结对作业-WordCount进阶版
1.在文章开头给出博客作业要求地址。
博客园地址:https://www.cnblogs.com/happyzm/p/9559372.html
2.给出结对小伙伴的学号、博客地址,结对项目的码云地址。
结对小伙伴的学号:201621123012
博客地址:https://www.cnblogs.com/saodeyipi/p/9756450.html
结对的码云地址:https://gitee.com/wistarias/PersonalProject-Java
3.给出结对的PSP表格。
| PSP2.1 | 结对开发流程 | 预估耗费时间(分钟) | 实际耗费时间(分钟) |
|---|---|---|---|
| Planning | 计划 | 10 | 5 |
| · Estimate | 明确需求和其他相关因素,估计每个阶段的时间成本 | 5 | 0 |
| Development | 开发 | 150 | 200 |
| · Analysis | 需求分析 (包括学习新技术) | 10 | 15 |
| · Design Spec | 生成设计文档 | 10 | 0 |
| · Design Review | 设计复审 | 10 | 5 |
| · Coding Standard | 代码规范 | 0 | 0 |
| · Design | 具体设计 | 10 | 20 |
| · Coding | 具体编码 | 100 | 120 |
| · Code Review | 代码复审 | 10 | 5 |
| · Test | 测试(自我测试,修改代码,提交修改) | 10 | 25 |
| Reporting | 报告 | 10 | 6 |
| · | 测试报告 | 5 | 2 |
| · | 计算工作量 | 5 | 2 |
| · | 并提出过程改进计划 | 0 | 0 |
4.设计实现过程。设计包括代码如何组织,比如会有几个类,几个函数,他们之间关系如何,关键函数是否需要画出流程图?单元测试是怎么设计的?
1.这个程序我负责的是对文件的行,单词数,字符数,单词频率的计算,我的搭档负责的是图形化的界面。
public class words //文件读取并完成对行,单词数,字符数,单词频率的计算
2.在类中一共有6个函数
public static int line(String filename) //文件读取并完成对行的计算
public static int bytenumber(String filename) //文件读取并完成对字符数的计算
public static int wordnumber(String filename)//文件读取并完成对单词数的计算
public static List<Map.Entry<String, Integer>> out(String filename)//文件读取并完成对单词频率的计算
public static List<Map.Entry<String, Integer>> out(String filename, int h)//文件读取并完成对指定数量单词频率的计算
public static List<Map.Entry<String, Integer>> outg(String filename, int k)//文件读取并完成对指定数量单词组的计算
5.代码说明。展示出项目关键代码,并解释思路与注释说明。
1.关键代码
(1)line(String filename)
