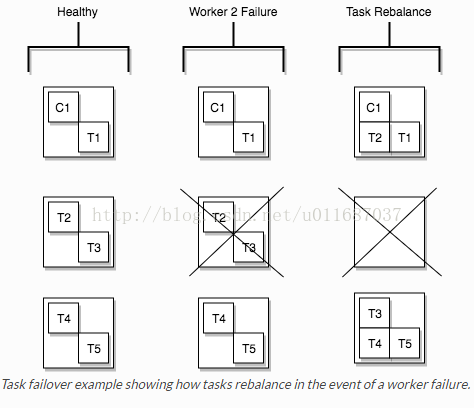
3) Workers:connectors和tasks都是逻辑工作单位,必须安排在进程中执行,而在kafka connect中,这些进程就是workers,分别有两种worker:standalone和distributed。这里不对standalone进行介绍,具体的可以查看官方文档。我个人觉得distributed worker很棒,因为它提供了可扩展性以及自动容错的功能,你可以使用一个group.ip来启动很多worker进程,在有效的worker进程中它们会自动的去协调执行connector和task,如果你新加了一个worker或者挂了一个worker,其他的worker会检测到然后在重新分配connector和task。
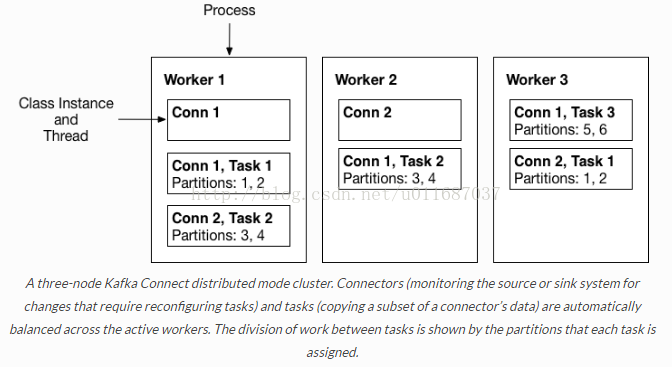
4) Converters: converter会把bytes数据转换成kafka connect内部的格式,也可以把kafka connect内部存储格式的数据转变成bytes,converter对connector来说是解耦的,所以其他的connector都可以重用,例如,使用了avro converter,那么jdbc connector可以写avro格式的数据到kafka,当然,hdfs connector也可以从kafka中读出avro格式的数据。
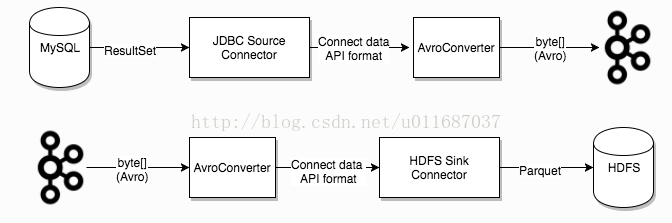
3、kafka connect的启动。
Kafka connect的工作模式分为两种,分别是standalone模式和distributed模式。
在独立模式种,所有的work都在一个独立的进程种完成,如果用于生产环境,建议使用分布式模式,都在真的就有点浪费kafka connect提供的容错功能了。
standalone启动的命令很简单,如下:
bin/connect-standalone.shconfig/connect-standalone.properties connector1.properties[connector2.properties ...]
一次可以启动多个connector,只需要在参数中加上connector的配置文件路径即可。
启动distributed模式命令如下:
bin/connect-distributed.shconfig/connect-distributed.properties
在connect-distributed.properties的配置文件中,其实并没有配置了你的connector的信息,因为在distributed模式下,启动不需要传递connector的参数,而是通过REST API来对kafka connect进行管理,包括启动、暂停、重启、恢复和查看状态的操作,具体介绍详见下文。
在启动kafkaconnect的distributed模式之前,首先需要创建三个主题,这三个主题的配置分别对应connect-distributed.properties文件中config.storage.topic(default connect-configs)、offset.storage.topic (default connect-offsets) 、status.storage.topic (default connect-status)的配置,那么它们分别有啥用处呢?
- config.storage.topic:用以保存connector和task的配置信息,需要注意的是这个主题的分区数只能是1,而且是有多副本的。(推荐partition 1,replica 3)
- offset.storage.topic:用以保存offset信息。(推荐partition50,replica 3)
- status.storage.topic:用以保存connetor的状态信息。(推荐partition10,replica 3)
以下是创建主题命令:
- # config.storage.topic=connect-configs
- $ bin/kafka-topics --create --zookeeper localhost:2181 --topicconnect-configs --replication-factor 3 --partitions 1
- # offset.storage.topic=connect-offsets
- $ bin/kafka-topics --create --zookeeper localhost:2181 --topicconnect-offsets --replication-factor 3 --partitions 50
- # status.storage.topic=connect-status
- $ bin/kafka-topics --create --zookeeper localhost:2181 --topicconnect-status --replication-factor 3 --partitions 10
具体配置信息再次不在赘述,详见kafka官方文档:http://kafka.apache.org/documentation/#connect
4、通过rest api管理connector
因为kafka connect的意图是以服务的方式去运行,所以它提供了REST API去管理connectors,默认的端口是8083,你也可以在启动kafka connect之前在配置文件中添加rest.port配置。
- GET /connectors – 返回所有正在运行的connector名
- POST /connectors – 新建一个connector; 请求体必须是json格式并且需要包含name字段和config字段,name是connector的名字,config是json格式,必须包含你的connector的配置信息。
- GET /connectors/{name} – 获取指定connetor的信息
- GET /connectors/{name}/config – 获取指定connector的配置信息
- PUT /connectors/{name}/config – 更新指定connector的配置信息
- GET /connectors/{name}/status – 获取指定connector的状态,包括它是否在运行、停止、或者失败,如果发生错误,还会列出错误的具体信息。
- GET /connectors/{name}/tasks – 获取指定connector正在运行的task。
- GET /connectors/{name}/tasks/{taskid}/status – 获取指定connector的task的状态信息
- PUT /connectors/{name}/pause – 暂停connector和它的task,停止数据处理知道它被恢复。
- PUT /connectors/{name}/resume – 恢复一个被暂停的connector
- POST /connectors/{name}/restart – 重启一个connector,尤其是在一个connector运行失败的情况下比较常用
- POST /connectors/{name}/tasks/{taskId}/restart – 重启一个task,一般是因为它运行失败才这样做。
- DELETE /connectors/{name} – 删除一个connector,停止它的所有task并删除配置。
kafka connect简介以及部署的更多相关文章
- 替代Flume——Kafka Connect简介
我们知道过去对于Kafka的定义是分布式,分区化的,带备份机制的日志提交服务.也就是一个分布式的消息队列,这也是他最常见的用法.但是Kafka不止于此,打开最新的官网. 我们看到Kafka最新的定义是 ...