while ((line = bufReader.readLine()) != null) {
for (int i = 0; i <= line.length() - 1; i++) {
if (Character.isUpperCase(line.charAt(i))) //对大写字母的判断
{
Character.toLowerCase(line.charAt(i));
}
}
linecount++;//行数统计
text.add(line);
}
文件读取并完成对行的计算
(2)bytenumber(String filename)
while ((line = bufReader.readLine()) != null) {
for (int i = 0; i <= line.length() - 1; i++) {
if (Character.isUpperCase(line.charAt(i))) //对大写字母的判断
{
Character.toLowerCase(line.charAt(i));
}
}
wordcount += line.length();//字符数统计
text.add(wordcount );
}
文件读取并完成对字符数的计算
(3)wordnumber(String filename)
for (String words : text) {
String[] word = words.split("[^a-zA-Z0-9]");
for (String pp : word) {
String regex = "^[a-z]{4}[a-z0-9\\s]*$";
if (pp.matches(regex) == true) {
text2.add(pp);
}
}
}
return text2.size();
文件读取并完成对单词数的计算
(4)out(String filename)
Map<String, Integer> map = new TreeMap<String, Integer>();
for (String word : text2) {
if (map.get(word) != null) {
map.put(word, map.get(word) + 1);
} else {
map.put(word, 1);
}
}
List<Map.Entry<String, Integer>> infoIds = new ArrayList<Map.Entry<String, Integer>>(map.entrySet());
List<Map.Entry<String, Integer>> infoIds1 = new ArrayList<Map.Entry<String, Integer>>();
Collections.sort(infoIds, new Comparator<Map.Entry<String, Integer>>() {
public int compare(Map.Entry<String, Integer> o1,
Map.Entry<String, Integer> o2) {
return (o2.getValue() - o1.getValue());
}
});
System.out.println("--------------排序后--------------");
for (int i = 0; i < infoIds.size(); i++) {
Entry<String, Integer> ent = infoIds.get(i);
if (i <= 9) {
infoIds1.add(ent);
}
}
return infoIds1;
文件读取并完成对单词频率的计算
2.代码测试
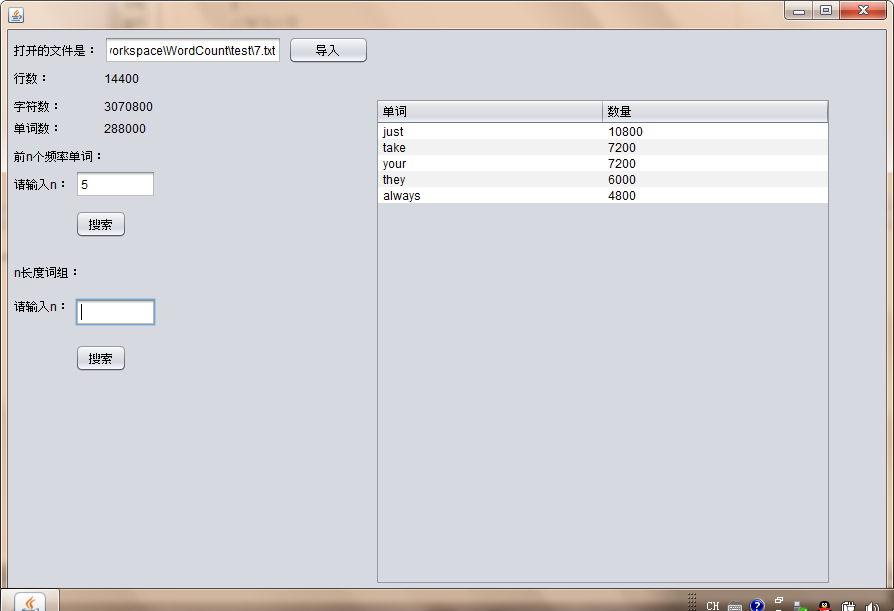
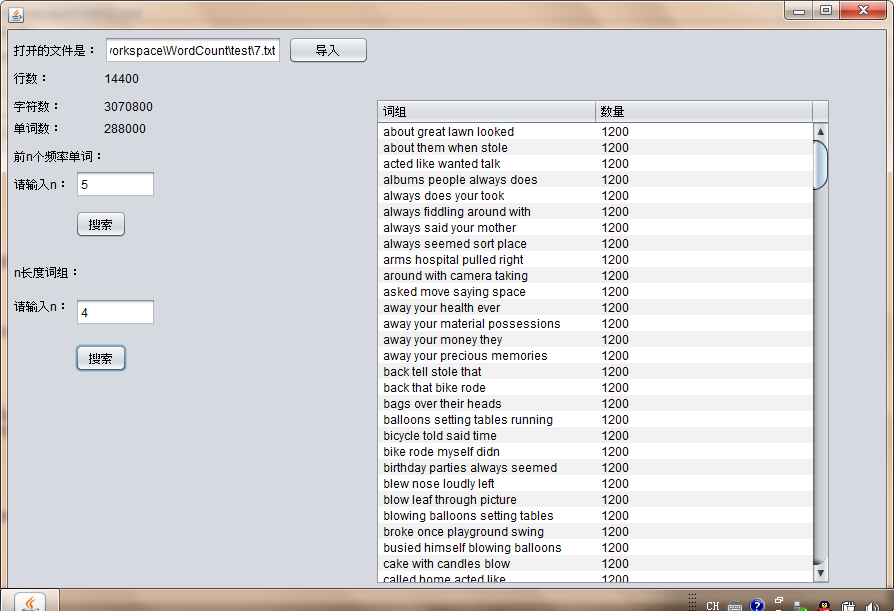
3.代码的提交

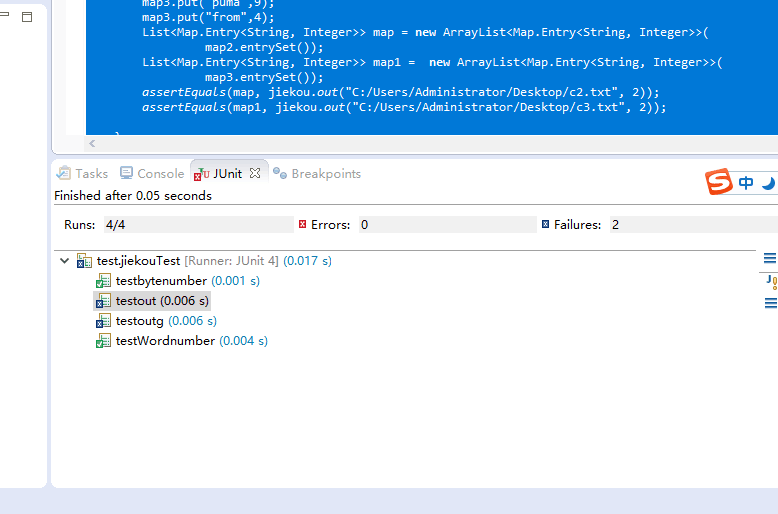
6.单元测试
测试数据
c1.txt:空文件
c2.txt:包含英文,特殊字符,中文等
c3.txt:一篇完整的英语的短文
import static org.junit.Assert.*;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
import java.util.TreeMap;
import org.junit.Before;
import org.junit.Test;
import one.jiekou;
public class jiekouTest {
@Before
public void setUp() throws Exception {
}
@Test
public void testWordnumber() {
assertEquals(0, jiekou.wordnumber("C:/Users/Administrator/Desktop/c1.txt"));//空文件
assertEquals(14, jiekou.wordnumber("C:/Users/Administrator/Desktop/c2.txt"));//14个单词的纯英文
assertEquals(160, jiekou.wordnumber("C:/Users/Administrator/Desktop/c3.txt"));//160个单词的英文数字混合
}
@Test
public void testbytenumber() {
assertEquals(0, jiekou.bytenumber("C:/Users/Administrator/Desktop/c1.txt"));
assertEquals(136, jiekou.bytenumber("C:/Users/Administrator/Desktop/c2.txt"));
assertEquals(1505, jiekou.bytenumber("C:/Users/Administrator/Desktop/c3.txt"));
}
@Test
public void testout() {
Map<String, Integer> map2 = new TreeMap<String, Integer>();
Map<String, Integer> map3 = new TreeMap<String, Integer>();
map2.put("xmkczui84", 4);
map2.put("agisckxvn", 4);
map3.put("puma", 9);
map3.put("from", 4);
List<Map.Entry<String, Integer>> map = new ArrayList<Map.Entry<String, Integer>>(
map2.entrySet());
List<Map.Entry<String, Integer>> map1 = new ArrayList<Map.Entry<String, Integer>>(
map3.entrySet());