- Kafka Connect简介
Kafka Connect简介 http://colobu.com/2016/02/24/kafka-connect/#more Kafka 0.9+增加了一个新的特性Kafka Connect,可以 ...
- 最简单流处理引擎——Kafka Streaming简介
Kafka在0.10.0.0版本以前的定位是分布式,分区化的,带备份机制的日志提交服务.而kafka在这之前也没有提供数据处理的顾服务.大家的流处理计算主要是还是依赖于Storm,Spark Stre ...
- Kafka: Connect
转自:http://www.cnblogs.com/f1194361820/p/6108025.html Kafka Connect 简介 Kafka Connect 是一个可以在Kafka与其他系统 ...
- Hadoop生态圈-Kafka的本地模式部署
Hadoop生态圈-Kafka的本地模式部署 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.Kafka简介 1>.什么是JMS 答:在Java中有一个角消息系统的东西,我 ...
- kafka——集群安裝部署(自带zookeeper)
kafka系列文章 第一章 linux单机安装kafka 第二章 kafka--集群安裝部署(自带zookeeper) 一.kafka简介 kafka官网:http://kafka.apache.or ...
- Kafka的安装和部署及测试
1.简介 大数据分析处理平台包括数据的接入,数据的存储,数据的处理,以及后面的展示或者应用.今天我们连说一下数据的接入,数据的接入目前比较普遍的是采用kafka将前面的数据通过消息的方式,以数据流的形 ...
- 基于Kafka Connect框架DataPipeline在实时数据集成上做了哪些提升?
在不断满足当前企业客户数据集成需求的同时,DataPipeline也基于Kafka Connect 框架做了很多非常重要的提升. 1. 系统架构层面. DataPipeline引入DataPipeli ...
- 打造实时数据集成平台——DataPipeline基于Kafka Connect的应用实践
导读:传统ETL方案让企业难以承受数据集成之重,基于Kafka Connect构建的新型实时数据集成平台被寄予厚望. 在4月21日的Kafka Beijing Meetup第四场活动上,DataPip ...
随机推荐
- java代码中fastjson生成字符串和解析字符串的方法和javascript文件中字符串和json数组之间的转换方法
1.java代码中fastjson生成字符串和解析字符串的方法 List<TemplateFull> templateFulls = new ArrayList<TemplateFu ...
- CodeIgniter 框架在Apache服务器下去掉index.php 总结
最近一段时间一直研究CI框架,但是对CI框架的跳转链接一直需要加index.php前缀,经过CI论坛的各种解决方案,最后总结记录一下自己实际操作去掉index.php的过程. 1.要修改Apache ...
- 如何在GitHub上删除某个文件夹?
步骤: (以删除.idea文件夹为例) git rm -r --cached .idea #--cached不会把本地的.idea删除 git commit -m 'delete .idea dir' ...
- Oracle----Oracle 11g XE release2安装与指导
今天上午我安装了Oracle 11g企业版,发现太占内存了,考虑到MS SQL有express版本,所以寻思着尝试尝试Oracle 11g的express版本,就是EX版本.下面是具体的安装步骤. 1 ...
- UIImagePickerController关于图片裁剪
- (UIImage*)scaleImage:(UIImage*)anImage withEditingInfo:(NSDictionary*)editInfo{ UIImage *newImage; ...
- 第一百九十六节,jQuery EasyUI,Tooltip(提示框)组件
jQuery EasyUI,Tooltip(提示框)组件 学习要点: 1.加载方式 2.属性列表 3.事件列表 4.方法列表 本节课重点了解 EasyUI 中 Tooltip(提示框)组件的使用方法, ...
- 黑马day11 事务的四大特性
1.事务的四大特性:一个事务具有的最主要的特性.一个设计良好的数据库能够为我们保证这四大特性. 1.1原子性:原子性是指事务是一个不可切割的工作单位,事务中的操作要么都发生要么都不发生. 1.2一致性 ...
- python3----ljust rjust center
Python中打印字符串时可以调用ljust(左对齐),rjust(右对齐),center(中间对齐)来输出整齐美观的字符串,使用起来非常简单,包括使用第二个参数填充(默认为空格).看下面的例子就会明 ...
- python3----练习题(三级菜单)
三级菜单程序. 运行程序输出第一级菜单. 选择一级菜单某项,输出二级菜单,同理输出三级菜单. 退出时返回上一级菜单 menu = { '北京市': { '东城区': { 'aa', 'bb', }, ...
- ubuntu 16.04 系统语言汉化
转载自:https://jingyan.baidu.com/article/5553fa82cedaa265a2393420.html