assertEquals(map, jiekou.out("C:/Users/Administrator/Desktop/c2.txt", 2));
assertEquals(map1, jiekou.out("C:/Users/Administrator/Desktop/c3.txt", 2));
}
@Test
public void testoutg() {
Map<String, Integer> map3 = new TreeMap<String, Integer>();
Map<String, Integer> map2 = new TreeMap<String, Integer>();
map3.put("accumulate experts from felt obliged", 1);
map2.put("america when reports came into", 1);
List<Map.Entry<String, Integer>> map1 = new ArrayList<Map.Entry<String, Integer>>(
map3.entrySet());
assertEquals(map3, "{" + jiekou.outg("C:/Users/Administrator/Desktop/c3.txt", 5).get(0) + "}");
assertEquals(map2, "{" + jiekou.outg("C:/Users/Administrator/Desktop/c3.txt", 5).get(1) + "}");
}
}
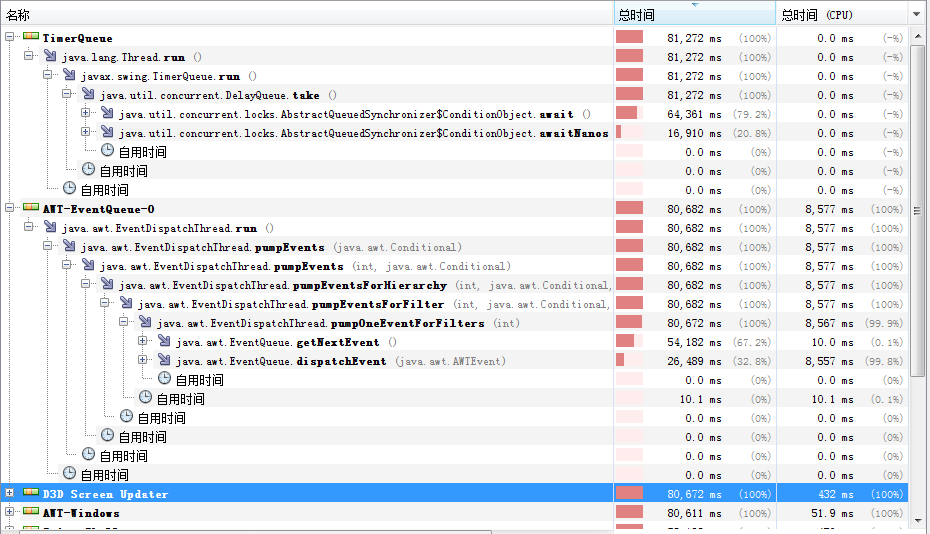
7.效能分析
8.结合在构建之法中学习到的相关内容与结对项目的实践经历,描述结对的感受,是否1+1>2?。
进行结对编程遇到的问题比我想象的多,在开始决定要做网页还是gui时就产生了不同的想法,之后在代码分工时碰到分工的不明确,导致有些功能重叠,还有就是有个人写得较快时,另一个人没有写好,这导致另一个人的进度不得不放缓。最后的一个问题是大家的代码风格不太相同,所以在对接时容易遇到一些问题。当然这结对编程也是有好处的,当其中一方比较放松时,另一方的需求就会时时激励你不断的前进。而且要写的代码量减少了很多,总的来说还是1+1>2的。
结对作业-WordCount进阶版的更多相关文章
- 结对作业——WordCount进阶版
Deadline: 2018-10-7 22:00PM,以博客提交至班级博客时间为准 要求参考来自:https://www.cnblogs.com/xinz/archive/2011/11/27/22 ...
- 第二次结对作业-WordCount进阶需求
原博客 队友博客 github项目地址 目录 具体分工 需求分析 PSP表格 解题思路描述与设计实现说明 爬虫使用 代码组织与内部实现设计(类图) 算法的关键与关键实现部分流程图 附加题设计与展示 设 ...
- 结队第二次作业——WordCount进阶需求
结队第二次作业--WordCount进阶需求 博客地址 051601135 岳冠宇 博客地址 051604103 陈思孝 博客地址 Github地址 具体分工 队友实现了爬虫功能,我实现了wordco ...
- 结对第2次作业——WordCount进阶需求
作业题目链接 队友链接 Fork的同名仓库的Github项目地址 具体分工 玮哥负责命令参数判断.单词权重统计,我只负责词组词频统计(emmmm). PSP表格 预估耗时(分钟) 实际耗时(分钟) P ...
- 结对作业二——WordCount进阶版
软工作业三 要求地址 作业要求地址 结对码云项目地址 结对伙伴:秦玉 博客地址 PSP表格 PSP2.1 个人开发流程 预估耗费时间(分钟) 实际耗费时间(分钟) Planning 计划 10 7 · ...
- 《软件工程实践》第五次作业-WordCount进阶需求 (结对第二次)
在文章开头给出结对同学的博客链接.本作业博客的链接.你所Fork的同名仓库的Github项目地址 本作业博客链接 github pair c 031602136魏璐炜博客 031602139徐明盛博客 ...
- 软工实践第五次作业-WordCount进阶需求
软工实践作业(五) GitHub 作业链接 结对博客 031602240 具体分工 PSP表格 代码规范 解题思路与设计说明 爬虫使用 代码组织与内部实现设计(类图) 算法关键 实现方法 流程图 附加 ...
- 软工实践——结对作业2【wordCount进阶需求】
附录: 队友的博客链接 本次作业的博客链接 同名仓库项目地址 一.具体分工 我负责撰写爬虫爬取信息以及代码整合测试,队友子恒负责写词组词频统计功能的代码. 二.PSP表格 PSP2.1 Persona ...
- 结对作业(1.0版)(bug1已修复)
import java.awt.EventQueue; import javax.swing.JFrame; import javax.swing.JPanel; import javax.swing ...
随机推荐
- proc文件系统详解(原创)
Linux系统上的/proc目录是一种文件系统,即proc文件系统.与其它常见的文件系统不同的是,/proc是一种伪文件系统(也即虚拟文件系统),存储的是当前内核运行状态的一系列特殊文件,用户可以通过 ...
- Angular2快速入门-2.创建一个新闻列表
背景: 我们想通过一个例子,展示下Angular2 怎么绑定页面,怎么创建Component, 例子:我们创建一个新闻列表,当点击新闻列表中某一条新闻的时候,展示出该条新闻的详细信息, 在详细信息中可 ...
- VS2017自动添加头部注释
让VS自动生成类的头部注释,只需修改两个文集即可,一下两个路径下个有一个 Class.cs文件 D:\Program Files (x86)\Microsoft Visual Studio\2017\ ...
- BurpSuite系列(九)----Comparer模块(比较器)
一.简介 Burp Comparer在Burp Suite中主要提供一个可视化的差异比对功能,来对比分析两次数据之间的区别.使用中的场景可能是: 1.枚举用户名过程中,对比分析登陆成功和失败时,服务器 ...
- linux中stdout,stdin,stderr意义
stdout, stdin, stderr的中文名字分别是标准输出,标准输入和标准错误. 在Linux下,当一个用户进程被创建的时候,系统会自动为该进程创建三个数据流,也就是题目中所提到的这三个.那么 ...
- python调用Go代码
Go 1.5发布了,其中包含了一个特性:可以编译生成动态链接库,经试验,生成的.so文件可以被python加载并调用.下面举个例子: 先写一个go文件main.go: package main imp ...
- 有关Lucene的问题(4):影响Lucene对文档打分的四种方式
原文出自:http://forfuture1978.iteye.com/blog/591804点击打开链接 在索引阶段设置Document Boost和Field Boost,存储在(.nrm)文件中 ...
- ZOJ3953 Intervals
题意 有n个区间,要求删除一些区间使得不存在三个相交的区间.找出删除的最少区间. 分析 是个比较显然的贪心吧. 先按照区间的左起点进行排序,然后从左往右扫,当有三个区间相交的时候,删除那个右端点最远的 ...
- LoadRunner 关联和集合点、检查点
1)关联的定义 很多时候,当时录完之后,没有问题.过一段时间再跑脚本,就不会成功.比如session,过期了,再一次使用,就会出错.这个时候,需要在每次访问的时候动态的拿到session,这种情况就需 ...
- Hyperledger子项目
Hyperledger由五个子项目构成: • BlockChain Explorer 展⽰和查询区块链块.事务和相关数据的 Web应⽤ • Fabric 区块链技术的⼀个实现(主要项目) • STL ...